Technical architecture
Te Papa's collection data is stored in Axiell's EMu collection management system (in a relational database). The EMu system does have some APIs available, but they require knowledge of the internal data structures and they do not serve the data in a semantically linked, standardised format.
Our Collections Online website uses its own copy of the published data from EMu. Our new Collections API makes yet another copy of the published data - but eventually we will switch Collections Online to using this API too.
- EMu - The original source of published collection data (our curators use EMu to manage the Te Papa collections).
- Indexer - A Java program that regularly extracts records from the EMu API, converts them into a JSON data format, and stores them in the Elastic Search database. Our JSON data format uses JSON-LD which means it can also be used in Semantic Web and Linked Data applications.
- Elastic Search - An internal, searchable database containing a copy of published EMu collection data as JSON records.
- API Shim - A public website (written in Java) that searches and retrieves raw records from the Elastic Search database and presents them as an API.
- Kong - An internal API administration website - that manages API authentication, rate limiting, etc.
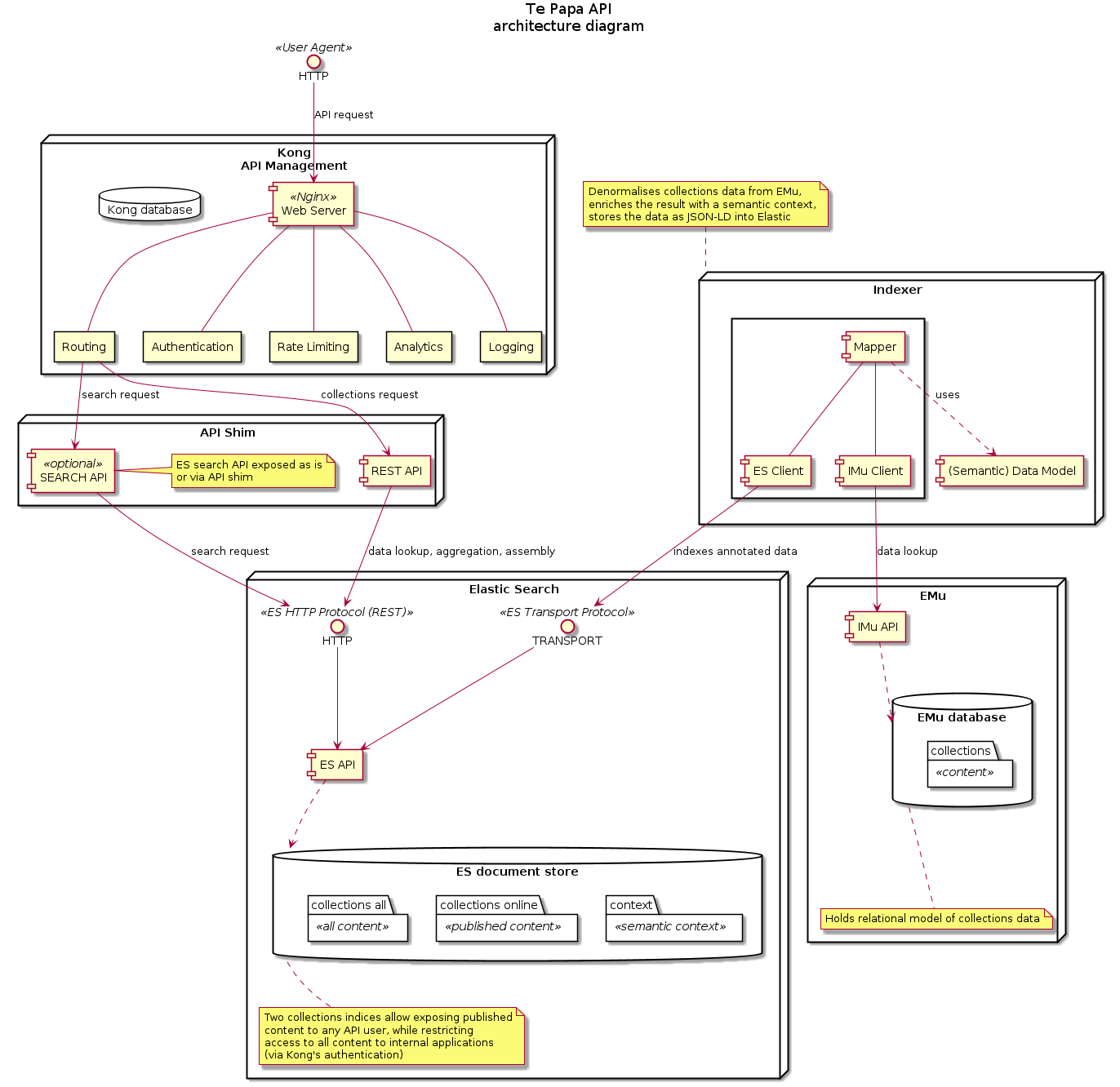
- This architecture provides search and 'get' using scalable, open source, industry solutions (i.e. Elastic Search, Kong, JSON-LD). In particular, Elastic Search lets us index new data while existing data is still being used - we can then switch indexes without any downtime. It is also designed to easily add in more servers as usage grows.
- We will review this architecture based on any future API requirements such as complex querys, 'post' (writing data into the API), SPARQL querys, etc.