Object model design decisions
This page records decisions made when designing the Te Papa Collections API metadata schema (in the Collections API Object Model).
The Te Papa museum catalogue describes a wide variety of resources so the Collections API's metadata schema combines objects and fields from a number of different schema into an Application Profile. The schema design process requires juggling conformance with our own Te Papa API data design guidelines and these multiple schema - which often requires some interpretation and compromise.
Data provided via the Collections API will faithfully reflect the state of the source data in our catalogue systems.
We have invested a lot of effort into improving the quality of our data, however it contains legacy information from paper records dating back to the museum's origins in 1865.
Adding default or automatically-generated values increases the risk of incorrect data. So we have chosen to provide the raw data 'as is' - you can make any adjustments you decide are necessary. We have made some automated improvements, but only when we are confident of the accuracy level of the result.
During development of the Collections API we are using interim namespaces:
- Te Papa Terms - http://collections-api.boh.tepapa.govt.nz/term.xml#
- Te Papa Collections - http://collections-api.boh.tepapa.govt.nz/collection.xml#
- Darwin Core IRI - https://raw.githubusercontent.com/tdwg/vocab/master/code-examples/darwin-core/dwciri.ttl#
Te Papa uses the Darwin Core (DwC) schema for natural sciences collection items (for example, animal or plant specimens). This enables our collections data to be included in virtual herbariums and other biodiversity registers around the world.
Our Collections API uses the richer Resource Description Framework version of Darwin Core (using JSON-LD), which is then 'dumbed-down' to 'Simple Darwin Code' when exporting data dumps.
The Darwin Core RDF Guide discusses the process of converting Simple Darwin Core data into the Resource Description Framework (RDF). Some aspects are not fully described yet, so we are in discussion with the Biodiversity Information Standards Task Group to determine the best practices, including:
- Best practice for connecting containers together
- Dereferencing of the Darwin Core IRI namespace
- Dereferencing of the Darwin-SW IRI namespace
Te Papa's API data design guidelines aims to keep the field structure as flat as possible, however Darwin Core requires fields to be grouped together within containers.
Darwin Core RDF does not yet specify how its containers are related to each other. The Task Group's authors have a proposal: Darwin-SW (DSW). We are using this proposal as a basis for the containers in Te Papa's Collections API, with some limitations.
Te Papa's existing metadata containers mostly align with Darwin Core's containers: specimens, identification events, collection events, locations, agents, taxon, and media. However we do not currently separate out the concepts of organisms and occurrences.
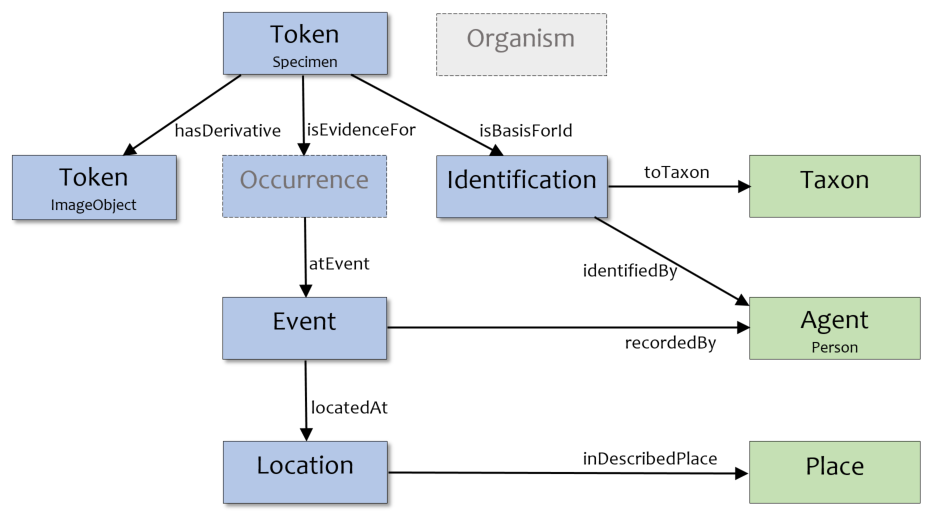
We have limited resourcing available to convert our legacy data, so we have implemented a compromise that partly conforms to Darwin-SW. If/when the Darwin-SW structure is ratified by the Task Group as a Darwin Core standard, we may revisit our implementation then.
- Our primary record is the specimen (as part of the museum's collection). This specimen is equivalent to the Darwin-SW Token.
- Darwin-SW is focused around the concept of an organism (where a specimen is just evidence of that organism). We have not included an automatically-generated Organism entity as we believe these should be defined with human input.
- Our secondary record is the collection event (when the specimen was collected into our collection). This maps to the Darwin Core Event.
- We do not have a separate record for the intermediate concept of occurrence, so we have inserted an automatically-generated scant Occurrence record, but kept its fields with the enclosed Event container (as we don't have an occurrence endpoint in our API).
The following type data is provided in Te Papa specimen records:
-
rdf:typeRDF type field containing:dwc:PreservedSpecimen -
dc:typeDublin Core type field containing other types:- DCMI type:
dcmitype:PhysicalObject - CIDOC-CRM type:
crm:E20_Biological_Object - DSW type:
dsw:Token - DwC basis of record:
dwc:PreservedSpecimenordwc:FossilSpecimen
- DCMI type:
-
dwc:basisOfRecordDwC basis of record field containing text:PreservedSpecimenorFossilSpecimen
Darwin Core RDF best practice is for both the Darwin Core and generic Dublin Core types to be provided in RDF type fields. However, this conflicts with the core attributes in Te Papa's API data design guidelines (where there is only one RDF type due to the constraints of JSON usability). So the DCMI type is provided in a Dublin Core type field instead.
Our collections contain mainly preserved specimens with some fossils.
We have chosen dwc:PreservedSpecimen as the main RDF type for all specimens
(so they can be easily differentiated from non-specimen collection records of
type crm:E19_Physical_Object).
The actual (preserved/fossil) type appears in a DC type field and the
dwc:basisOfRecord field.
Many historical dates in our catalogue do not have month or day information.
So our structured dates conform to ISO 8601
but are formatted based on the
W3C Date and Time Formats Specification.
This supports: YYYY, YYYY-MM and YYYY-MM-DD formats and ranges such as
YYYY/YYYY.
Often our specimens have multiple locations recorded for where they were
collected.
We provide a primary point in the tp:mappingCentroid container, which is a
centroid (average) of the multiple source location points.
The various source points are also provided in a separate tp:mappingDetails
container within the Event container.
Note that the accuracy of our geographic points vary. Recent readings might use GPS-based recording, whereas older readings may be from map co-ordinates that were later automatically converted to longitude/latitude. When there are multiple source points, these may be from multiple separate collection events, or just a single event location that has been converted automatically multiple times.
Our primary centroid locations are provided in standard WGS84 World Geodetic System co-ordinates. Many of these centroids have been converted from another NZ geodetic datum, but they are presented as the best co-ordinates known to Te Papa. The other detailed source mapping locations are supplied in their original geodetic datums, where known.
For the primary centroids, we are currently using a low-accuracy conversion from NZGD49 to NZGD2000 datums, based on national mid-points with +/-15 metres accuracy - see: Where in the world are we?, insert 8.
Some points are withheld for commercial reasons - this is stated in the
dwc:informationWithheld field (where appropriate).
We have not selected a schema for Taxon records yet. In the meantime we have used the Darwin Core taxon fields (though these were only intended to be used as convenience terms).
We have chosen to use schema.org QuantitativeValue properties for measurements. This suits our non-specimen collection items better, which may have multiple components with groups of dimensions (for example: chair WxHxD, table WxHxD).
Specimen measurements (such as Darwin Core's MeasurementOrFact) tend to be a
single list of dimensions, which does not suit our museum collection overall.
-
Preference of HTTP IRIs over non-HTTP IRIs as resource identifiers, to provide more compatibility with Linked Data guidelines. Note that HTTP IRIs have not been added to Collections API data yet, so generated RDF data will contain a lot of blank nodes.
-
Usage of institution and collection codes from the Global Register of Biodiversity Repositories and from Te Papa's own internal collection names
-
Textual convenience fields are populated to improve searchability in the API, including: continent, country, stateProvince
-
Media files are connected using
tp:hasRepresentationrather thanfoaf:depiction(because currently it is not possible to separate images that depict the item from other images) -
The dates that the catalogue record itself was created or modified is in the raw JSON, but is currently excluded from the Darwin Core mapping.