Add http & https asset sources
#16366
Conversation
|
It looks like |
|
It's possible to add an exception for the licenses, but unmaintained and vulnerable is pretty bad. |
|
This could be done with something like |
@mnmaita actually that would be great, I've replaced // crates/bevy_asset/src/http_source.rs#134
let client = reqwest_middleware::ClientBuilder::new(Client::new())
.with(Cache(HttpCache {
mode: CacheMode::Default,
manager: CACacheManager::default(),
options: HttpCacheOptions::default(),
}))
.build();
let response = ContinuousPoll(client.get(str_path).send())
.await |
|
FWIW surf has a bug where any erroring http response >8kb stops every subsequent request from succeeding and is unlikely to ever be fixed which made me unable to use bevy_web_asset so I would personally appreciate a switch 😄. If you can't get reqwest to work perhaps hyper would suffice since it's already in the dep tree for BRP? Perhaps too low level for this. |
|
The council of bevy async wizards has spoken and we're going with A few notes:
|
|
You added a new example but didn't add metadata for it. Please update the root Cargo.toml file. |
Tested on Windows 11. The example prints a 404 error when the .meta file fails to load and doesn't show the sprite. If I configure AssetPlugin to AssetMetaCheck::Never, it runs correctly. I believe the asset is still supposed to load successfully even if the .meta file 404s so I think this is a bug? |
You can ignore that. It isn't a required check. Once those 2 small issues above are fixed, this should be in a pretty good state, I think. |
|
The generated |
http & https asset sourceshttp & https asset sources
|
Ok I can confirm the example is working in wasm and native builds. I'm a bit uneasy merging without native http caching. One of the primary use-cases for the feature is large assets and the current implementation wil re-download them every time the app is run. Maybe a stupidly naive cache, ie one that never automatically invalidates, is better than nothing? In the long run it looks like a |
|
A simple native cache has been added and is ready for review |
|
You added a new feature but didn't update the readme. Please run |
# Objective Basic `TextShadow` support. ## Solution New `TextShadow` component with `offset` and `color` fields. Just insert it on a `Text` node to add a shadow. New system `extract_text_shadows` handles rendering. It's not "real" shadows just the text redrawn with an offset and a different colour. Blur-radius support will need changes to the shaders and be a lot more complicated, whereas this still looks okay and took a couple of minutes to implement. I added the `TextShadow` component to `bevy_ui` rather than `bevy_text` because it only supports the UI atm. We can add a `Text2d` version in a followup but getting the same effect in `Text2d` is trivial even without official support. --- ## Showcase <img width="122" alt="text_shadow" src="https://github.com/user-attachments/assets/0333d167-c507-4262-b93b-b6d39e2cf3a4" /> <img width="136" alt="g" src="https://github.com/user-attachments/assets/9b01d5d9-55c9-4af7-9360-a7b04f55944d" />
# Objective - A common bevy pattern is to pre-allocate a weak `Handle` with a static, random ID and fill it during `Plugin::build` via `load_internal_asset!` - This requires generating a random 128-bit number that is interpreted as a UUID. This is much less convenient than generating a UUID directly, and also, strictly speaking, error prone, since it often results in an invalid UUIDv4 – they have to follow the pattern `xxxxxxxx-xxxx-4xxx-xxxx-xxxxxxxxxxxx`, where `x` is a random nibble (in practice this doesn't matter, since the UUID is just interpreted as a bag of bytes). ## Solution - Add a `weak_handle!` macro that internally calls [`uuid::uuid!`](https://docs.rs/uuid/1.12.0/uuid/macro.uuid.html) to parse a UUID from a string literal. - Now any random UUID generation tool can be used to generate an asset ID, such as `uuidgen` or entering "uuid" in DuckDuckGo. Previously: ```rust const SHADER: Handle<Shader> = Handle::weak_from_u128(314685653797097581405914117016993910609); ``` After this PR: ```rust const SHADER: Handle<Shader> = weak_handle!("1347c9b7-c46a-48e7-b7b8-023a354b7cac"); ``` Note that I did not yet migrate any of the existing uses. I can do that if desired, but want to have some feedback first to avoid wasted effort. ## Testing Tested via the included doctest.
…evyengine#17685) # Objective - Fixes bevyengine#17411 ## Solution - Deprecated `Component::register_component_hooks` - Added individual methods for each hook which return `None` if the hook is unused. ## Testing - CI --- ## Migration Guide `Component::register_component_hooks` is now deprecated and will be removed in a future release. When implementing `Component` manually, also implement the respective hook methods on `Component`. ```rust // Before impl Component for Foo { // snip fn register_component_hooks(hooks: &mut ComponentHooks) { hooks.on_add(foo_on_add); } } // After impl Component for Foo { // snip fn on_add() -> Option<ComponentHook> { Some(foo_on_add) } } ``` ## Notes I've chosen to deprecate `Component::register_component_hooks` rather than outright remove it to ease the migration guide. While it is in a state of deprecation, it must be used by `Components::register_component_internal` to ensure users who haven't migrated to the new hook definition scheme aren't left behind. For users of the new scheme, a default implementation of `Component::register_component_hooks` is provided which forwards the new individual hook implementations. Personally, I think this is a cleaner API to work with, and would allow the documentation for hooks to exist on the respective `Component` methods (e.g., documentation for `OnAdd` can exist on `Component::on_add`). Ideally, `Component::on_add` would be the hook itself rather than a getter for the hook, but it is the only way to early-out for a no-op hook, which is important for performance. ## Migration Guide `Component::register_component_hooks` has been deprecated. If you are manually implementing the `Component` trait and registering hooks there, use the individual methods such as `on_add` instead for increased clarity.
# Objective Progresses bevyengine#17569. The end goal here is to synchronize component registration. See the other PR for details for the motivation behind that. For this PR specifically, the objective is to decouple `Components` from `Storages`. What components are registered etc should have nothing to do with what Storages looks like. Storages should only care about what entity archetypes have been spawned. ## Solution Previously, this was used to create sparse sets for relevant components when those components were registered. Now, we do that when the component is inserted/spawned. This PR proposes doing that in `BundleInfo::new`, but there may be a better place. ## Testing In theory, this shouldn't have changed any functionality, so no new tests were created. I'm not aware of any examples that make heavy use of sparse set components either. ## Migration Guide - Remove storages from functions where it is no longer needed. - Note that SparseSets are no longer present for all registered sparse set components, only those that have been spawned. --------- Co-authored-by: SpecificProtagonist <[email protected]> Co-authored-by: Chris Russell <[email protected]>
# Objective Add a mesh with a more regular shape to visualize the anisotropy effect. ## Solution Add a `Sphere` to the scene. ## Testing Ran `anisotropy` example ## Showcase   Note: defects are already mentioned on bevyengine#16179
…ine#17675) # Objective There was a bug in the default `Relationship::on_insert` implementation that caused it to not properly handle entities targeting themselves in relationships. The relationship component was properly removed, but it would go on to add itself to its own target component. ## Solution Added a missing `return` and a couple of tests (`self_relationship_fails` failed on its second assert prior to this PR). ## Testing See above.
# Objective - Make use of the new `weak_handle!` macro added in bevyengine#17384 ## Solution - Migrate bevy from `Handle::weak_from_u128` to the new `weak_handle!` macro that takes a random UUID - Deprecate `Handle::weak_from_u128`, since there are no remaining use cases that can't also be addressed by constructing the type manually ## Testing - `cargo run -p ci -- test` --- ## Migration Guide Replace `Handle::weak_from_u128` with `weak_handle!` and a random UUID.
# Objective Create a minimal example of how to modify the material from a `Gltf`. This is frequently asked about on the help channel of the discord. ## Solution Create the example. ## Showcase 
# Objective This is a follow up to bevyengine#9822, which automatically adds sync points during the Schedule build process. However, the implementation in bevyengine#9822 feels very "special case" to me. As the number of things we want to do with the `Schedule` grows, we need a modularized way to manage those behaviors. For example, in one of my current experiments I want to automatically add systems to apply GPU pipeline barriers between systems accessing GPU resources. For dynamic modifications of the schedule, we mostly need these capabilities: - Storing custom data on schedule edges - Storing custom data on schedule nodes - Modify the schedule graph whenever it builds These should be enough to allows us to add "hooks" to the schedule build process for various reasons. cc @hymm ## Solution This PR abstracts the process of schedule modification and created a new trait, `ScheduleBuildPass`. Most of the logics in bevyengine#9822 were moved to an implementation of `ScheduleBuildPass`, `AutoInsertApplyDeferredPass`. Whether a dependency edge should "ignore deferred" is now indicated by the presence of a marker struct, `IgnoreDeferred`. This PR has no externally visible effects. However, in a future PR I propose to change the `before_ignore_deferred` and `after_ignore_deferred` API into a more general form, `before_with_options` and `after_with_options`. ```rs schedule.add_systems( system.before_with_options(another_system, IgnoreDeferred) ); schedule.add_systems( system.before_with_options(another_system, ( IgnoreDeferred, AnyOtherOption { key: value } )) ); schedule.add_systems( system.before_with_options(another_system, ()) ); ```
Fixes bevyengine#17535 Bevy's approach to handling "entity mapping" during spawning and cloning needs some work. The addition of [Relations](bevyengine#17398) both [introduced a new "duplicate entities" bug when spawning scenes in the scene system](bevyengine#17535) and made the weaknesses of the current mapping system exceedingly clear: 1. Entity mapping requires _a ton_ of boilerplate (implement or derive VisitEntities and VisitEntitesMut, then register / reflect MapEntities). Knowing the incantation is challenging and if you forget to do it in part or in whole, spawning subtly breaks. 2. Entity mapping a spawned component in scenes incurs unnecessary overhead: look up ReflectMapEntities, create a _brand new temporary instance_ of the component using FromReflect, map the entities in that instance, and then apply that on top of the actual component using reflection. We can do much better. Additionally, while our new [Entity cloning system](bevyengine#16132) is already pretty great, it has some areas we can make better: * It doesn't expose semantic info about the clone (ex: ignore or "clone empty"), meaning we can't key off of that in places where it would be useful, such as scene spawning. Rather than duplicating this info across contexts, I think it makes more sense to add that info to the clone system, especially given that we'd like to use cloning code in some of our spawning scenarios. * EntityCloner is currently built in a way that prioritizes a single entity clone * EntityCloner's recursive cloning is built to be done "inside out" in a parallel context (queue commands that each have a clone of EntityCloner). By making EntityCloner the orchestrator of the clone we can remove internal arcs, improve the clarity of the code, make EntityCloner mutable again, and simplify the builder code. * EntityCloner does not currently take into account entity mapping. This is necessary to do true "bullet proof" cloning, would allow us to unify the per-component scene spawning and cloning UX, and ultimately would allow us to use EntityCloner in place of raw reflection for scenes like `Scene(World)` (which would give us a nice performance boost: fewer archetype moves, less reflection overhead). ## Solution ### Improved Entity Mapping First, components now have first-class "entity visiting and mapping" behavior: ```rust #[derive(Component, Reflect)] #[reflect(Component)] struct Inventory { size: usize, #[entities] items: Vec<Entity>, } ``` Any field with the `#[entities]` annotation will be viewable and mappable when cloning and spawning scenes. Compare that to what was required before! ```rust #[derive(Component, Reflect, VisitEntities, VisitEntitiesMut)] #[reflect(Component, MapEntities)] struct Inventory { #[visit_entities(ignore)] size: usize, items: Vec<Entity>, } ``` Additionally, for relationships `#[entities]` is implied, meaning this "just works" in scenes and cloning: ```rust #[derive(Component, Reflect)] #[relationship(relationship_target = Children)] #[reflect(Component)] struct ChildOf(pub Entity); ``` Note that Component _does not_ implement `VisitEntities` directly. Instead, it has `Component::visit_entities` and `Component::visit_entities_mut` methods. This is for a few reasons: 1. We cannot implement `VisitEntities for C: Component` because that would conflict with our impl of VisitEntities for anything that implements `IntoIterator<Item=Entity>`. Preserving that impl is more important from a UX perspective. 2. We should not implement `Component: VisitEntities` VisitEntities in the Component derive, as that would increase the burden of manual Component trait implementors. 3. Making VisitEntitiesMut directly callable for components would make it easy to invalidate invariants defined by a component author. By putting it in the `Component` impl, we can make it harder to call naturally / unavailable to autocomplete using `fn visit_entities_mut(this: &mut Self, ...)`. `ReflectComponent::apply_or_insert` is now `ReflectComponent::apply_or_insert_mapped`. By moving mapping inside this impl, we remove the need to go through the reflection system to do entity mapping, meaning we no longer need to create a clone of the target component, map the entities in that component, and patch those values on top. This will make spawning mapped entities _much_ faster (The default `Component::visit_entities_mut` impl is an inlined empty function, so it will incur no overhead for unmapped entities). ### The Bug Fix To solve bevyengine#17535, spawning code now skips entities with the new `ComponentCloneBehavior::Ignore` and `ComponentCloneBehavior::RelationshipTarget` variants (note RelationshipTarget is a temporary "workaround" variant that allows scenes to skip these components. This is a temporary workaround that can be removed as these cases should _really_ be using EntityCloner logic, which should be done in a followup PR. When that is done, `ComponentCloneBehavior::RelationshipTarget` can be merged into the normal `ComponentCloneBehavior::Custom`). ### Improved Cloning * `Option<ComponentCloneHandler>` has been replaced by `ComponentCloneBehavior`, which encodes additional intent and context (ex: `Default`, `Ignore`, `Custom`, `RelationshipTarget` (this last one is temporary)). * Global per-world entity cloning configuration has been removed. This felt overly complicated, increased our API surface, and felt too generic. Each clone context can have different requirements (ex: what a user wants in a specific system, what a scene spawner wants, etc). I'd prefer to see how far context-specific EntityCloners get us first. * EntityCloner's internals have been reworked to remove Arcs and make it mutable. * EntityCloner is now directly stored on EntityClonerBuilder, simplifying the code somewhat * EntityCloner's "bundle scratch" pattern has been moved into the new BundleScratch type, improving its usability and making it usable in other contexts (such as future cross-world cloning code). Currently this is still private, but with some higher level safe APIs it could be used externally for making dynamic bundles * EntityCloner's recursive cloning behavior has been "externalized". It is now responsible for orchestrating recursive clones, meaning it no longer needs to be sharable/clone-able across threads / read-only. * EntityCloner now does entity mapping during clones, like scenes do. This gives behavior parity and also makes it more generically useful. * `RelatonshipTarget::RECURSIVE_SPAWN` is now `RelationshipTarget::LINKED_SPAWN`, and this field is used when cloning relationship targets to determine if cloning should happen recursively. The new `LINKED_SPAWN` term was picked to make it more generically applicable across spawning and cloning scenarios. ## Next Steps * I think we should adapt EntityCloner to support cross world cloning. I think this PR helps set the stage for that by making the internals slightly more generalized. We could have a CrossWorldEntityCloner that reuses a lot of this infrastructure. * Once we support cross world cloning, we should use EntityCloner to spawn `Scene(World)` scenes. This would yield significant performance benefits (no archetype moves, less reflection overhead). --------- Co-authored-by: eugineerd <[email protected]> Co-authored-by: Alice Cecile <[email protected]>
# Objective Fixes bevyengine#17718 ## Solution Schedule `text_system` before `AssetEvents`. I guess what was happening here is that glyphs weren't shown because `text_system` was running before `AssetEevents` and so `prepare_uinodes` never recieves the the asset modified event about the glyph texture atlas image.
…ine#17738) Right now, meshes aren't grouped together based on the bindless texture slab when drawing shadows. This manifests itself as flickering in Bistro. I believe that there are two causes of this: 1. Alpha masked shadows may try to sample from the wrong texture, causing the alpha mask to appear and disappear. 2. Objects may try to sample from the blank textures that we pad out the bindless slabs with, causing them to vanish intermittently. This commit fixes the issue by including the material bind group ID as part of the shadow batch set key, just as we do for the prepass and main pass.
# Objective The docs of `EaseFunction` don't visualize the different functions, requiring you to check out the Bevy repo and running the `easing_function` example. ## Solution - Add tool to generate suitable svg graphs. This only needs to be re-run when adding new ease functions. - works with all themes - also add missing easing functions to example. --- ## Showcase  --------- Co-authored-by: François Mockers <[email protected]>
{kind=link}
# Objective After bevyengine#17461, the ease function labels in this example are a bit cramped, especially in the bottom row. This adjusts the spacing slightly and centers the labels. ## Solution - The label is now a child of the plot and they are drawn around the center of the transform - Plot size and extents are now constants, and this thing has been banished: ```rust i as f32 * 95.0 - 1280.0 / 2.0 + 25.0, -100.0 - ((j as f32 * 250.0) - 300.0), 0.0, ``` - There's room for expansion in another row, so make that easier by doing the chunking by row - Other misc tidying of variable names, sprinkled in a few comments, etc. ## Before <img width="1280" alt="Screenshot 2025-02-08 at 7 33 14 AM" src="https://github.com/user-attachments/assets/0b79c619-d295-4ab1-8cd1-d23c862d06c5" /> ## After <img width="1280" alt="Screenshot 2025-02-08 at 7 32 45 AM" src="https://github.com/user-attachments/assets/656ef695-9aa8-42e9-b867-1718294316bd" />
# Objective While working on bevyengine#17742, I noticed that the `Steps` easing function looked a bit suspicious. 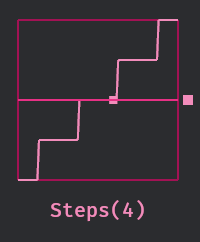 Comparing to the options available in [css](https://developer.mozilla.org/en-US/docs/Web/CSS/easing-function/steps#description): 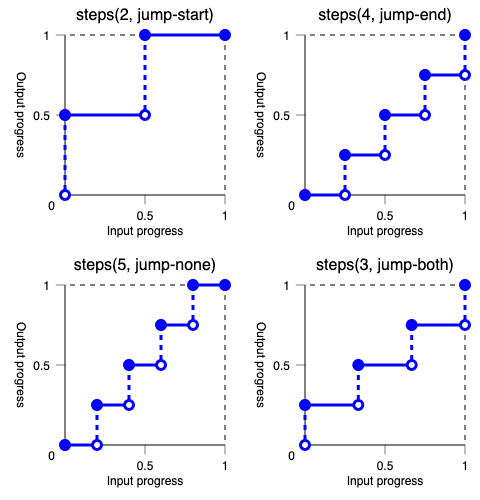 It is "off the charts," so probably not what users are expecting. ## Solution Use `floor` when rounding to match the default behavior (jump-end, top right) in css. <img width="100" alt="image" src="https://github.com/user-attachments/assets/1ec46270-72f2-4227-87e4-03de881548ab" /> ## Testing I had to modify an existing test that was testing against the old behavior. This function and test were introduced in bevyengine#14788 and I didn't see any discussion about the rounding there. `cargo run --example easing_functions` ## Migration Guide <!-- Note to editors: this should be adjusted if 17744 is addressed, and possibly combined with the notes from the PR that fixes it. --> `EaseFunction::Steps` now behaves like css's default, "jump-end." If you were relying on the old behavior, we plan on providing it. See bevyengine#17744.
This PR makes Bevy keep entities in bins from frame to frame if they haven't changed. This reduces the time spent in `queue_material_meshes` and related functions to near zero for static geometry. This patch uses the same change tick technique that bevyengine#17567 uses to detect when meshes have changed in such a way as to require re-binning. In order to quickly find the relevant bin for an entity when that entity has changed, we introduce a new type of cache, the *bin key cache*. This cache stores a mapping from main world entity ID to cached bin key, as well as the tick of the most recent change to the entity. As we iterate through the visible entities in `queue_material_meshes`, we check the cache to see whether the entity needs to be re-binned. If it doesn't, then we mark it as clean in the `valid_cached_entity_bin_keys` bit set. If it does, then we insert it into the correct bin, and then mark the entity as clean. At the end, all entities not marked as clean are removed from the bins. This patch has a dramatic effect on the rendering performance of most benchmarks, as it effectively eliminates `queue_material_meshes` from the profile. Note, however, that it generally simultaneously regresses `batch_and_prepare_binned_render_phase` by a bit (not by enough to outweigh the win, however). I believe that's because, before this patch, `queue_material_meshes` put the bins in the CPU cache for `batch_and_prepare_binned_render_phase` to use, while with this patch, `batch_and_prepare_binned_render_phase` must load the bins into the CPU cache itself. On Caldera, this reduces the time spent in `queue_material_meshes` from 5+ ms to 0.2ms-0.3ms. Note that benchmarking on that scene is very noisy right now because of bevyengine#17535. 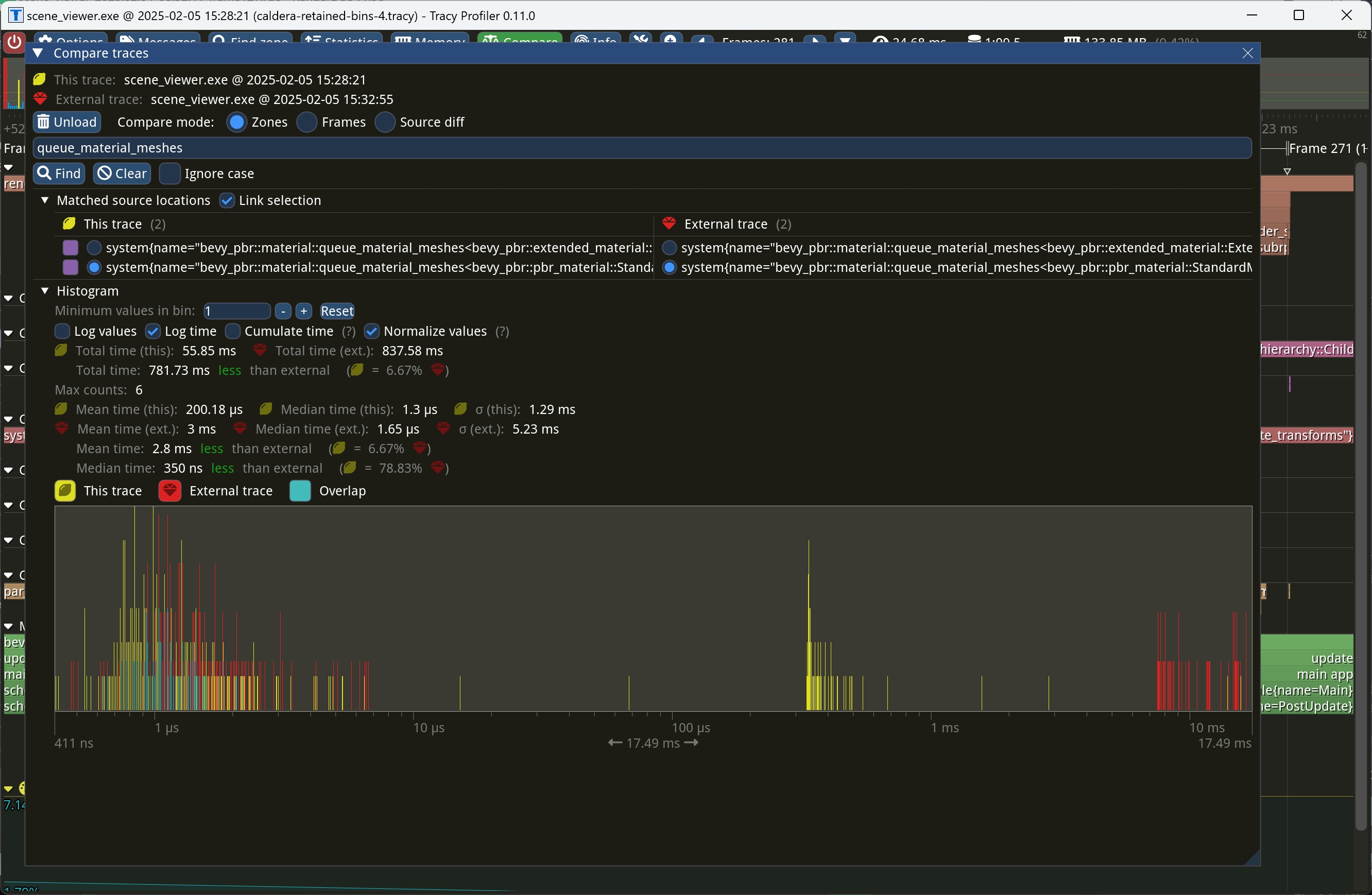
…light's render world entity. (bevyengine#17749) Right now, we key the cached light change ticks off the `LightEntity`. This uses the render world entity, which isn't stable between frames. Thus in practice few shadows are retained from frame to frame. This PR fixes the issue by keying off the `RetainedViewEntity` instead, which is designed to be stable from frame to frame.
) PR bevyengine#17684 broke occlusion culling because it neglected to set the indirect parameter offsets for the late mesh preprocessing stage if the work item buffers were already set. This PR moves the update of those values to a new function, `init_work_item_buffers`, which is unconditionally called for every phase every frame. Note that there's some complexity in order to handle the case in which occlusion culling was enabled on one frame and disabled on the next, or vice versa. This was necessary in order to make the occlusion culling toggle in the `occlusion_culling` example work again.
…bevyengine#17735) # Objective - Add command encoding parallelization to transparent 2d pass render node. - Improves bevyengine#17733 ## Solution Using functionality added in bevyengine#9172 ## Testing - Tested in personal project where multiple cameras are rendered with objects rendered in transparent 2d pass.
# Objective Things were breaking post-cs. ## Solution `specialize_mesh_materials` must run after `collect_meshes_for_gpu_building`. Therefore, its placement in the `PrepareAssets` set didn't make sense (also more generally). To fix, we put this class of system in ~`PrepareResources`~ `QueueMeshes`, although it potentially could use a more descriptive location. We may want to review the placement of `check_views_need_specialization` which is also currently in `PrepareAssets`.
# Objective - publish script copy the license files to all subcrates, meaning that all publish are dirty. this breaks git verification of crates - the order and list of crates to publish is manually maintained, leading to error. cargo 1.84 is more strict and the list is currently wrong ## Solution - duplicate all the licenses to all crates and remove the `--allow-dirty` flag - instead of a manual list of crates, get it from `cargo package --workspace` - remove the `--no-verify` flag to... verify more things?
…gine#17741) Fix bevyengine#16477. - Remove temporary silence introduced in bevyengine#16763 - bump version of `notify-debouncer-full` to remove transitive dependency on `instant` crate.
# Objective The entity disabling / default query filter work added in bevyengine#17514 and bevyengine#13120 is neat, but we don't teach users how it works! We should fix that before 0.16. ## Solution Write a simple example to teach the basics of entity disabling! ## Testing `cargo run --example entity_disabling` ## Showcase  --------- Co-authored-by: Zachary Harrold <[email protected]>
Didn't remove WgpuWrapper. Not sure if it's needed or not still. ## Testing - Did you test these changes? If so, how? Example runner - Are there any parts that need more testing? Web (portable atomics thingy?), DXC. ## Migration Guide - Bevy has upgraded to [wgpu v24](https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md#v2400-2025-01-15). - When using the DirectX 12 rendering backend, the new priority system for choosing a shader compiler is as follows: - If the `WGPU_DX12_COMPILER` environment variable is set at runtime, it is used - Else if the new `statically-linked-dxc` feature is enabled, a custom version of DXC will be statically linked into your app at compile time. - Else Bevy will look in the app's working directory for `dxcompiler.dll` and `dxil.dll` at runtime. - Else if they are missing, Bevy will fall back to FXC (not recommended) --------- Co-authored-by: Alice Cecile <[email protected]> Co-authored-by: IceSentry <[email protected]> Co-authored-by: François Mockers <[email protected]>
…ine#17330) This pr uses the `extern crate self as` trick to make proc macros behave the same way inside and outside bevy. - Removes noise introduced by `crate as` in the whole bevy repo. - Fixes bevyengine#17004. - Hardens proc macro path resolution. - [x] `BevyManifest` needs cleanup. - [x] Cleanup remaining `crate as`. - [x] Add proper integration tests to the ci. - `cargo-manifest-proc-macros` is written by me and based/inspired by the old `BevyManifest` implementation and [`bkchr/proc-macro-crate`](https://github.com/bkchr/proc-macro-crate). - What do you think about the new integration test machinery I added to the `ci`? More and better integration tests can be added at a later stage. The goal of these integration tests is to simulate an actual separate crate that uses bevy. Ideally they would lightly touch all bevy crates. - Needs RA test - Needs testing from other users - Others need to run at least `cargo run -p ci integration-test` and verify that they work. --------- Co-authored-by: Alice Cecile <[email protected]>
# Objective Solves bevyengine#17747. ## Solution - Adds an example for creating a default value for Local. ## Testing - Example code compiles and passes assertions.
## Objective
A major critique of Bevy at the moment is how boilerplatey it is to
compose (and read) entity hierarchies:
```rust
commands
.spawn(Foo)
.with_children(|p| {
p.spawn(Bar).with_children(|p| {
p.spawn(Baz);
});
p.spawn(Bar).with_children(|p| {
p.spawn(Baz);
});
});
```
There is also currently no good way to statically define and return an
entity hierarchy from a function. Instead, people often do this
"internally" with a Commands function that returns nothing, making it
impossible to spawn the hierarchy in other cases (direct World spawns,
ChildSpawner, etc).
Additionally, because this style of API results in creating the
hierarchy bits _after_ the initial spawn of a bundle, it causes ECS
archetype changes (and often expensive table moves).
Because children are initialized after the fact, we also can't count
them to pre-allocate space. This means each time a child inserts itself,
it has a high chance of overflowing the currently allocated capacity in
the `RelationshipTarget` collection, causing literal worst-case
reallocations.
We can do better!
## Solution
The Bundle trait has been extended to support an optional
`BundleEffect`. This is applied directly to World immediately _after_
the Bundle has fully inserted. Note that this is
[intentionally](bevyengine#16920)
_not done via a deferred Command_, which would require repeatedly
copying each remaining subtree of the hierarchy to a new command as we
walk down the tree (_not_ good performance).
This allows us to implement the new `SpawnRelated` trait for all
`RelationshipTarget` impls, which looks like this in practice:
```rust
world.spawn((
Foo,
Children::spawn((
Spawn((
Bar,
Children::spawn(Spawn(Baz)),
)),
Spawn((
Bar,
Children::spawn(Spawn(Baz)),
)),
))
))
```
`Children::spawn` returns `SpawnRelatedBundle<Children, L:
SpawnableList>`, which is a `Bundle` that inserts `Children`
(preallocated to the size of the `SpawnableList::size_hint()`).
`Spawn<B: Bundle>(pub B)` implements `SpawnableList` with a size of 1.
`SpawnableList` is also implemented for tuples of `SpawnableList` (same
general pattern as the Bundle impl).
There are currently three built-in `SpawnableList` implementations:
```rust
world.spawn((
Foo,
Children::spawn((
Spawn(Name::new("Child1")),
SpawnIter(["Child2", "Child3"].into_iter().map(Name::new),
SpawnWith(|parent: &mut ChildSpawner| {
parent.spawn(Name::new("Child4"));
parent.spawn(Name::new("Child5"));
})
)),
))
```
We get the benefits of "structured init", but we have nice flexibility
where it is required!
Some readers' first instinct might be to try to remove the need for the
`Spawn` wrapper. This is impossible in the Rust type system, as a tuple
of "child Bundles to be spawned" and a "tuple of Components to be added
via a single Bundle" is ambiguous in the Rust type system. There are two
ways to resolve that ambiguity:
1. By adding support for variadics to the Rust type system (removing the
need for nested bundles). This is out of scope for this PR :)
2. Using wrapper types to resolve the ambiguity (this is what I did in
this PR).
For the single-entity spawn cases, `Children::spawn_one` does also
exist, which removes the need for the wrapper:
```rust
world.spawn((
Foo,
Children::spawn_one(Bar),
))
```
## This works for all Relationships
This API isn't just for `Children` / `ChildOf` relationships. It works
for any relationship type, and they can be mixed and matched!
```rust
world.spawn((
Foo,
Observers::spawn((
Spawn(Observer::new(|trigger: Trigger<FuseLit>| {})),
Spawn(Observer::new(|trigger: Trigger<Exploded>| {})),
)),
OwnerOf::spawn(Spawn(Bar))
Children::spawn(Spawn(Baz))
))
```
## Macros
While `Spawn` is necessary to satisfy the type system, we _can_ remove
the need to express it via macros. The example above can be expressed
more succinctly using the new `children![X]` macro, which internally
produces `Children::spawn(Spawn(X))`:
```rust
world.spawn((
Foo,
children![
(
Bar,
children![Baz],
),
(
Bar,
children![Baz],
),
]
))
```
There is also a `related!` macro, which is a generic version of the
`children!` macro that supports any relationship type:
```rust
world.spawn((
Foo,
related!(Children[
(
Bar,
related!(Children[Baz]),
),
(
Bar,
related!(Children[Baz]),
),
])
))
```
## Returning Hierarchies from Functions
Thanks to these changes, the following pattern is now possible:
```rust
fn button(text: &str, color: Color) -> impl Bundle {
(
Node {
width: Val::Px(300.),
height: Val::Px(100.),
..default()
},
BackgroundColor(color),
children![
Text::new(text),
]
)
}
fn ui() -> impl Bundle {
(
Node {
width: Val::Percent(100.0),
height: Val::Percent(100.0),
..default(),
},
children![
button("hello", BLUE),
button("world", RED),
]
)
}
// spawn from a system
fn system(mut commands: Commands) {
commands.spawn(ui());
}
// spawn directly on World
world.spawn(ui());
```
## Additional Changes and Notes
* `Bundle::from_components` has been split out into
`BundleFromComponents::from_components`, enabling us to implement
`Bundle` for types that cannot be "taken" from the ECS (such as the new
`SpawnRelatedBundle`).
* The `NoBundleEffect` trait (which implements `BundleEffect`) is
implemented for empty tuples (and tuples of empty tuples), which allows
us to constrain APIs to only accept bundles that do not have effects.
This is critical because the current batch spawn APIs cannot efficiently
apply BundleEffects in their current form (as doing so in-place could
invalidate the cached raw pointers). We could consider allocating a
buffer of the effects to be applied later, but that does have
performance implications that could offset the balance and value of the
batched APIs (and would likely require some refactors to the underlying
code). I've decided to be conservative here. We can consider relaxing
that requirement on those APIs later, but that should be done in a
followup imo.
* I've ported a few examples to illustrate real-world usage. I think in
a followup we should port all examples to the `children!` form whenever
possible (and for cases that require things like SpawnIter, use the raw
APIs).
* Some may ask "why not use the `Relationship` to spawn (ex:
`ChildOf::spawn(Foo)`) instead of the `RelationshipTarget` (ex:
`Children::spawn(Spawn(Foo))`)?". That _would_ allow us to remove the
`Spawn` wrapper. I've explicitly chosen to disallow this pattern.
`Bundle::Effect` has the ability to create _significant_ weirdness.
Things in `Bundle` position look like components. For example
`world.spawn((Foo, ChildOf::spawn(Bar)))` _looks and reads_ like Foo is
a child of Bar. `ChildOf` is in Foo's "component position" but it is not
a component on Foo. This is a huge problem. Now that `Bundle::Effect`
exists, we should be _very_ principled about keeping the "weird and
unintuitive behavior" to a minimum. Things that read like components
_should be the components they appear to be".
## Remaining Work
* The macros are currently trivially implemented using macro_rules and
are currently limited to the max tuple length. They will require a
proc_macro implementation to work around the tuple length limit.
## Next Steps
* Port the remaining examples to use `children!` where possible and raw
`Spawn` / `SpawnIter` / `SpawnWith` where the flexibility of the raw API
is required.
## Migration Guide
Existing spawn patterns will continue to work as expected.
Manual Bundle implementations now require a `BundleEffect` associated
type. Exisiting bundles would have no bundle effect, so use `()`.
Additionally `Bundle::from_components` has been moved to the new
`BundleFromComponents` trait.
```rust
// Before
unsafe impl Bundle for X {
unsafe fn from_components<T, F>(ctx: &mut T, func: &mut F) -> Self {
}
/* remaining bundle impl here */
}
// After
unsafe impl Bundle for X {
type Effect = ();
/* remaining bundle impl here */
}
unsafe impl BundleFromComponents for X {
unsafe fn from_components<T, F>(ctx: &mut T, func: &mut F) -> Self {
}
}
```
---------
Co-authored-by: Alice Cecile <[email protected]>
Co-authored-by: Gino Valente <[email protected]>
Co-authored-by: Emerson Coskey <[email protected]>
|
Closinng in favor of a fresh pr with clean commit history: #17889 |
Objective
bevy_web_asset, allowing assets loaded viahttp#16307Solution
http&httpsasset sourcesTesting
cargo run --example http_sourceShowcase
Bevy now supports assets loaded via url!
Add the
http_sourcefeature to load assets served over the web, with support for both native and wasm targets. On native targets thehttp_source_cachefeature will use a basic caching mechanism to avoid repeated network requests.