We are currently in the process of organizing our code, and will release the code on GitHub upon acceptance of the paper.
Stay tuned for updates!
Zihao Sheng1,*, Zilin Huang1,*, Yansong Qu2, Yue Leng3, Sruthi Bhavanam3, Sikai Chen1,✉
1University of Wisconsin-Madison, 2Purdue University, 3Google
*Equally Contributing First Authors, ✉Corresponding Author
🔥 To the best of our knowledge, CurricuVLM is the first work to utilize VLMs for dynamic curriculum generation in closed-loop autonomous driving training.
🏁 CurricuVLM outperforms state-of-the-art baselines, across both regular and safety-critical scenarios, achieving superior performance in terms of navigation success, driving efficiency, and safety metrics..
| Case 1 | Case 2 | Case 3 | Case 4 | Case 5 |
|---|---|---|---|---|
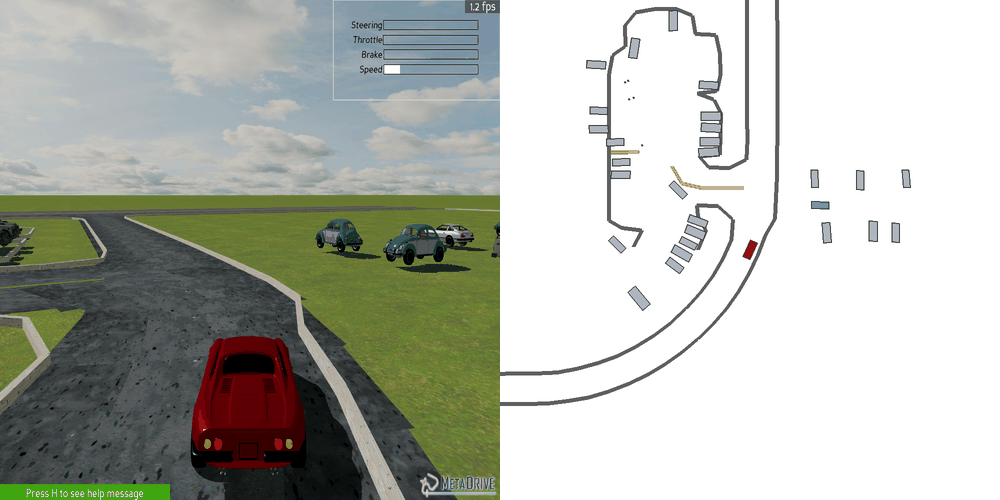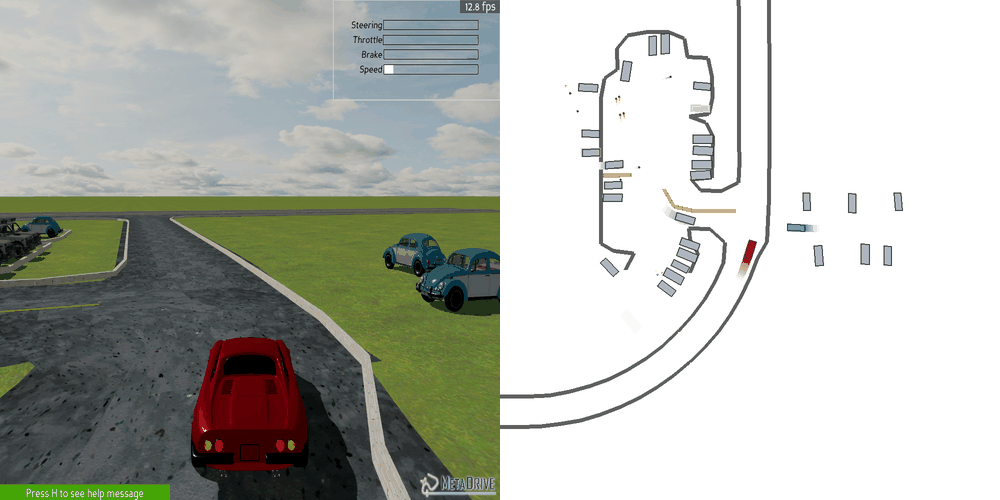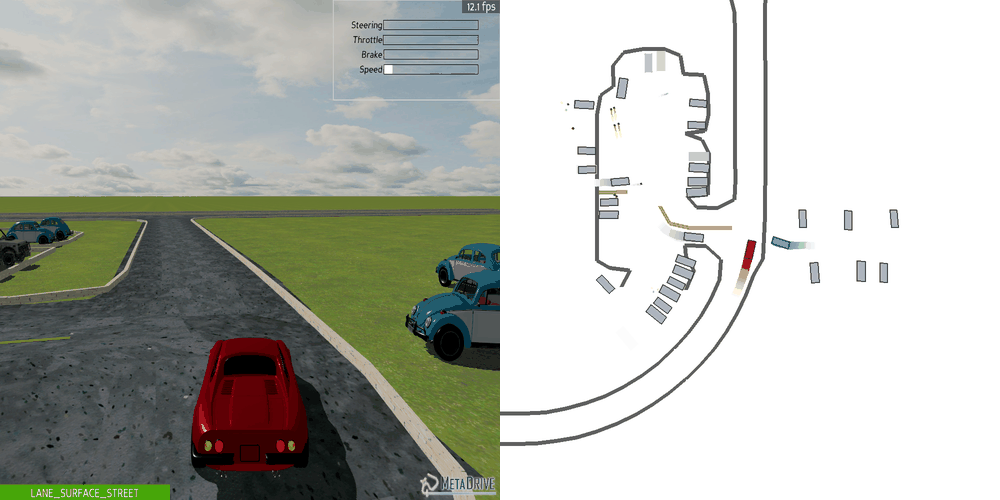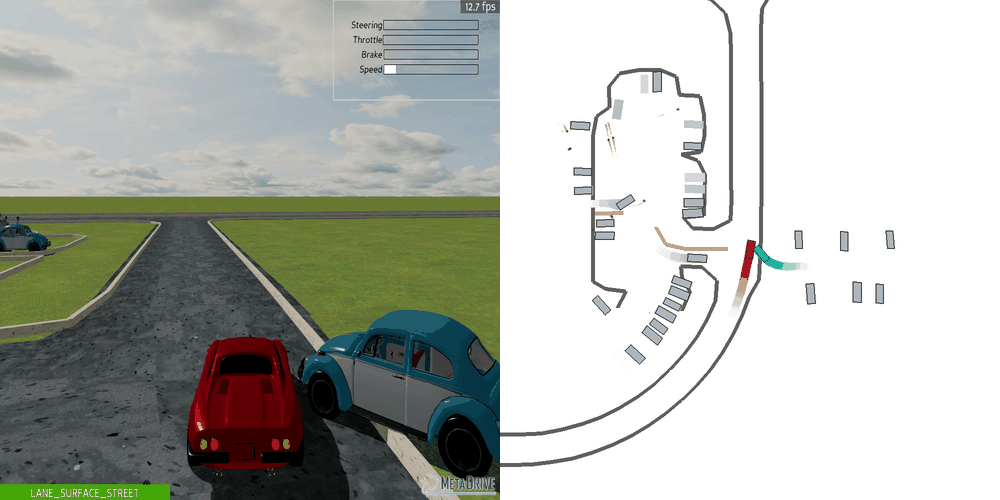 |
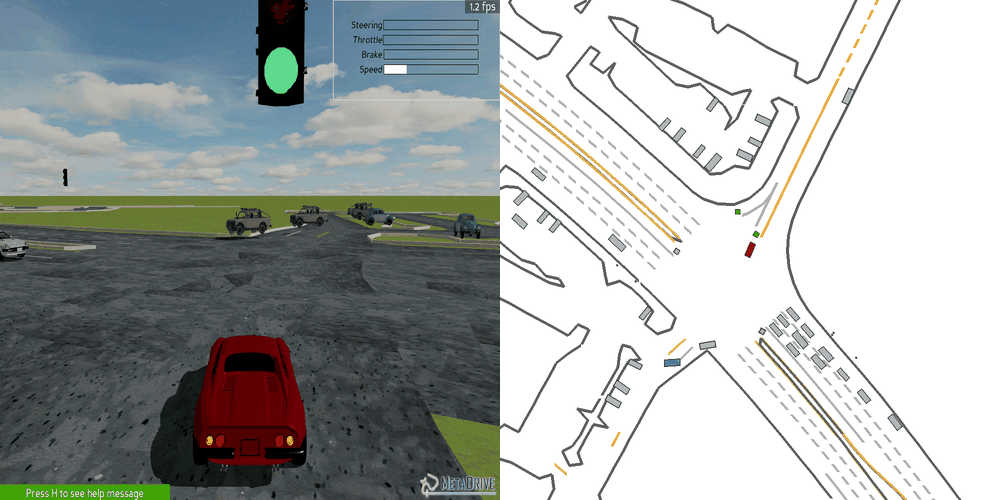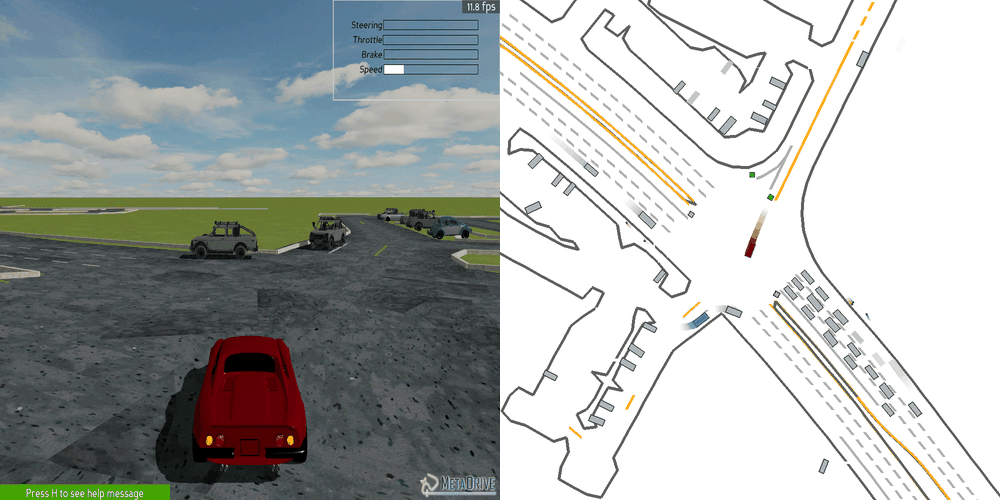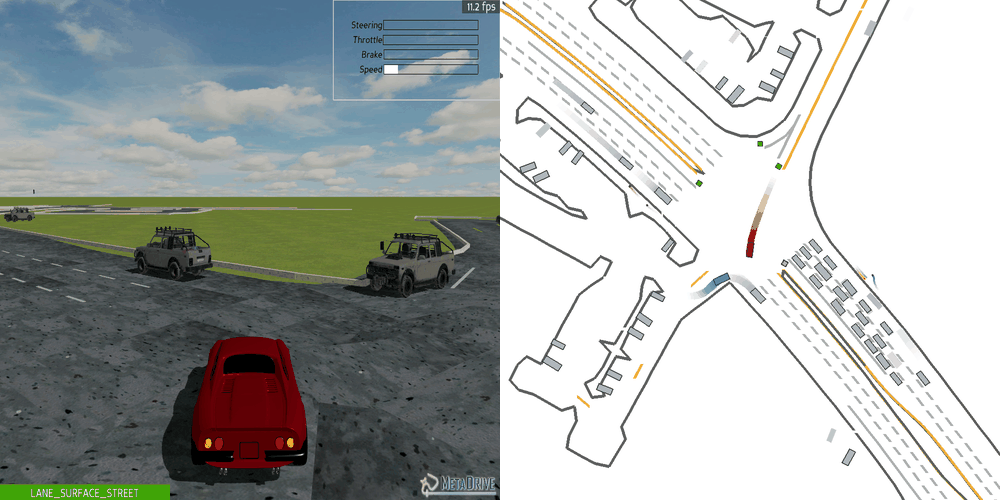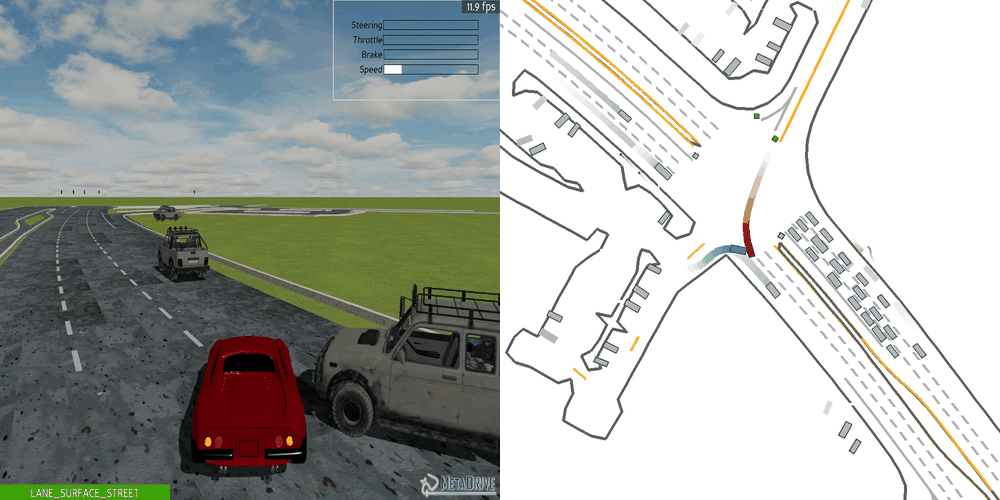 |
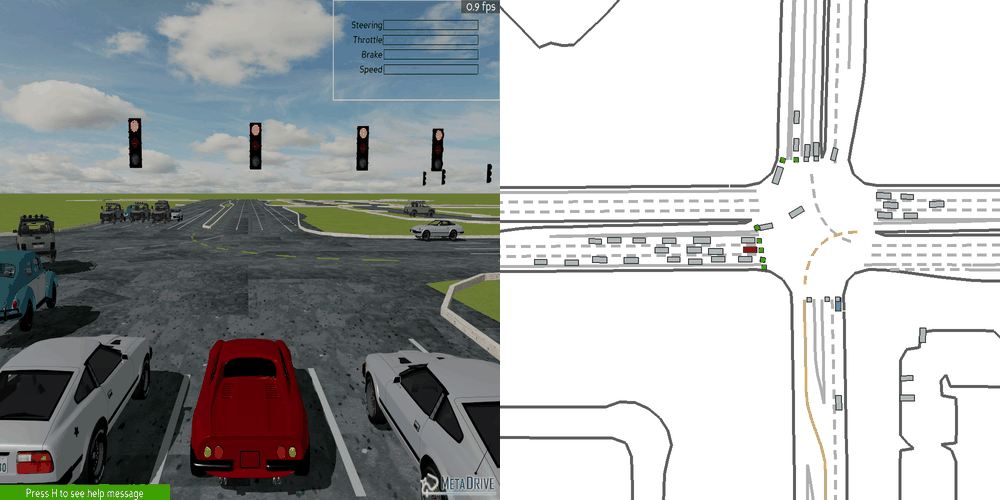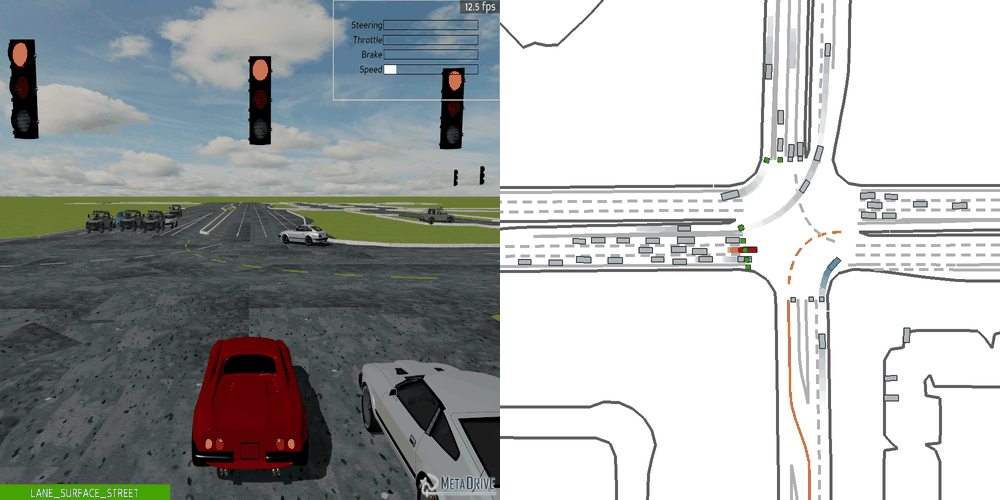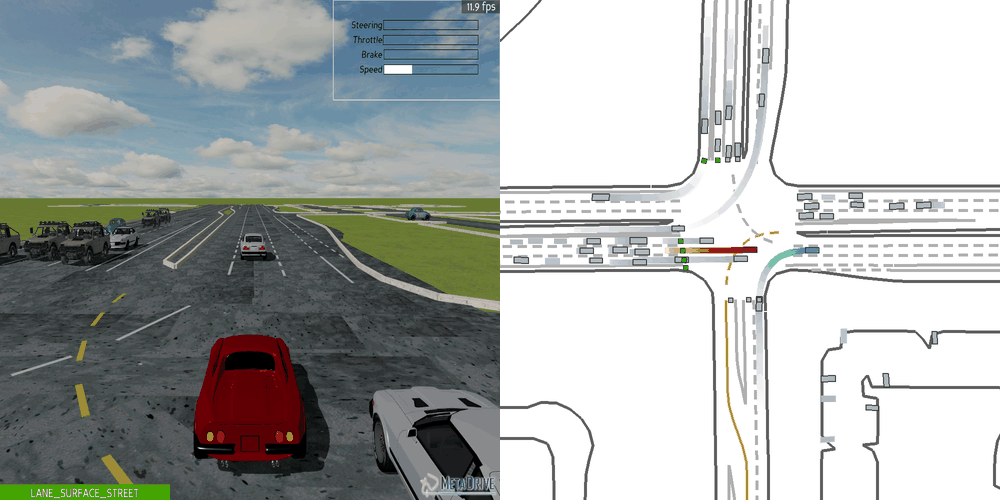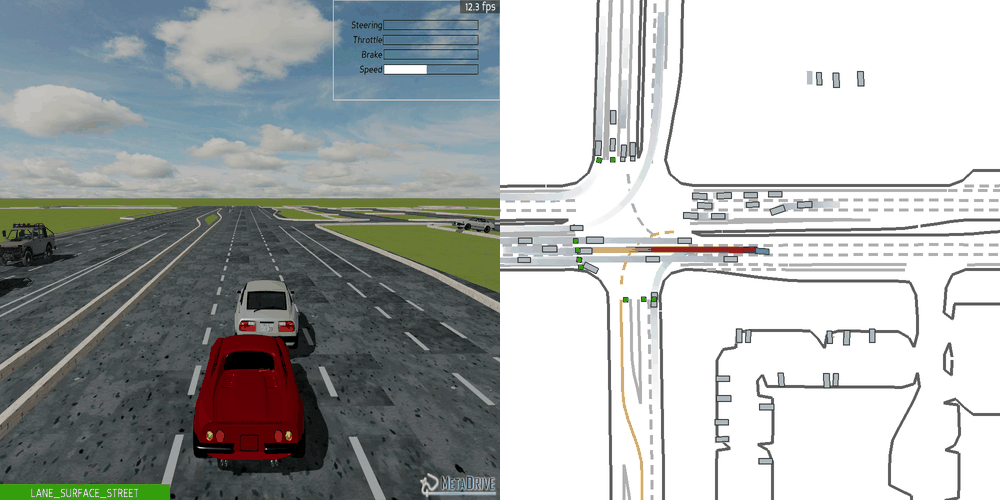 |
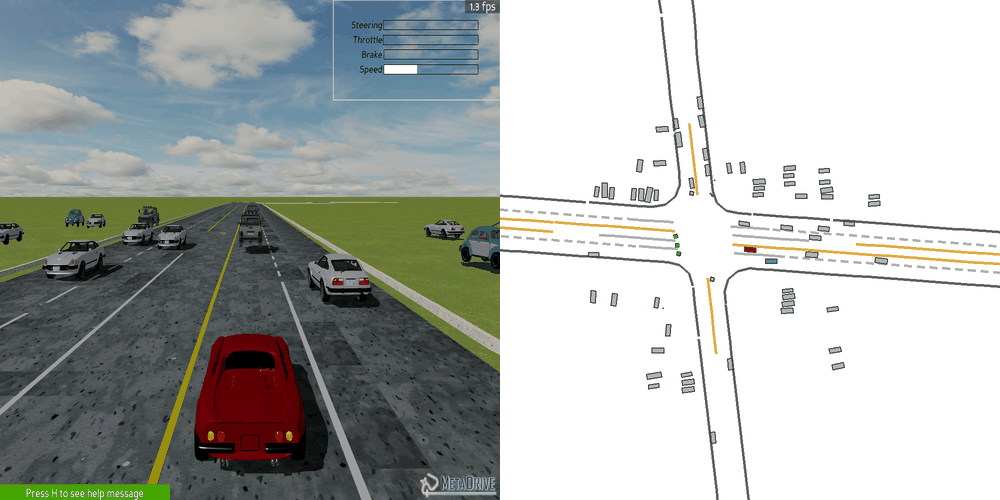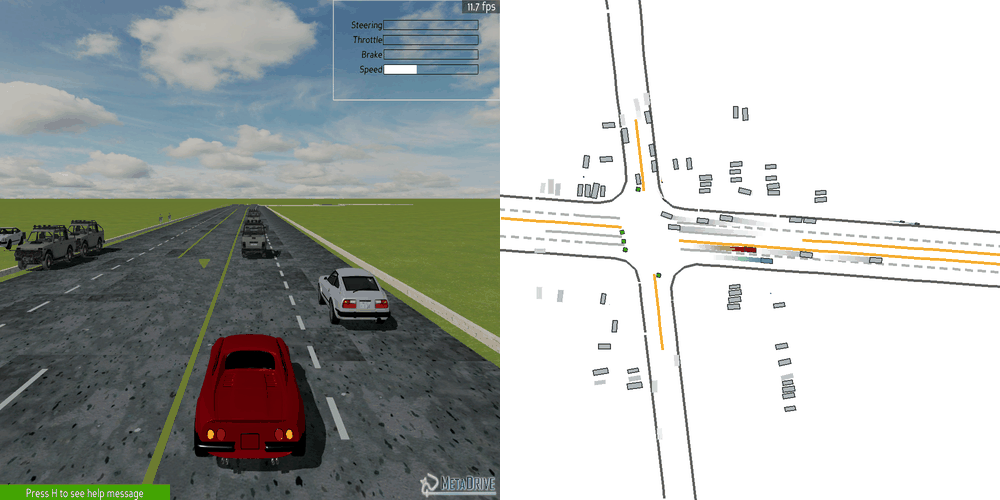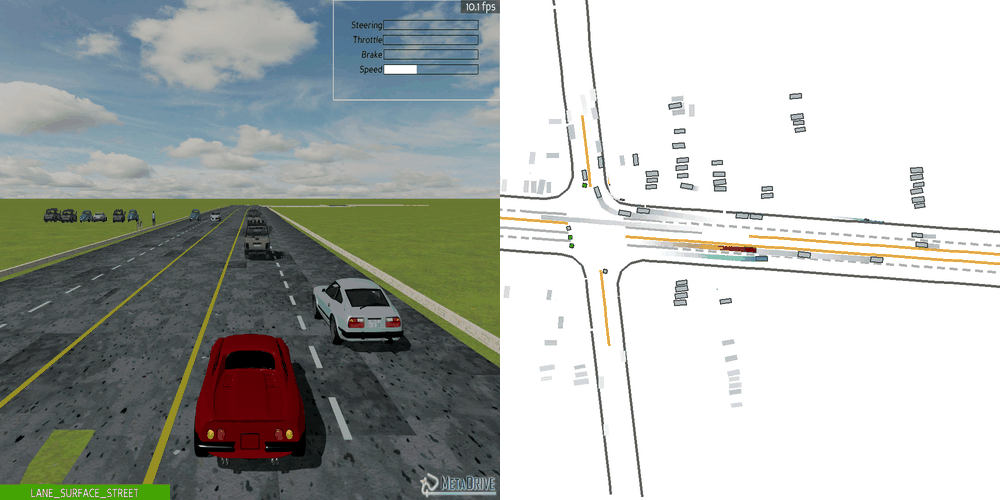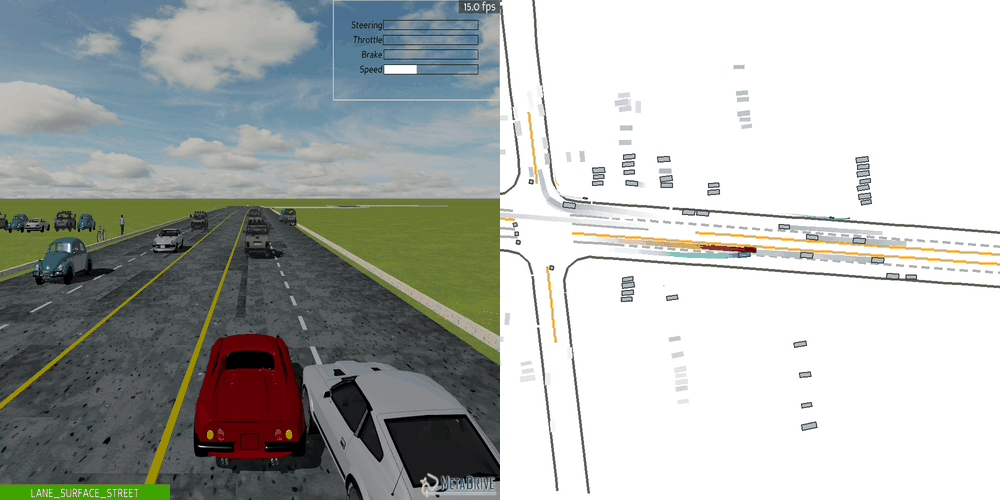 |
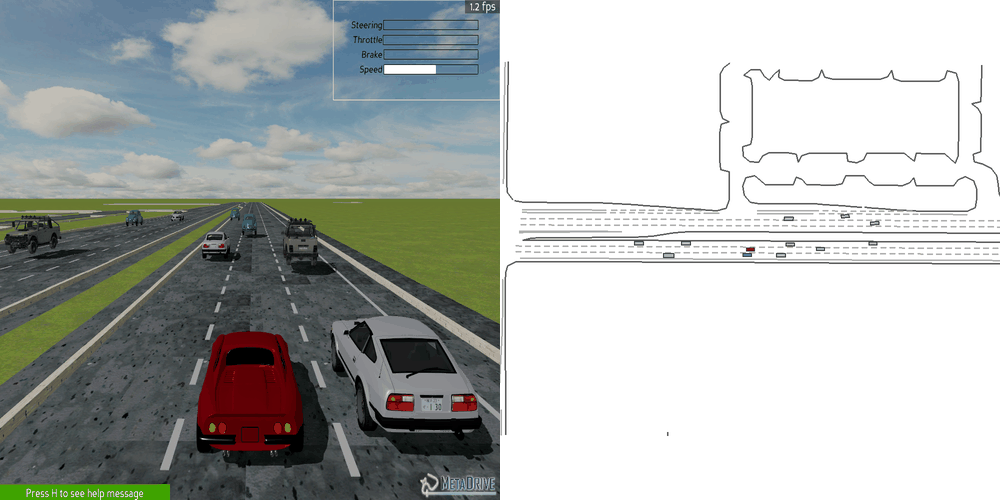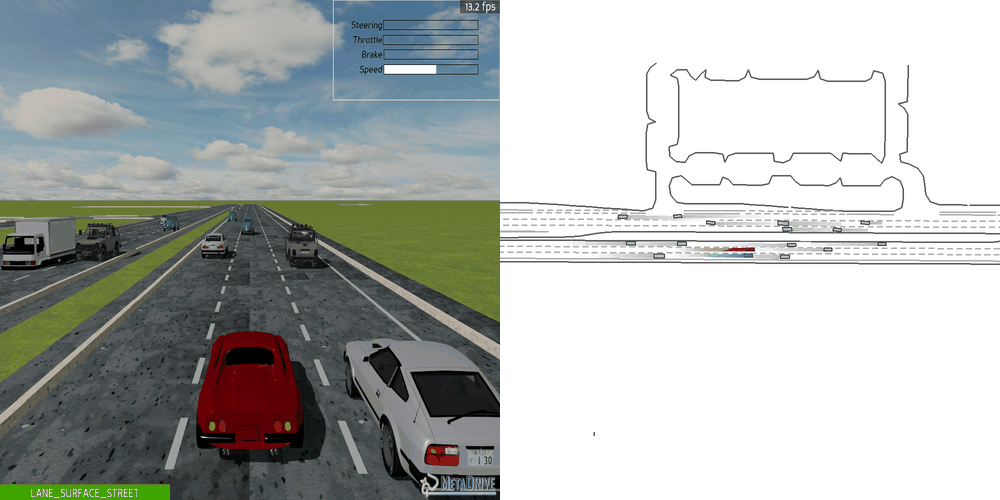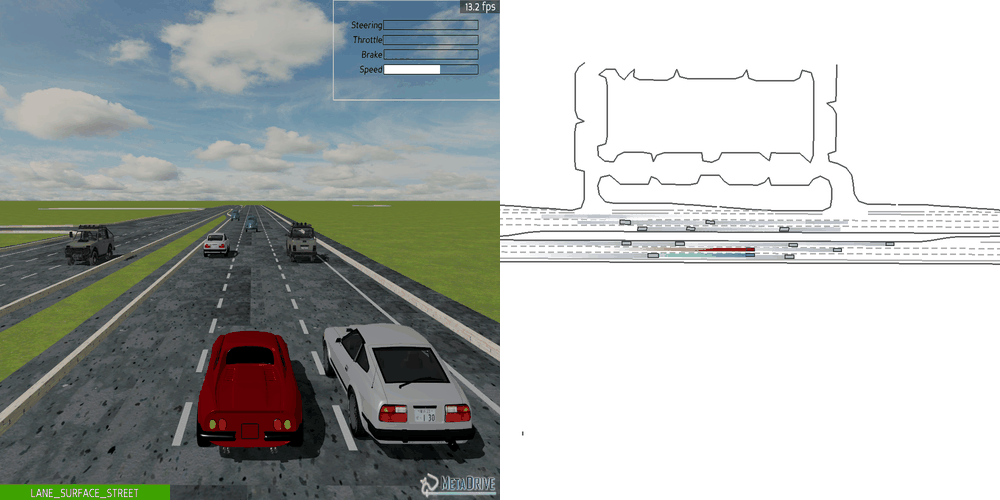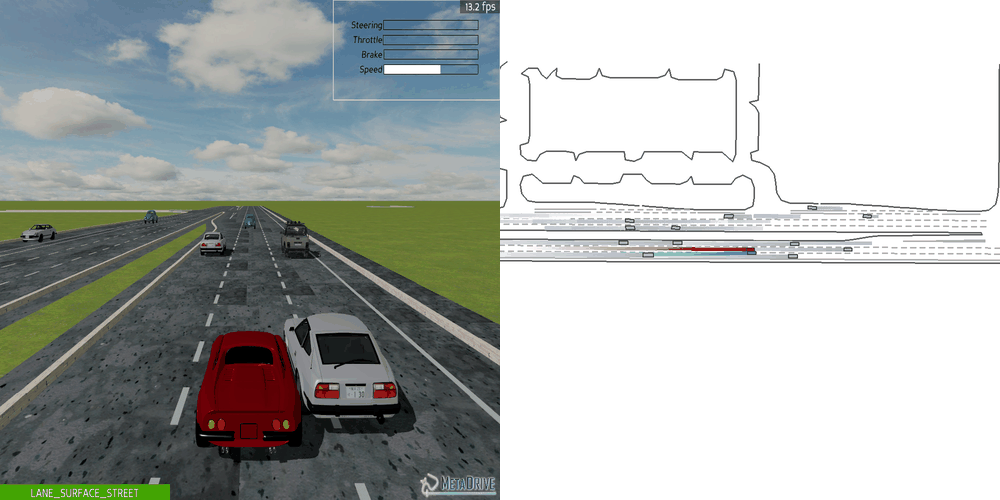 |
| Case 1 | Case 2 | Case 3 | Case 4 | Case 5 |
|---|---|---|---|---|
 |
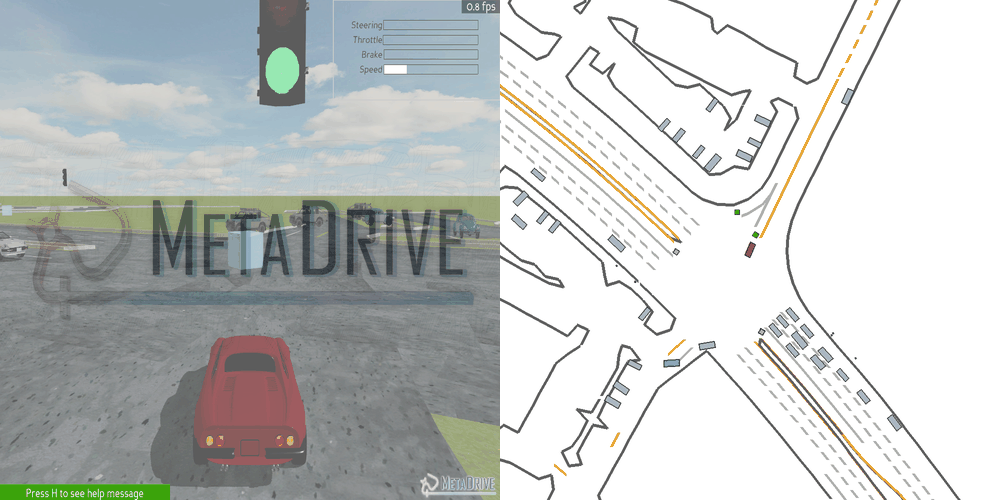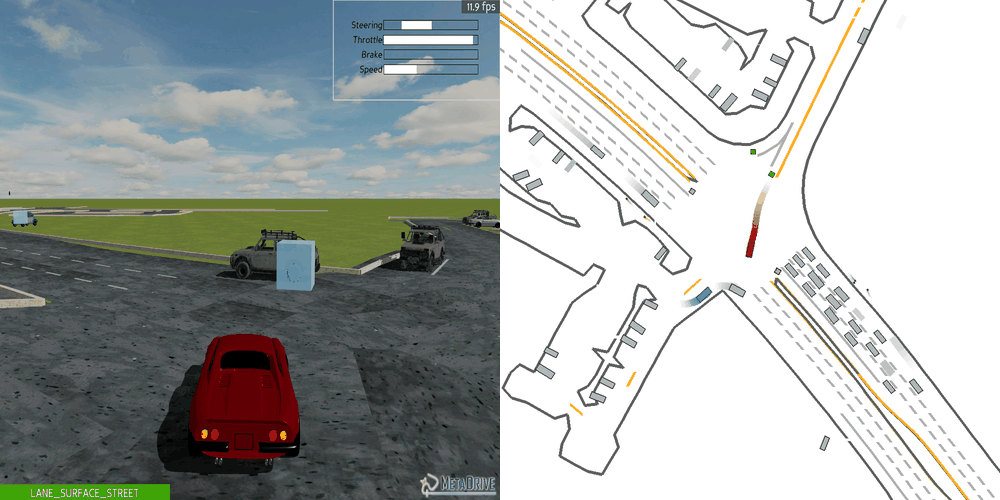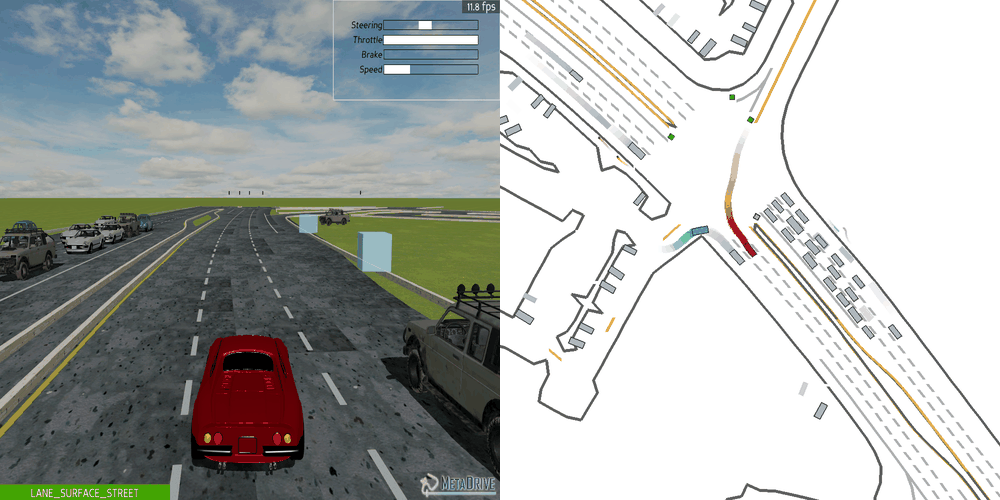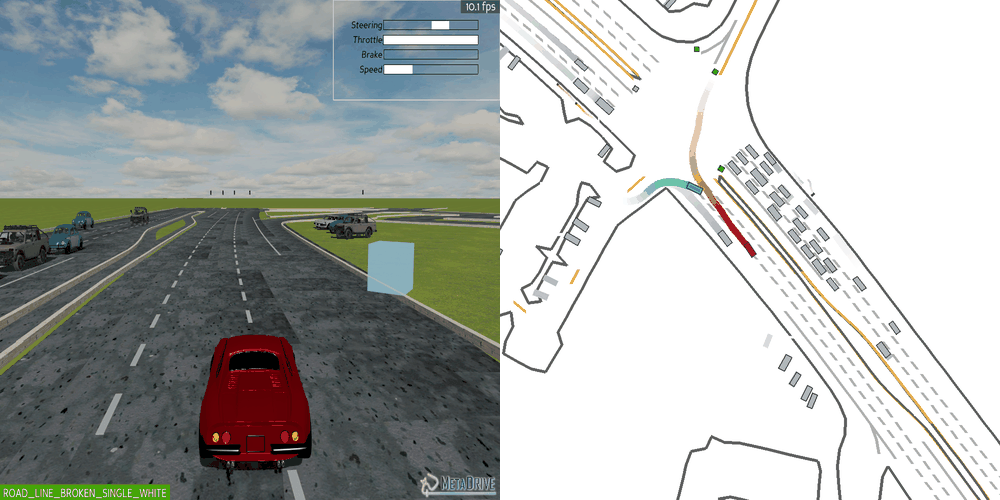 |
 |
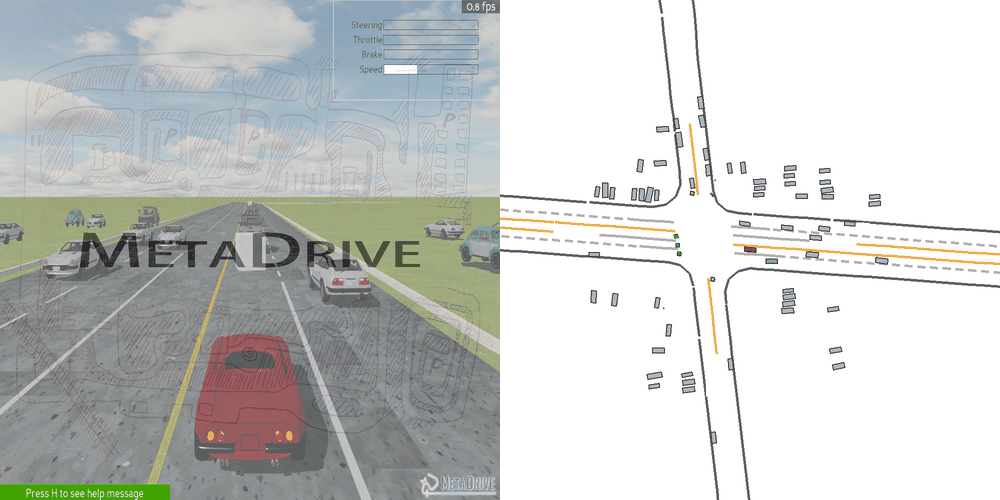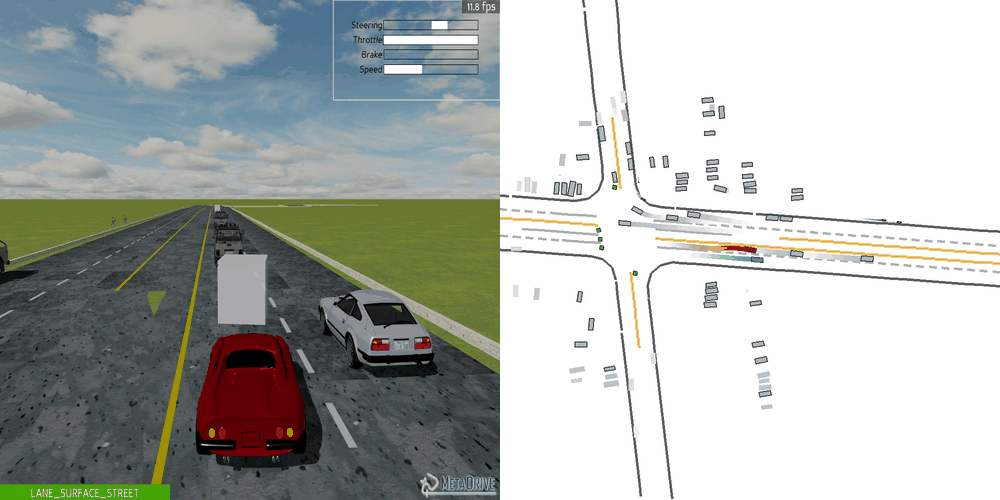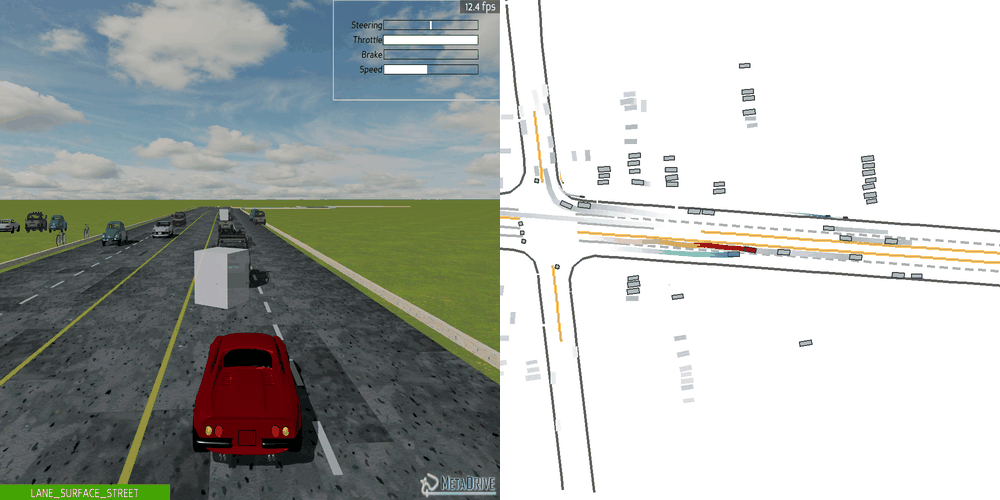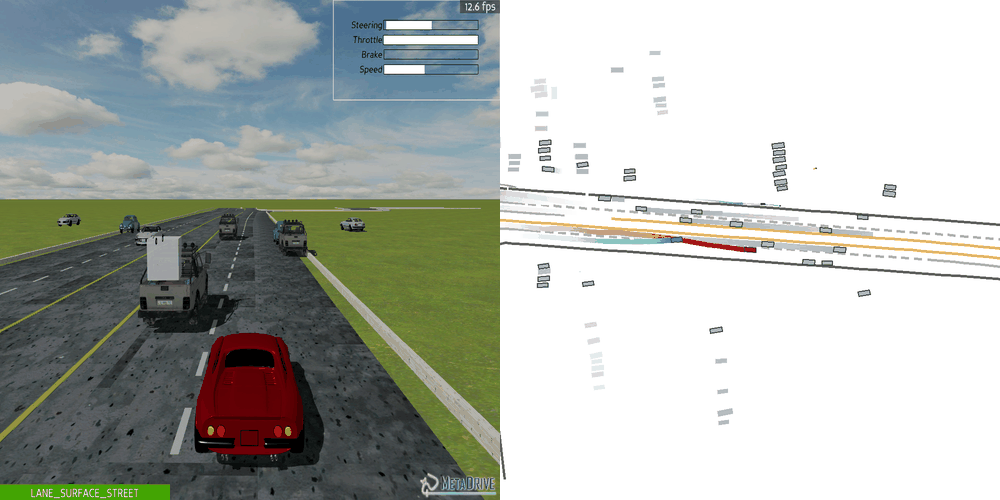 |
 |
If you find CurricuVLM useful for your research, please consider giving us a star 🌟 and citing our paper:
@article{sheng2025curricuvlm,
title={CurricuVLM: Towards Safe Autonomous Driving via Personalized Safety-Critical Curriculum Learning with Vision-Language Models},
author={Sheng, Zihao and Huang, Zilin and Qu, Yansong and Leng, Yue and Bhavanam, Sruthi and Chen, Sikai},
journal={arXiv preprint arXiv:2502.15119},
year={2025}
}