Releases: mage-ai/mage-ai
0.8.75 | Guardians Release

Polars integration
Support using Polars DataFrame in Mage blocks.
Opsgenie integration
Shout out to Sergio Santiago for his contribution of integrating Opsgenie as an alerting option in Mage.
Doc: https://docs.mage.ai/production/observability/alerting-opsgenie
Data integration
Speed up exporting data to BigQuery destination
Add support for using batch load jobs instead of the query API in BigQuery destination. You can enable it by setting use_batch_load to true in BigQuery destination config.
When loading ~150MB data to BigQuery, using batch loading reduces the time from 1 hour to around 2 minutes (30x the speed).
Microsoft SQL Server destination improvements
- Support ALTER command to add new columns
- Support MERGE command with multiple unique columns (use AND to connect the columns)
- Add MSSQL config fields to
io_config.yaml - Support multiple keys in MSSQL destination
Other improvements
- Fix parsing int timestamp in intercom source.
- Remove the “Execute” button from transformer block in data integration pipelines.
- Support using ssh tunnel for MySQL source with private key content
Git integration improvements
- Pass in Git settings through environment variables
- Use
git switchto switch branches - Fix git ssh key generation
- Save cwd as repo path if user leaves the field blank
Update disable notebook edit mode to allow certain operations
Add another value to DISABLE_NOTEBOOK_EDIT_ACCESS environment variable to allow users to create secrets, variables, and run blocks.
The available values are
- 0: this is the same as omitting the variable
- 1: no edit/execute access to the notebook within Mage. Users will not be able to use the notebook to edit pipeline content, execute blocks, create secrets, or create variables.
- 2: no edit access for pipelines. Users will not be able to edit pipeline/block metadata or content.
Doc: https://docs.mage.ai/production/configuring-production-settings/overview#read-only-access
Update Admin abilities
- Allow admins to view and update existing users' usernames/emails/roles/passwords (except for owners and other admins).
- Admins can only view Viewers/Editors and adjust their roles between those two.
- Admins cannot create or delete users (only owners can).
- Admins cannot make other users owners or admins (only owners can).
Retry block runs from specific block
For standard python pipelines, retry block runs from a selected block. The selected block and all downstream blocks will be re-ran after clicking the Retry from selected block button.
Other bug fixes & polish
-
Fix terminal user authentication. Update terminal authentication to happen on message.
-
Fix a potential authentication issue for the Google Cloud PubSub publisher client
-
Dependency graph improvements
- Update dependency graph connection depending on port side
- Show all ports for data loader and exporter blocks in dependency graph
-
DBT
- Support DBT alias and schema model config
- Fix
limitproperty in DBT block PUT request payload.
-
Retry pipeline run
- Fix bug: Individual pipeline run retries does not work on sqlite.
- Allow bulk retry runs when DISABLE_NOTEBOOK_EDIT_ACCESS enabled
- Fix bug: Retried pipeline runs and errors don’t appear in Backfill detail page.
-
Fix bug: When Mage fails to fetch a pipeline due to a backend exception, it doesn't show the actual error. It uses "undefined" in the pipeline url instead, which makes it hard to debug the issue.
-
Improve job scheduling: If jobs with QUEUED status are not in queue, re-enqueue them.
-
Pass
imagePullSecretsto k8s job when usingk8sas the executor. -
Fix streaming pipeline cancellation.
-
Fix the version of google-cloud-run package.
-
Fix query permissions for block resource
-
Catch
sqlalchemy.exc.InternalErrorin server and roll back transaction.
View full Changelog
0.8.69 | Hairy Otter Release

Markdown blocks aka Note blocks or Text blocks
Added Markdown block to Pipeline Editor.
Doc: https://docs.mage.ai/guides/blocks/markdown-blocks

Git integration improvements
Add git clone action
Allow users to select which files to commit
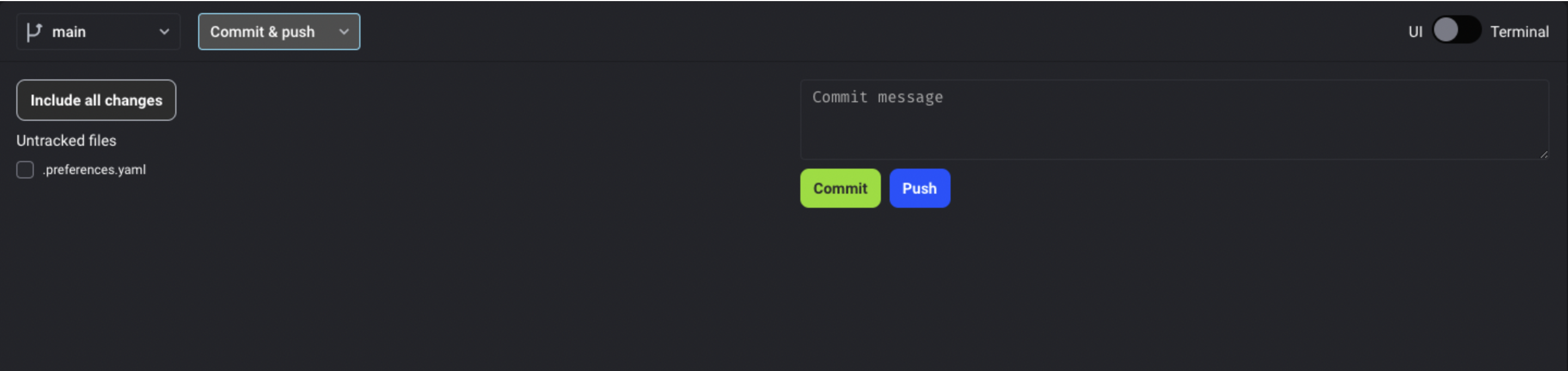
Add HTTPS authentication
Doc: https://docs.mage.ai/production/data-sync/git#https-token-authentication
Add a terminal toggle, so that users have easier access to the terminal
Callback block improvements
Doc: https://docs.mage.ai/development/blocks/callbacks/overview
Make callback block more generic and support it in data integration pipeline.
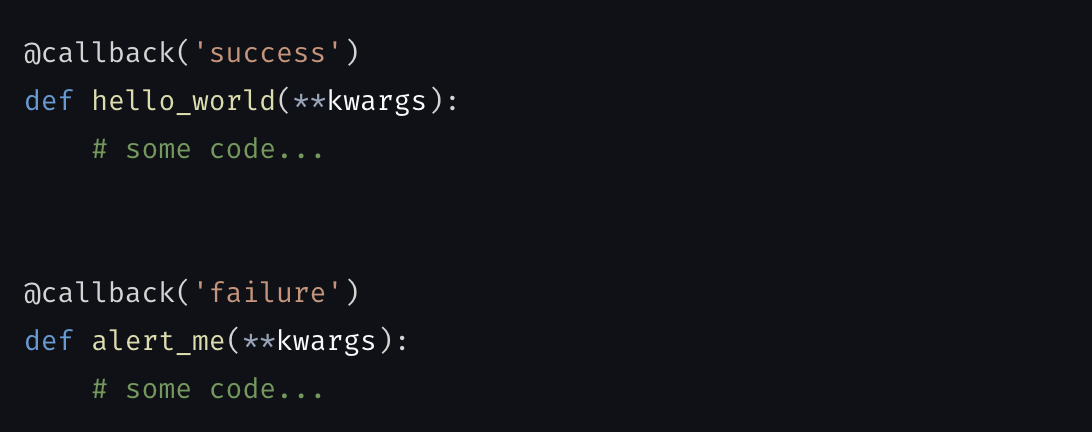
Keyword arguments available in data integration pipeline callback blocks: https://docs.mage.ai/development/blocks/callbacks/overview#data-integration-pipelines-only
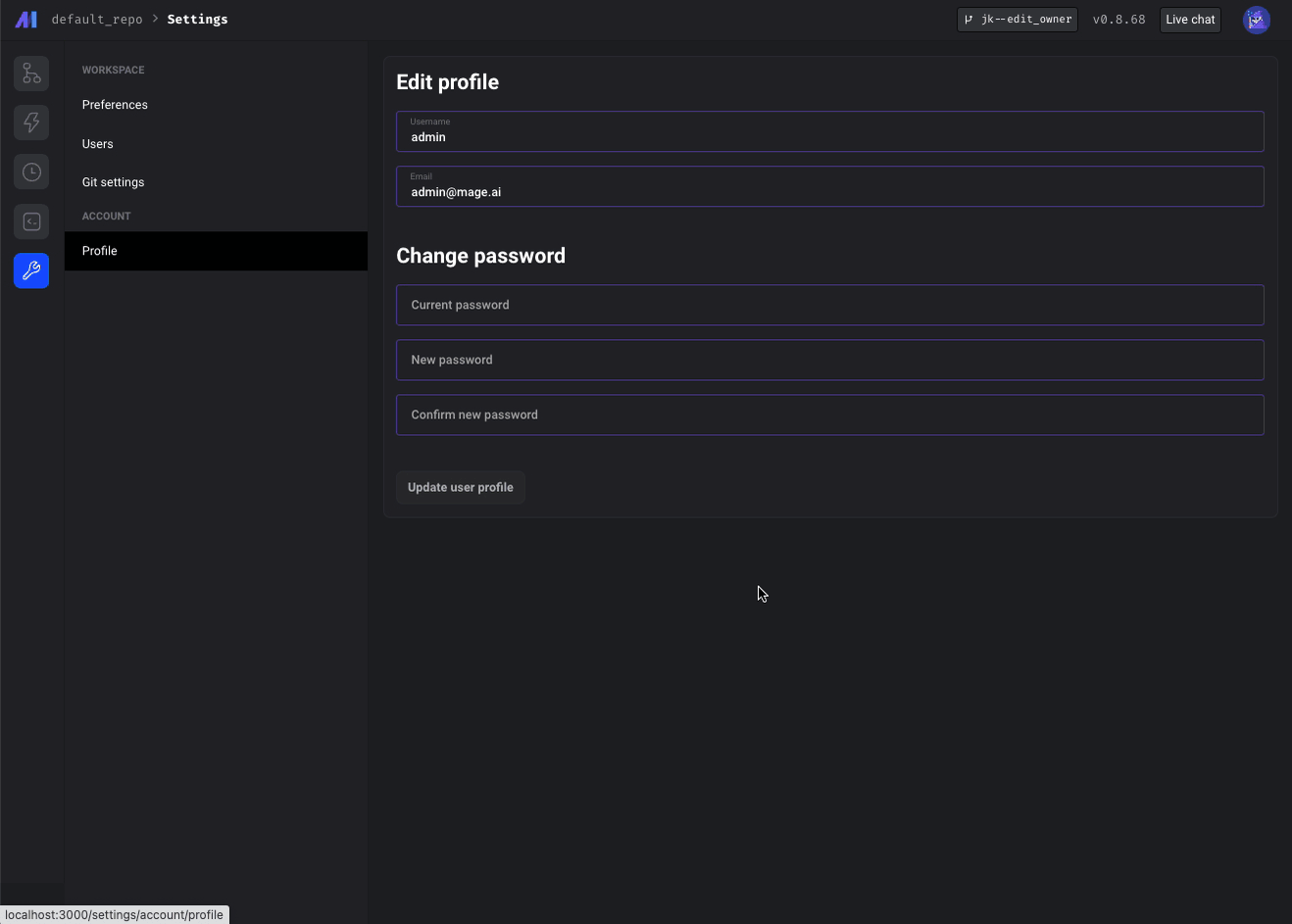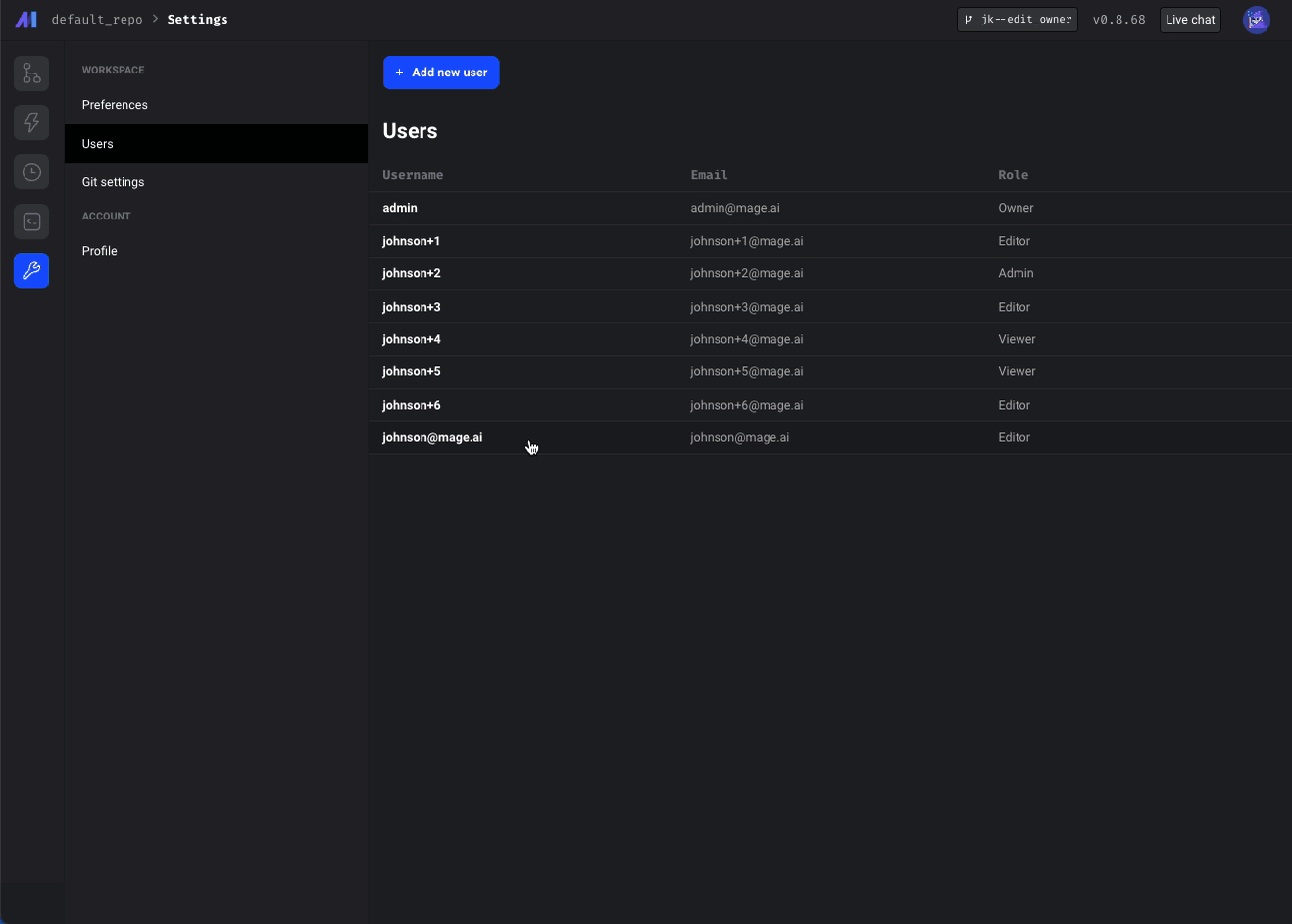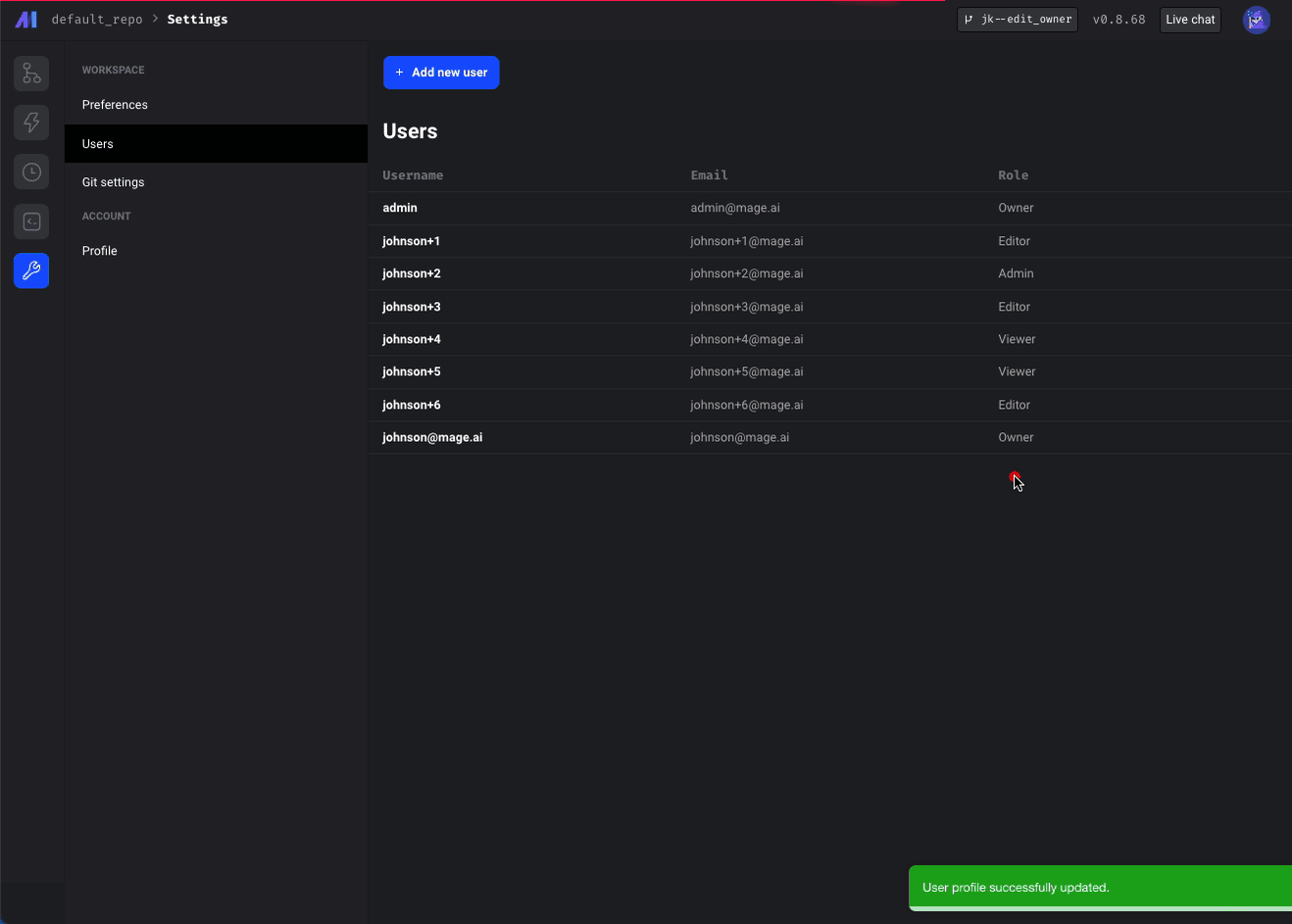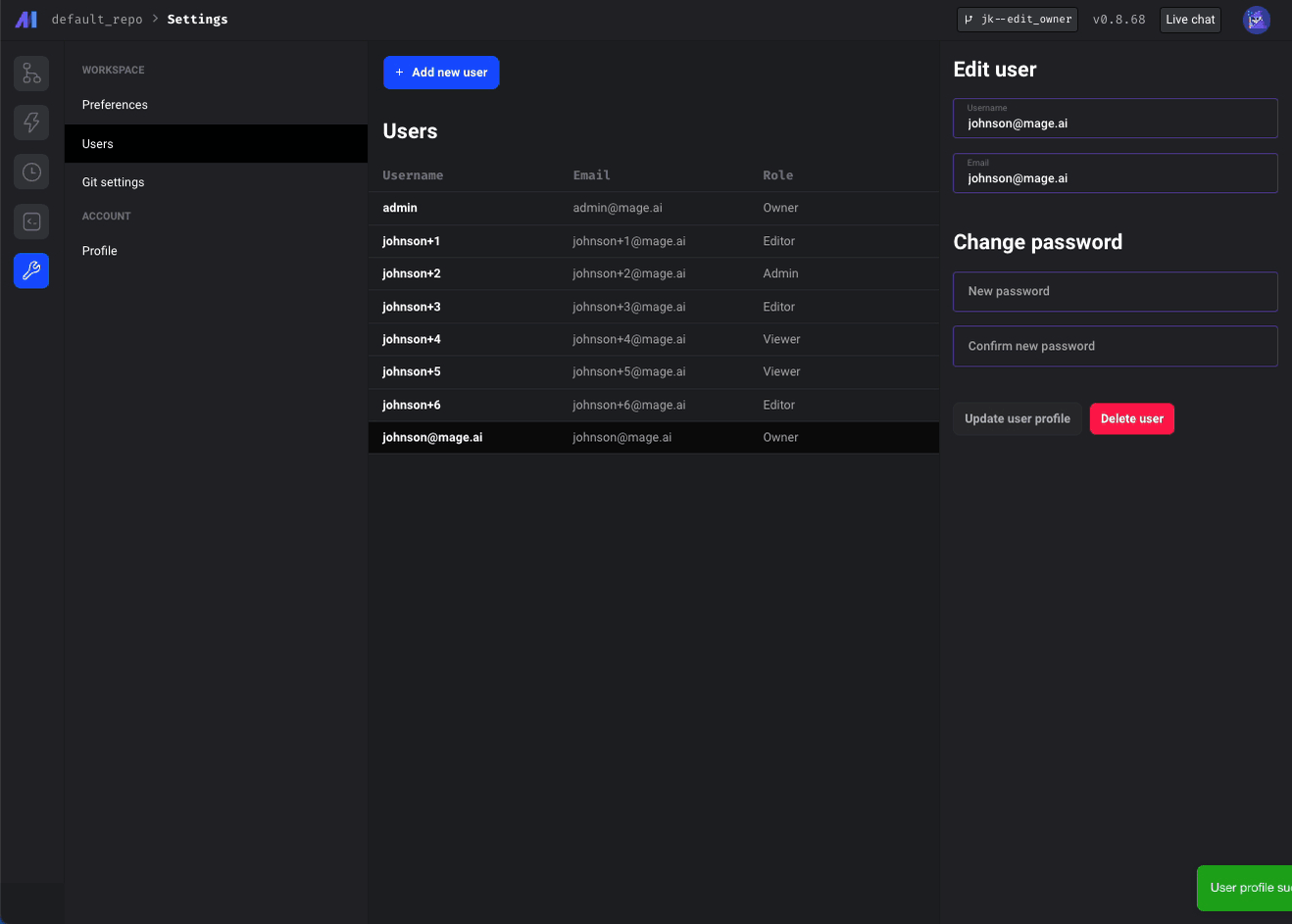
Transfer owner status or edit the owner account email
- Owners can make other users owners.
- Owners can edit other users' emails.
- Users can edit their emails.
Bulk retry pipeline runs.
Support bulk retrying pipeline runs for a pipeline.
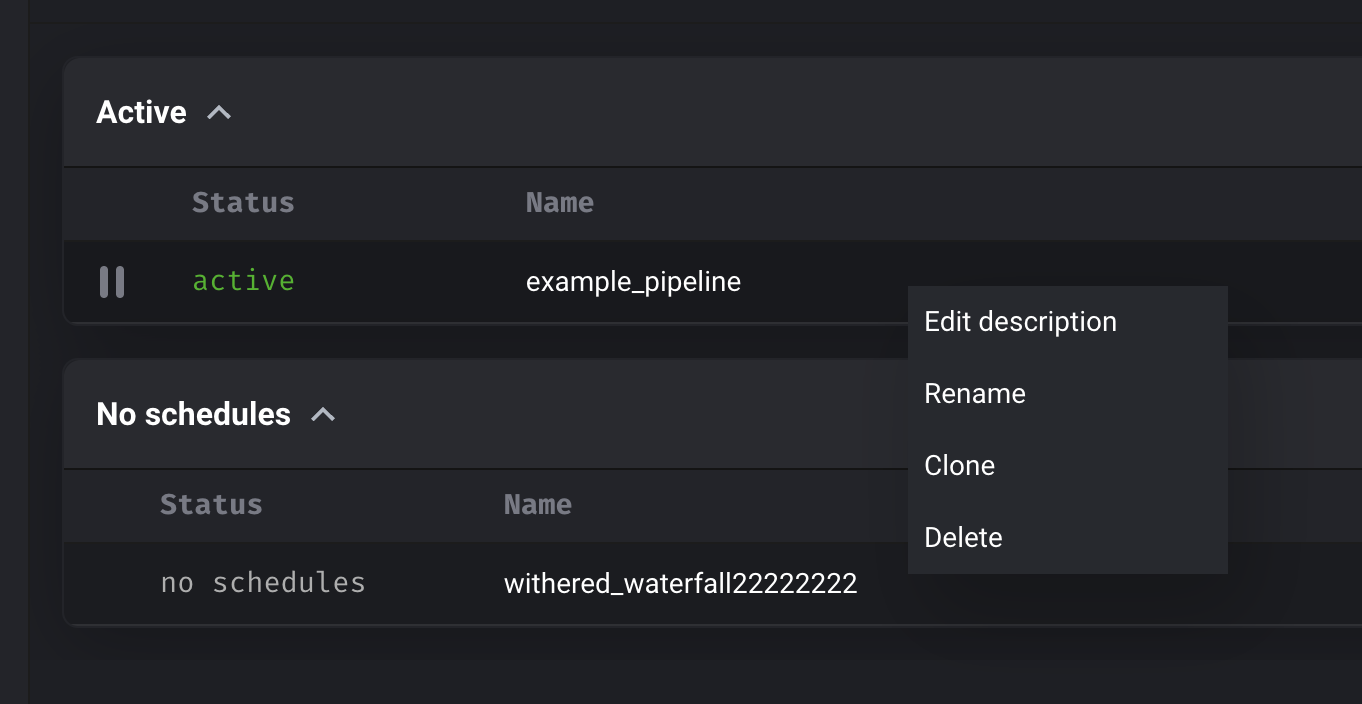
Right click context menu
Add right click context menu for row on pipeline list page for pipeline actions (e.g. rename).
Navigation improvements
When hovering over left and right vertical navigation, expand it to show navigation title like BigQuery’s UI.
Use Great Expectations suite from JSON object or JSON file
Doc: https://docs.mage.ai/development/testing/great-expectations#json-object
Support DBT incremental models
Doc: https://docs.mage.ai/dbt/incremental-models
Data integration pipeline
New destination: Google Cloud Storage
Shout out to André Ventura for his contribution of adding the Google Cloud Storage destination to data integration pipeline.
Other improvements
- Use bookmarks properly in Intercom incremental streams.
- Support IAM role based authentication in the Amazon S3 source and Amazon S3 destination for data integration pipelines
SQL module improvements
Add Apache Druid data source
Shout out to Dhia Eddine Gharsallaoui again for his contribution of adding Druid data source to Mage.
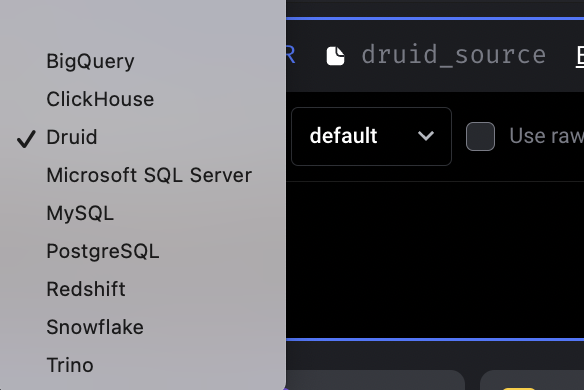
Doc: https://docs.mage.ai/integrations/databases/Druid
Add location as a config in BigQuery IO

Speed up Postgres IO export method
Use COPY command in mage_ai.io.postgres.Postgres export method to speed up writing data to Postgres.
Streaming pipeline
New source: Google Cloud PubSub
Doc: https://docs.mage.ai/guides/streaming/sources/google-cloud-pubsub
Deserialize message with Avro schema in Confluent schema registry
Kubernetes executor
Add config to set all pipelines use K8s executor
Setting the environment variable DEFAULT_EXECUTOR_TYPE to k8s to use K8s executor by default for all pipelines. Doc: https://docs.mage.ai/production/configuring-production-settings/compute-resource#2-set-executor-type-and-customize-the-compute-resource-of-the-mage-executor
Add the k8s_executor_config to project’s metadata.yaml to apply the config to all the blocks that use k8s executor in this project. Doc: https://docs.mage.ai/production/configuring-production-settings/compute-resource#kubernetes-executor
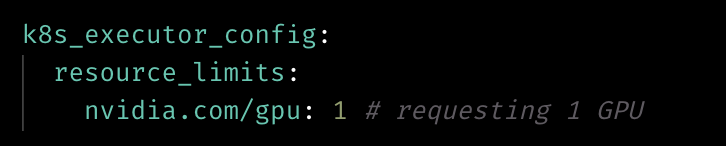
Support configuring GPU for k8s executor
Allow specifying GPU resource in k8s_executor_config.
Not use default as service account namespace in Helm chart
Fix service account permission for creating Kubernetes jobs by not using default namespace.
Doc for deploying with Helm: https://docs.mage.ai/production/deploying-to-cloud/using-helm
Other bug fixes & polish
- Fix error: When selecting or filtering data from parent block, error occurs: "AttributeError: list object has no attribute tolist".
- Fix bug: Web UI crashes when entering edit page (github issue).
- Fix bug: Hidden folder (.mage_temp_profiles) disabled in File Browser and not able to be minimized
- Support configuring Mage server public host used in the email alerts by setting environment variable
MAGE_PUBLIC_HOST. - Speed up PipelineSchedule DB query by adding index to column.
- Fix EventRulesResource AWS permissions error
- Fix bug: Bar chart shows too many X-axis ticks

View full Changelog
0.8.58 | Once & Always Release

Trigger pipeline from a block
Provide code template to trigger another pipeline from a block within a different pipeline.****
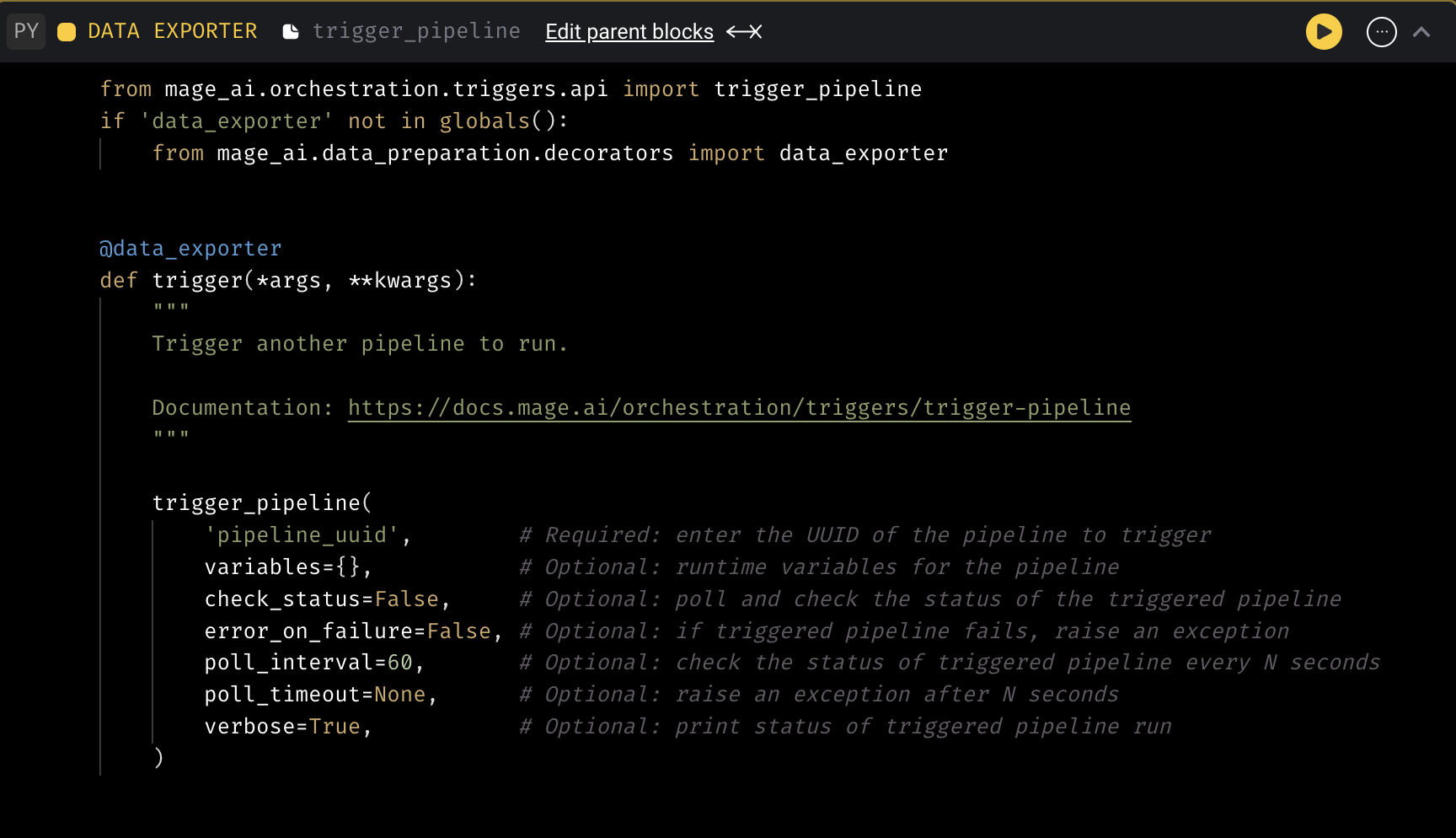
Doc: https://docs.mage.ai/orchestration/triggers/trigger-pipeline
Data integration pipeline
New source: Twitter Ads
Streaming pipeline
New sink: MongoDB
Doc: https://docs.mage.ai/guides/streaming/destinations/mongodb
Allow deleting SQS message manually
Mage supports two ways to delete messages:
- Delete the message in the data loader automatically after deserializing the message body.
- Manually delete the message in transformer after processing the message.
Doc: https://docs.mage.ai/guides/streaming/sources/amazon-sqs#message-deletion-method
Allow running multiple executors for streaming pipeline
Set executor_count variable in the pipeline’s metadata.yaml file to run multiple executors at the same time to scale the streaming pipeline execution
Doc: https://docs.mage.ai/guides/streaming/overview#run-pipeline-in-production
Improve instructions in the sidebar for getting block output variables
- Update generic block templates for custom, transformer, and data exporter blocks so it's easier for users to pass the output from upstream blocks.
- Clarified language for block output variables in Sidekick.

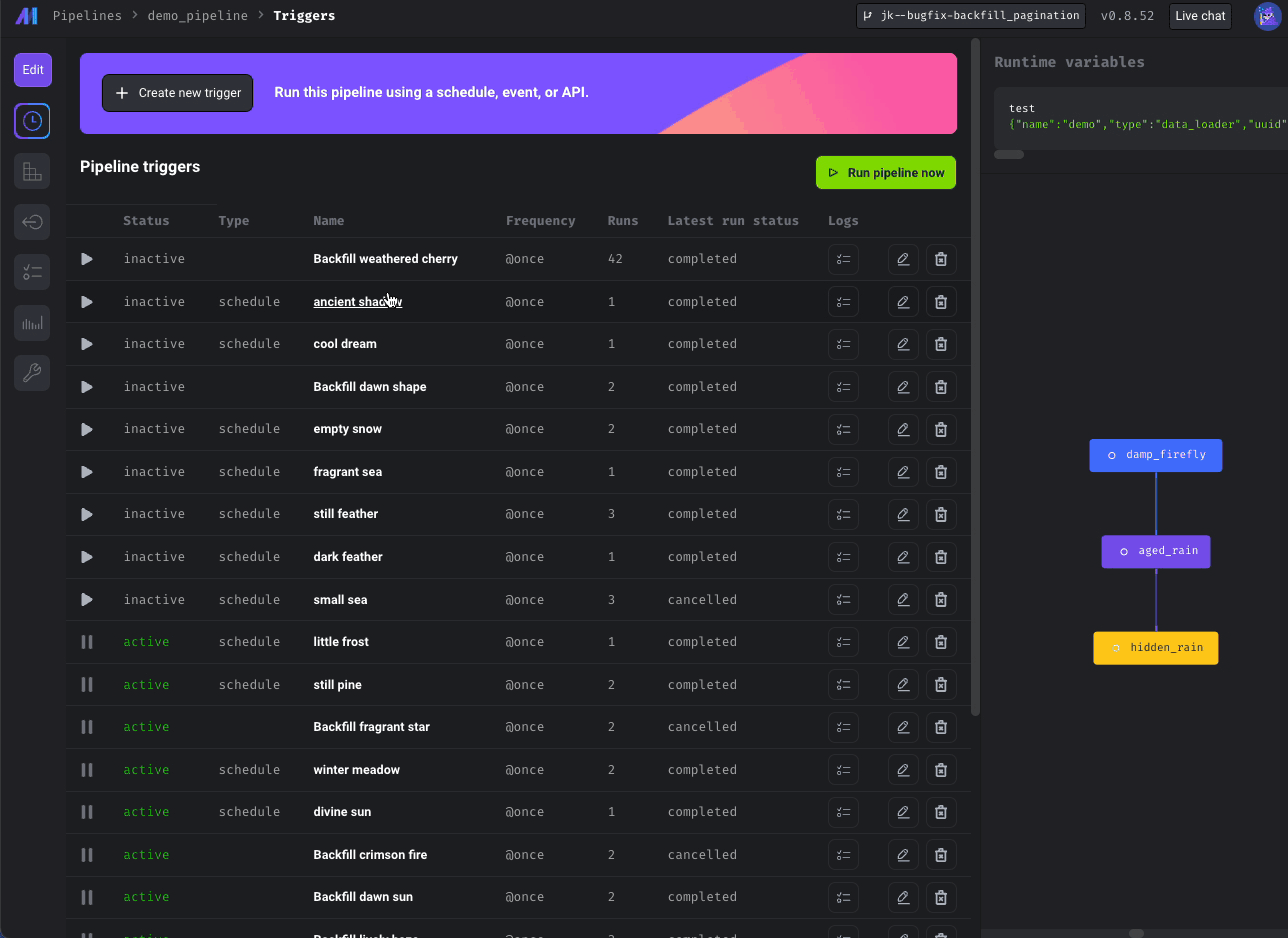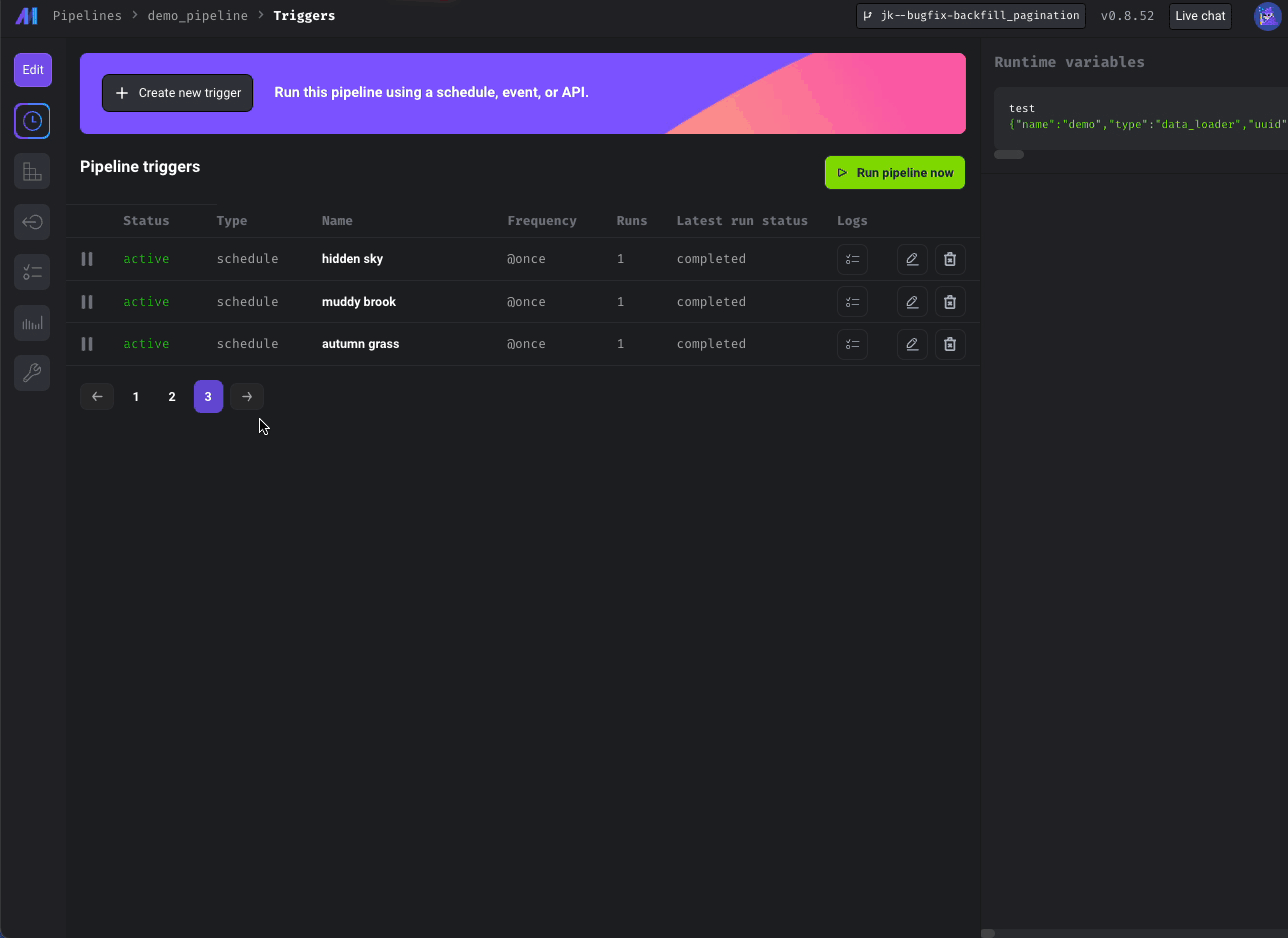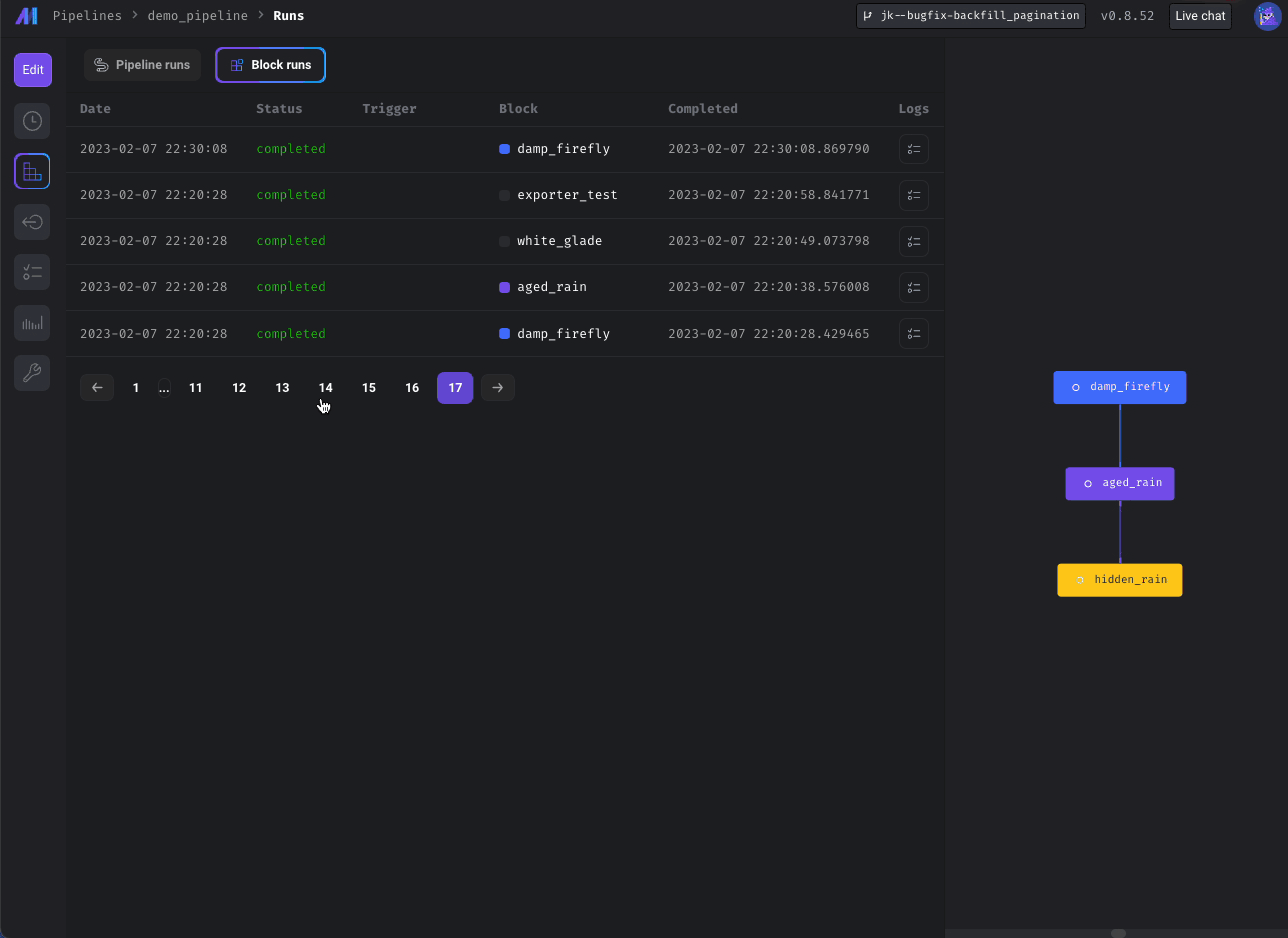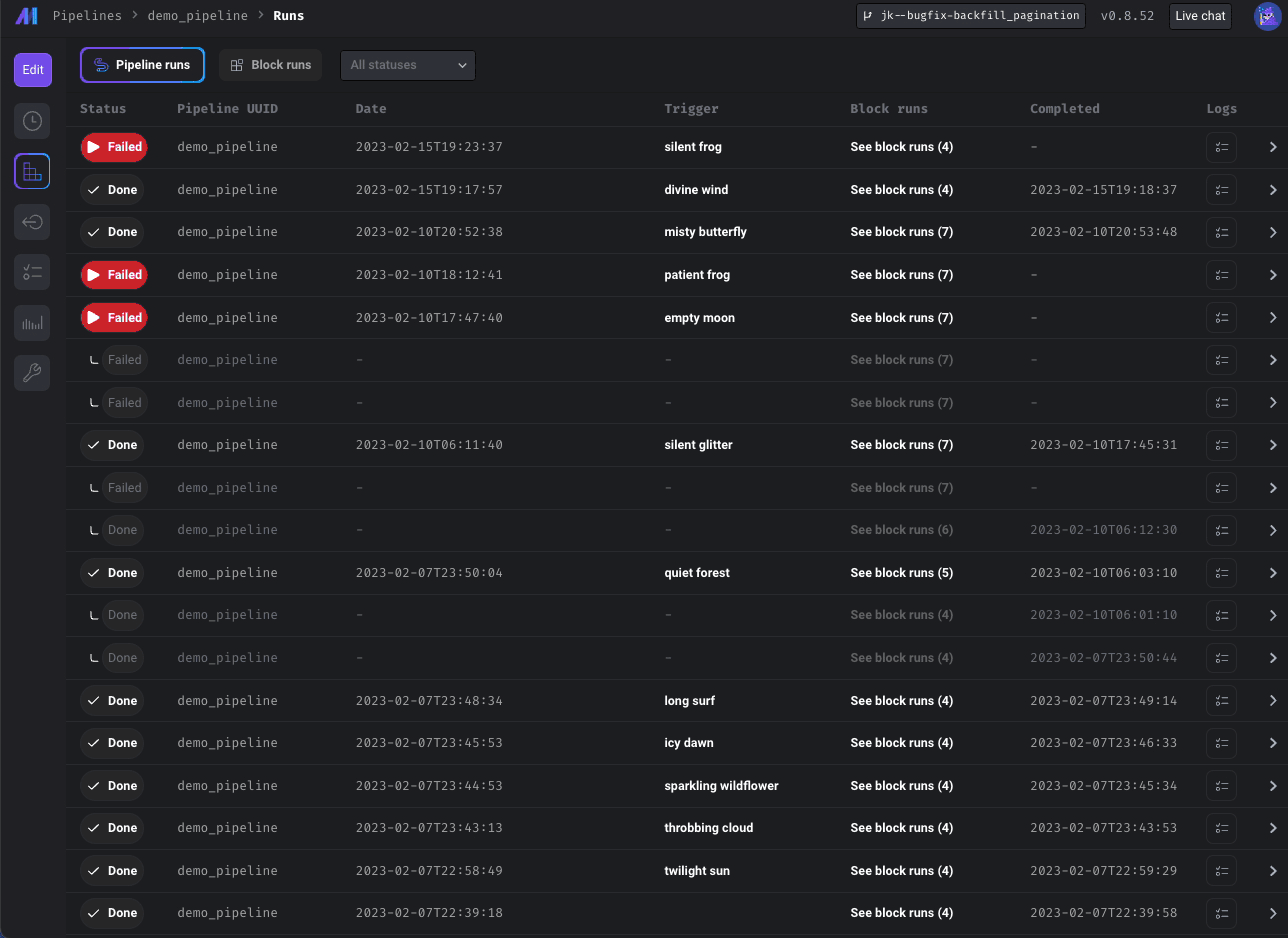
Paginate block runs in Pipeline Detail page and schedules on Trigger page
Added pagination to Triggers and Block Run pages
Automatically install requirements.txt file after git pulls
After pulling the code from git repository to local, automatically install the libraries in requirements.txt so that the pipelines can run successfully without manual installation of the packages.
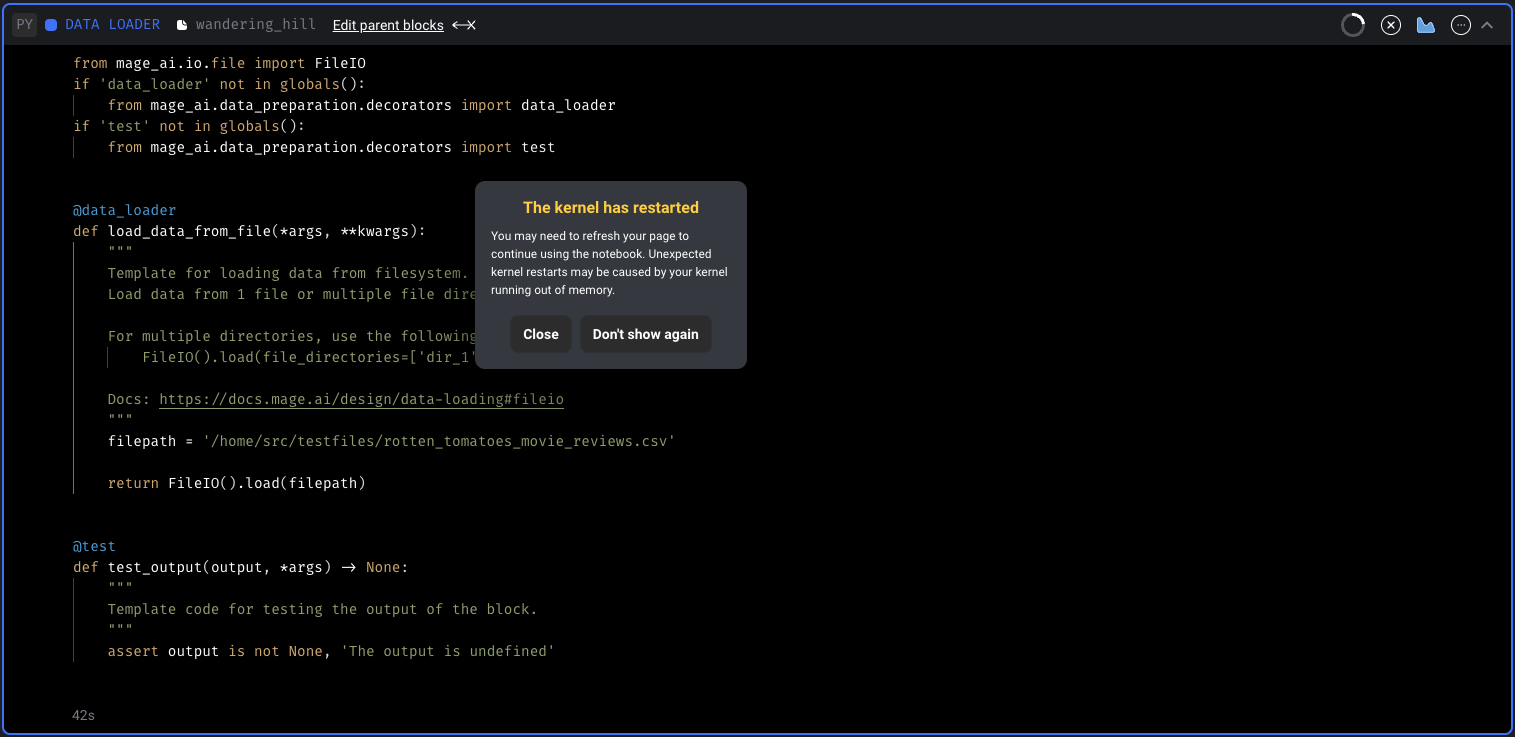
Add warning for kernel restarts and show kernel metrics
- Add warning for kernel if it unexpectedly restarts.
- Add memory and cpu metrics for the kernel.
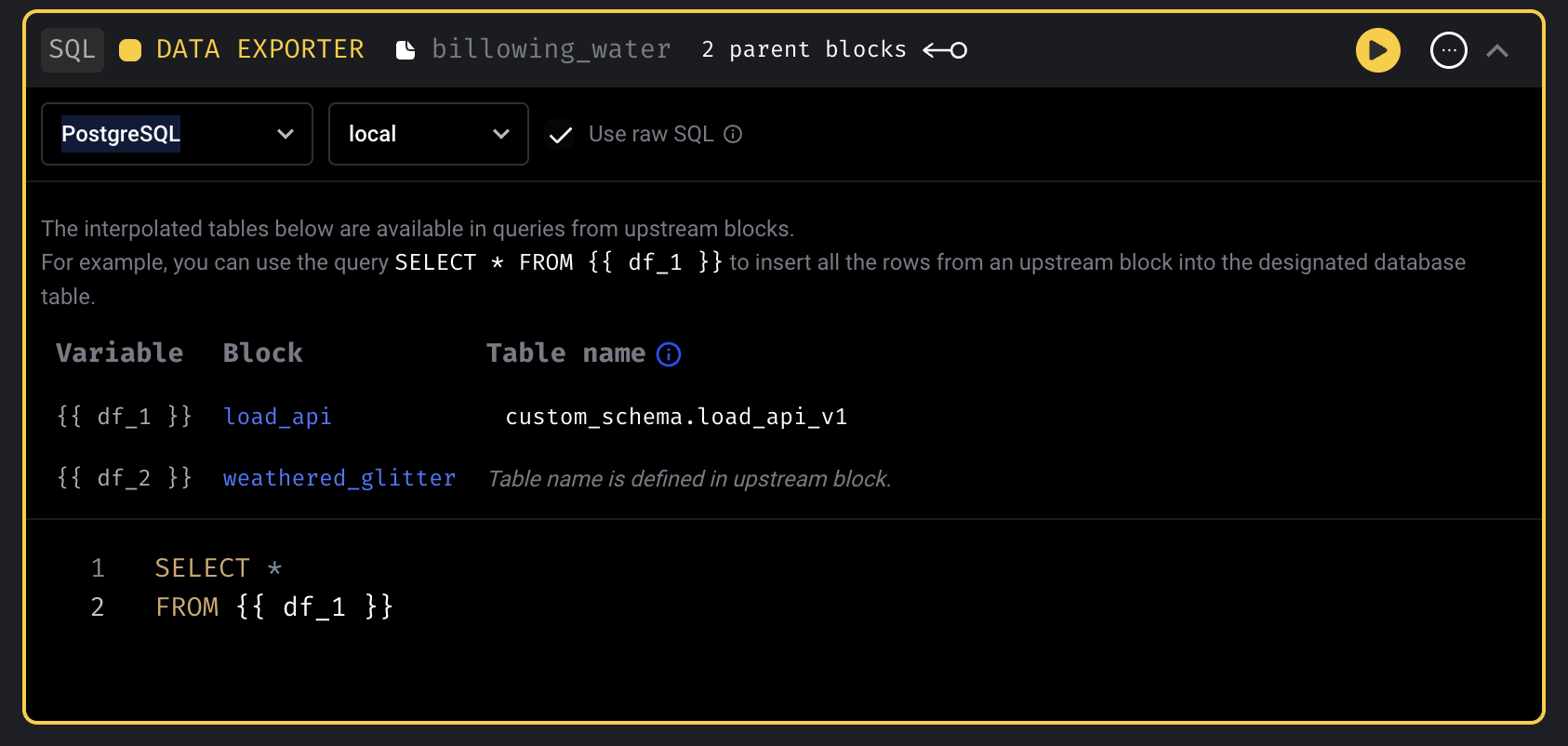
SQL block: Customize upstream table names
Allow setting the table names for upstream blocks when using SQL blocks.
Other bug fixes & polish
- Fix “Too many open files” error by providing the option to increase the “maximum number of open files” value: https://docs.mage.ai/production/configuring-production-settings/overview#ulimit
- Add
connect_timeoutto PostgreSQL IO - Add
locationto BigQuery IO - Mitigate race condition in Trino IO
- When clicking the sidekick navigation, don’t clear the URL params
- UI: support dynamic child if all dynamic ancestors eventually reduce before dynamic child block
- Fix PySpark pipeline deletion issue. Allow pipeline to be deleted without switching kernel.
- DBT block improvement and bug fixes
- Fix the bug of running all models of DBT
- Fix DBT test not reading profile
- Disable notebook shortcuts when adding new DBT model.
- Remove
.sqlextension in DBT model name if user includes it (the.sqlextension should not be included). - Dynamically size input as user types DBT model name with
.sqlsuffix trailing to emphasize that the.sqlextension should not be included. - Raise exception and display in UI when user tries to add a new DBT model to the same file location/path.
- Fix
onSuccesscallback logging issue - Fixed
mage runcommand. Set repo_path before initializing the DB so that we can get correct db_connection_url. - Fix bug: Code block running spinner keeps spinning when restarting kernel.
- Fix bug: Terminal doesn’t work in mage demo
- Automatically redirect users to the sign in page if they are signed in but can’t load anything.
- Add folder lines in file browser.
- Fix
ModuleNotFoundError: No module named 'aws_secretsmanager_caching'when running pipeline from command line
View full Changelog
0.8.52 | The Super Mario Bros. Release

ClickHouse SQL block
Support using SQL block to fetch data from, transform data in and export data to ClickHouse.
Doc: https://docs.mage.ai/integrations/databases/ClickHouse
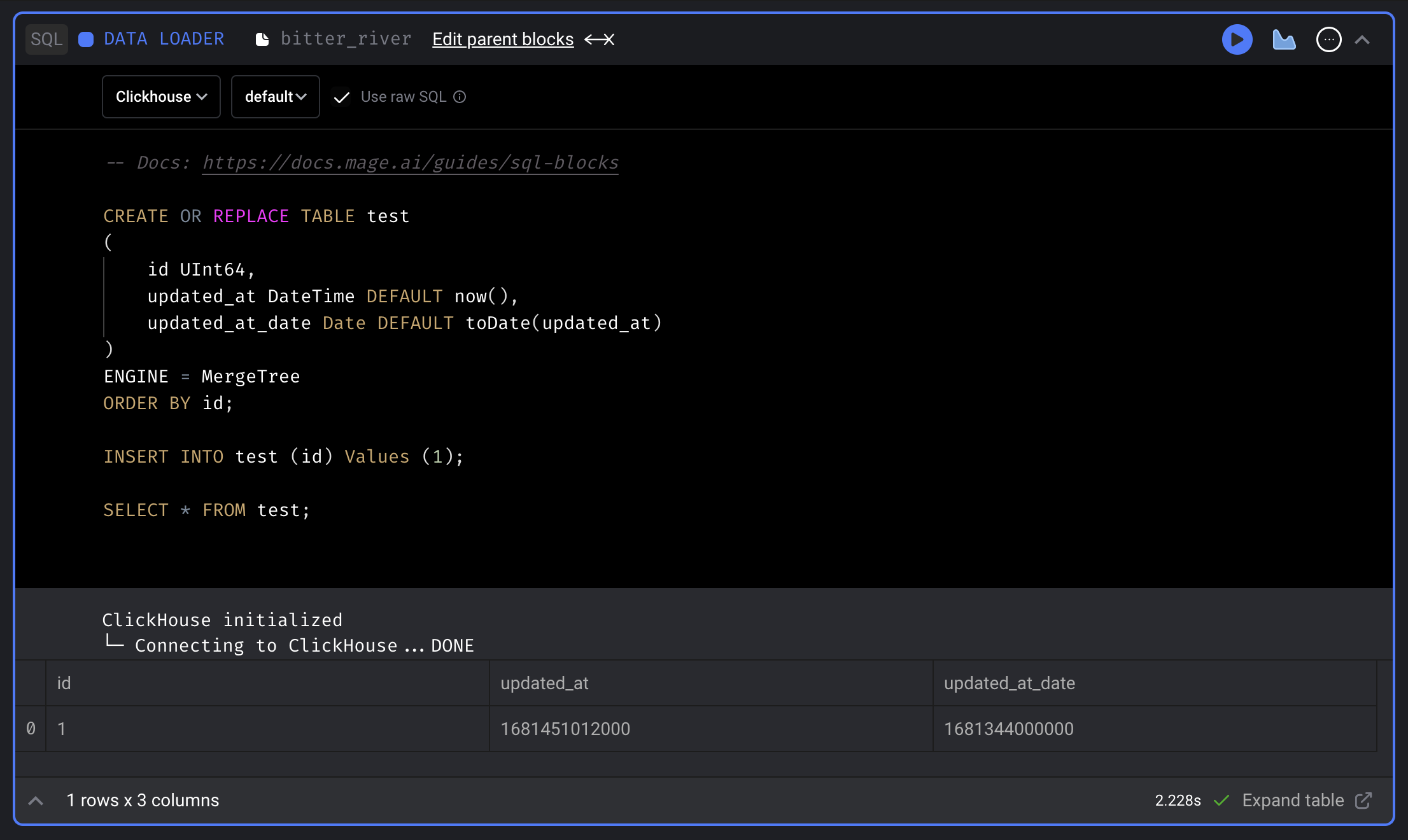
Trino SQL block
Support using SQL block to fetch data from, transform data in and export data to Trino.
Doc: https://docs.mage.ai/development/blocks/sql/trino
Sentry integration
Enable Sentry integration to track and monitor exceptions in Sentry dashboard.
Doc: https://docs.mage.ai/production/observability/sentry
Drag and drop to re-order blocks in pipeline
Mage now supports dragging and dropping blocks to re-order blocks in pipelines.
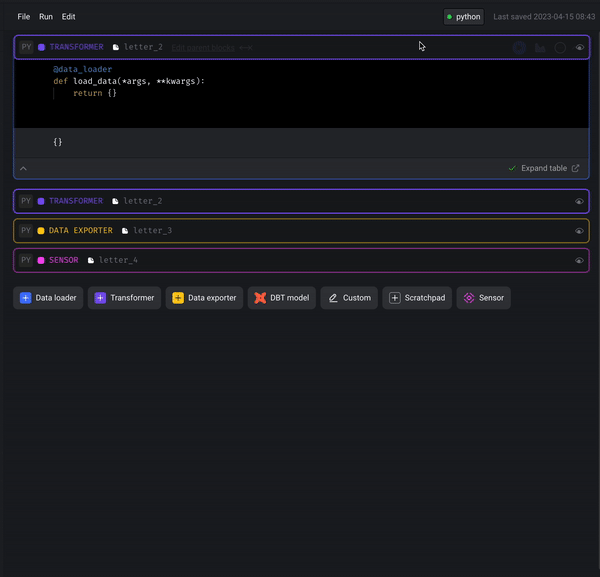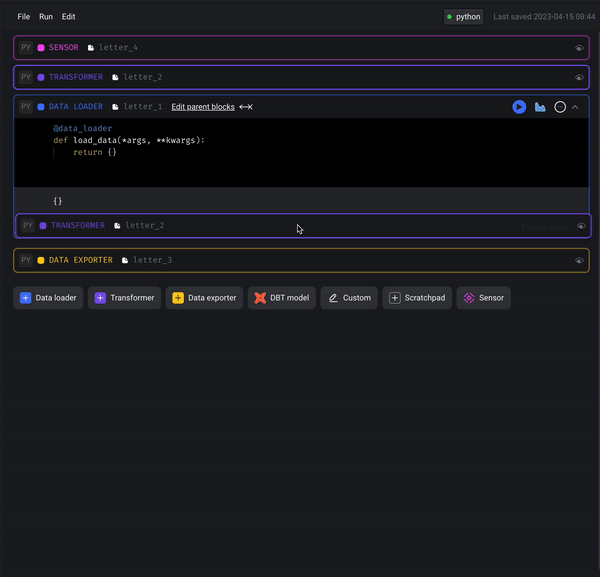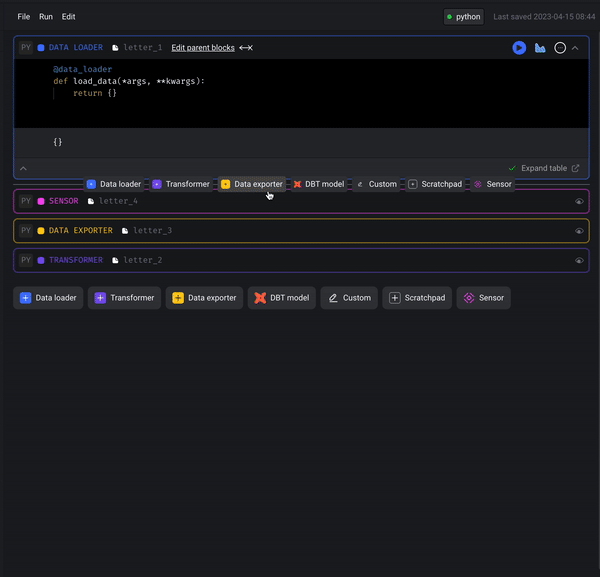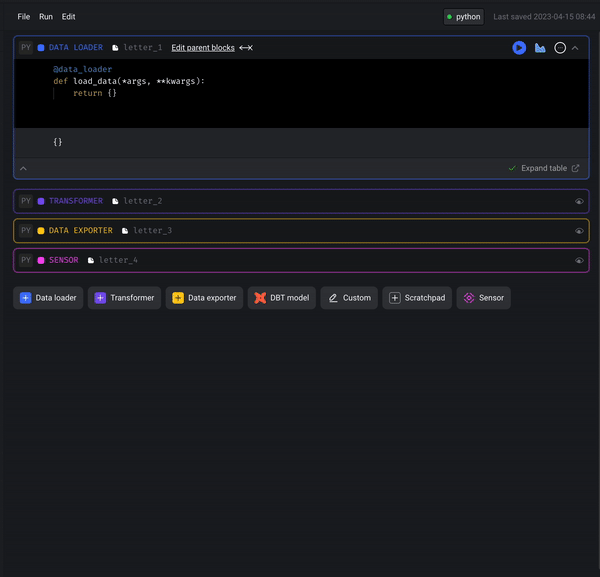
Streaming pipeline
Add AWS SQS streaming source
Support consuming messages from SQS queues in streaming pipelines.
Doc: https://docs.mage.ai/guides/streaming/sources/amazon-sqs
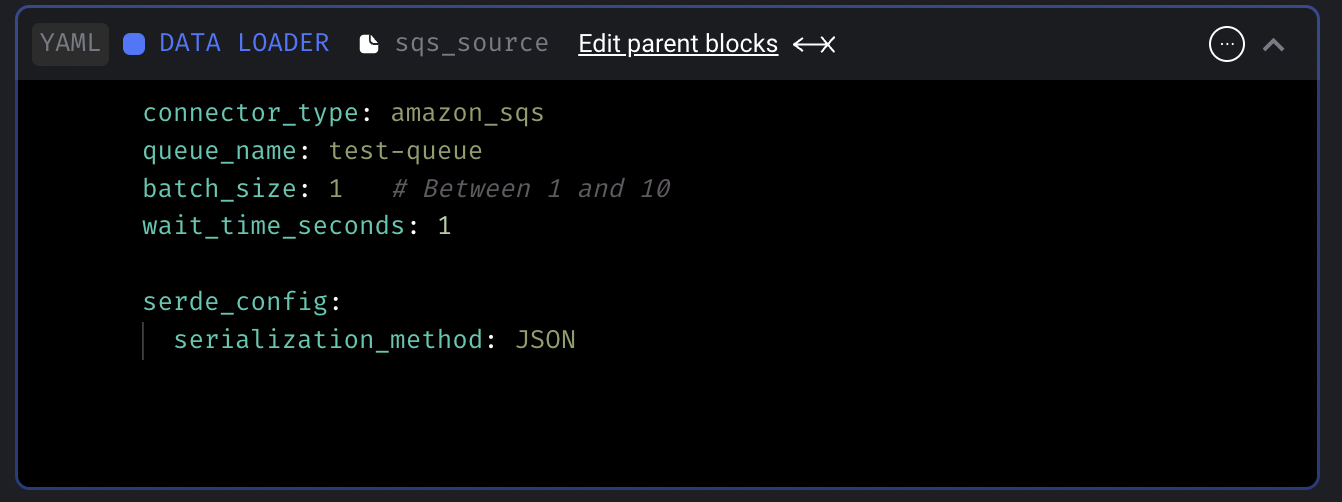
Add dummy streaming sink
Dummy sink will print the message optionally and discard the message. This dummy sink will be useful when users want to trigger other pipelines or 3rd party services using the ingested data in transformer.
Doc: https://docs.mage.ai/guides/streaming/destinations/dummy
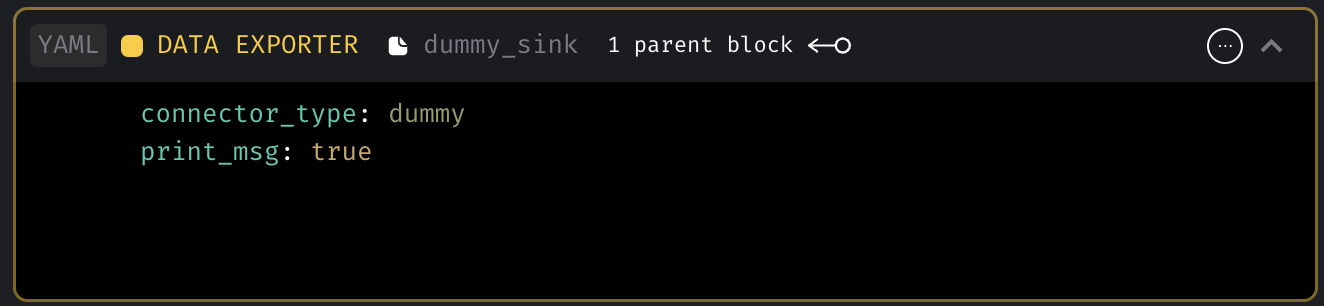
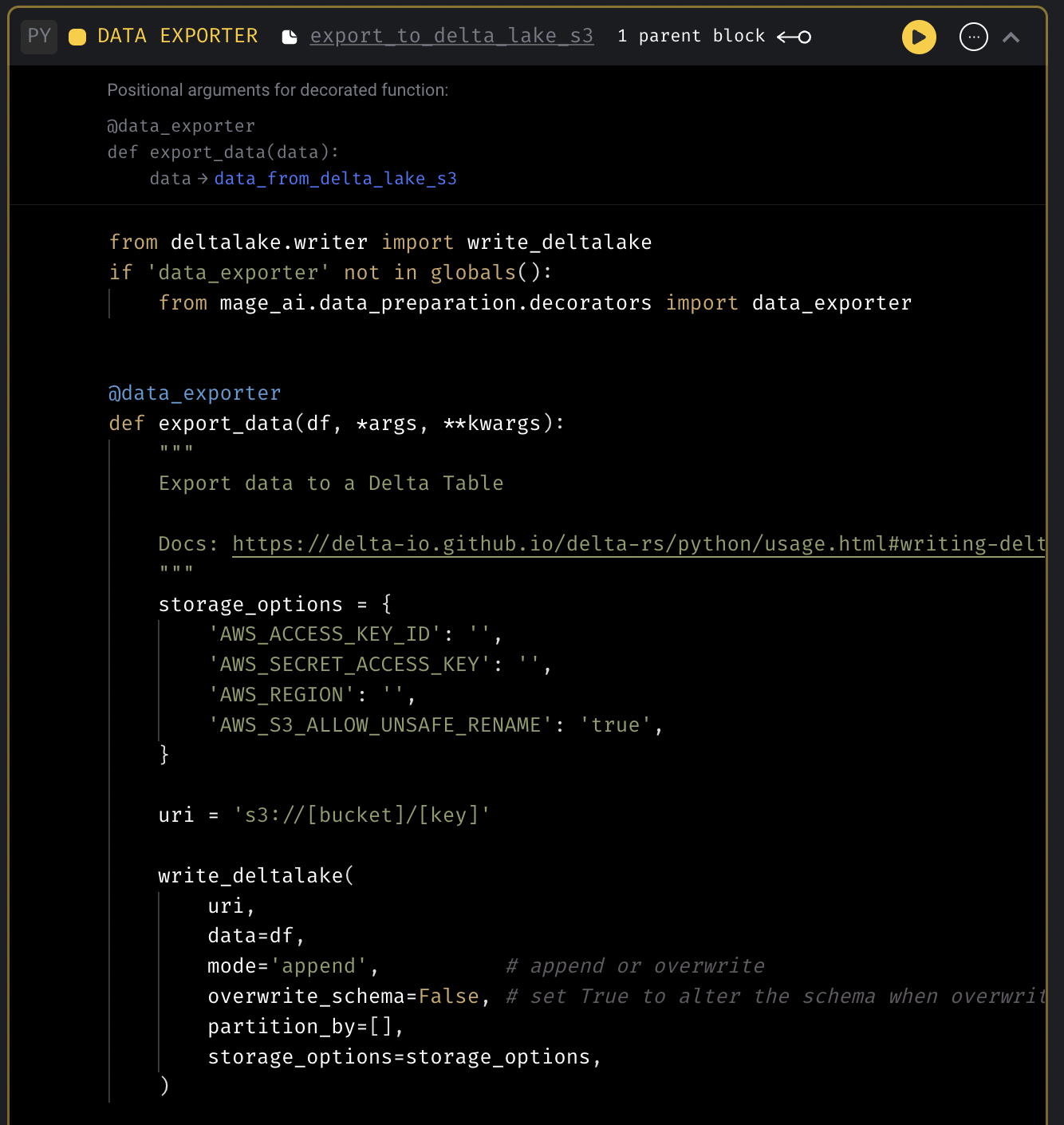
Delta Lake code templates
Add code templates to fetch data from and export data to Delta Lake.
Delta Lake data loader template
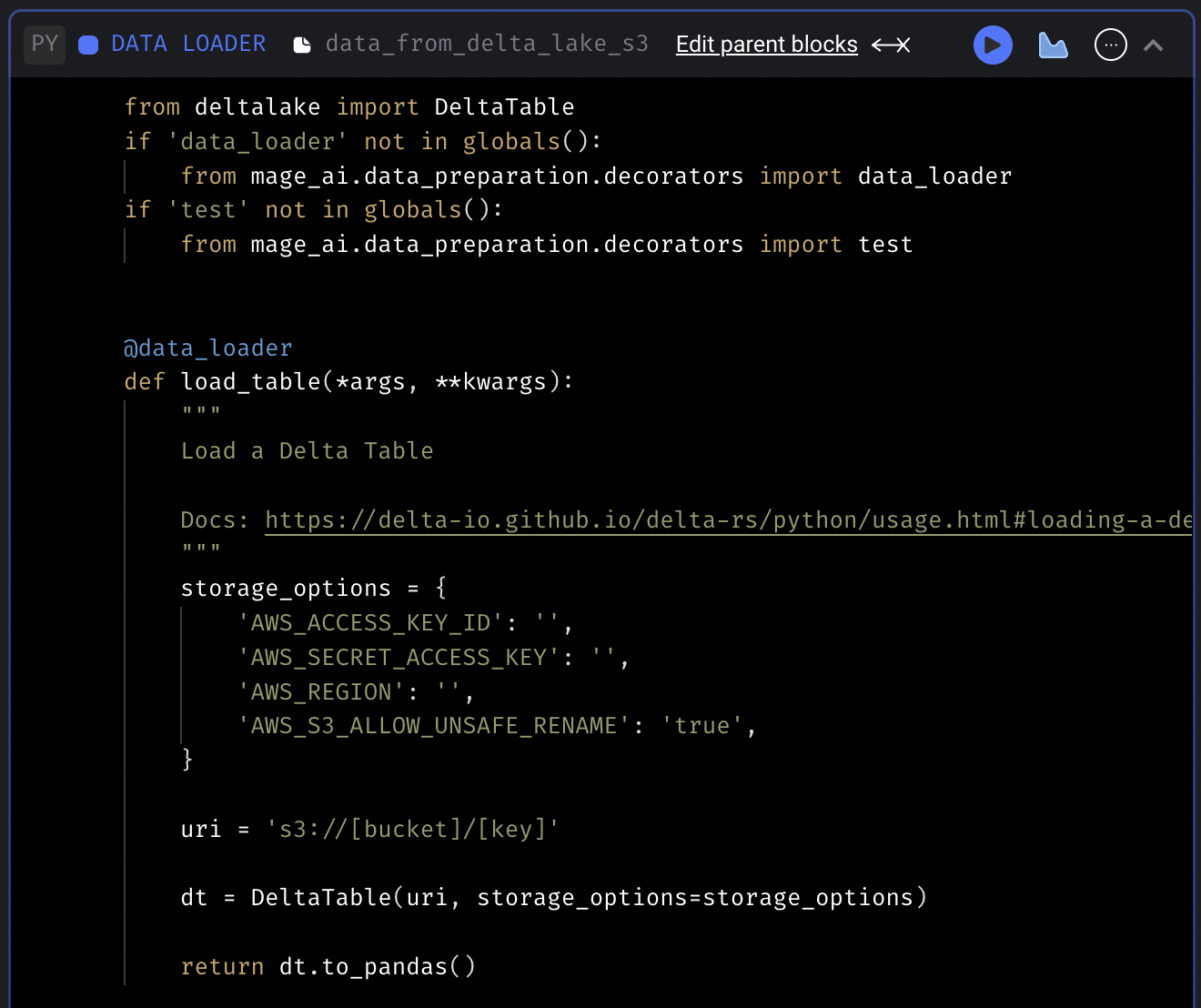
Delta Lake data exporter template
Unit tests for Mage pipelines
Support writing unit tests for Mage pipelines that run in the CI/CD pipeline using mock data.
Doc: https://docs.mage.ai/development/testing/unit-tests
Data integration pipeline
- Chargebee source: Fix load sample data issue
- Redshift destination: Handle unique constraints in destination tables.
DBT improvements
- If there are two DBT model files in the same directory with the same name but one has an extra
.sqlextension, the wrong file may get deleted if you try to delete the file with the double.sqlextension. - Support using Python block to transform data between DBT model blocks
- Support
+schemain DBT profile
Other bug fixes & polish
- SQL block
- Automatically limit SQL block data fetching while using the notebook but also provide manually override to adjust the limit while using the notebook. Remove these limits when running pipeline end-to-end outside the notebook.
- Only export upstream blocks if current block using raw SQL and its using the variable
- Update SQL block to use
io_config.yamldatabase and schema by default
- Fix timezone in pipeline run execution date.
- Show backfill preview dates in UTC time
- Raise exception when loading empty pipeline config.
- Fix dynamic block creation when reduced block has another dynamic block as downstream block
- Write Spark DataFrame in parquet format instead of csv format
- Disable user authentication when REQUIRE_USER_AUTHENTICATION=0
- Fix loggings for Callback blocks
- Git
- Import git only when the
Gitfeature is used. - Update git actions error message
- Import git only when the
- Notebook
- Fix Notebook page freezing issue
- Make Notebook right vertical navigation sticky
- More documentations
- Add architecture overview diagram and doc: https://docs.mage.ai/production/deploying-to-cloud/architecture
- Add doc for setting up event trigger lambda function: https://docs.mage.ai/guides/triggers/events/aws#set-up-lambda-function
View full Changelog
0.8.44 | Dungeons and Dragons Release

Configure trigger in code
In addition to configuring triggers in UI, Mage also supports configuring triggers in code now. Create a triggers.yaml file under your pipeline folder and enter the triggers config. The triggers will automatically be synced to DB and trigger UI.
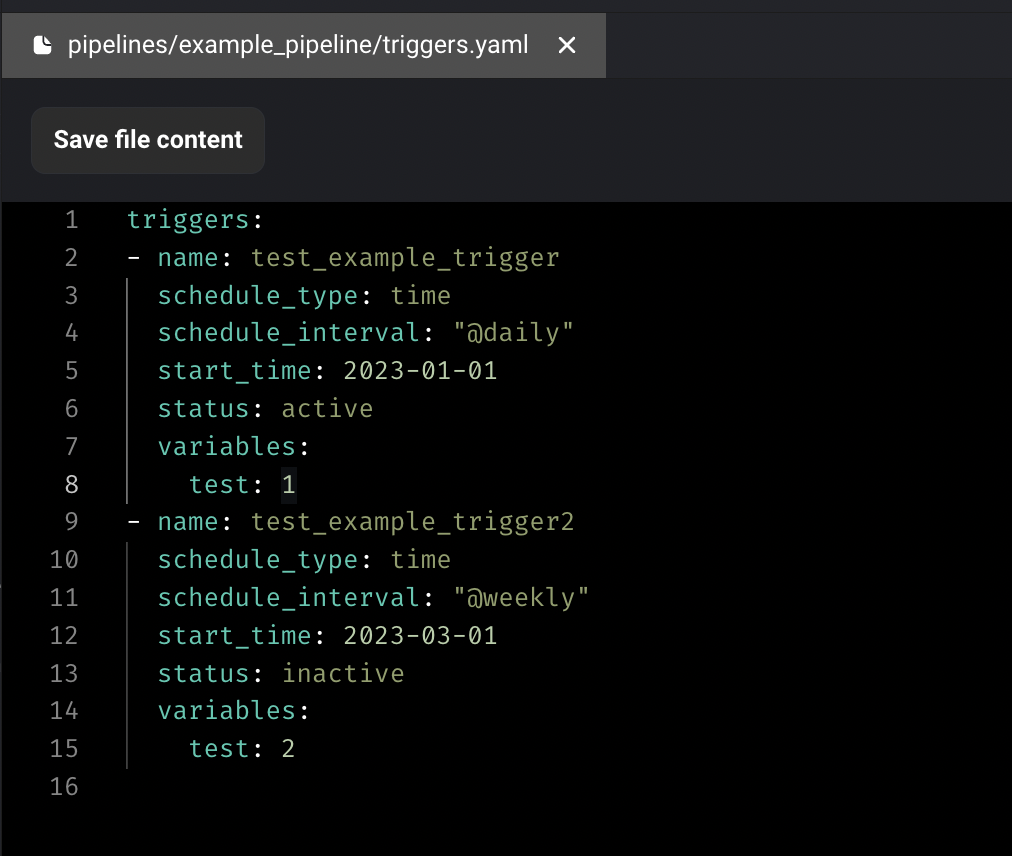
Doc: https://docs.mage.ai/guides/triggers/configure-triggers-in-code
Centralize server logger and add verbosity control
Shout out to Dhia Eddine Gharsallaoui for his contribution of centralizing the server loggings and adding verbosity control. User can control the verbosity level of the server logging by setting the SERVER_VERBOSITY environment variables. For example, you can set SERVER_VERBOSITY environment variable to ERROR to only print out errors.
Doc: https://docs.mage.ai/production/observability/logging#server-logging
Customize resource for Kubernetes executor
User can customize the resource when using the Kubernetes executor now by adding the executor_config to the block config in pipeline’s metadata.yaml.
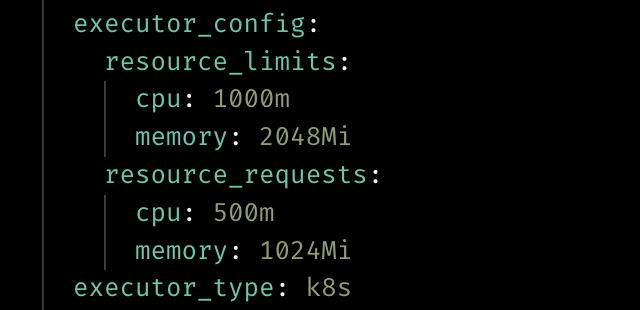
Doc: https://docs.mage.ai/production/configuring-production-settings/compute-resource#kubernetes-executor
Data integration pipelines
- Google sheets source: Fix loading sample data from Google Sheets
- Postgres source: Allow customizing the publication name for logical replication
- Google search console source: Support email field in google_search_console config
- BigQuery destination: Limit the number of subqueries in BigQuery query
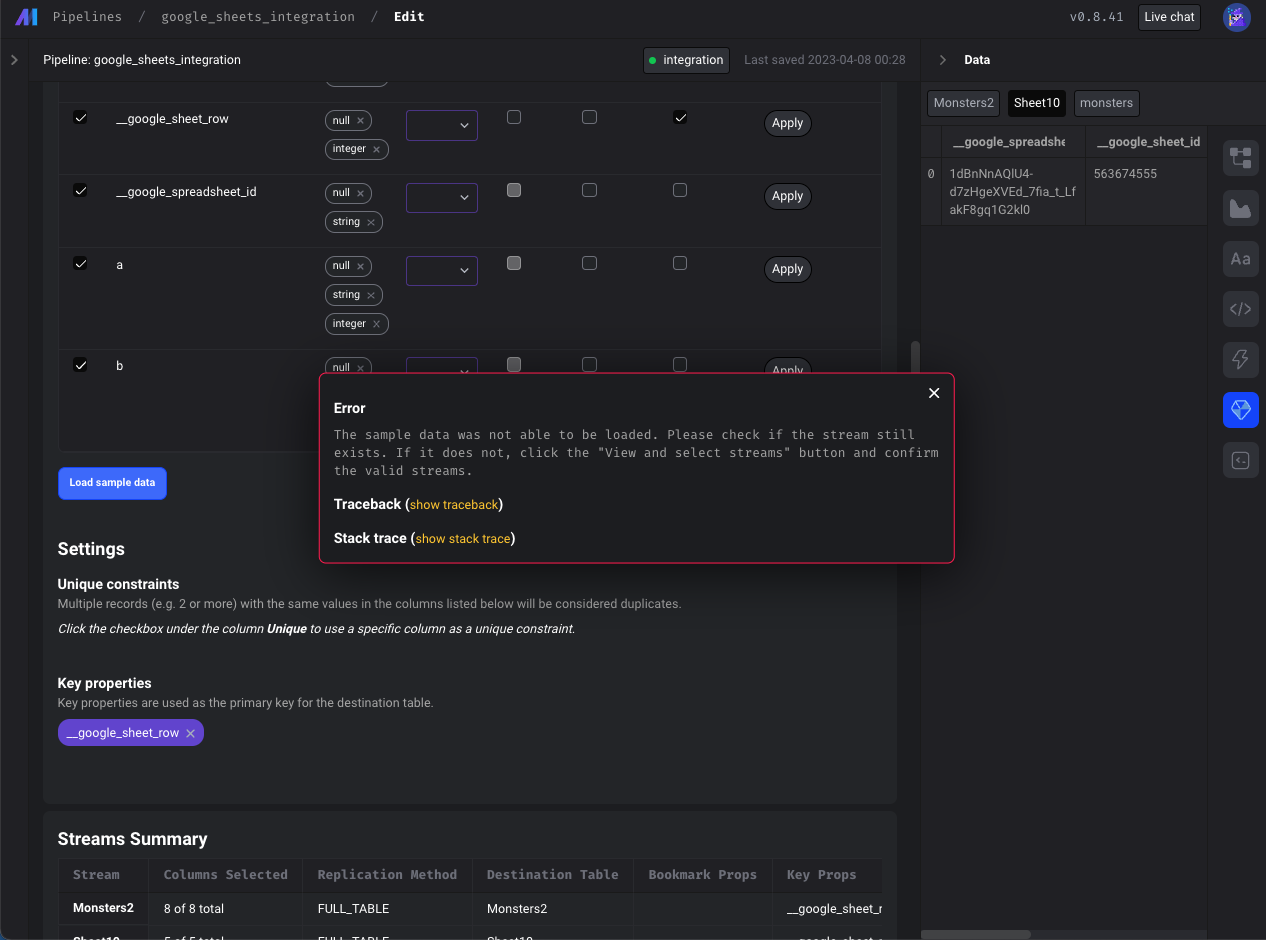
- Show more descriptive error (instead of
{}) when a stream that was previously selected may have been deleted or renamed. If a previously selected stream was deleted or renamed, it will still appear in theSelectStreamsmodal but will automatically be deselected and indicate that the stream is no longer available in red font. User needs to click "Confirm" to remove the deleted stream from the schema.
Terminal improvements
- Use named terminals instead of creating a unique terminal every time Mage connects to the terminal websocket.
- Update terminal for windows. Use
cmdshell command for windows instead of bash. Allow users to overwrite the shell command with theSHELL_COMMANDenvironment variable. - Support copy and pasting multiple commands in terminal at once.
- When changing the path in the terminal, don’t permanently change the path globally for all other processes.
- Show correct logs in terminal when installing requirements.txt.
DBT improvements
- Interpolate environment variables and secrets in DBT profile
Git improvements
- Update git to support multiple users
Postgres exporter improvements
- Support reordering columns when exporting a dataframe to Postgres
- Support specifying unique constraints when exporting the dataframe
with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader:
loader.export(
df,
schema_name,
table_name,
index=False,
if_exists='append',
allow_reserved_words=True,
unique_conflict_method='UPDATE',
unique_constraints=['col'],
)Other bug fixes & polish
- Fix chart loading errors.
- Allow pipeline runs to be canceled from UI.
- Fix raw SQL block trying to export upstream python block.
- Don’t require metadata for dynamic blocks.
- When editing a file in the file editor, disable keyboard shortcuts for notebook pipeline blocks.
- Increase autosave interval from 5 to 10 seconds.
- Improve vertical navigation fixed scrolling.
- Allow users to force delete block files. When attempting to delete a block file with downstream dependencies, users can now override the safeguards in place and choose to delete the block regardless.
View full Changelog
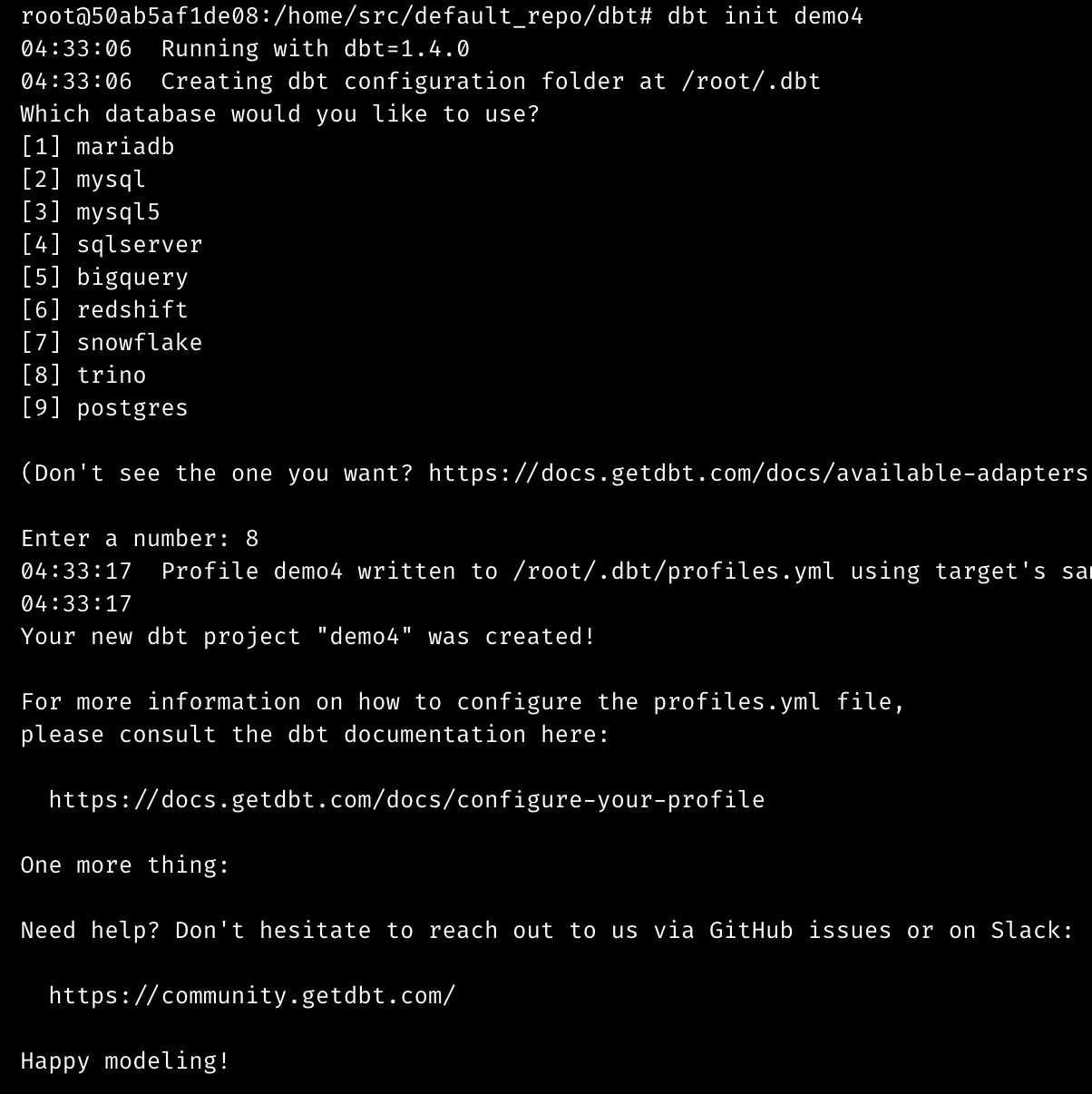
Release 0.8.37 | Foundation Release

Interactive terminal
The terminal experience is improved in this release, which adds new interactive features and boosts performance. Now, you can use the following interactive commands and more:
git add -pdbt init demogreat_expectations init
Data integration pipeline
New source: Google Ads
Shout out to Luis Salomão for adding the Google Ads source.
New source: Snowflake
New destination: Amazon S3
Bug Fixes
- In the MySQL source, map the Decimal type to Number.
- In the MySQL destination, use
DOUBLE PRECISIONinstead ofDECIMALas the column type for float/double numbers.
Streaming pipeline
New sink: Amazon S3
Doc: https://docs.mage.ai/guides/streaming/destinations/amazon-s3
Other improvements
-
Enable the logging of custom exceptions in the transformer of a streaming pipeline. Here is an example code snippet:
@transformer def transform(messages: List[Dict], *args, **kwargs): try: raise Exception('test') except Exception as err: kwargs['logger'].error('Test exception', error=err) return messages
-
Support cancelling running streaming pipeline (when pipeline is executed in PipelineEditor) after page is refreshed.
Alerting option for Google Chat
Shout out to Tim Ebben for adding the option to send alerts to Google Chat in the same way as Teams/Slack using a webhook.
Example config in project’s metadata.yaml
notification_config:
alert_on:
- trigger_failure
- trigger_passed_sla
slack_config:
webhook_url: ...How to create webhook url: https://developers.google.com/chat/how-tos/webhooks#create_a_webhook
Other bug fixes & polish
-
Prevent a user from editing a pipeline if it’s stale. A pipeline can go stale if there are multiple tabs open trying to edit the same pipeline or multiple people editing the pipeline at different times.
-
Fix bug: Code block scrolls out of view when focusing on the code block editor area and collapsing/expanding blocks within the code editor.
-
Fix bug: Sync UI is not updating the "rows processed" value.
-
Fix the path issue of running dynamic blocks on a Windows server.
-
Fix index out of range error in data integration transformer when filtering data in the transformer.
-
Fix issues of loading sample data in Google Sheets.
-
Fix chart blocks loading data.
-
Fix Git integration bugs:
- The confirm modal after clicking “synchronize data” was sometimes not actually running the sync, so removed that.
- Fix various git related user permission issues.
- Create local repo git path if it doesn’t exists already.
-
Add preventive measures for saving a pipeline:
- If the content that is about to be saved to a YAML file is invalid YAML, raise an exception.
- If the block UUIDs from the current pipeline and the content that is about to be saved differs, raise an exception.
-
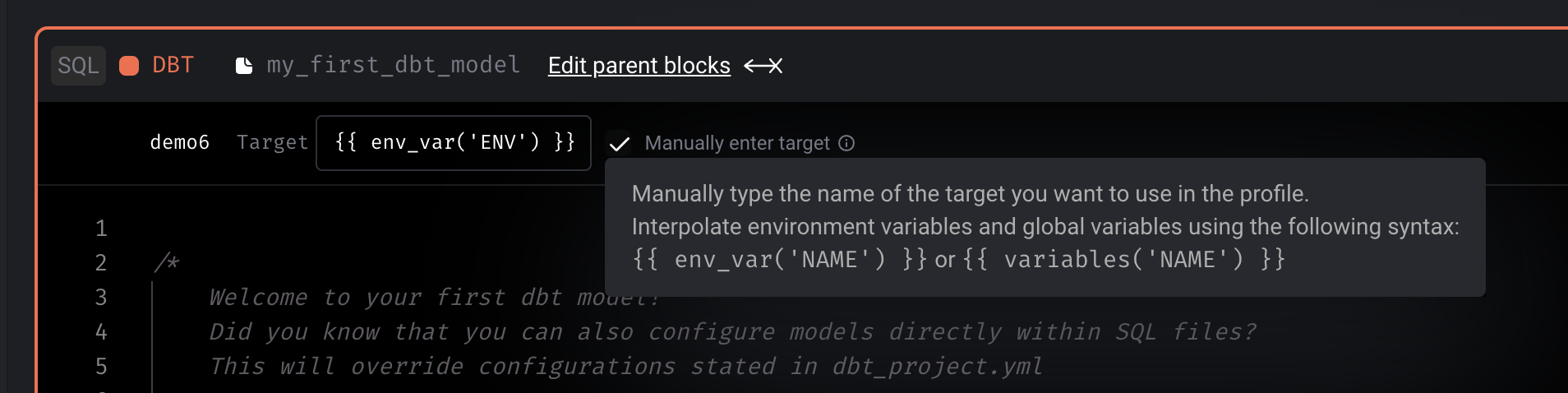
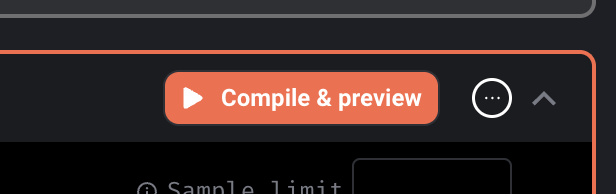
DBT block
- Support DBT staging. When a DBT model runs and if it’s configured to use a schema with a suffix, Mage will now take that into account when fetching a sample of the model at the end of the block run.
- Fix
Circular reference detectedissue with DBT variables. - Manually input DBT block profile to allow variable interpolation.
- Show DBT logs when running compile and preview.
-
SQL block
- Don’t limit raw SQL query; allow all rows to be retrieved.
- Support SQL blocks passing data to downstream SQL blocks with different data providers.
- Raise an exception if a raw SQL block is trying to interpolate an upstream raw SQL block from a different data provider.
- Fix date serialization from 1 block to another.
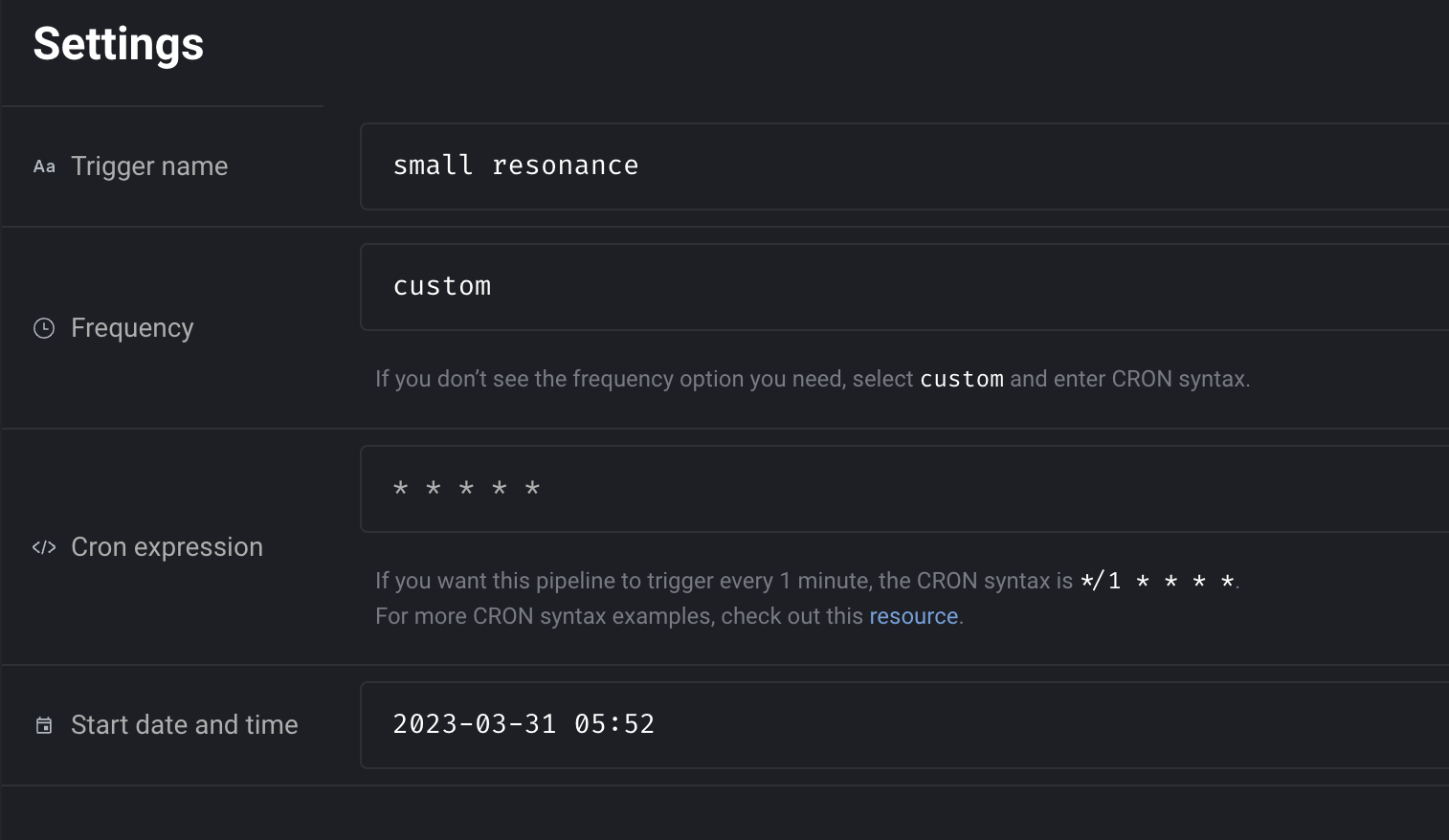
-
Add helper for using CRON syntax in trigger setting.
- Document internal API endpoints for development and contributions: https://docs.mage.ai/contributing/backend/api/overview
View full Changelog
Release 0.8.29 | Wick Release

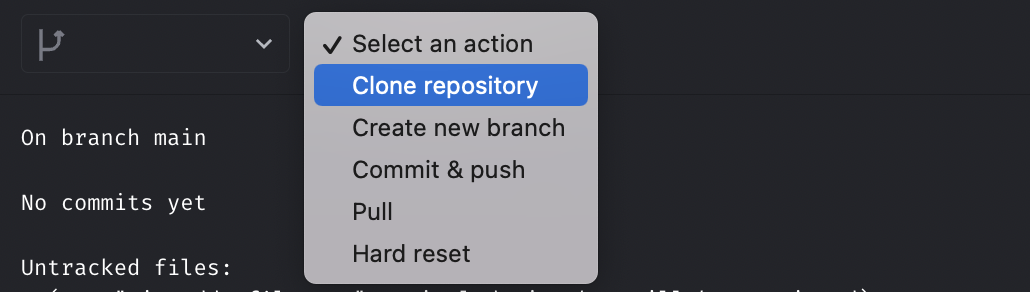
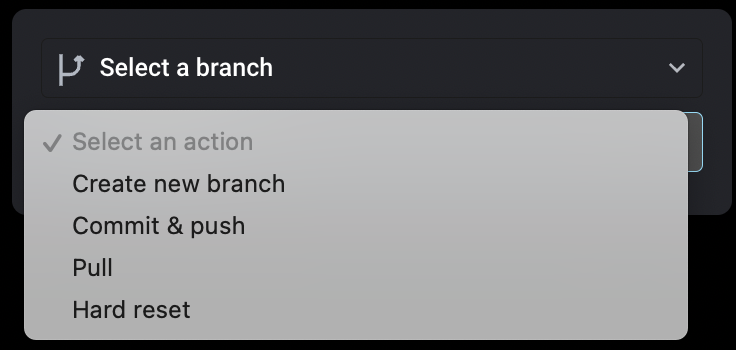
Commit, push and pull code changes between Mage and Github/Gitlab repository
Mage supports Github/Gitlab integration via UI now. You can perform the following actions with the UI.
- Create new branch
- Commit & push
- Pull
- Hard reset
Doc on setting up integration: https://docs.mage.ai/production/data-sync/git

Deploy Mage using AWS CodeCommit and AWS CodeDeploy
Add terraform templates for deploying Mage to ECS from a CodeCommit repo with AWS CodePipeline. It will create 2 separate CodePipelines, one for building a docker image to ECR from a CodeCommit repository, and another one for reading from ECR and deploying to ECS.
Docs on using the terraform templates: https://docs.mage.ai/production/deploying-to-cloud/aws/code-pipeline
Use ECS task roles for AWS authentication
When you run Mage on AWS, instead of using hardcoded API keys, you can also use ECS task role to authenticate with AWS services.
Opening http://localhost:6789/ automatically
Shout out to Bruno Gonzalez for his contribution of supporting automatically opening Mage in a browser tab when using mage start command in your laptop.
Github issue: #2233
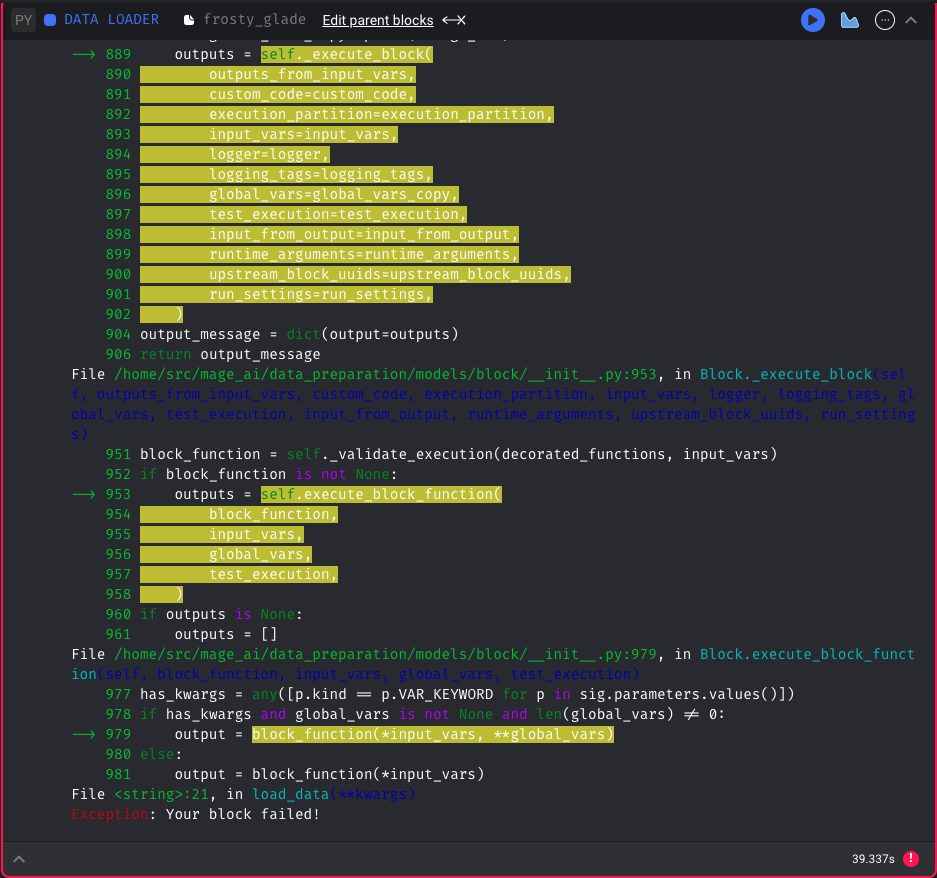
Update notebook error display
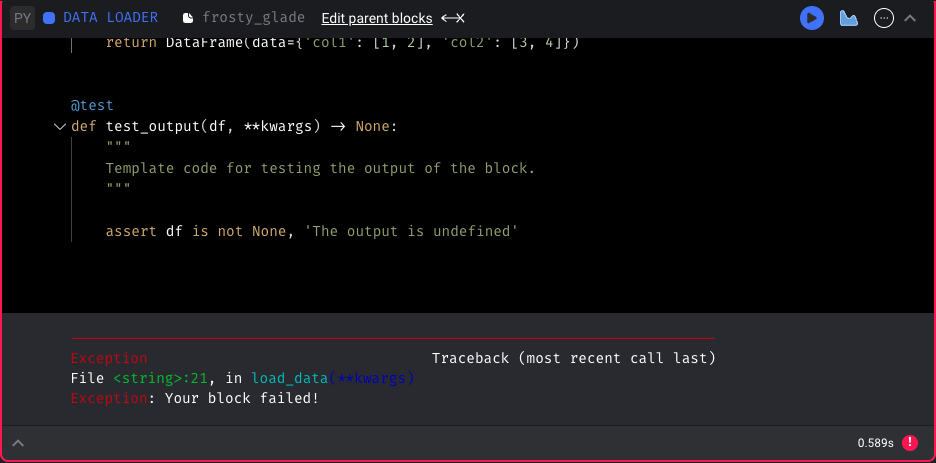
When executing a block in the notebook and an error occurs, show the stack trace of the error without including the custom code wrapper (useless information).
Before:
After:
Data integration pipeline improvements
MySQL
- Add Mage automatically created columns to destination table if table already exists in MySQL.
- Don’t lower case column names for MySQL destination.
Commercetools
- Add inventory stream for Commercetools source.
Outreach
- Fix outreach source rate limit issue.
Snowflake
- Fix Snowflake destination column comparison when altering table. Use uppercase for column names if
disable_double_quotesis True. - Escape single quote when converting array values.
Streaming pipeline improvements
- Truncate print messages in execution output to prevent freezing the browser.
- Disable keyboard shortcuts in streaming pipelines to run blocks.
- Add async handler to streaming source base class. You can set
consume_method = SourceConsumeMethod.READ_ASYNCin your streaming source class. Then it'll use read_async method.
Pass event variable to kwargs for event trigger pipelines
Mag supports triggering pipelines on AWS events. Now, you can access the raw event data in block method via kwargs['event'] . This enhancement enables you to easily customize your pipelines based on the event trigger and to handle the event data as needed within your pipeline code.
Other bug fixes & polish
- Fix “Circular import” error of using the
secret_varin repo's metadata.yaml - Fix bug: Tooltip at very right of Pipeline Runs or Block Runs graphs added a horizontal overflow.
- Fix bug: If an upstream dependency was added on the Pipeline Editor page, stale upstream connections would be updated for a block when executing a block via keyboard shortcut (i.e. cmd/ctrl+enter) inside the block code editor.
- Cast column types (int, float) when reading block output Dataframe.
- Fix block run status caching issue in UI. Mage UI sometimes fetched stale block run statuses from backend, which is misleading. Now, the UI always fetches the latest block run status without cache.
- Fix timezone mismatch issue for pipeline schedule execution date comparison so that there’re no duplicate pipeline runs created.
- Fix bug: Sidekick horizontal scroll bar not wide enough to fit 21 blocks when zoomed all the way out.
- Fix bug: When adding a block between two blocks, if the first block was a SQL block, it would use the SQL block content to create a block regardless of the block language.
- Fix bug: Logs for pipeline re-runs were not being filtered by timestamp correctly due to execution date of original pipeline run being used for filters.
- Increase canvas size of dependency graph to accommodate more blocks / blocks with long names.
View full Changelog
Release 0.8.27 | Shazam Release
Great Expectations integration
Mage is now integrated with Great Expectations to test the data produced by pipeline blocks.
You can use all the expectations easily in your Mage pipeline to ensure your data quality.
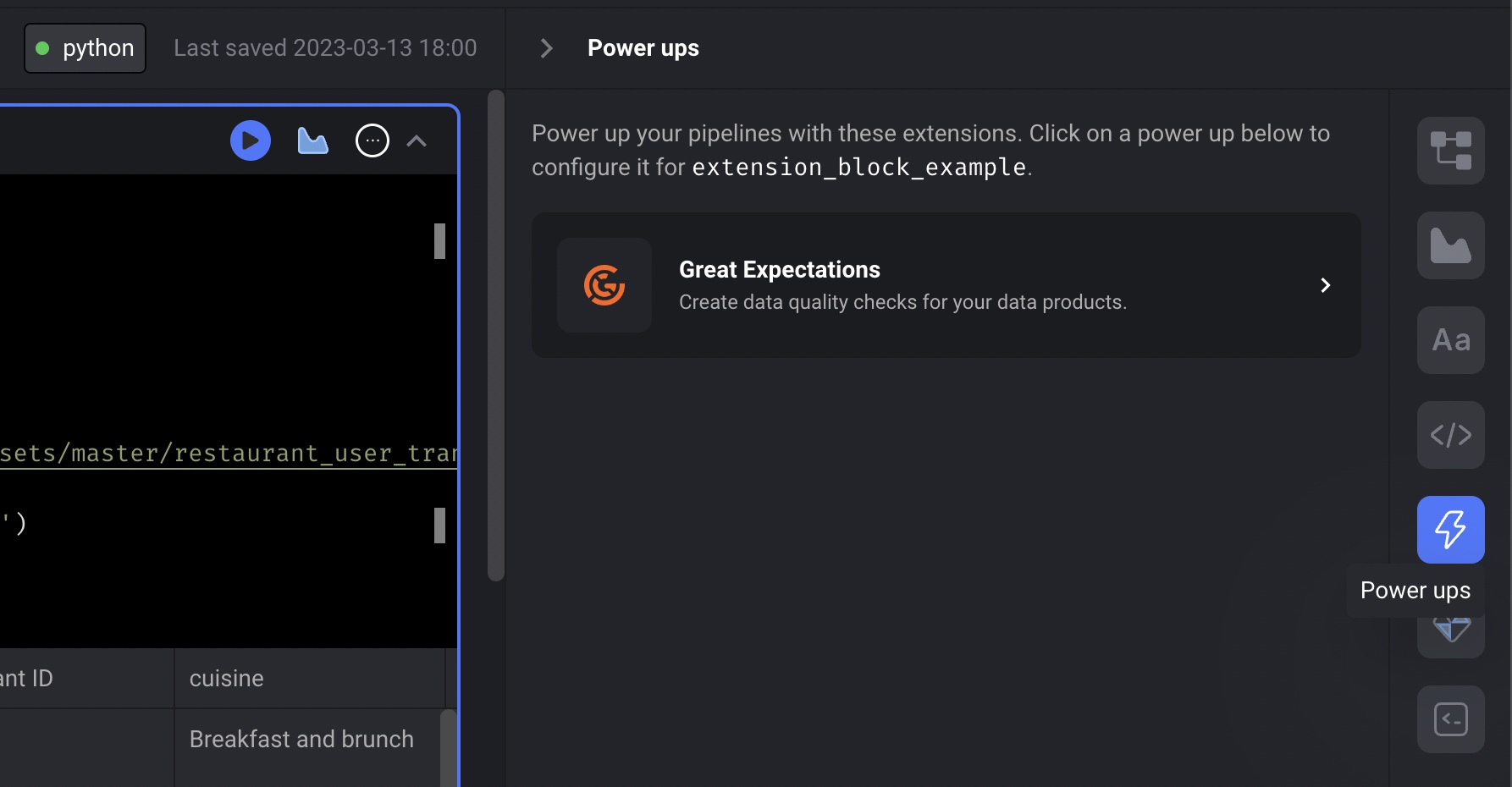
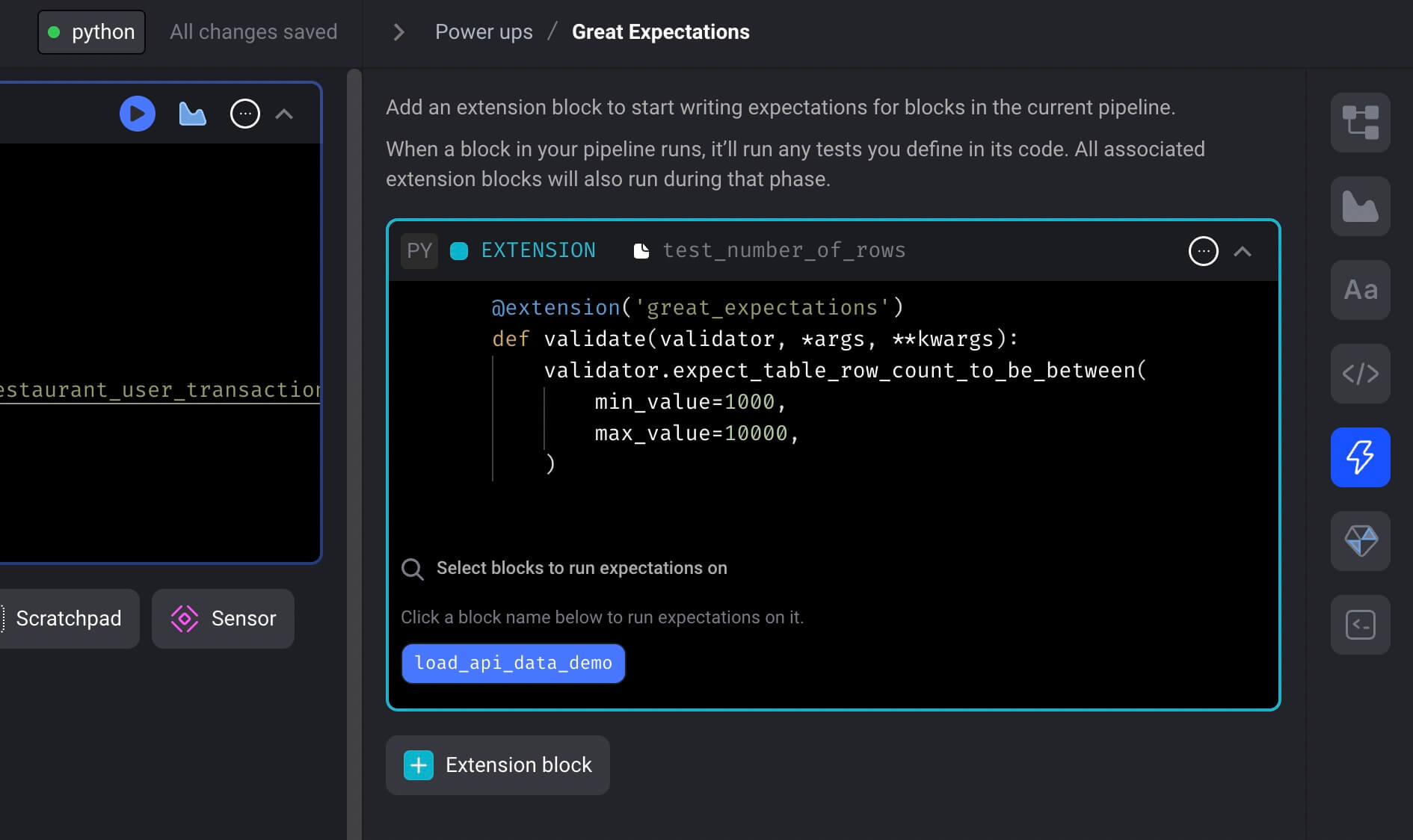
Follow the doc to add expectations to your pipeline to run tests for your block output.
Pipeline dashboard updates
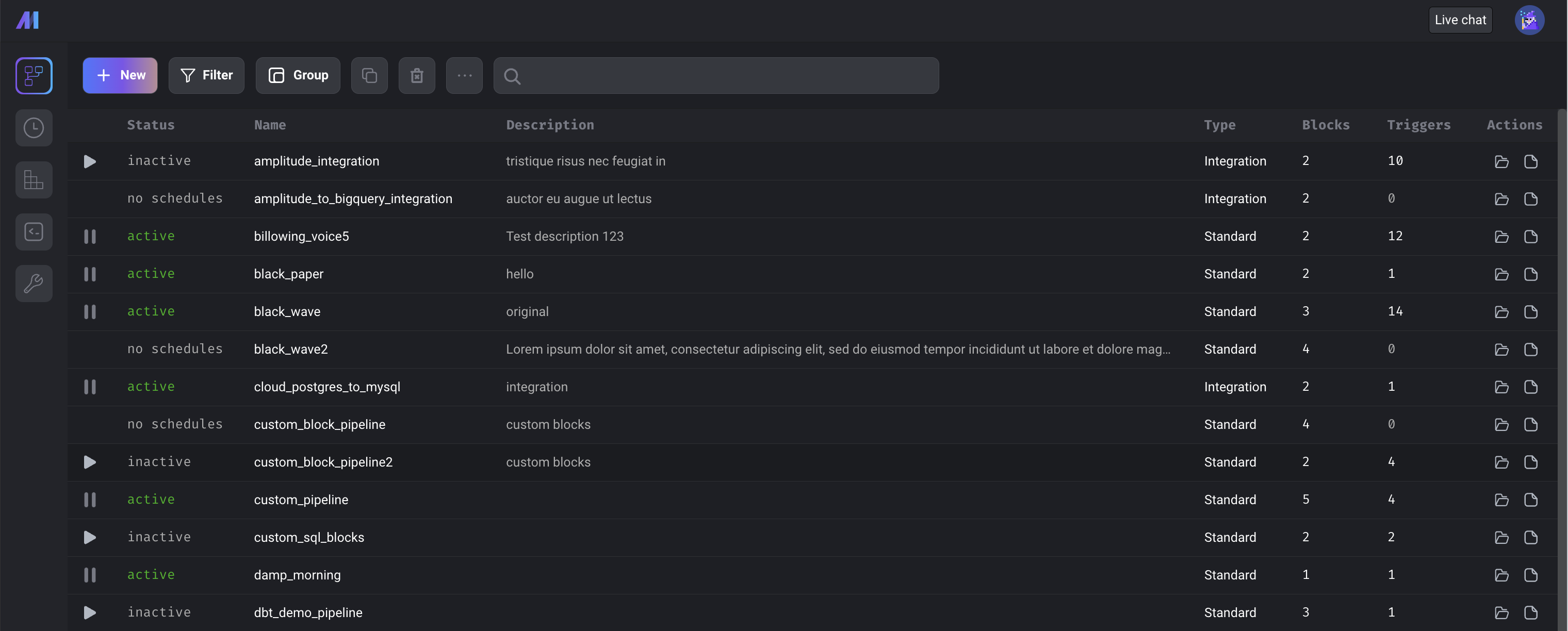
-
Added pipeline description.
-
Single click on a row no longer opens a pipeline. In order to open a pipeline now, users can double-click a row, click on the pipeline name, or click on the open folder icon at the end of the row.
-
Select a pipeline row to perform an action (e.g. clone, delete, rename, or edit description).
- Clone pipeline (icon with 2 overlapping squares) - Cloning the selected pipeline will create a new pipeline with the same configuration and code blocks. The blocks use the same block files as the original pipeline. Pipeline triggers, runs, backfills, and logs are not copied over to the new pipeline.
- Delete pipeline (trash icon) - Deletes selected pipeline
- Rename pipeline (item in dropdown menu under ellipsis icon) - Renames selected pipeline
- Edit description (item in dropdown menu under ellipsis icon) - Edits pipeline description. Users can hover over the description in the table to view more of it.
-
Users can click on the file icon under the
Actionscolumn to go directly to the pipeline's logs. -
Added search bar which searches for text in the pipeline
uuid,name, anddescriptionand filters the pipelines that match. -
The create, update, and delete actions are not accessible by Viewer roles.
-
Added badge in Filter button indicating number of filters applied.
-
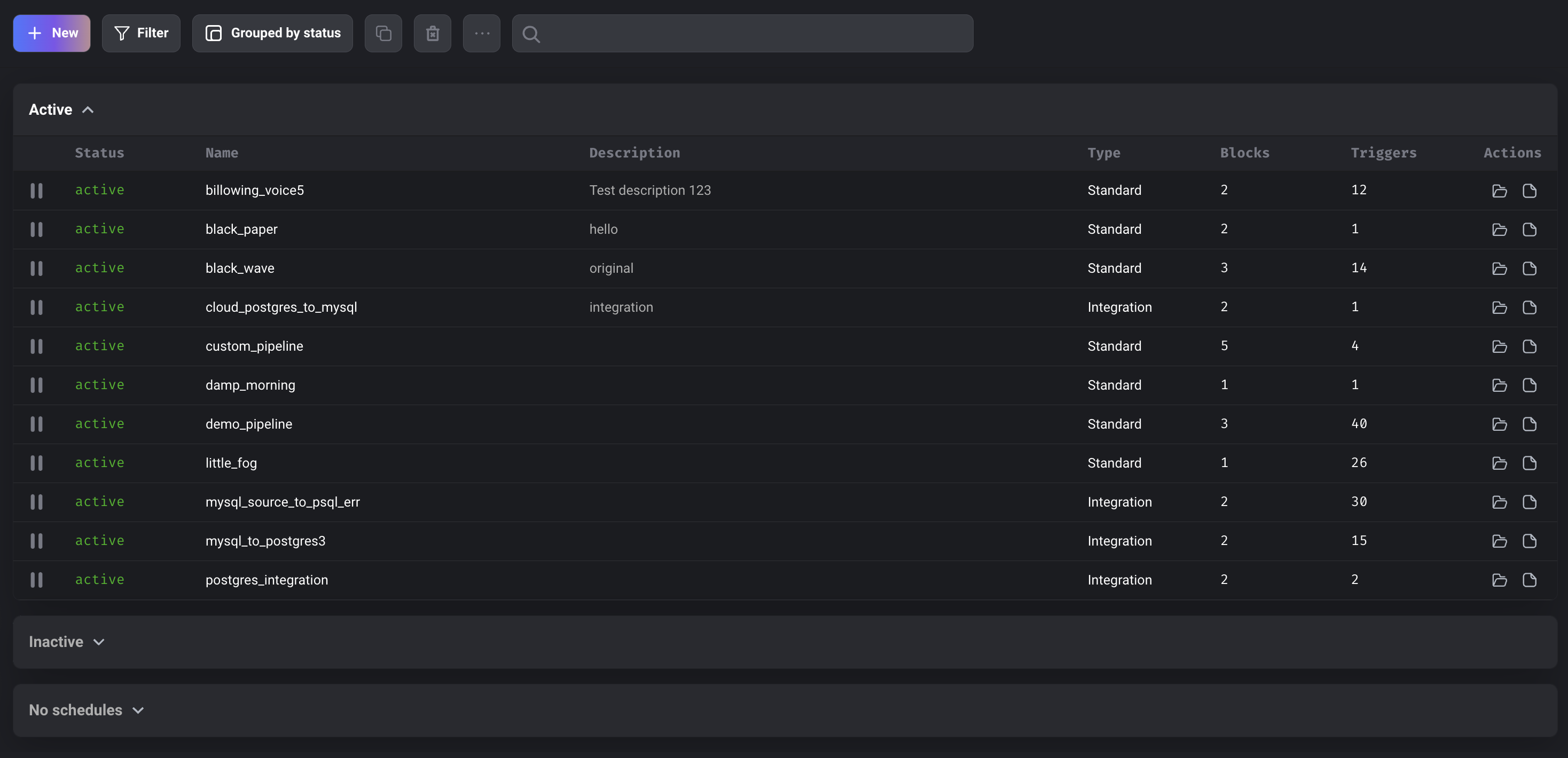
Group pipelines by
statusortype.

SQL block improvements
Toggle SQL block to not create table
Users can write raw SQL blocks and only include the INSERT statement. CREATE TABLE statement isn’t required anymore.
Support writing SELECT statements in SQL using raw SQL
Users can write SELECT statements using raw SQL in SQL blocks now.
Find all supported SQL statements using raw SQL in this doc.
Support for ssh tunnel in multiple blocks
When using SSH tunnel to connect to Postgres database, SSH tunnel was originally only supported in block run at a time due to port conflict. Now Mage supports SSH tunneling in multiple blocks by finding the unused port as the local port. This feature is also supported in Python block when using mage_ai.io.postgres module.
Data integration pipeline
New source: Pipedrive
Shout out to Luis Salomão for his continuous contribution to Mage. The new source Pipedrive is available in Mage now.
Fix BigQuery “query too large” error
Add check for size of query since that can potentially exceed the limit.
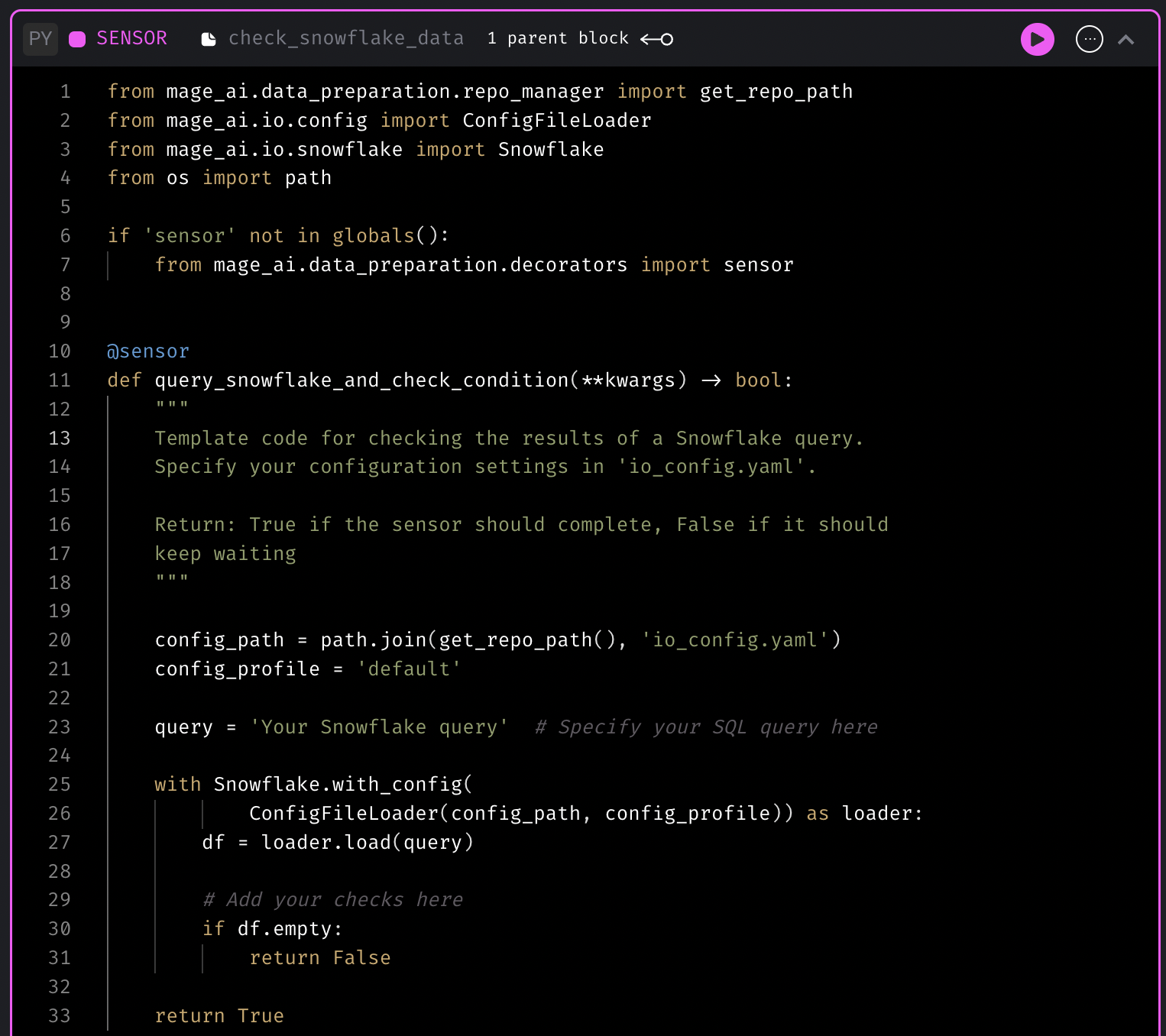
New sensor templates
Sensor block is used to continuously evaluate a condition until it’s met. Mage now has more sensor templates to check whether data lands in S3 bucket or SQL data warehouses.
Sensor template for checking if a file exists in S3
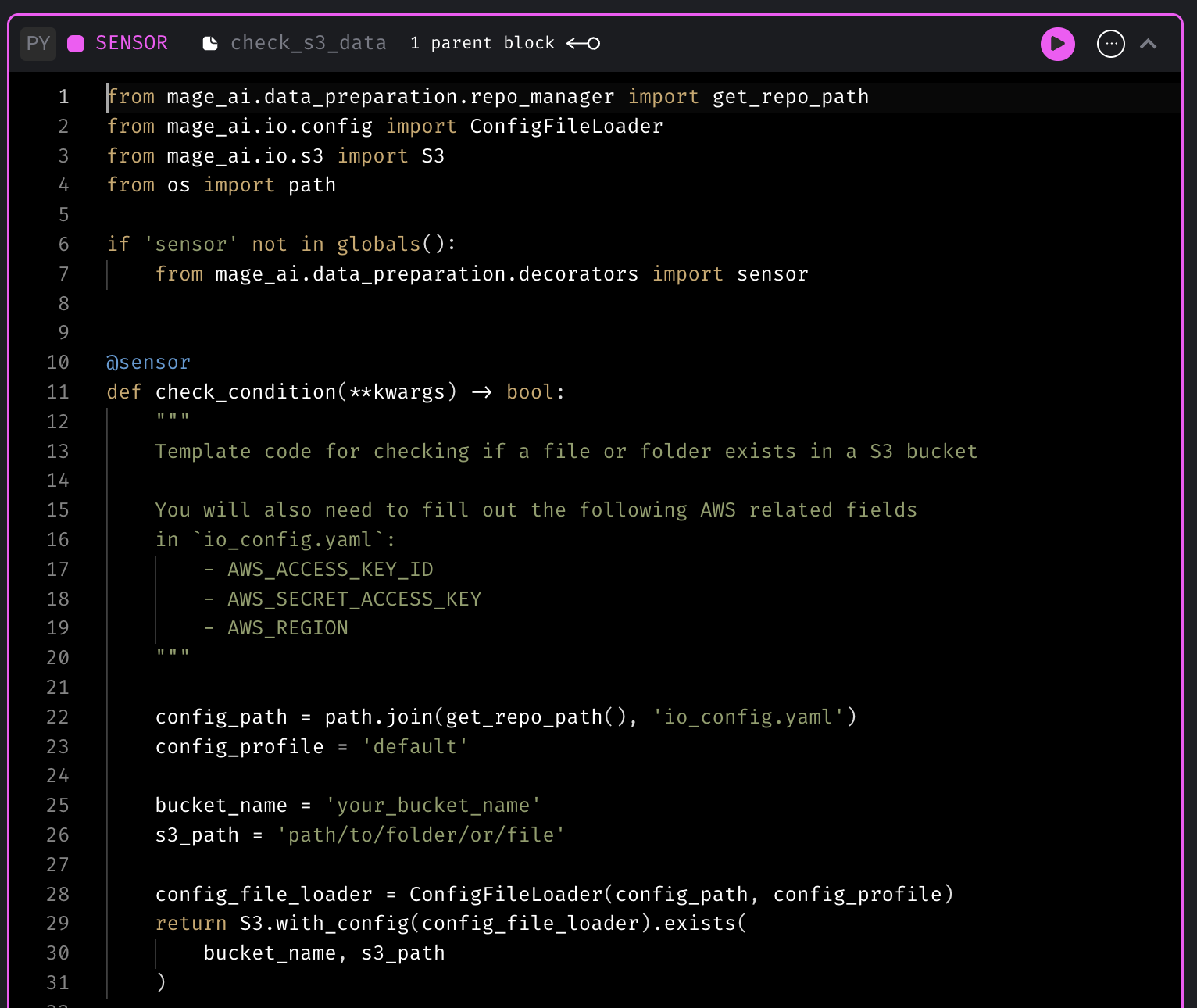
Sensor template for checking the data in SQL data warehouse
Support for Spark in standalone mode (self-hosted)
Mage can connect to a standalone Spark cluster and run PySpark code on it. You can set the environment variable SPARK_MASTER_HOST in your Mage container or instance. Then running PySpark code in a standard batch pipeline will work automagically by executing the code in the remote Spark cluster.
Follow this doc to set up Mage to connect to a standalone Spark cluster.
Mask environment variable values with stars in output
Mage now automatically masks environment variable values with stars in terminal output or block output to prevent showing sensitive data in plaintext.

Other bug fixes & polish
-
Improve streaming pipeline logging
- Show streaming pipeline error logging
- Write logs to multiple files
-
Provide the working NGINX config to allow Mage WebSocket traffic.
location / { proxy_pass http://127.0.0.1:6789; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "Upgrade"; proxy_set_header Host $host; } -
Fix raw SQL quote error.
-
Add documentation for developer to add a new source or sink to streaming pipeline: https://docs.mage.ai/guides/streaming/contributing
View full Changelog
Release 0.8.24 | Merlin Release
Disable editing files or executing code in production environment
You can configure Mage to not allow any edits to pipelines or blocks in production environment. Users will only be able to create triggers and view the existing pipelines.
Doc: https://docs.mage.ai/production/configuring-production-settings/overview#read-only-access
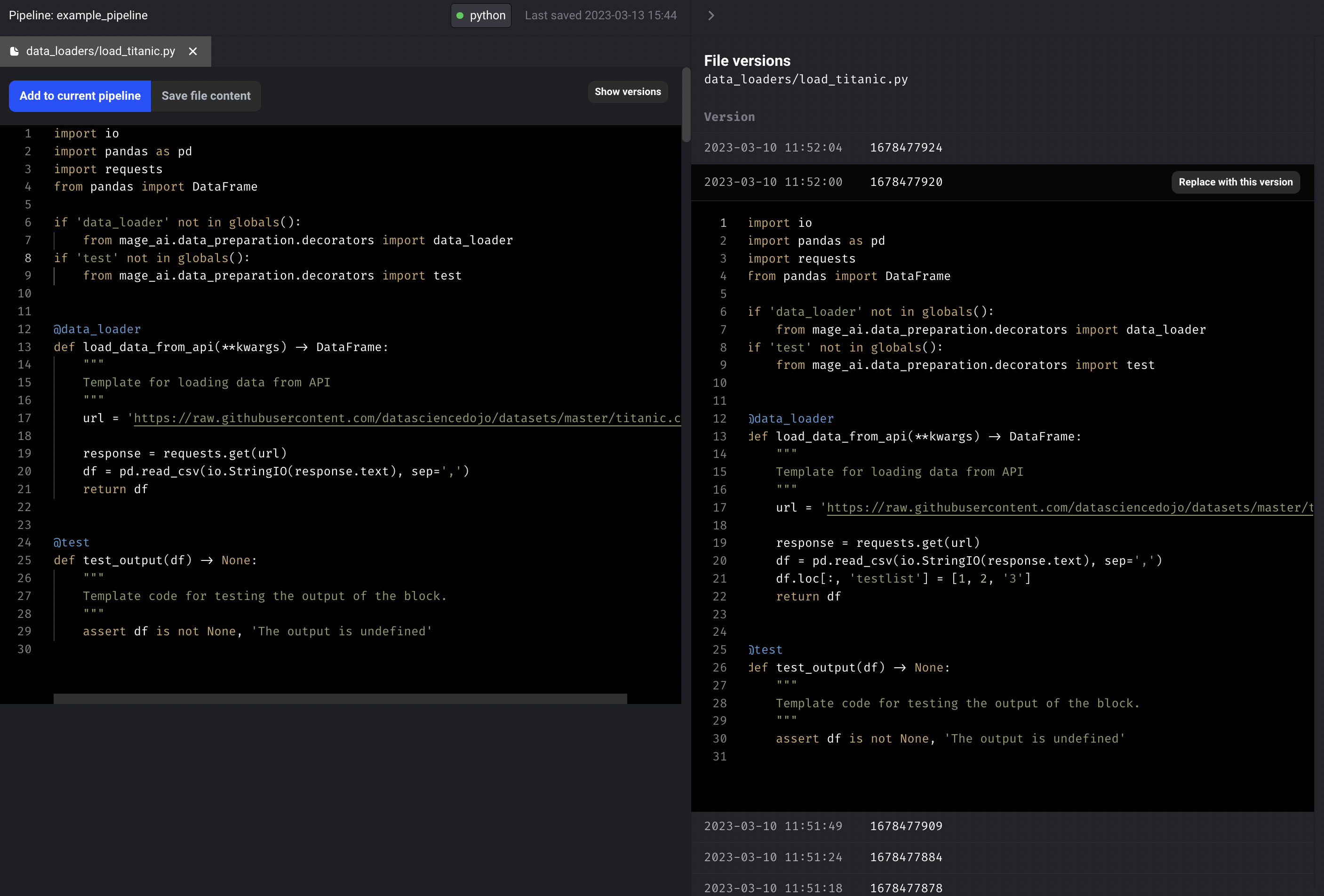
Pipeline and file versioning
- Create versions of a file for every create or update to the content. Display the versions and allow user to update current file content to a specific file version. Doc: https://docs.mage.ai/development/versioning/file-versions
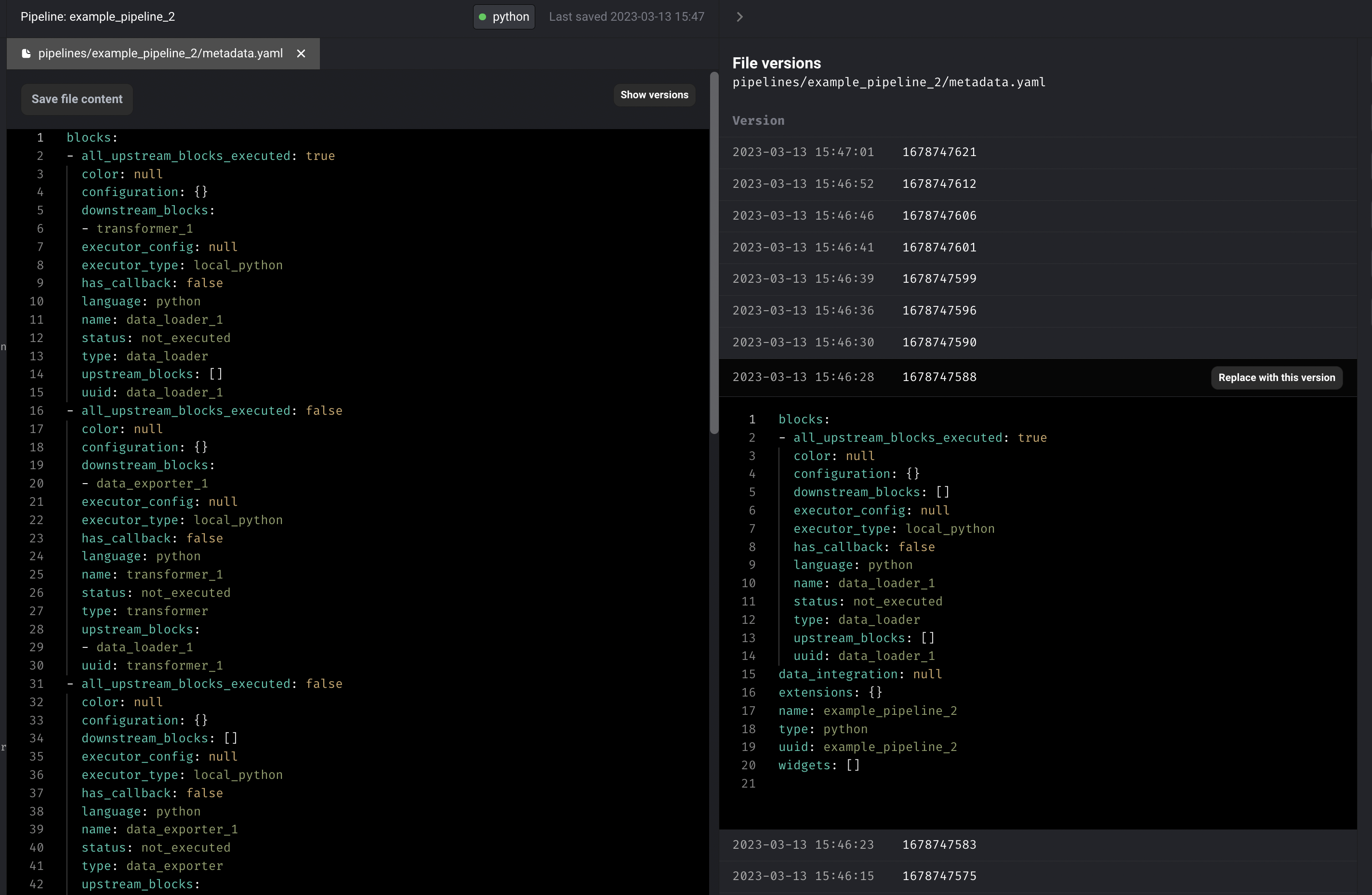
- Support pipeline file versioning. Display the historical pipeline versions and allow user to roll back to a previous pipeline version if pipeline config is messed up.
Support LDAP authentication
Shout out to Dhia Eddine Gharsallaoui for his contribution of adding LDAP authentication method to Mage. When LDAP authentication is enabled, users will need to provide their LDAP credentials to log in to the system. Once authenticated, Mage will use the authorization filter to determine the user’s permissions based on their LDAP group membership.
Follow the guide to set up LDAP authentication.
DBT support for SQL Server
Support running SQL Server DBT models in Mage.
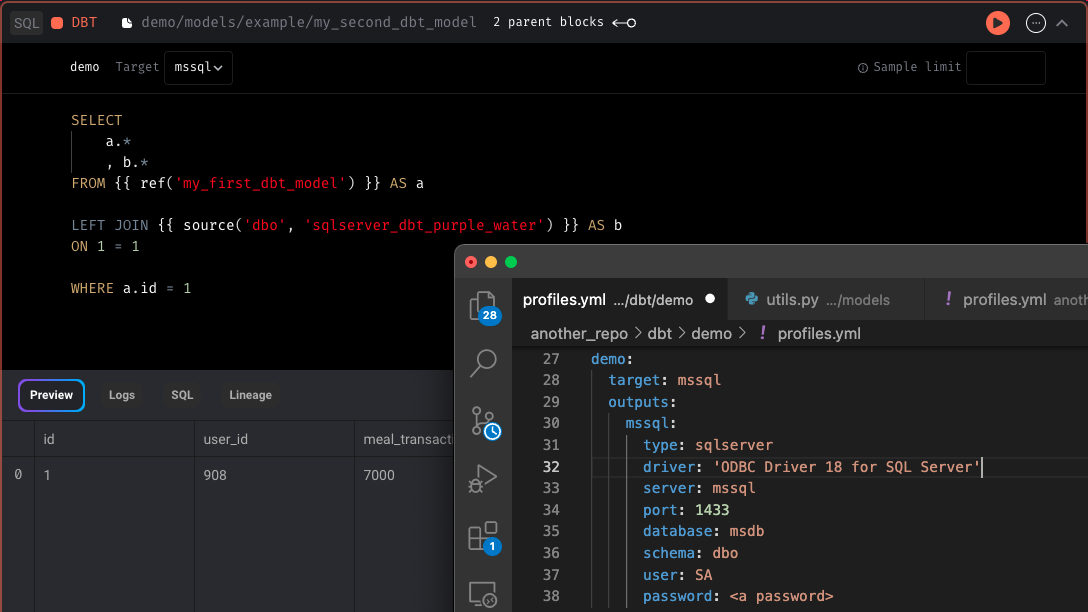
Tutorial for setting up a DBT project in Mage: https://docs.mage.ai/tutorials/setup-dbt
Helm deployment
Mage can now be deployed to Kubernetes with Helm: https://mage-ai.github.io/helm-charts/
How to install Mage Helm charts
helm repo add mageai https://mage-ai.github.io/helm-charts
helm install my-mageai mageai/mageaiTo customize the mount volume for Mage container, you’ll need to customize the values.yaml
-
Get the
values.yamlwith the commandhelm show values mageai/mageai > values.yaml -
Edit the
volumesconfig invalues.yamlto mount to your Mage project path
Doc: https://docs.mage.ai/production/deploying-to-cloud/using-helm
Integration with Spark running in the same Kubernetes cluster
When you run Mage and Spark in the same Kubernetes cluster, you can set the environment variable SPARK_MASTER_HOST to the url of the master node of the Spark cluster in Mage container. Then you’ll be able to connect Mage to your Spark cluster and execute PySpark code in Mage.
Follow this guide to use Mage with Spark in Kubernetes cluster.
Improve Kafka source and sink for streaming pipeline
- Set api_version in Kafka source and Kafka destination
- Allow passing raw message value to transformer so that custom deserialization logic can be applied in transformer (e.g. custom Protobuf deserialization logic).
Data integration pipeline
- Add more streams to Front app source
- Channels
- Custom Fields
- Conversations
- Events
- Rules
- Fix Snowflake destination alter table command errors
- Fix MySQL source bytes decode error
Pipeline table filtering
Add filtering (by status and type) for pipelines.


Renaming a pipeline transfers all the existing triggers, variables, pipeline runs, block runs, etc to the new pipeline
- When renaming a pipeline, transfer existing triggers, backfills, pipeline runs, and block runs to the new pipeline name.
- Prevent users from renaming pipeline to a name already in use by another pipeline.
Update the variable tab with more instruction for SQL and R variables
- Update the Variables tab with more instruction for SQL and R variables.
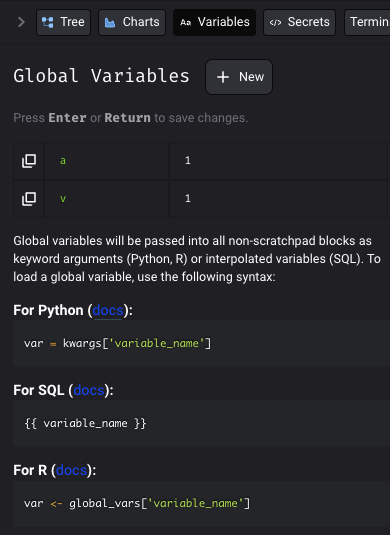
- Improve SQL/R block upstream block interpolation helper hints.
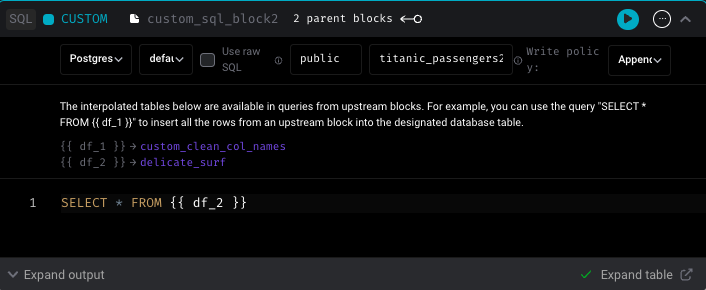
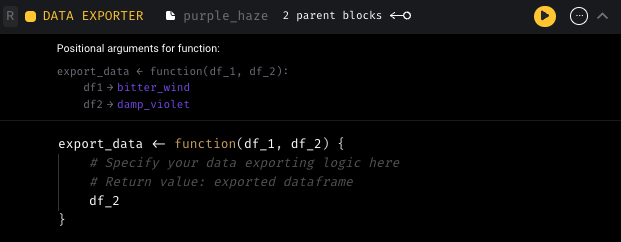
Other bug fixes & polish
- Update sidekick to have a vertical navigation
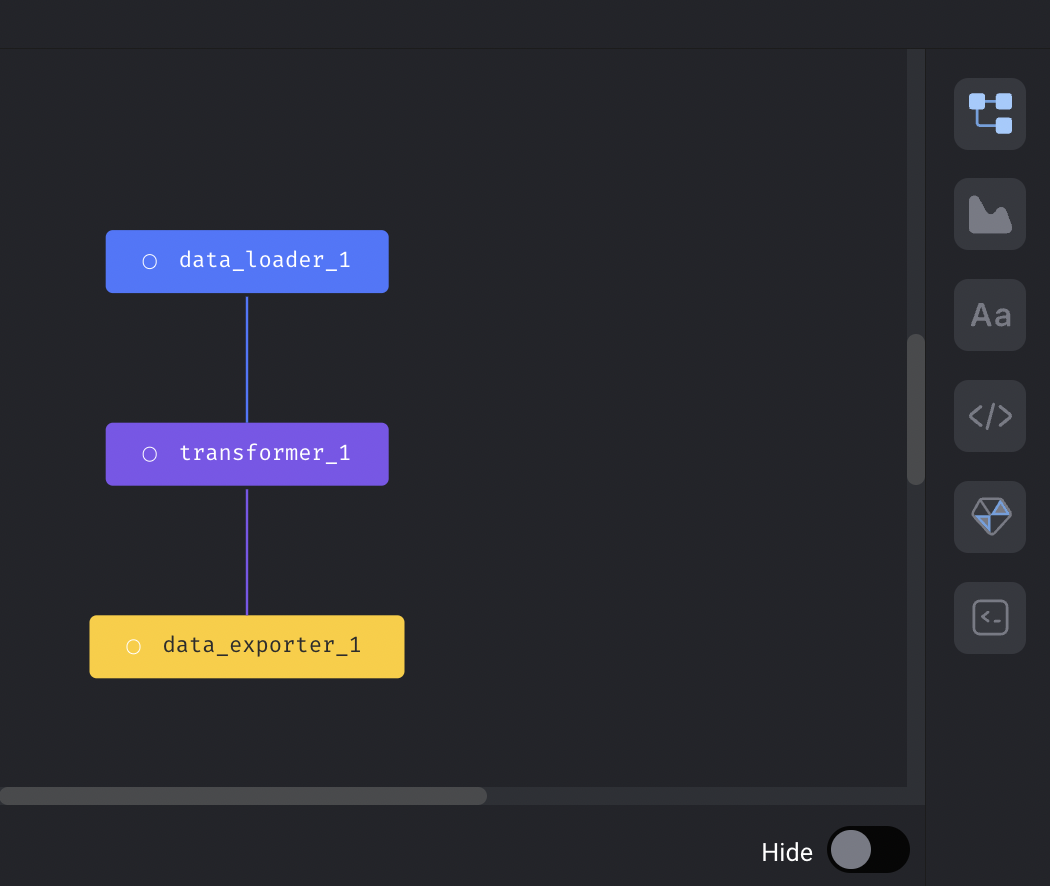
- Fix
Allow blocks to failsetting for pipelines with dynamic blocks. - Git sync: Overwrite origin url with the user's remote_repo_link if it already exists.
- Resolve DB model refresh issues in pipeline scheduler
- Fix bug: Execute pipeline in Pipeline Editor gets stuck at first block.
- Use the upstream dynamic block’s block metadata as the downstream child block’s kwargs.
- Fix using reserved words as column names in mage.io Postgres export method
- Fix error
sqlalchemy.exc.PendingRollbackError: Can't reconnect until invalid transaction is rolled back.in API middleware - Hide "custom" add block button in streaming pipelines.
- Fix bug: Paste not working in Firefox browser (https) (Error: "navigator.clipboard.read is not a function").
View full Changelog
Release 0.8.15 | Creed Release
Allow pipeline to keep running even if other unrelated blocks fail
Mage pipeline used to stop running if any of the block run failed. A setting was added to continue running the pipeline even if a block in the pipeline fails during the execution.
Check out the doc to learn about the additional settings of a trigger.
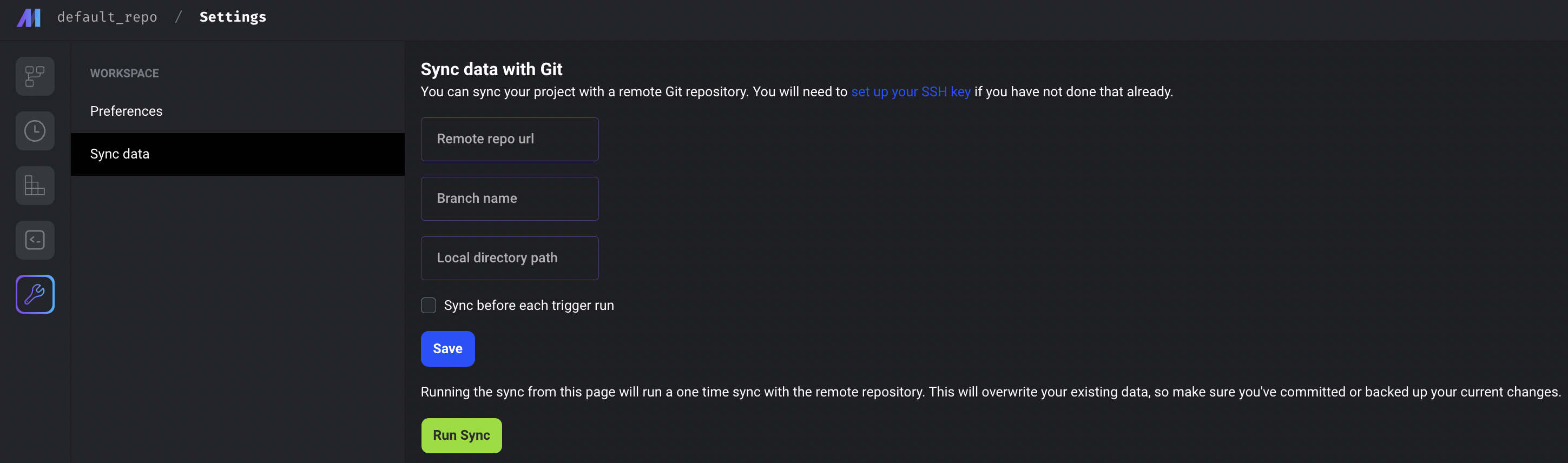
Sync project with Github
If you have your pipeline data stored in a remote repository in Github, you can sync your local project with the remote repository through Mage.
Follow the doc to set up the sync with Github.
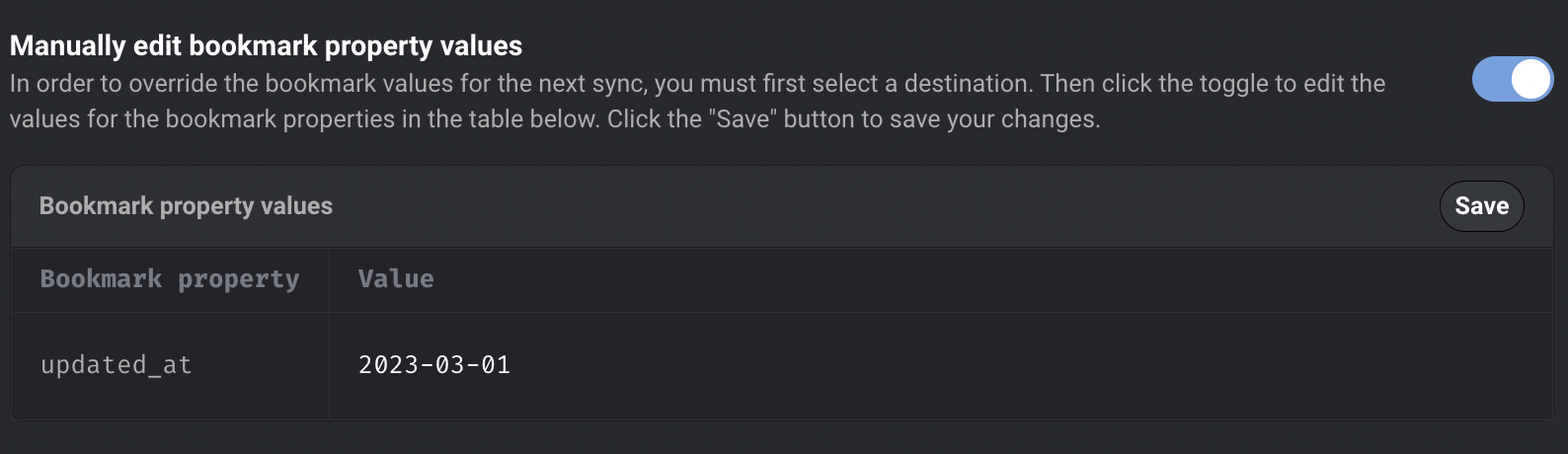
Data integration pipeline
Edit bookmark property values for data integration pipeline from the UI
Edit bookmark property values from UI. User can edit the bookmark values, which will be used as a bookmark for the next sync. The bookmark values will automatically update to the last record synced after the next sync is completed. Check out the doc to learn about how to edit bookmark property values.
Improvements on existing sources and destinations
-
Use TEXT instead of VARCHAR with character limit as the column type in Postgres destination
-
Show a loader on a data integration pipeline while the list of sources and destinations are still loading

Streaming pipeline
Deserialize Protobuf messages in Kafka’s streaming source
Specify the Protobuf schema class path in the Kafka source config so that Mage can deserialize the Protobuf messages from Kafka.
Doc: https://docs.mage.ai/guides/streaming/sources/kafka#deserialize-message-with-protobuf-schema
Add Kafka as streaming destination
Doc: https://docs.mage.ai/guides/streaming/destinations/kafka
Ingest data to Redshift via Kinesis
Mage doesn’t directly stream data into Redshift. Instead, Mage can stream data to Kinesis. You can configure streaming ingestion for your Amazon Redshift cluster and create a materialized view using SQL statements.
Doc: https://docs.mage.ai/guides/streaming/destinations/redshift
Cancel all running pipeline runs for a pipeline
Add the button to cancel all running pipeline runs for a pipeline.
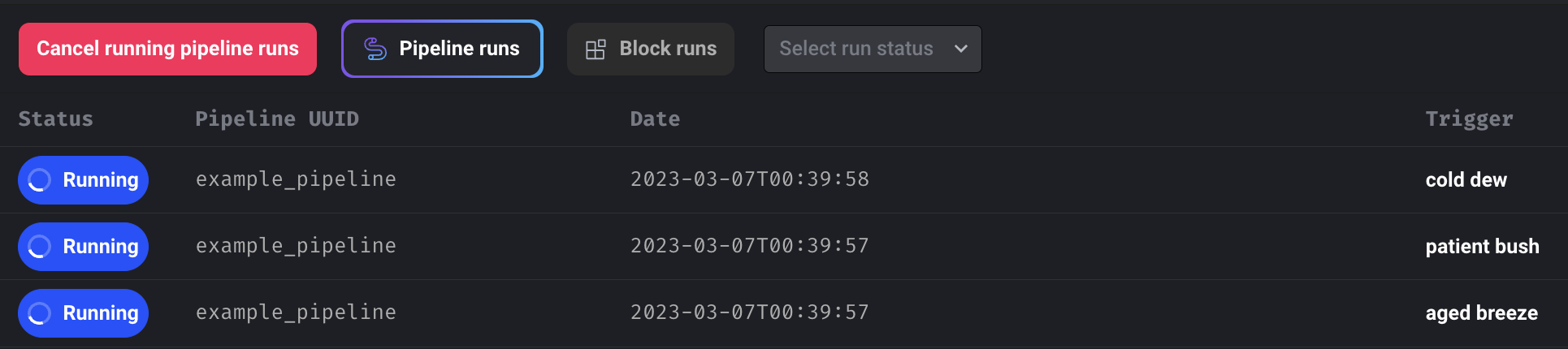
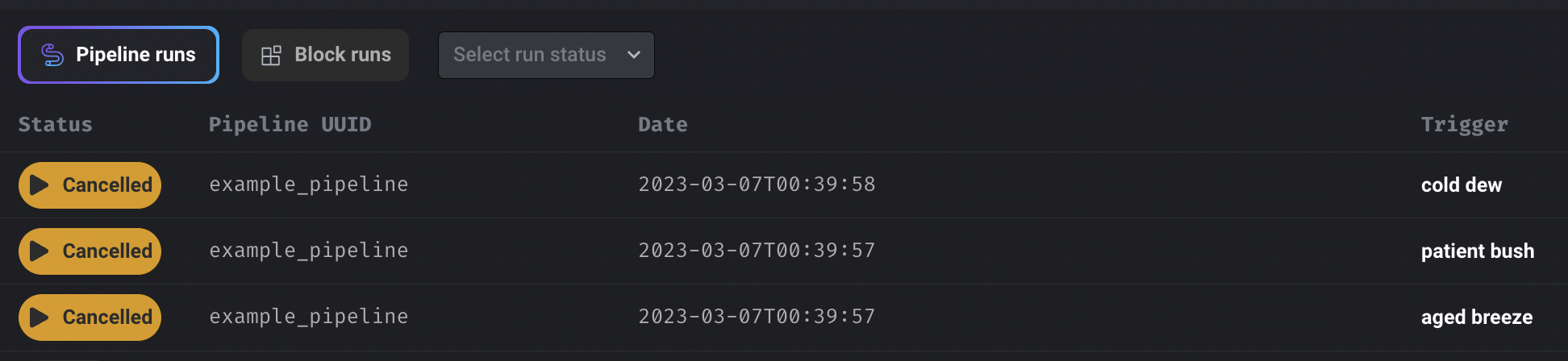
Other bug fixes & polish
-
For the viewer role, don’t show the edit options for the pipeline
-
Show “Positional arguments for decorated function” preview for custom blocks
-
Disable notebook keyboard shortcuts when typing in input fields in the sidekick
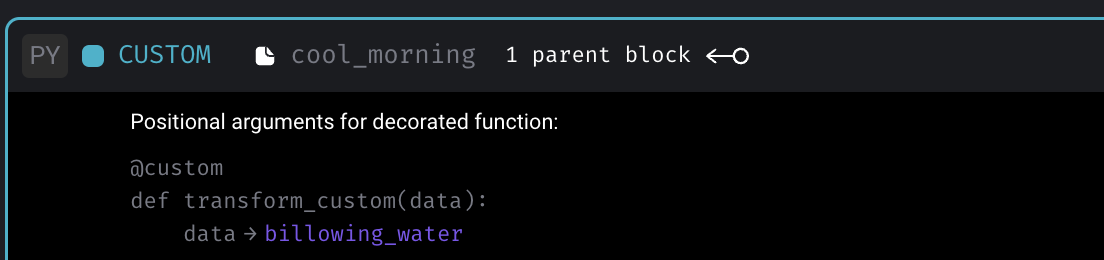
View full Changelog