Releases: mage-ai/mage-ai
0.9.14 | Blue Beetle 🪲

What's Changed
🎉 Exciting New Features
✨ New Connector: sFTP
Ahoy! There's a new connector on-board the Mage ship: sFTP. 🚢
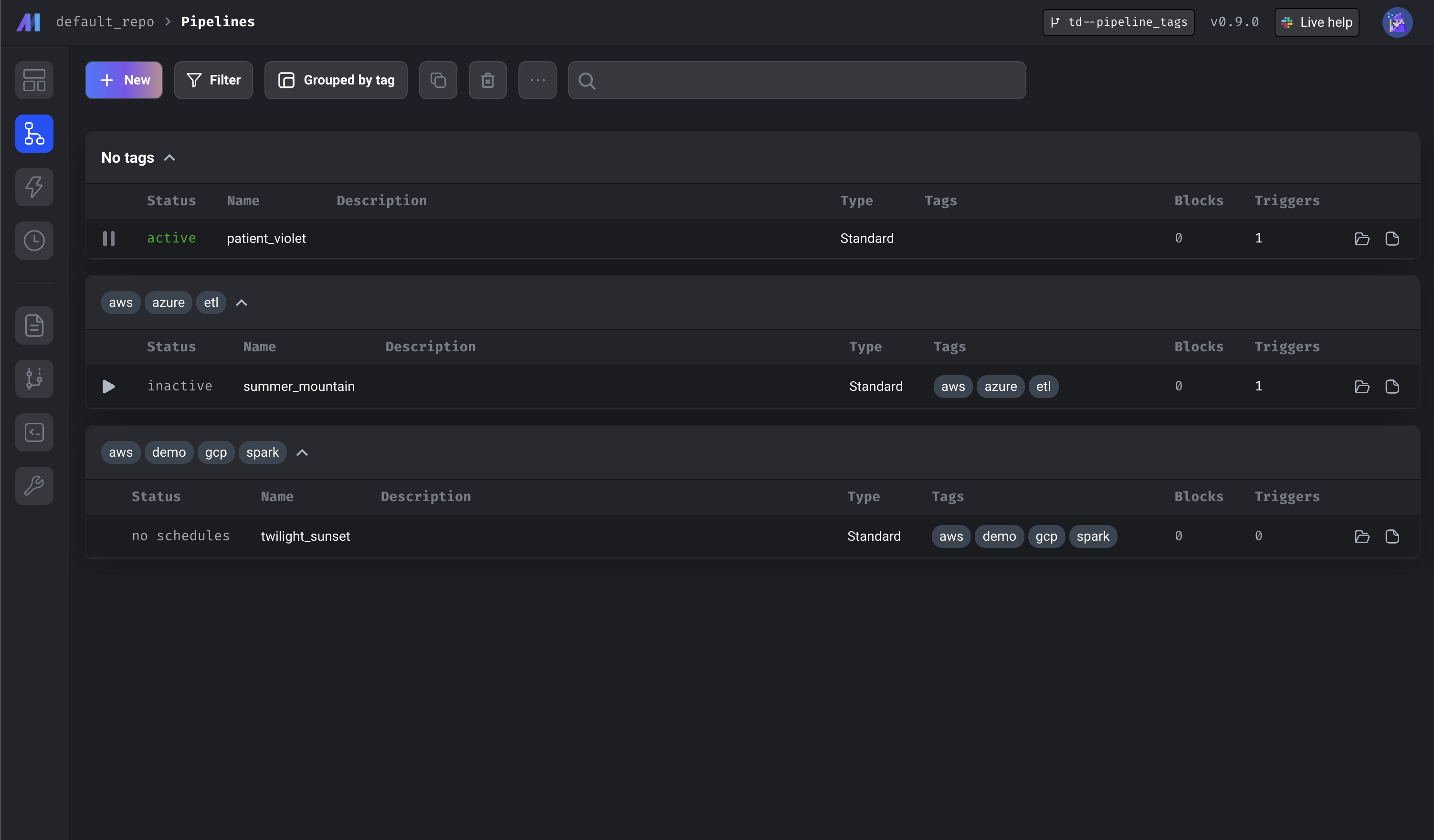
✨ Pipeline Schedule Tags
Pipeline schedules can now be tagged to help categorize them in the UI. 🎉


✨ Pipeline Run Cancellation
😎 Manual pipeline runs can now be cancelled via the UI.

by @johnson-mage in #3236
🐛 Bug Fixes
- Fix error logging for replica blocks by @dy46 in #3183
- Fix variables dir construction by @dy46 in #3203
- Escape password in
db_connection_urlby @dy46 in #3189 - Renaming blocks with shared pipelines by @johnson-mage in #3199
- Fix infinite rendering loop in SchemaTable by @johnson-mage in #3213
- Fix log detail metrics object rendering issue by @johnson-mage in #3216
- Fix
dbt-snowflakewhen password null by @tommydangerous in #3225 - Update redshift format value by @dy46 in #3196
- Fix EMR pyspark kernel permission error by @wangxiaoyou1993 in #3227
- Update where the
frontend_dist_base_pathis created by @dy46 in #3224 - Block run and pipeline run start/completion times in UTC by @johnson-mage in #3229
- Allow adding block from search by @johnson-mage in #3235
- Fix setting project uuid error by @dy46 in #3231
- Fix custom templates with empty parent names by @tommydangerous in #3253
- Not obfuscate data in data integration records. by @wangxiaoyou1993 in #3265
- When comparing
spark.jars, use the file names and neglect paths by @csharplus in #3264 - Import decorators when executing block module by @dy46 in #3243
- Fix using location in
dbt-bigquery. by @wangxiaoyou1993 in #3273 - Fix trigger not showing up in block run view by @dy46 in #3274
💅 Enhancements & Polish
- Updated Facebook Ads SDK to 17.0.2 by @Luishfs in #3187
- Support updating ingress when creating k8s workspace by @dy46 in #3200
- Add API endpoint to Trigger detail page by @johnson-mage in #3219
- Add custom timeout to kafka streams by @mattppal in #3204
- Limit the number of rows of sql block output in pipeline run by @wangxiaoyou1993 in #3237
- Hide the token in the UI by @tommydangerous in #3254
- Use greater than operator for unique columns in source sql bookmark comparison. by @wangxiaoyou1993 in #3256
- Update block runs table by @johnson-mage in #3257
- Improve error message for duplicate column name. by @wangxiaoyou1993 in #3268
- Add count of completed blocks in pipelineRun table by @oonyoontong in #3245
- Block run count formatting in PipelineRuns table by @johnson-mage in #3276
- Added clickhouse state file location by @Luishfs in #3201
- Generate comment for code by @matrixstone in #3161
- Support dbt model config option for database by @tommydangerous in #3208
- Add custom block template for streaming pipeline by @tommydangerous in #3209
- Do not convert variables dir to abs path for s3 variables dir by @wangxiaoyou1993 in #3210
- Add tags and tags association for polymorphic relationship by @tommydangerous in #3211
- Change the table creation into two steps as required by the ClickHouse Cloud by @csharplus in #3194
- Add openssl dockerfile by @dy46 in #3215
- Add upstream blockIds when generating pipeline code by @matrixstone in #3169
New Contributors
- @oonyoontong made their first contribution in #3245
- @christopherscholz made their first contribution in #3258
Full Changelog: 0.9.11...0.9.14
Contributors
Assets 2
0.9.11 | Mutant Mayhem 🐢

🎉 Exciting New Features
✨ Base path configuration for Mage
There's a new environment variable in town— MAGE_BASE_PATH! 🤠
Mage now supports adding a prefix to a Mage URL, i.e. localhost:6789/my_prefix/
✨ Support for DROP TABLE in raw SQL blocks
Raw SQL blocks can now drop tables! 🎉
by @wangxiaoyou1993 in #3184
✨ MongoDB connection string support
Our MongoDB users will be happy about this one— MongoDB can now be accessed via a connection string, for example: mongodb+srv://{username}:{password}@{host}
Doc: https://docs.mage.ai/integrations/databases/MongoDB#add-credentials
by @wangxiaoyou1993 in #3188
✨ Salesforce destination
Data integration pipelines just got another great destination— Salesforce!
🐛 Bug Fixes
- Fix circular dependency and repo config issues by @dy46 in #3168
- Fix an issue in the bigquery init method by @csharplus in #3171
- Fix base path frontend_dist creation by @dy46 in #3182
- Fix the
booldata type conversion issue with the ClickHouse exporter by @csharplus in #3172 - Do not start pipeline run immediately after creation by @wangxiaoyou1993 in #3173
💅 Enhancements & Polish
- Add block runtime chart for all blocks by @johnson-mage in #3156
- Use Playwright for web UI test automation by @erictse in #3075
- Auto-scroll to newest logs by @johnson-mage in #3170
- Add
DISABLE_TERMINALenvironment variable by @juancaven1988 in #3174 - Consolidate AWS region variables by @dy46 in #3152
- Adding test connection to MongoDB destination by @Luishfs in #3159
- Adding test connection to clickhouse destination by @Luishfs in #3158
- Adding snowflake table name option and regex by @Luishfs in #3186
- Remove streaming S3 sink timer error by @wangxiaoyou1993 in #3190
- Include
frontend_dist_base_path_templatein package by @dy46 in #3178 - New options to pass Azure Blob
upload_kwargsto allow overwriting an existing file or use any other options by @sumanshusamarora in #3148
🎉 New Contributors
- @Radu-D made their first contribution in #3179
- @juancaven1988 made their first contribution in #3174
Full Changelog: 0.9.10...0.9.11
Contributors
Assets 2
0.9.10 | Haunted Mansion

What's Changed
🎉 Exciting New Features
🤖 Create blocks and documentation using LLMs
Block Creation

Document Generation

From the following PRs:
- Generate block using AI by @tommydangerous in #3095
- Generate documentation using AI by @tommydangerous in #3105
- Generate block template based on block description by @matrixstone in #3029
- Create model and API endpoint for global data products by @tommydangerous in #3135
❄️ Enable batch upload for Snowflake destination
Leveraging write_pandas in the snowflake-connector-python library, this feature enhances the speed of batch uploads using Snowflake destinations 🤯 by @csharplus in #2896
Auto-delete logs after retention period
Now, Mage can auto-remove logs after your retention period expires!
Configure retention_period in logging_config:
logging_config:
retention_period: '15d'Run command to delete old logs:
mage clean-old-logs k8s_projectby @wangxiaoyou1993 in #3139
MongoDB destination support (data integration)
MongoDB is now supported as a destination! 🎉 by @Luishfs in #3084
Pipeline-level concurrency
It's now possible to configure concurrency at the pipeline level:
concurrency_config:
block_run_limit: 1
pipeline_run_limit: 1Doc: https://docs.mage.ai/design/data-pipeline-management#pipeline-level-concurrency
by @wangxiaoyou1993 in #3112
🧱 New add-block flow


Mage's UI has been improved to feature a new add-block flow! by @tommydangerous in #3094, #3074, & #3106
Custom k8s executors
Mage now support custom k8s executor configuration:
k8s_executor_config:
service_account_name: mageai
job_name_prefix: "{{ env_var('KUBE_NAMESPACE') }}"
container_config:
image: mageai/mageai:0.9.7
env:
- name: USER_CODE_PATH
value: /home/src/k8s_projectby @wangxiaoyou1993 in #3127
Custom s3 endpoint_url in logger
You can now configure a custom endpoint_url in s3 loggers, allowing you to customize how messages are displayed!
logging_config:
type: s3
level: INFO
destination_config:
bucket: <bucket name>
prefix: <prefix path>
aws_access_key_id: <(optional) AWS access key ID>
aws_secret_access_key: <(optional) AWS secret access key>
endpoint_url: <(optional) custom endpoint url>by @wangxiaoyou1993 in #3137
Render text/html from block output
Text and HTML from block output is now rendered!

Clickhouse data integration support
Clickhouse is now supported as a integrations destination! by @Luishfs in #3005
Custom timeouts for ECS tasks
You can now set custom timeouts for all of your ECS tasks! by @wangxiaoyou1993 in #3144
Run multiple Mage instances with the same PostgreSQL databases
A single Postgres database can now support multiple Mage instances ✨ by @csharplus in #3070
🐛 Bug Fixes
- Clear pipeline list filters when clicking Defaults by @johnson-mage in #3092
- Fetch Snowflake role by @mattppal in #3100
- Add service argument to OracleDB data loader by @mattppal in #3032
- Fix
pymssqldependency by @dy46 in #3114 - Include runs without associated triggers in pipeline run count by @johnson-mage in #3118
- Fix positioning of nested flyout menu 4 levels deep by @johnson-mage in #3125
- Batch git sync in
pipeline_schedulerby @dy46 in #3102 - Only try to interpolate variables if they are in the query by @dy46 in #3142
- Fix command for running streaming pipeline in k8s executor. by @wangxiaoyou1993 in #3093
- Fix block flow bugs by @tommydangerous in #3094
- Catch timeout exception for test_connection by @dy46 in #3143
- Fix showing duplicate templates for v1 by @tommydangerous in #3128
check_statusmethod bug fix to look at pipelines ran between specific time period by @sumanshusamarora in #3115- Fix db init on start by @tommydangerous in #3080
- Fix logic for making API requests for block outputs or analyses that were throwing errors due to invalid
pipeline_uuidsby @johnson-mage in #3090
💅 Enhancements & Polish
- Decrease variables response size by @johnson-mage in #3097
- Cancel block runs when pipeline run fails by @dy46 in #3096
- Clean up code in
VariableResourcemethod by @johnson-mage in #3099 - Import block function from file for test execution by @dy46 in #3110
- Misc UI improvements by @johnson-mage in #3133
- Polish custom templates by @tommydangerous in #3120
- Throw correct exception about
io-configby @wangxiaoyou1993 in #3130 - Clarify input for dbt profile target if a default target is not configured by @johnson-mage in #3077
- Support nested sampling on output by @wangxiaoyou1993 in #3086
- Add API endpoint for fetching OAuth access tokens by @tommydangerous in #3089
New Contributors
- @sumanshusamarora made their first contribution in #3115
Full Changelog: 0.9.8...0.9.10
Contributors
Assets 2
0.9.8 | Dead Reckoning 💥

What's Changed
🎉 Exciting New Features
🔥 Custom block & pipeline templates
With this release, Magers now have the option to create pipeline templates, then use those to populate new pipelines.

Additionally, you may now browse, create, and use custom block templates in your pipelines. 🎉

by @tommydangerous in #3064, #3042 and #3065
🛟 Save pipelines list filters and groups
Your pipeline filters and groups are now sticky— that means setting filters/groups will persist through your Mage session.

by @tommydangerous in #3059
Horizontal scaling support for schedulers
You can now run the web server and scheduler in separate containers, allowing for horizontal scaling of the scheduler! Read more in our docs.
Run scheduler only:
/app/run_app.sh mage start project_name --instance-type schedulerRun web server only:
/app/run_app.sh mage start project_name --instance-type web_serverby @wangxiaoyou1993 in #3016
🎏 Run parallel integration streams
Data integration streams may now be executed in parallel!

Update secrets management backend
The secrets management backend can now handle multiple environments!
📆 Include interval datetimes and intervals in block variables
Interval datetimes and durations are now returned in block variables. Check out our docs for more info!

by @tommydangerous in #3058 and #3068
🐛 Bug Fixes
- Persist error message popup when selecting stream by @johnson-mage in #3028
- Add google oauth2 scopes to bigquery client by @mattppal in #3023
- enable backfills
deleteand add documentation by @mattppal in #3012 - Show warning if no streams displayed by @johnson-mage in #3034
- Fix SLA alerting as soon as trigger run starts by @dy46 in #3036
- Display error when fetching data providers by @johnson-mage in #3038
- Add
/filesroute to backend server and fix TypeError in FileEditor by @johnson-mage in #3041 - Create dynamic block runs in block executor by @wangxiaoyou1993 in #3035
- Fix block settings not updating after saving by @tommydangerous in #3021
- Catch redis error and fix logging by @wangxiaoyou1993 in #3047
- Fix roles query by entity bug by @dy46 in #3049
- API quickstart for rapid development by @mattppal in #3017
- Fix pipelines list filters and group bys not removing by @tommydangerous in #3060
- Fix deleting block by @wangxiaoyou1993 in #3011
- Temporary pymssql fix v2 by @dy46 in #3015
💅 Enhancements & Polish
- Add
Updated Atcolumn to Pipelines list page by @johnson-mage in #3050 - Default error log to Errors tab when opening log detail by @johnson-mage in #3052
- Add timeout for fetching files for git by @dy46 in #3051
- Encode URI component for file path on files page by @tommydangerous in #3067
- When clicking a file in file browser, select block if in pipeline by @tommydangerous in #3024
New Contributors
Full Changelog: 0.9.4...0.9.8
Contributors
Assets 2
0.9.4 | Solar Flare ☀️

🎉 Features
Azure Data Lake streaming pipeline support
Docs: https://docs.mage.ai/guides/streaming/destinations/azure_data_lake
Mage now supports Azure Data Lake as a streaming destination!

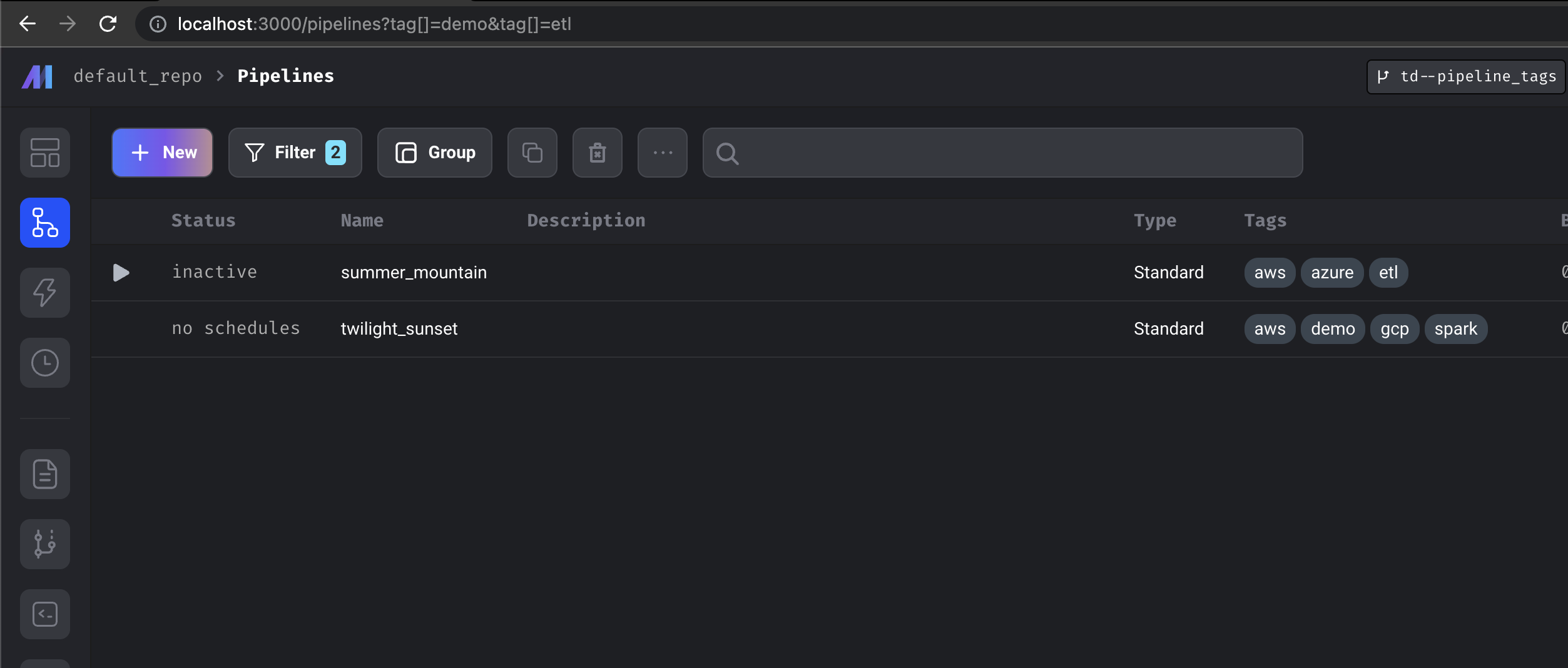
Pipeline Tags
Tags can now be applied to pipelines. Users can leverage the pipeline view to apply filters or group pipelines by tag.
Support for custom k8s executor job prefixes
You can now prefix your k8s executor jobs! Here’s an example k8s executor config file:
k8s_executor_config:
job_name_prefix: data-prep
resource_limits:
cpu: 1000m
memory: 2048Mi
resource_requests:
cpu: 500m
memory: 1024Mi
service_account_name: defaultSee the documentation for further details.
Removed data integration config details from logs
Mage no longer prints data integration settings in logs: a big win for security. 🔒

💅 Other bug fixes & polish
Cloud deployment
- Fix k8s job deletion error.
- Fix fetching AWS events while editing trigger.
- Fixes for Azure deployments.
- Integrate with Azure Key Vault to support
azure_secret_varsyntax: docs. - Pass resource limits from main ECS task to dev tasks.
- Use network configuration from main ECS service as a template for dev tasks.
Integrations
- Fix Postgres schema resolution error— this fixes schema names with characters like hyphens for Postgres.
- Escape reserved column names in Postgres.
- Snowflake strings are now casted as
VARCHARinstead ofVARCHAR(255). The MySQL loader now usesTEXTfor strings to avoid truncation. - Use AWS session token in io.s3.
- Fix the issue with database setting when running ClickHouse in SQL blocks
Other
- Fix multiple upstream block callback error. Input variables will now be fetched one block at a time.
- Fix data integration metrics calculation.
- Improved variable serialization/deserialization— this fixes kernel crashes due to OOM errors.
- User quote: "A pipeline that was taking ~1h runs in less than 2 min!"
- Fix trigger edit bug— eliminates bug that would reset fields in trigger.
- Fix default filepath in ConfigFileLoader (Thanks Ethan!)
- Move
COPYstep to reduce Docker build time. - Validate env values in trigger config.
- Fix overview crashing.
- Fix cron settings when editing in trigger.
- Fix editing pipeline’s executor type from settings.
- Fix block pipeline policy issue.
🗣️ Shout outs
- @ethanbrown3 made their first contribution in #2976 🎉
- @erictse made their first contribution in #2977 🥳
Contributors
Assets 2
0.9.0 | The Dial of Destiny

Workspace management
You can use Mage with multiple workspaces in the cloud now. Mage has a built in workspace manager that can be enabled in production. This feature is similar to the multi-development environments, but there are settings that can be shared across the workspaces. For example, the project owner can set workspace level permissions for users. The current additional features supported are:
- workspace level permissions
- workspace level git settings
Upcoming features:
- common workspace metadata file
- customizable permissions and roles
- pipeline level permissions
Doc: https://docs.mage.ai/developing-in-the-cloud/workspaces/overview
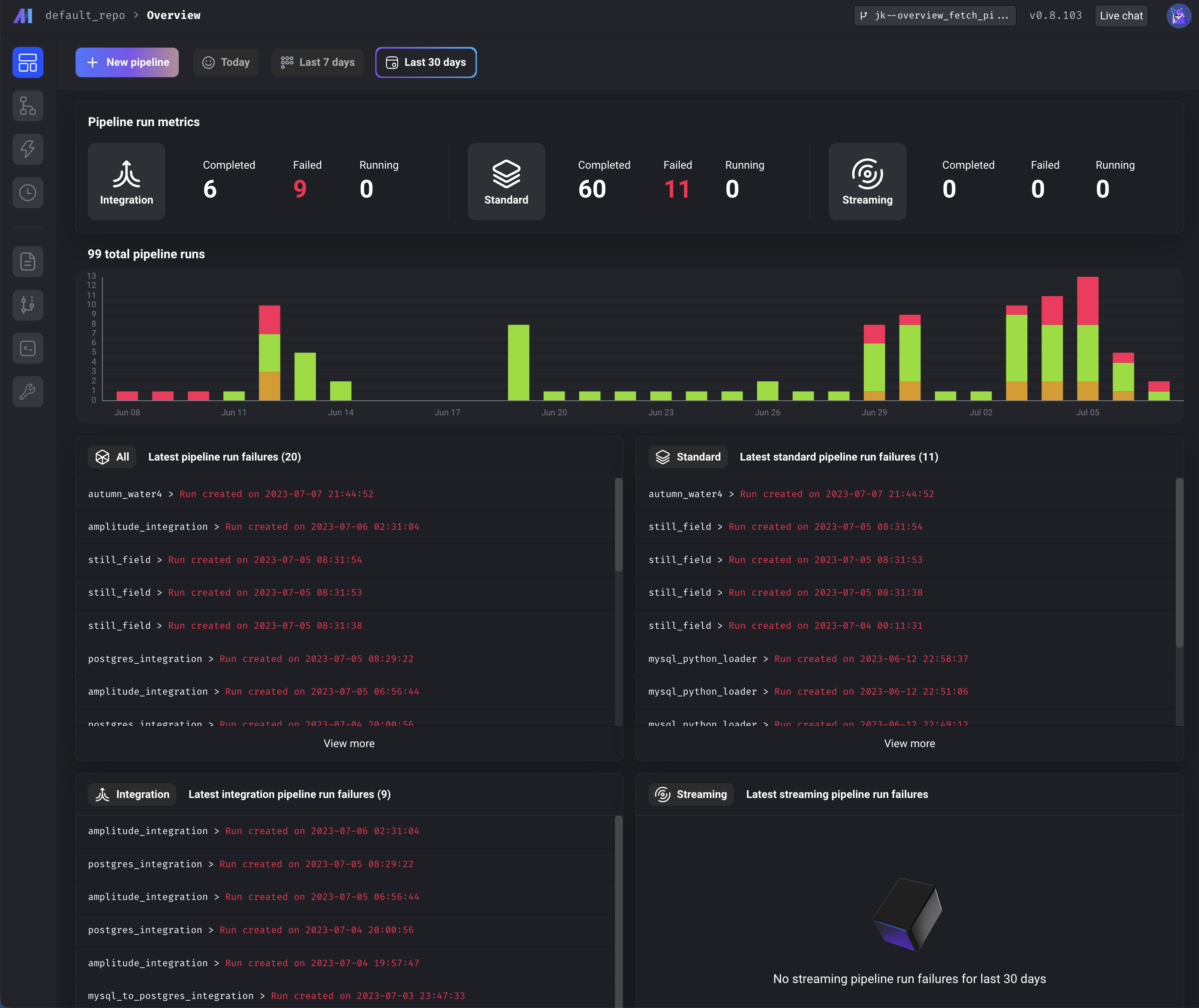
Pipeline monitoring dashboard
Add "Overview" page to dashboard providing summary of pipeline run metrics and failures.
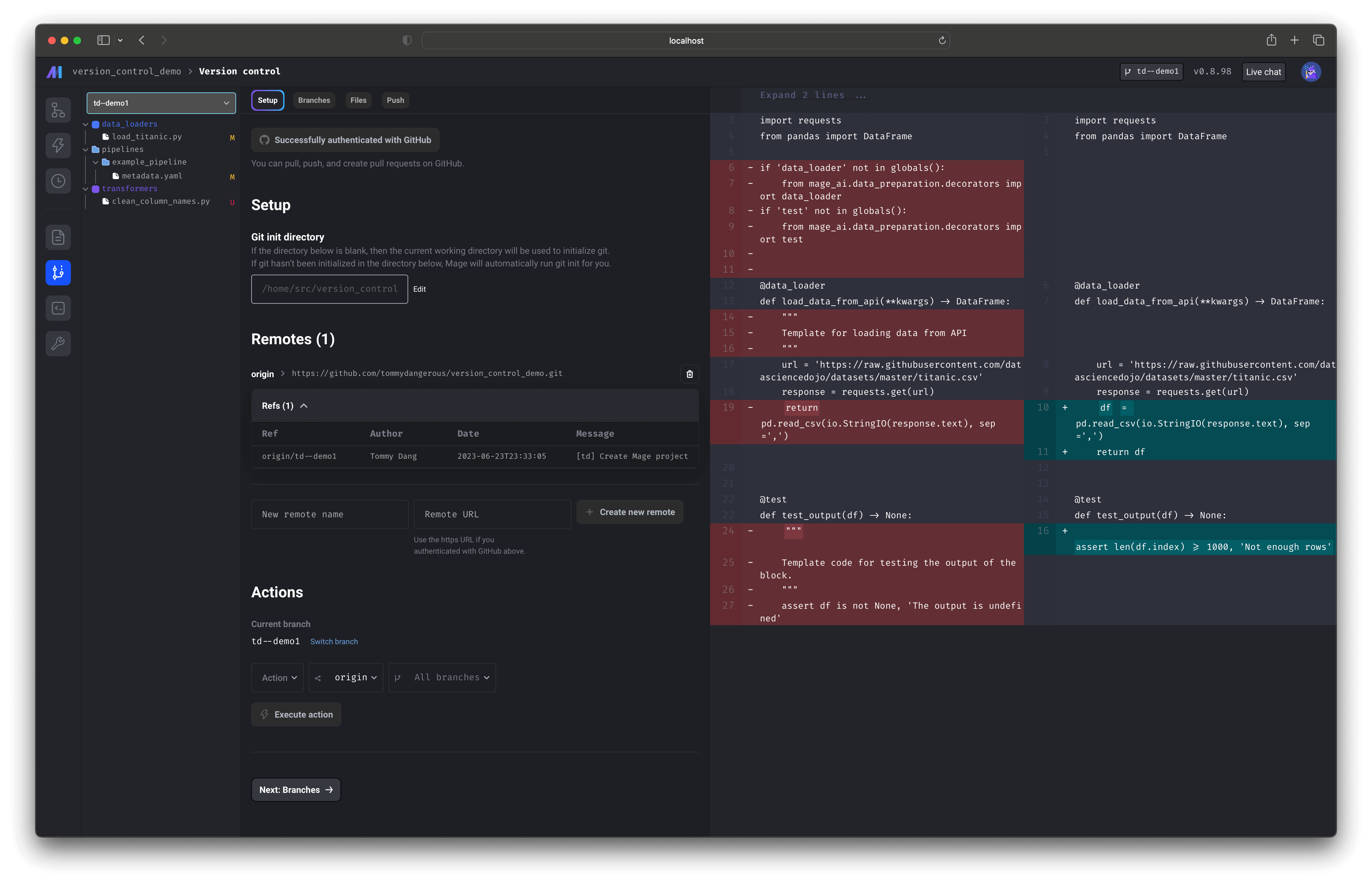
Version control application
Support all Git operations through UI. Authenticate with GitHub then pull from a remote repository, push local changes to a remote repository, and create pull requests for a remote repository.
Doc: https://docs.mage.ai/production/data-sync/github
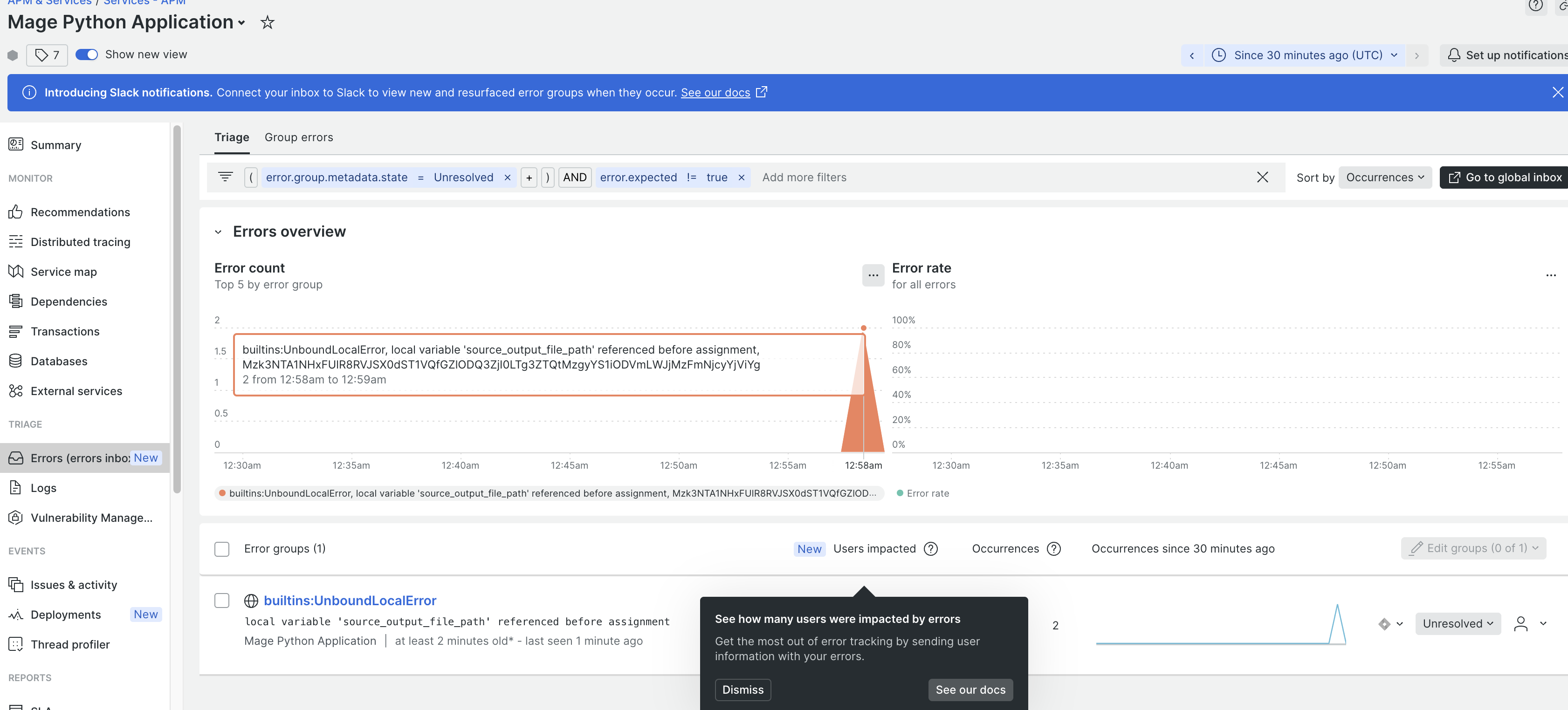
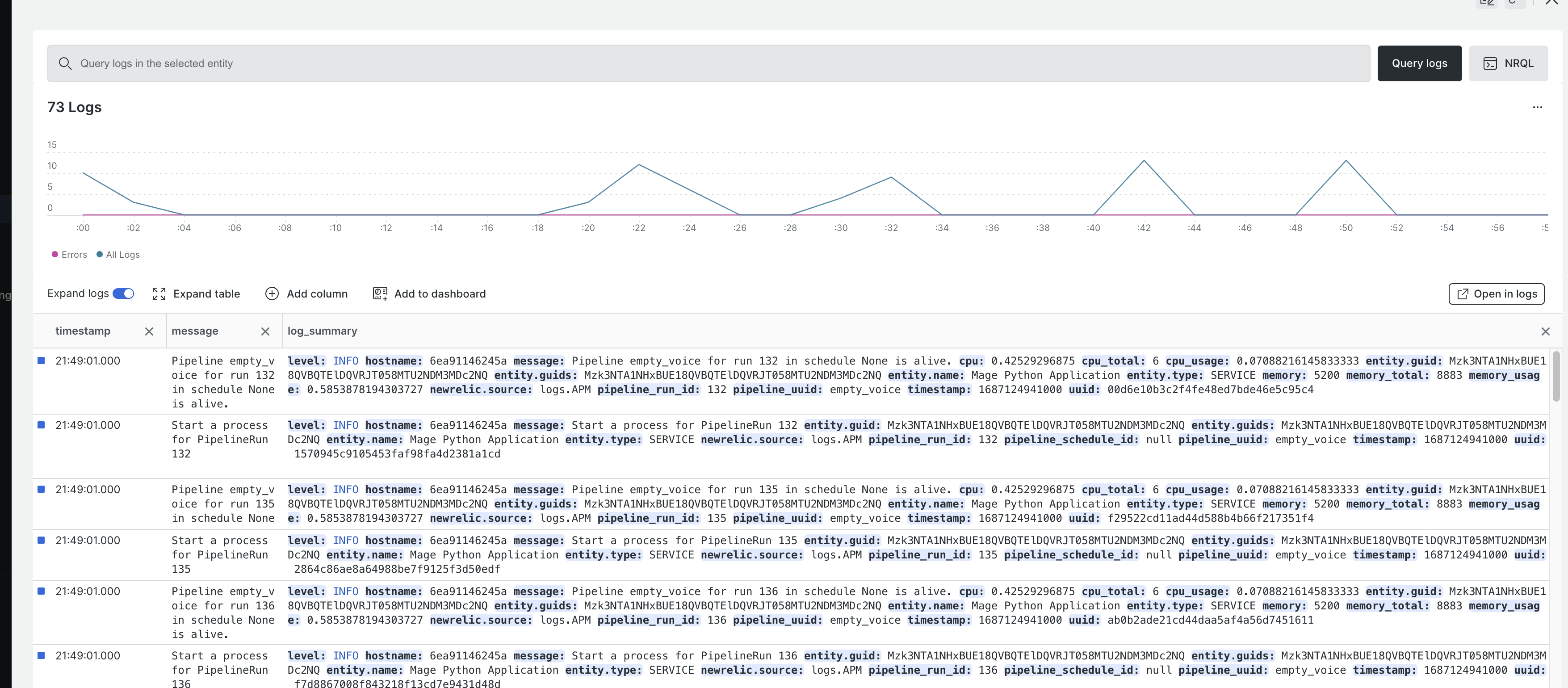
New Relic monitoring
- Set the
ENABLE_NEW_RELICenvironment variable to enable or disable new relic monitoring. - User need to follow new relic guide to create configuration file with license_key and app name.
Doc: https://docs.mage.ai/production/observability/newrelic
Authentication
Active Directory OAuth
Enable signing in with Microsoft Active Directory account in Mage.
Doc: https://docs.mage.ai/production/authentication/microsoft
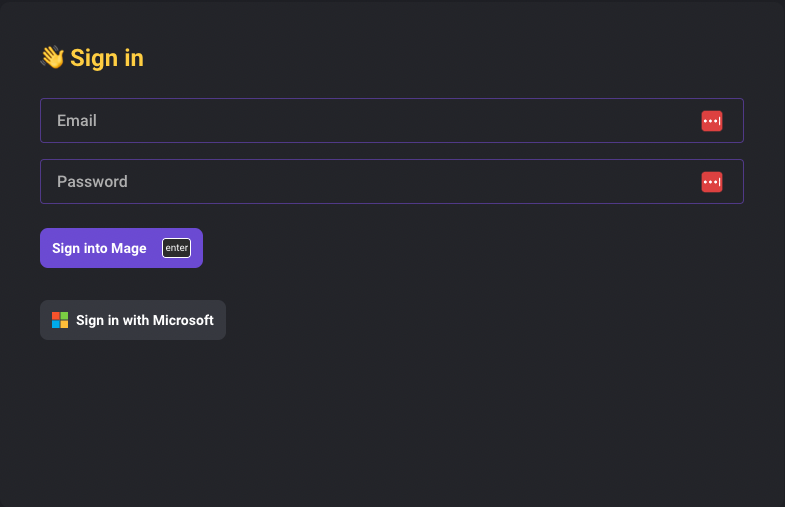
LDAP
https://docs.mage.ai/production/authentication/overview#ldap
- Update default LDAP user access from editor to no access. Add an environment variable
LDAP_DEFAULT_ACCESSso that the default access can be customized.
Add option to sync from Git on server start
There are two ways to configure Mage to sync from Git on server start
- Toggle
Sync on server start upoption in Git settings UI - Set
GIT_SYNC_ON_STARTenvironment variable (options: 0 or 1)
Doc: https://docs.mage.ai/production/data-sync/git#git-settings-as-environment-variables
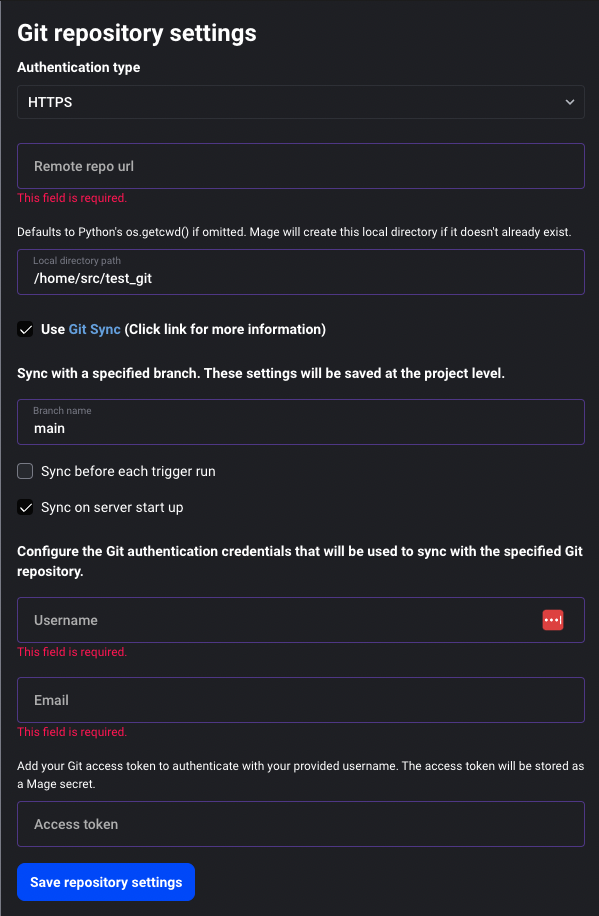
Data integration pipeline
Mode Analytics Source
Shout out to Mohamad Balouza for his contribution of adding the Mode Analytics source to Mage data integration pipeline.
OracleDB Destination
MinIO support for S3 in Data integrations pipeline
Support using S3 source to connect to MinIO by configuring the aws_endpoint in the config.
Bug fixes and improvements
- Snowflake: Use
TIMESTAMP_TZas column type for snowflake datetime column. - BigQuery: Not require key file for BigQuery source and destination. When Mage is deployed on GCP, it can use the service account to authenticate.
- Google Cloud Storage: Allow authenticating with Google Cloud Storage using service account
- MySQL
- Fix inserting DOUBLE columns into MySQL destination
- Fix comparing datetime bookmark column in MySQL source
- Use backticks to wrap column name in MySQL
- MongoDB source: Add authSource and authMechanism options for MongoDB source.
- Salesforce source: Fix loading sample data for Salesforce source
- Improve visibility into non-functioning "test connection" and "load sample data" features for integration pipelines:
- Show unsupported error is "Test connection" is not implemented for an integration source.
- Update error messaging for "Load sample data" to let user know that it may not be supported for the currently selected integration source.
- Interpolate pipeline name and UUID in data integration pipelines. Doc: https://docs.mage.ai/data-integrations/configuration#variable-names
SQL block
OracleDB Loader Block
Added OracleDB Data Loader block
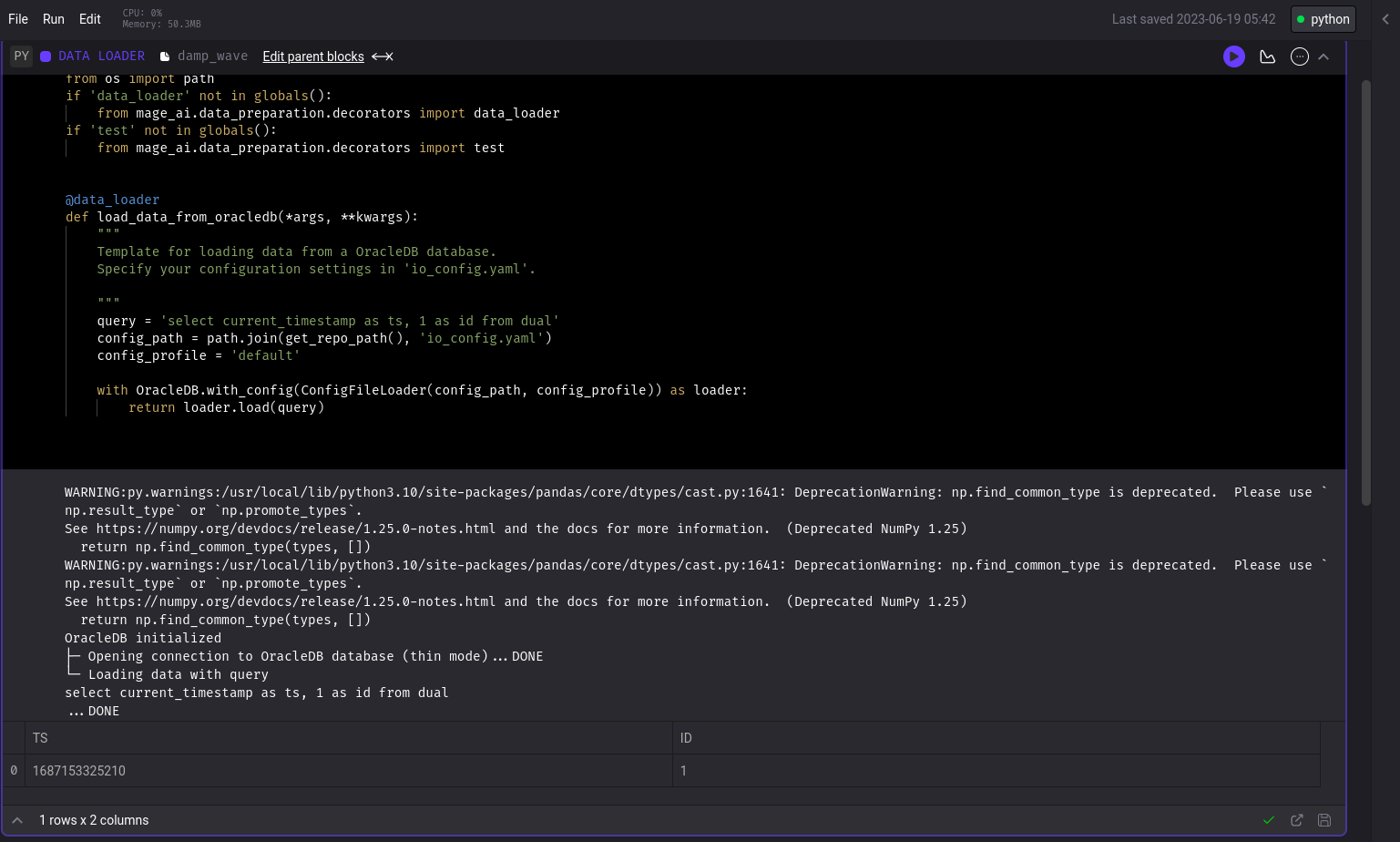
Bug fixes
- MSSQL: Fix MSSQL sql block schema.
Schemawas not properly set when checking table existence. Usedboas the default schema if no schema is set. - Trino: Fix inserting datetime column into Trino
- BigQuery: Throw exception in BigQuery SQL block
- ClickHouse: Support automatic table creation for ClickHouse data exporter
DBT block
DBT ClickHouse
Shout out to Daesgar for his contribution of adding support running ClickHouse DBT models in Mage.
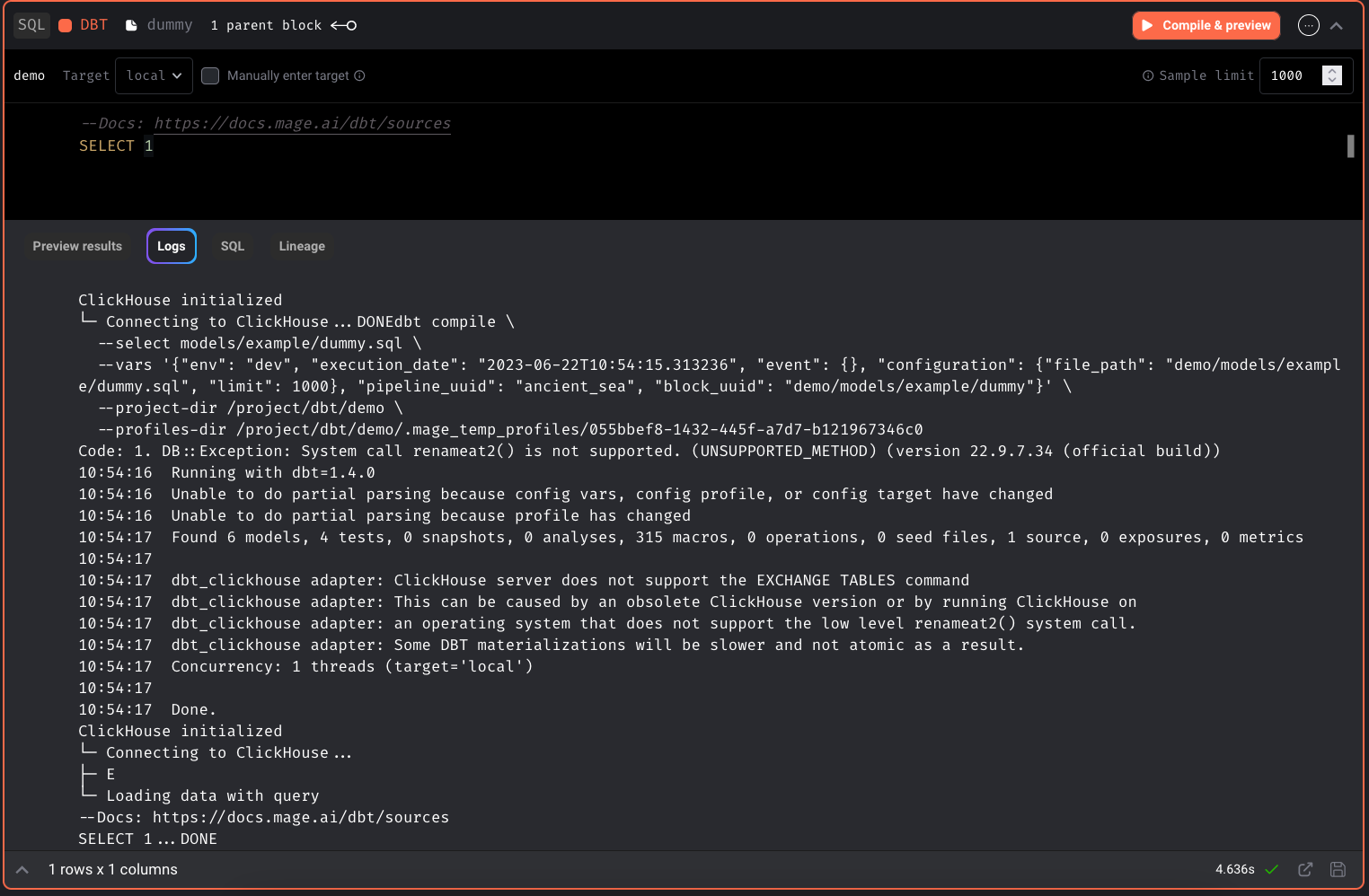
Add DBT generic command block
Add a DBT block that can run any generic command
Bug fixes and improvements
- Fix bug: Running DBT block preview would sometimes not use sample limit amount.
- Fix bug: Existing upstream block would get overwritten when adding a dbt block with a ref to that existing upstream block.
- Fix bug: Duplicate upstream block added when new block contains upstream block ref and upstream block already exists.
- Use UTF-8 encoding when logging output from DBT blocks.
Notebook improvements
-
Turn on output to logs when running a single block in the notebook
-
When running a block in the notebook, provide an option to only run the upstream blocks that haven’t been executed successfully.
-
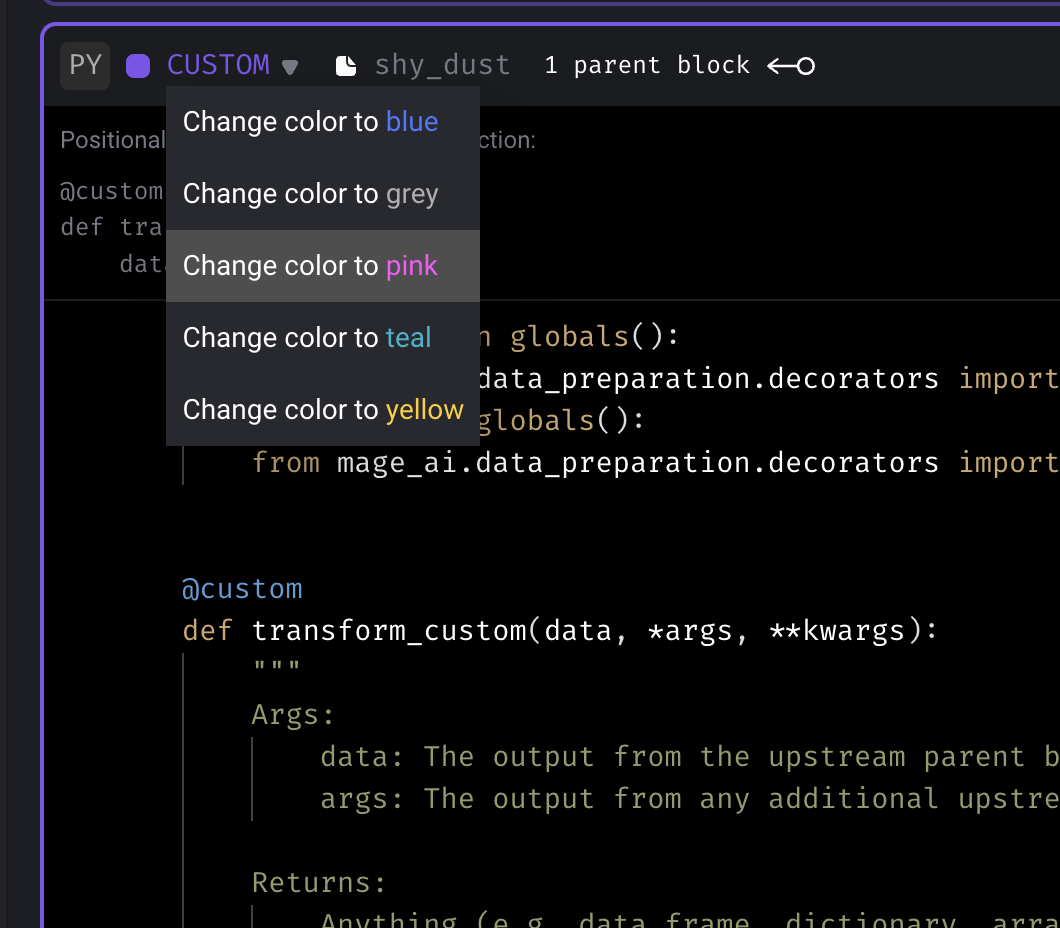
Change the color of a custom block from the UI.
-
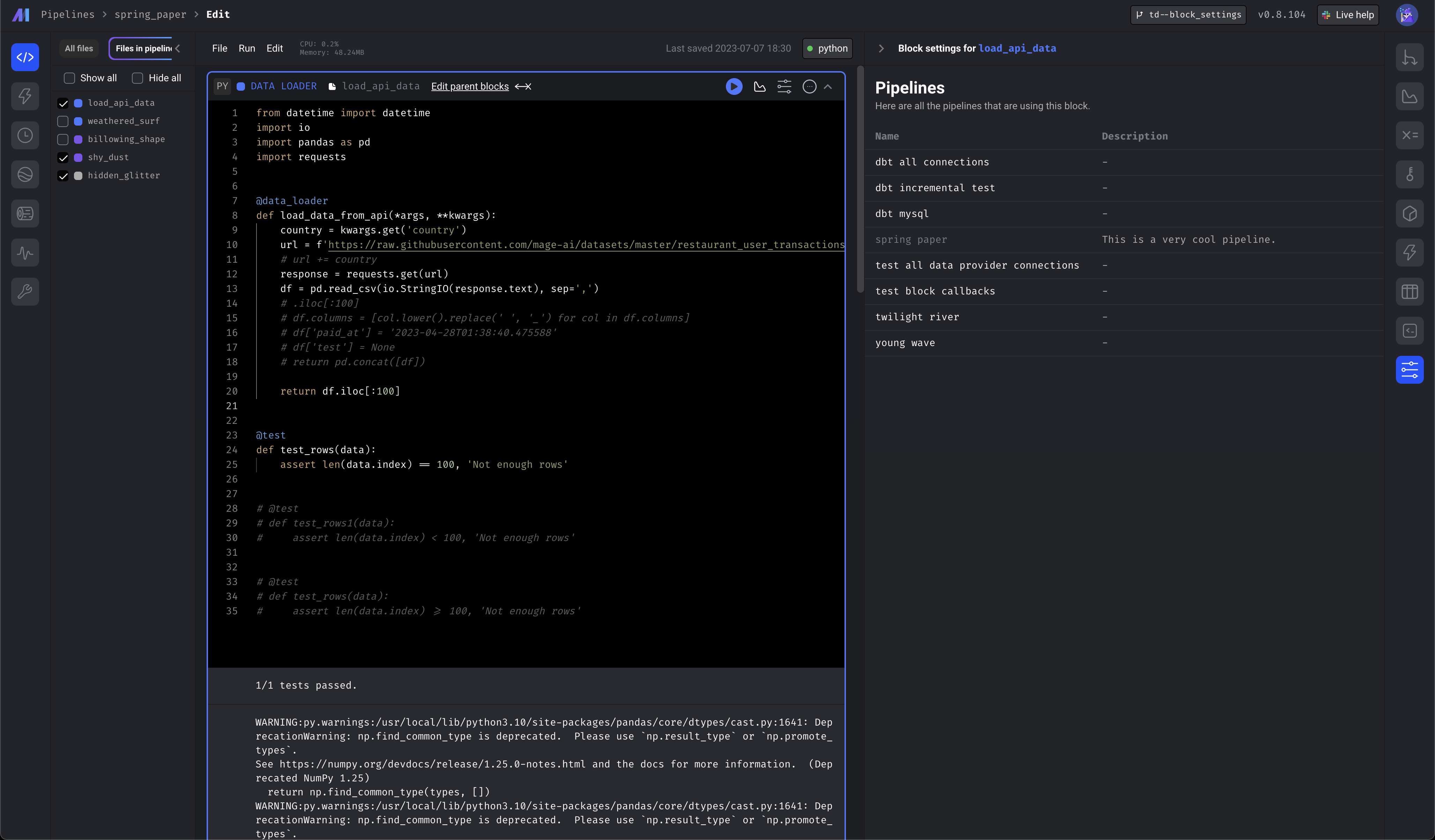
Show what pipelines are using a particular block
- Show block settings in the sidekick when selecting a block
- Show which pipelines a block is used in
- Create a block cache class that stores block to pipeline mapping
-
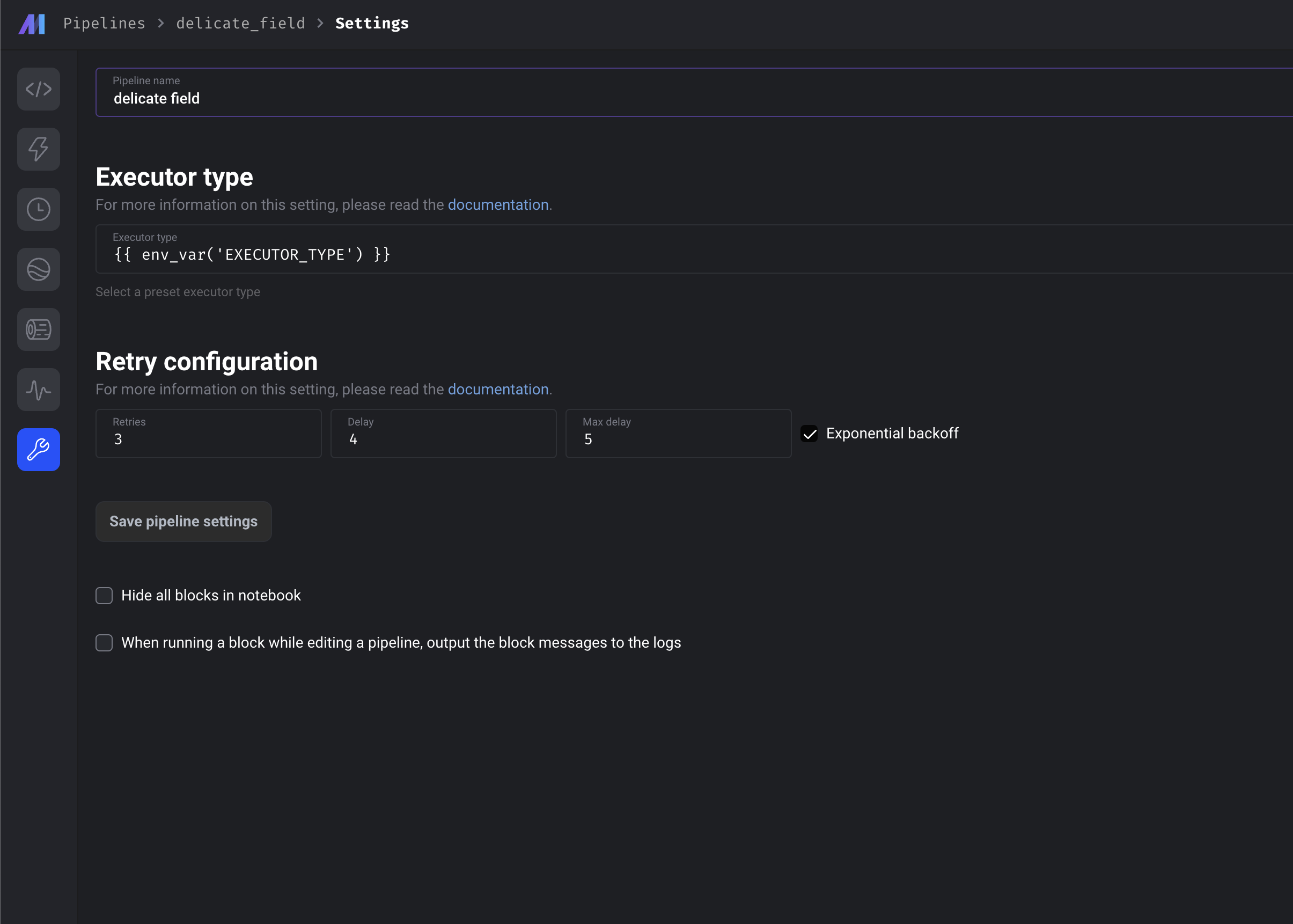
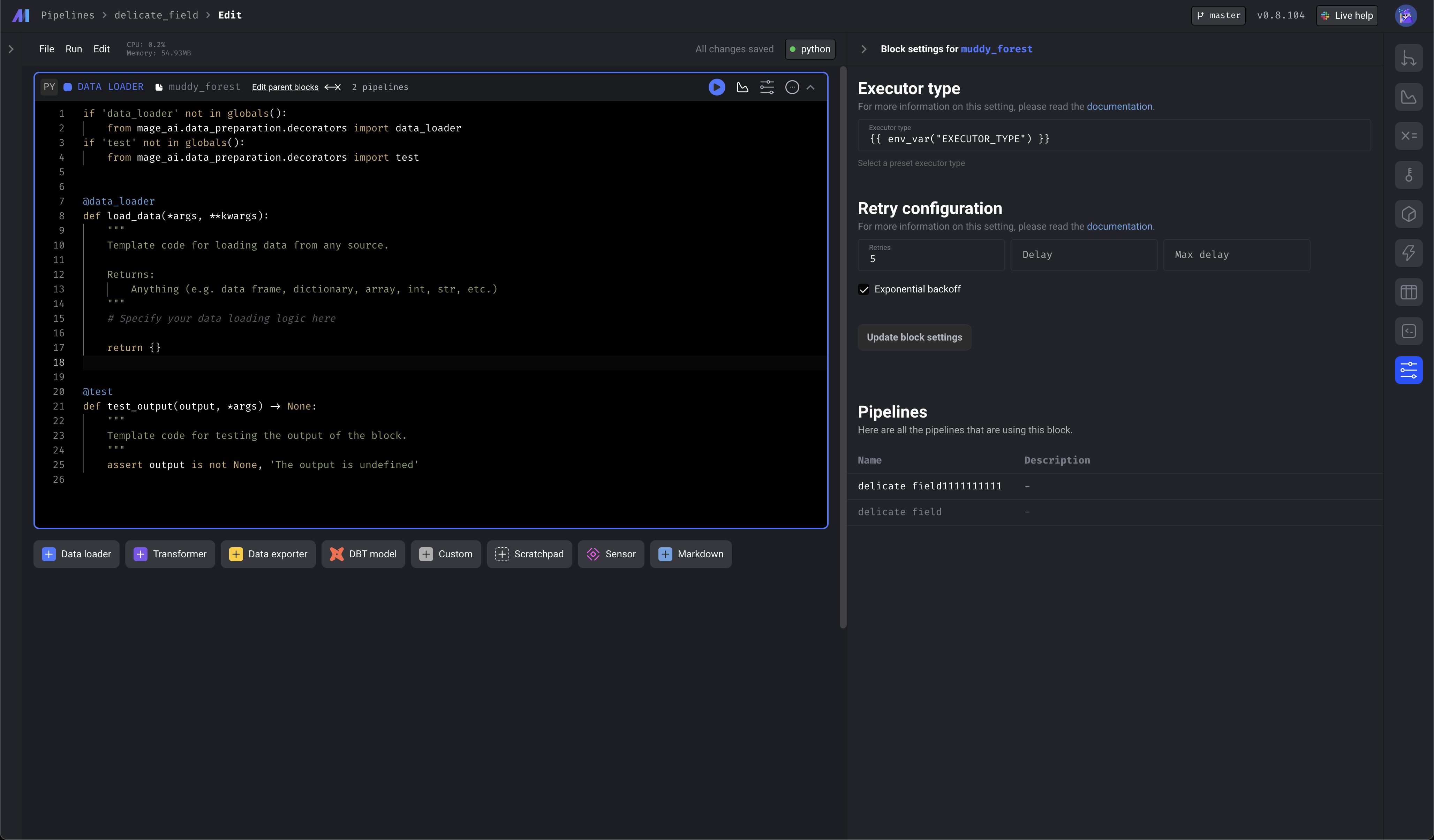
Enhanced pipeline settings page and block settings page
- Edit pipeline and block executor type and interpolate
- Edit pipeline and block retry config from the UI
- Edit block name and color from block settings
-
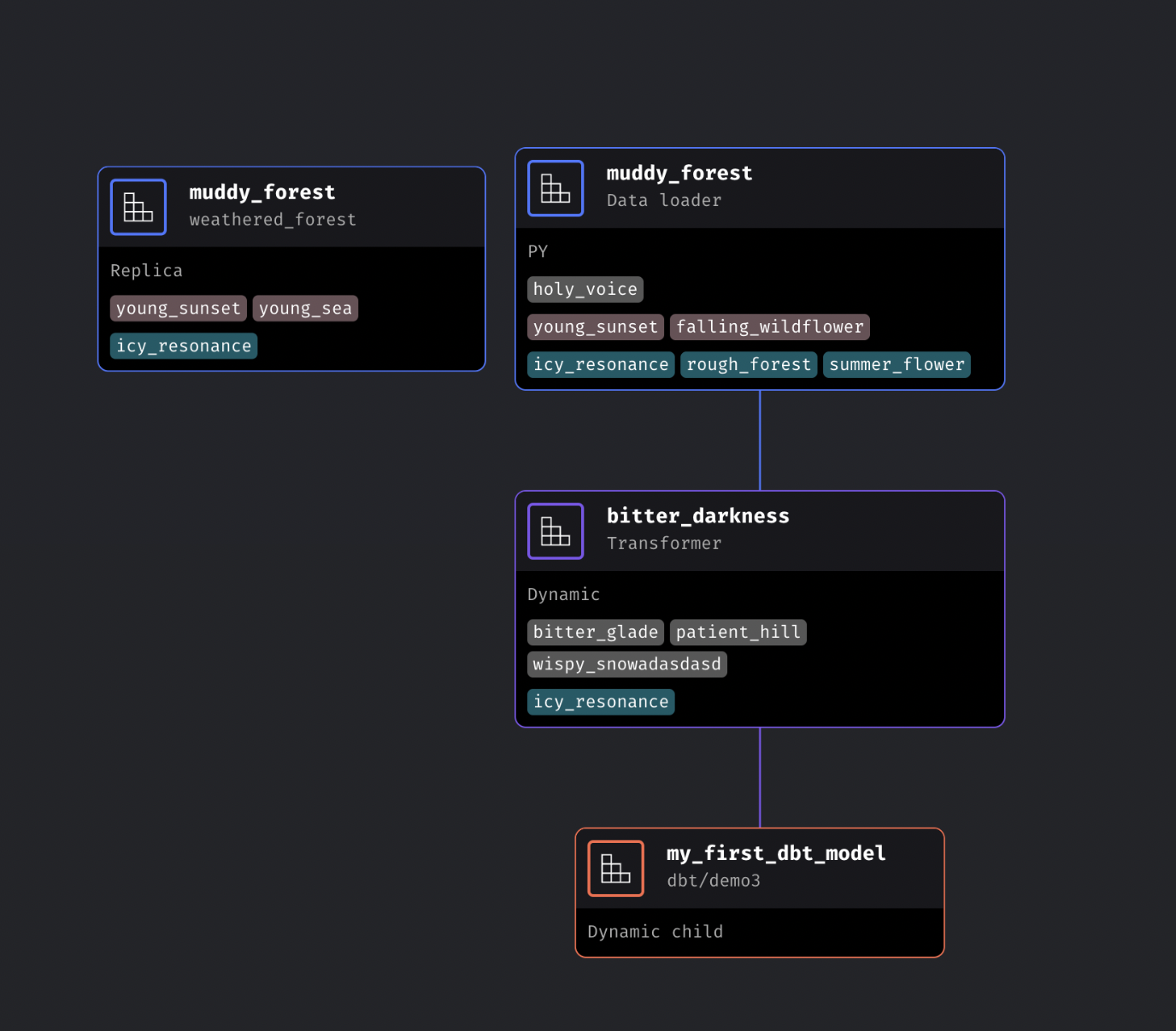
Enhance dependency tree node to show callbacks, conditionals, and extensions
-
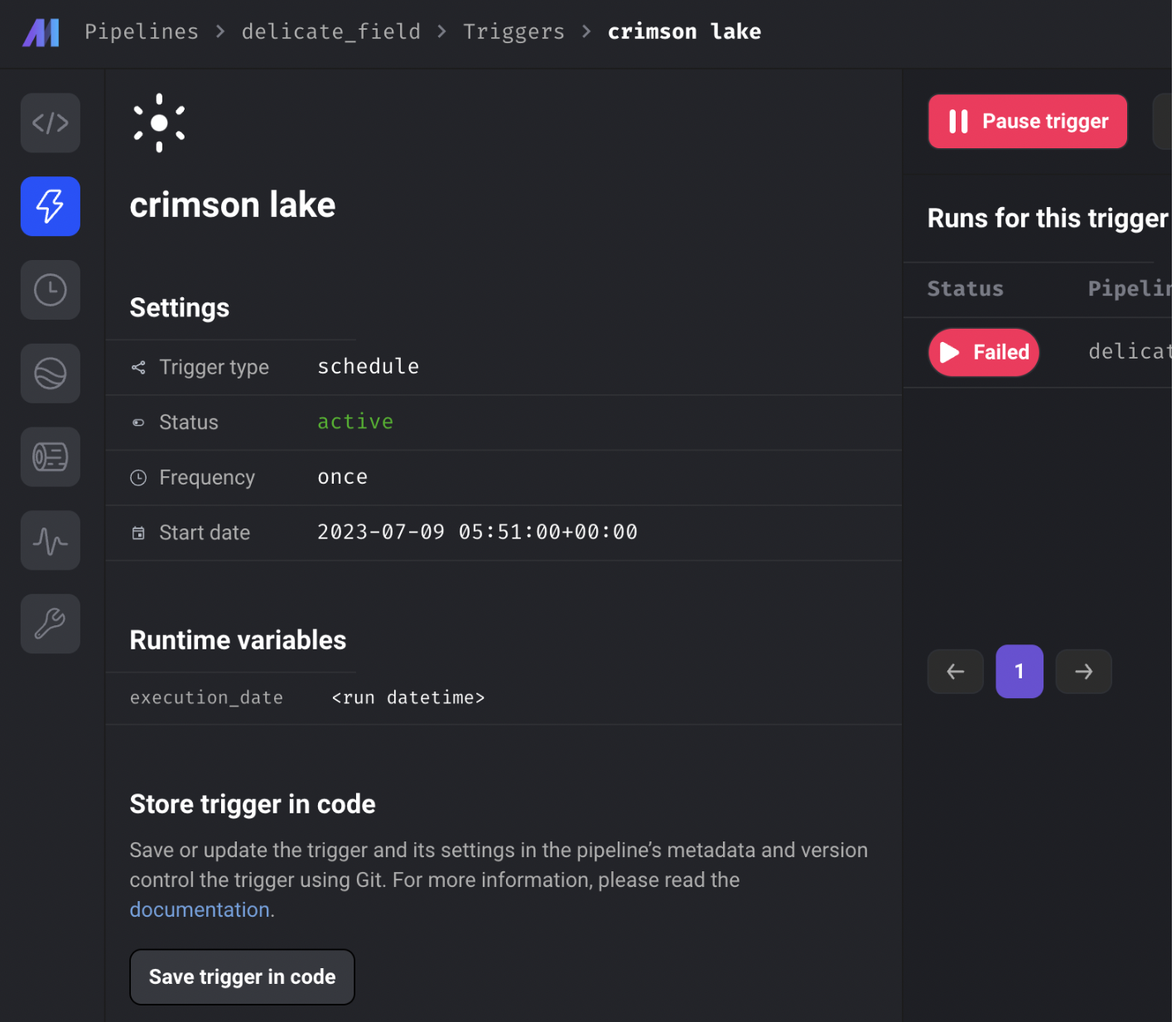
Save trigger from UI to code
Cloud deployment
-
Allow setting service account name for k8s executor
- Example k8s executor config:
k8s_executor_config: resource_limits: cpu: 1000m memory: 2048Mi resource_requests: cpu: 500m memory: 1024Mi service_account_name: custom_service_account_name
-
Support customizing the timeout seconds in GCP cloud run config.
- Example config
gcp_cloud_run_config: path_to_credentials_json_file: "/path/to/credentials_json_file" project_id: project_id timeout_seconds: 600
-
Check ECS task status after running the task.
Streaming pipeline
- Fix copy output in streaming pipeline. Catch deepcopy error (
TypeError: cannot pickle '_thread.lock' object in the deepcopy from the handle_batch_events_recursively) and fallback to copy method.
Spark pipeline
- Fix an issue with setting custom Spark pipeline config.
- Fix testing Spark DataFrame. Pass the correct Spark DataFrame to the test method.
Other bug fixes & polish
- Add json value macro. Example usage:
"{{ json_value(aws_secret_var('test_secret_key_value'), 'k1') }}" - Allow slashes in block_uuid when downloading block output. The regex for the block output download endpoint would not capture block_uuids with slashes in them, so this fixes that.
- Fix renaming block.
- Fix user auth when disable notebook edits is enabled.
- Allow JWT_SECRET to be modified via env var. The
JWT_SECRET...
0.8.93 | Rise of the Beasts Release

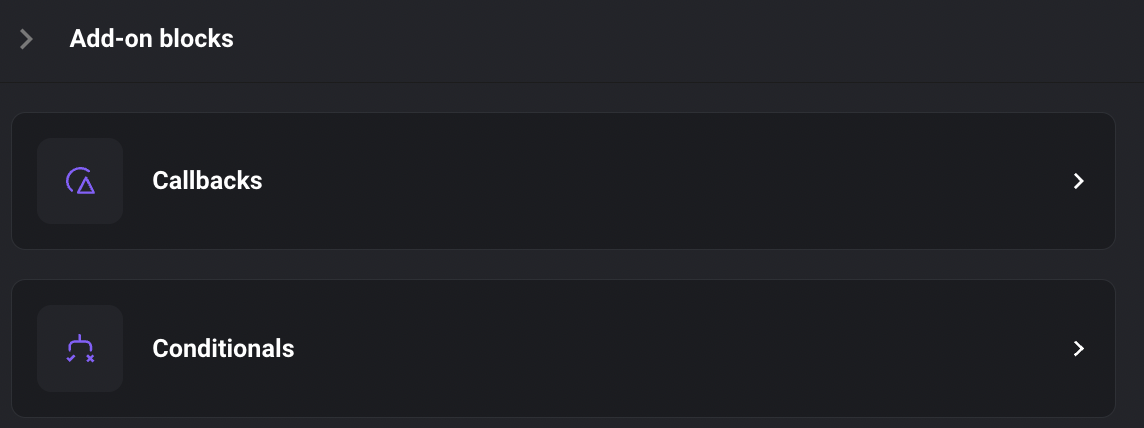
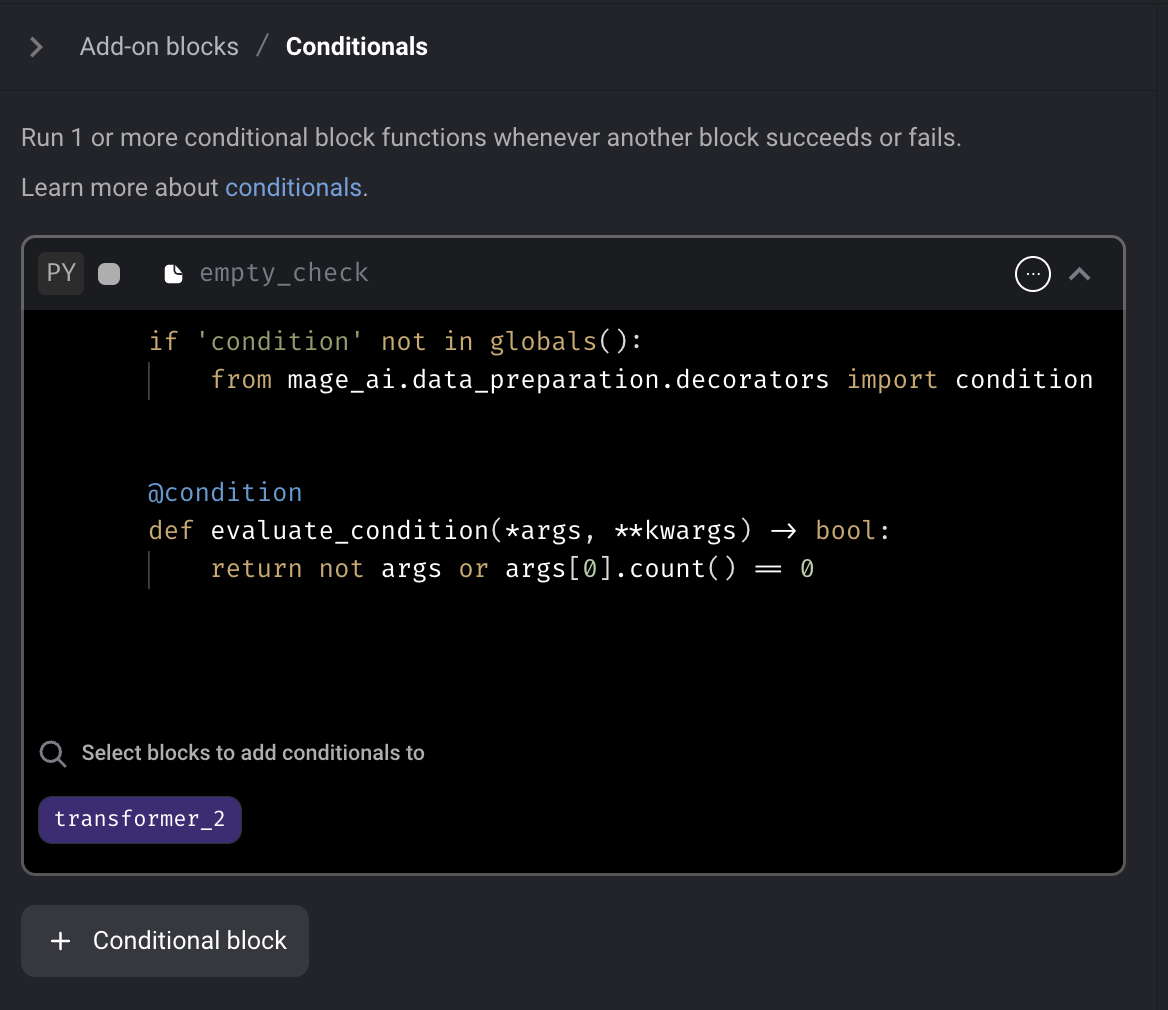
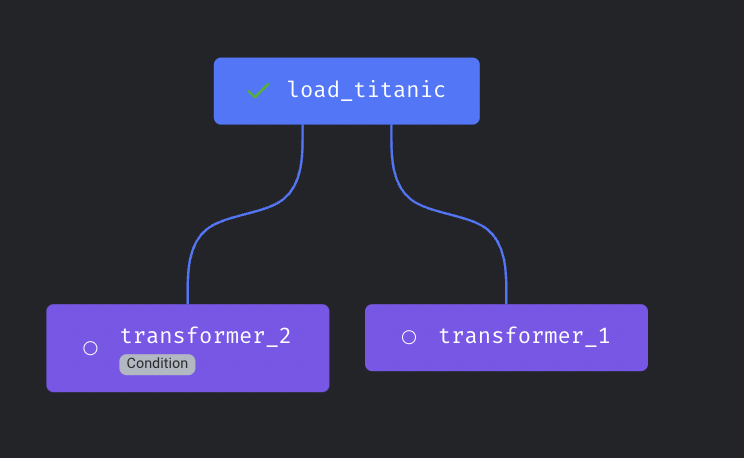
Conditional block
Add conditional block to Mage. The conditional block is an "Add-on" block that can be added to an existing block within a pipeline. If the conditional block evaluates as False, the parent block will not be executed.
Doc: https://docs.mage.ai/development/blocks/conditionals/overview
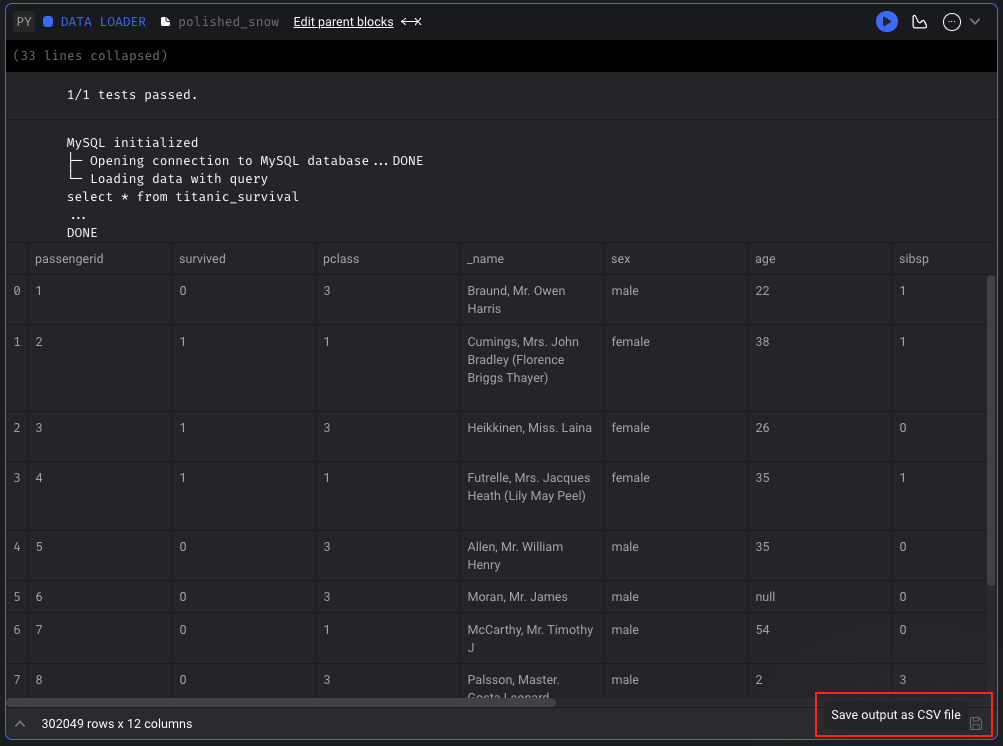
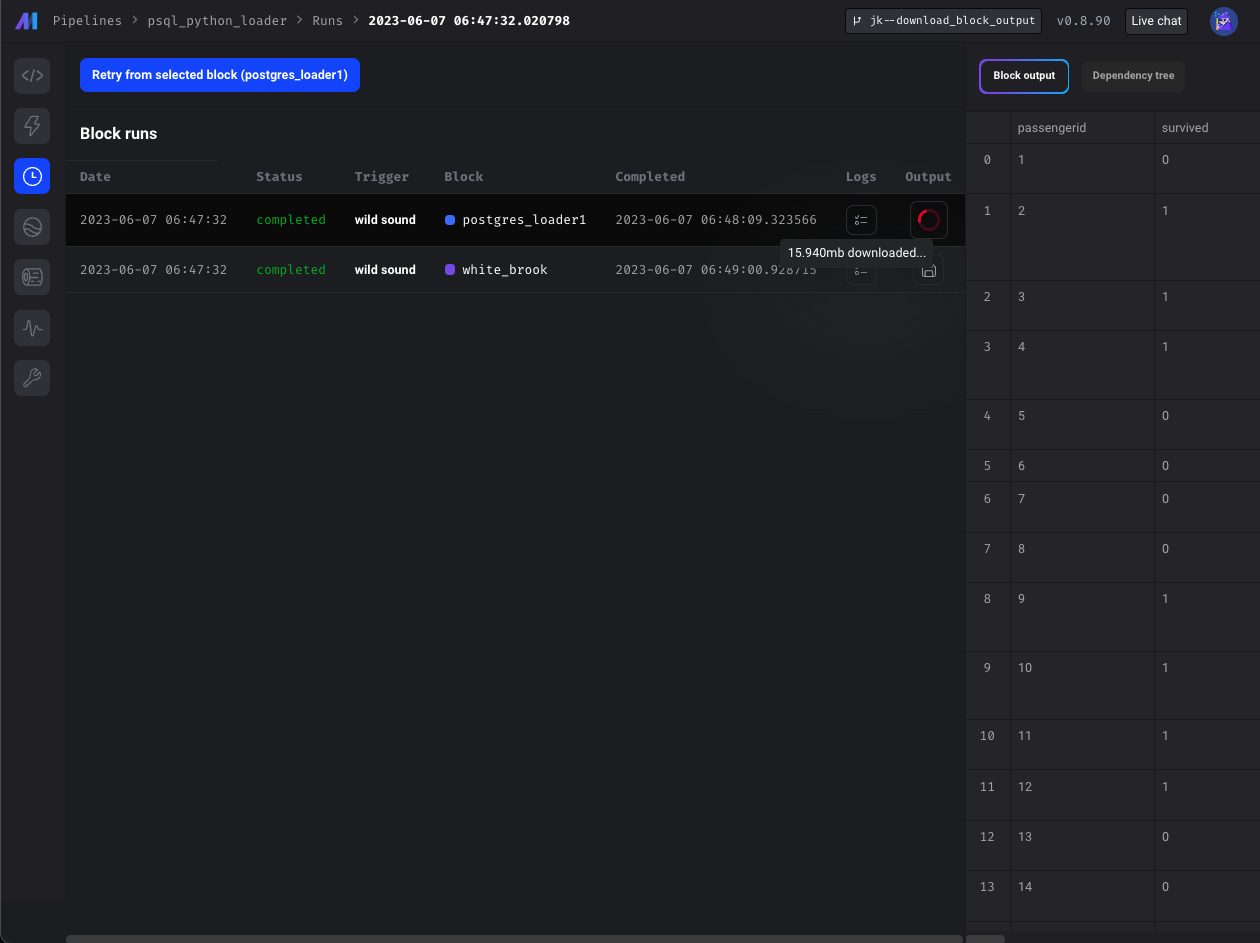
Download block output
For standard pipelines (not currently supported in integration or streaming pipelines), you can save the output of a block that has been run as a CSV file. You can save the block output in Pipeline Editor page or Block Runs page.
Doc: https://docs.mage.ai/orchestration/pipeline-runs/saving-block-output-as-csv
Customize Pipeline level spark config
Mage supports customizing Spark session for a pipeline by specifying the spark_config in the pipeline metadata.yaml file. The pipeline level spark_config will override the project level spark_config if specified.
Doc: https://docs.mage.ai/integrations/spark-pyspark#custom-spark-session-at-the-pipeline-level
Data integration pipeline
Oracle DB source
Download file data in the API source
Doc: https://github.com/mage-ai/mage-ai/tree/master/mage_integrations/mage_integrations/sources/api
Personalize notification messages
Users can customize the notification templates of different channels (slack, email, etc.) in project metadata.yaml. Hare are the supported variables that can be interpolated in the message templates: execution_time , pipeline_run_url , pipeline_schedule_id, pipeline_schedule_name, pipeline_uuid
Example config in project's metadata.yaml
notification_config:
slack_config:
webhook_url: "{{ env_var('MAGE_SLACK_WEBHOOK_URL') }}"
message_templates:
failure:
details: >
Failure to execute pipeline {pipeline_run_url}.
Pipeline uuid: {pipeline_uuid}. Trigger name: {pipeline_schedule_name}.
Test custom message."
Doc: https://docs.mage.ai/production/observability/alerting-slack#customize-message-templates
Support MSSQL and MySQL as the database engine
Mage stores orchestration data, user data, and secrets data in a database. In addition to SQLite and Postgres, Mage supports using MSSQL and MySQL as the database engine now.
MSSQL docs:
- https://docs.mage.ai/production/databases/default#mssql
- https://docs.mage.ai/getting-started/setup#using-mssql-as-database
MySQL docs:
- https://docs.mage.ai/production/databases/default#mysql
- https://docs.mage.ai/getting-started/setup#using-mysql-as-database
Add MinIO and Wasabi support via S3 data loader block
Mage supports connecting to MinIO and Wasabi by specifying the AWS_ENDPOINT field in S3 config now.
Doc: https://docs.mage.ai/integrations/databases/S3#minio-support
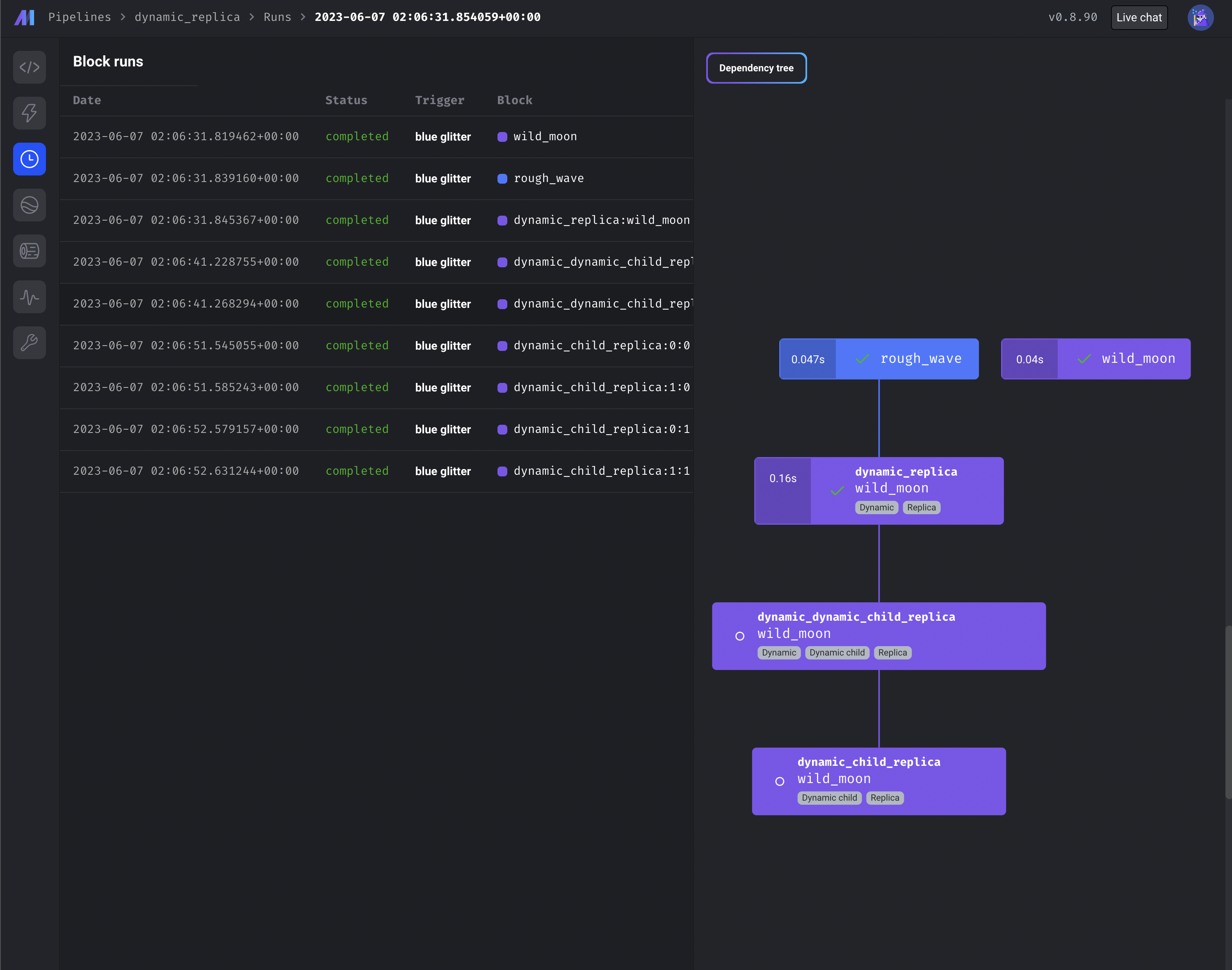
Use dynamic blocks with replica blocks
To maximize block reuse, you can use dynamic and replica blocks in combination.
- https://docs.mage.ai/design/blocks/dynamic-blocks
- https://docs.mage.ai/design/blocks/replicate-blocks
Other bug fixes & polish
- The command
CREATE SCHEMA IF NOT EXISTSis not supported by MSSQL. Provided a default command in BaseSQL -> build_create_schema_command, and an overridden implementation in MSSQL -> build_create_schema_command containing compatible syntax. (Kudos to gjvanvuuren) - Fix streaming pipeline
kwargspassing so that RabbitMQ messages can be acknowledged correctly. - Interpolate variables in streaming configs.
- Git integration: Create known hosts if it doesn't exist.
- Do not create duplicate triggers when DB query fails on checking existing triggers.
- Fix bug: when there are multiple downstream replica blocks, those blocks are not getting queued.
- Fix block uuid formatting for logs.
- Update WidgetPolicy to allow editing and creating widgets without authorization errors.
- Update sensor block to accept positional arguments.
- Fix variables for GCP Cloud Run executor.
- Fix MERGE command for Snowflake destination.
- Fix encoding issue of file upload.
- Always delete the temporary DBT profiles dir to prevent file browser performance degrade.
0.8.86 | Fast Release

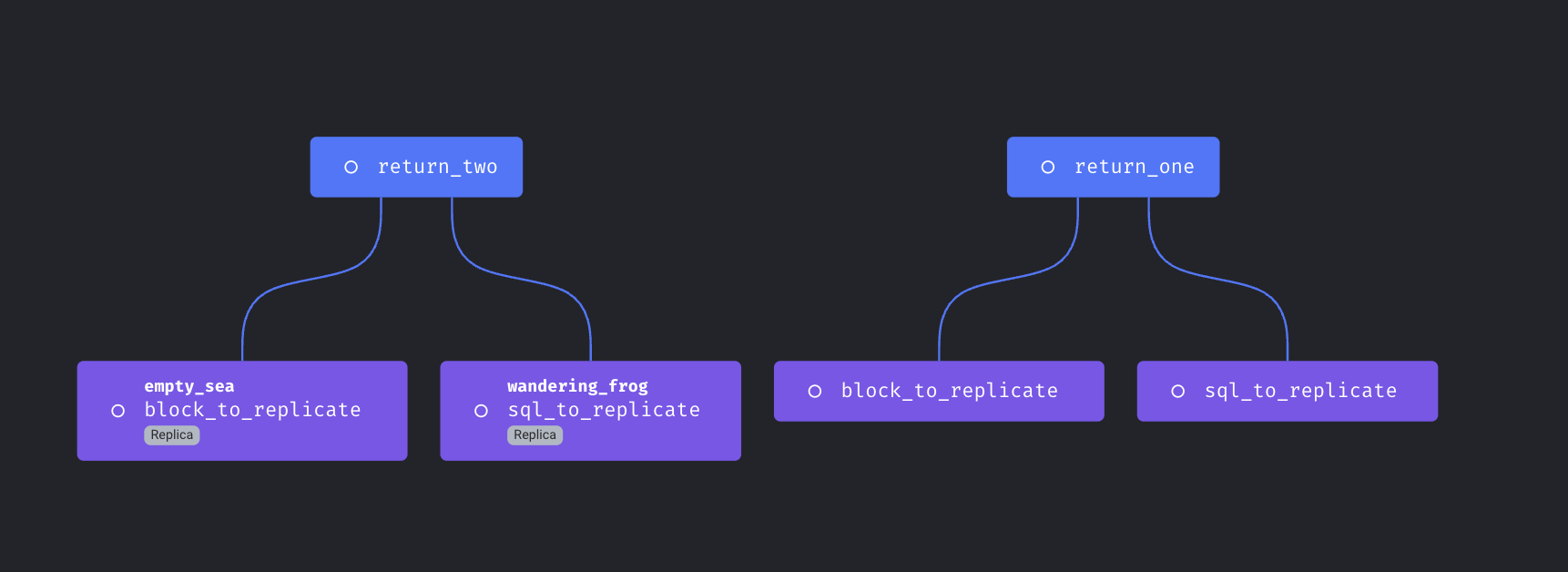
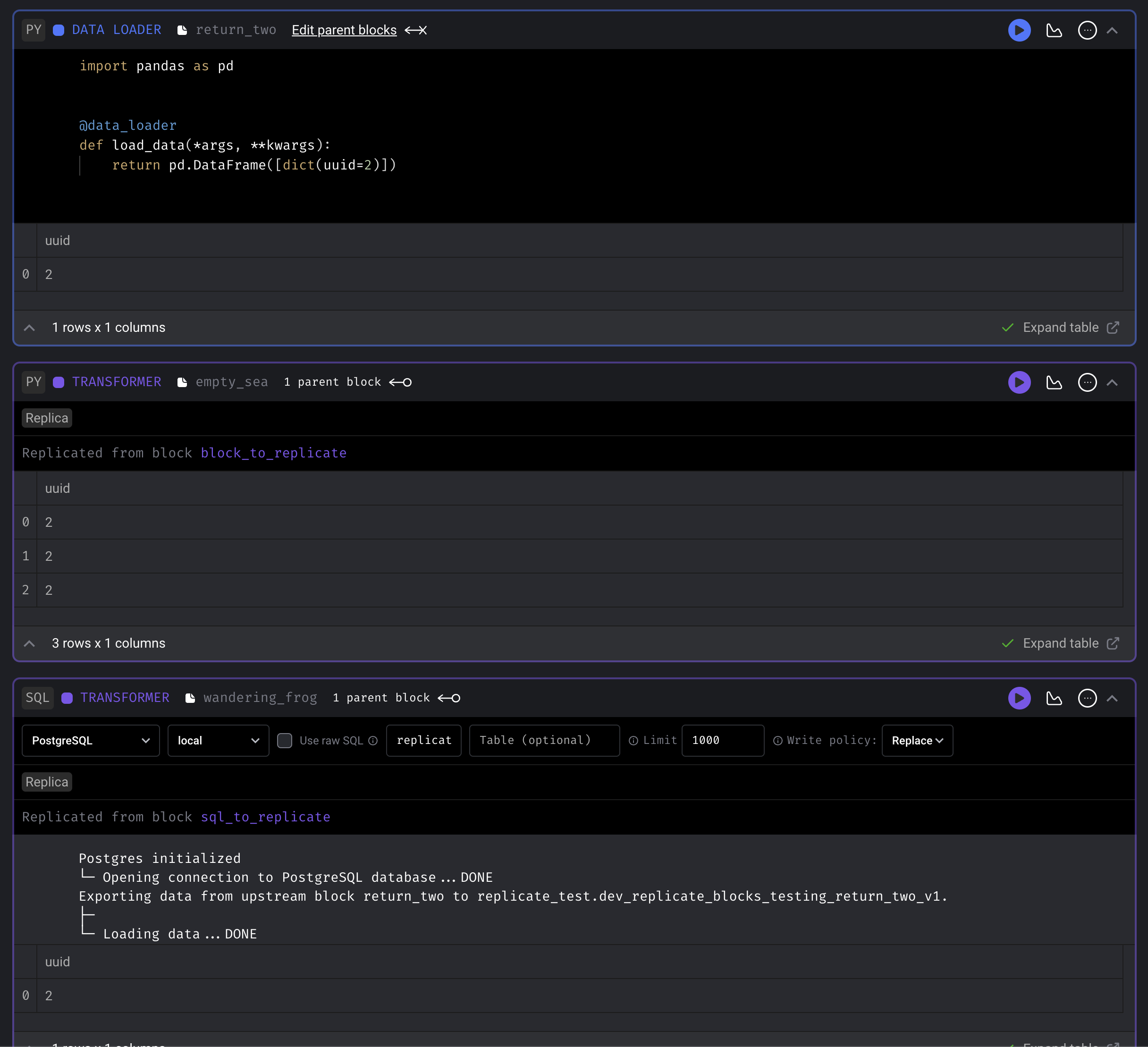
Replicate blocks
Support reusing same block multiple times in a single pipeline.
Doc: https://docs.mage.ai/design/blocks/replicate-blocks
Spark on Yarn
Support running Spark code on Yarn cluster with Mage.
Doc: https://docs.mage.ai/integrations/spark-pyspark#hadoop-and-yarn-cluster-for-spark
Customize retry config
Mage supports configuring automatic retry for block runs with the following ways
- Add
retry_configto project’smetadata.yaml. Thisretry_configwill be applied to all block runs. - Add
retry_configto the block config in pipeline’smetadata.yaml. The block levelretry_configwill override the globalretry_config.
Example config:
retry_config:
# Number of retry times
retries: 0
# Initial delay before retry. If exponential_backoff is true,
# the delay time is multiplied by 2 for the next retry
delay: 5
# Maximum time between the first attempt and the last retry
max_delay: 60
# Whether to use exponential backoff retry
exponential_backoff: trueDoc: https://docs.mage.ai/orchestration/pipeline-runs/retrying-block-runs#automatic-retry
DBT improvements
-
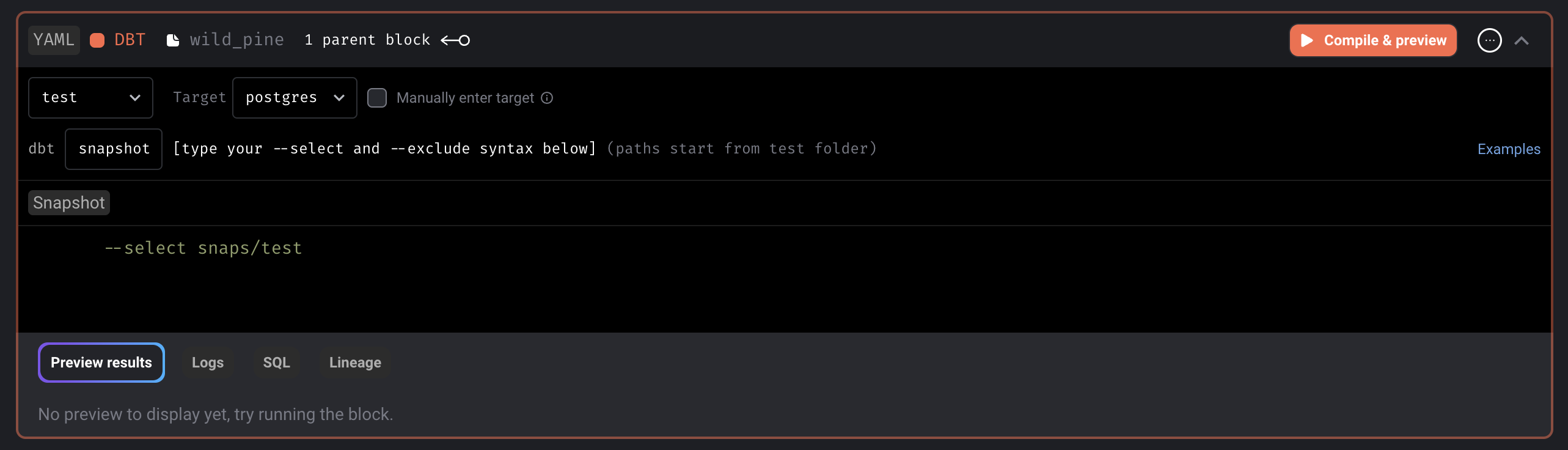
When running DBT block with language YAML, interpolate and merge the user defined --vars in the block’s code into the variables that Mage automatically constructs
- Example block code of different formats
--select demo/models --vars '{"demo_key": "demo_value", "date": 20230101}' --select demo/models --vars {"demo_key":"demo_value","date":20230101} --select demo/models --vars '{"global_var": {{ test_global_var }}, "env_var": {{ test_env_var }}}' --select demo/models --vars {"refresh":{{page_refresh}},"env_var":{{env}}}
-
Support
dbt_project.ymlcustom project names and custom profile names that are different than the DBT folder name -
Allow user to configure block to run DBT snapshot
Dynamic SQL block
Support using dynamic child blocks for SQL blocks
Doc: https://docs.mage.ai/design/blocks/dynamic-blocks#dynamic-sql-blocks
Run blocks concurrently in separate containers on Azure
If your Mage app is deployed on Microsoft Azure with Mage’s terraform scripts, you can choose to launch separate Azure container instances to execute blocks.
Run the scheduler and the web server in separate containers or pods
- Run scheduler only:
mage start project_name --instance-type scheduler - Run web server only:
mage start project_name --instance-type web_server- web server can be run in multiple containers or pods
- Run both server and scheduler:
mage start project_name --instance-type server_and_scheduler
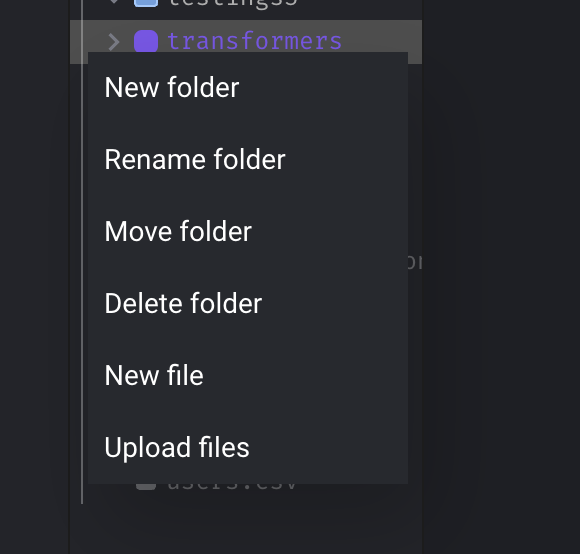
Support all operations on folder
Support “Add”, “Rename”, “Move”, “Delete” operations on folder.
Configure environments for triggers in code
Allow specifying envs value to apply triggers only in certain environments.
Example:
triggers:
- name: test_example_trigger_in_prod
schedule_type: time
schedule_interval: "@daily"
start_time: 2023-01-01
status: active
envs:
- prod
- name: test_example_trigger_in_dev
schedule_type: time
schedule_interval: "@hourly"
start_time: 2023-03-01
status: inactive
settings:
skip_if_previous_running: true
allow_blocks_to_fail: true
envs:
- devDoc: https://docs.mage.ai/guides/triggers/configure-triggers-in-code#create-and-configure-triggers
Replace current logs table with virtualized table for better UI performance
- Use virtual table to render logs so that loading thousands of rows won't slow down browser performance.
- Fix formatting of logs table rows when a log is selected (the log detail side panel would overly condense the main section, losing the place of which log you clicked).
- Pin logs page header and footer.
- Tested performance using Lighthouse Chrome browser extension, and performance increased 12 points.
Other bug fixes & polish
-
Add indices to schedule models to speed up DB queries.
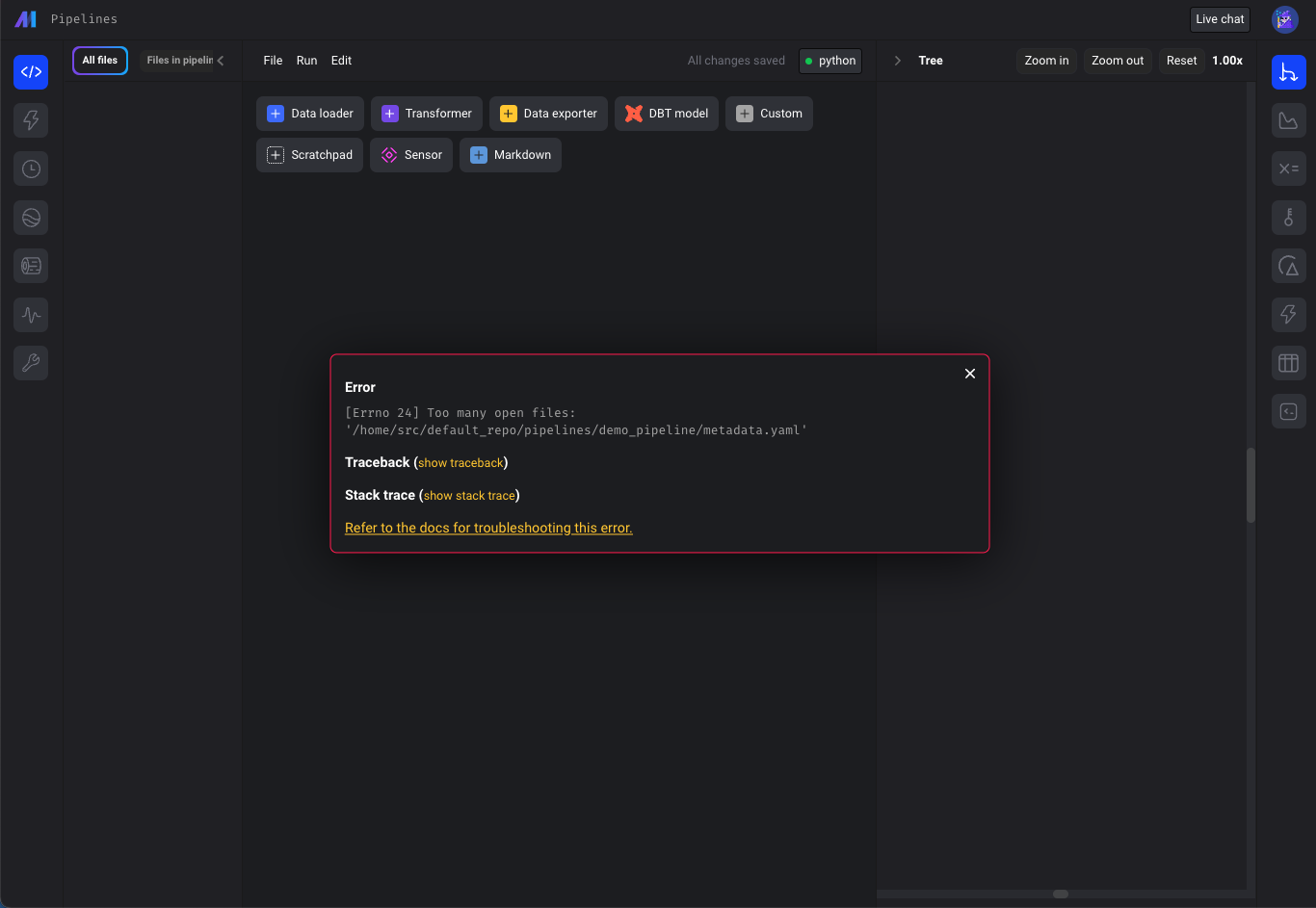
-
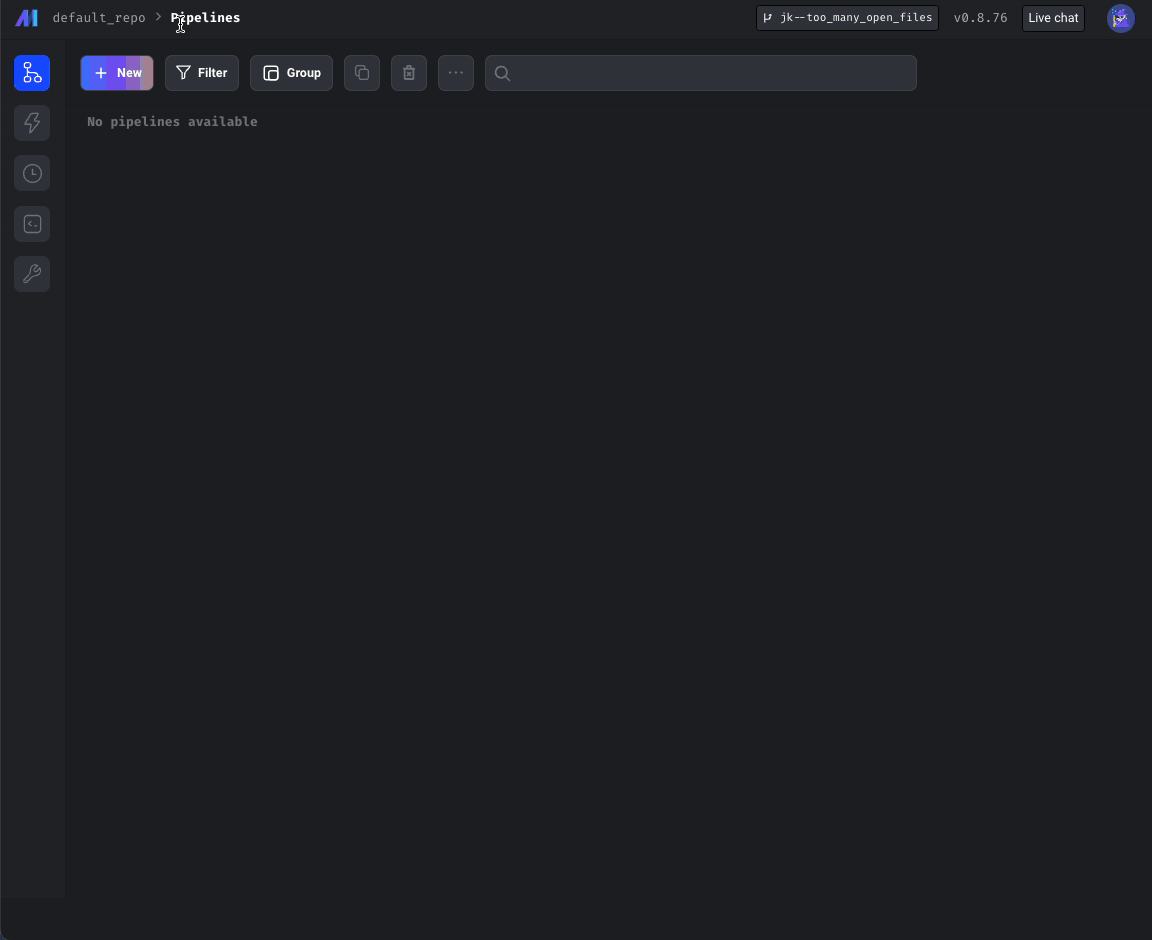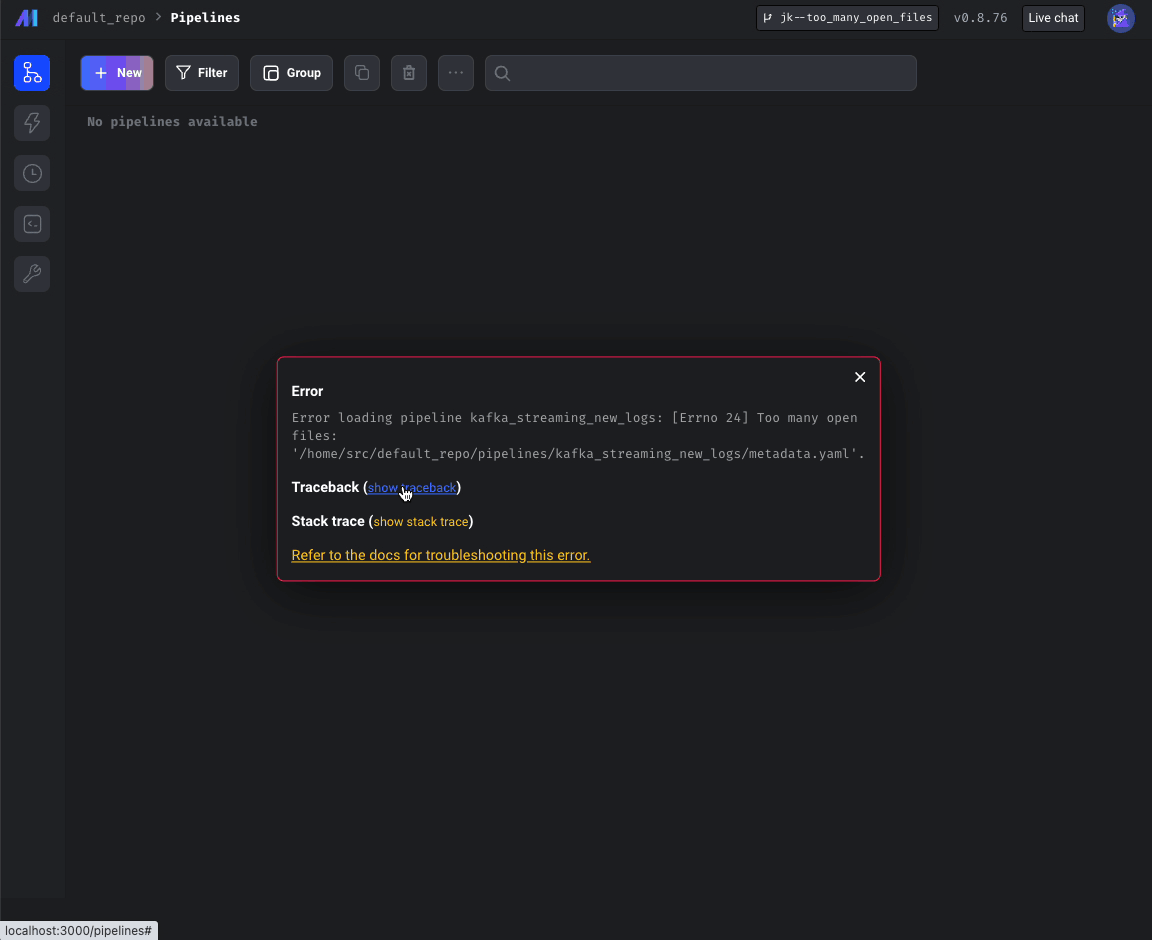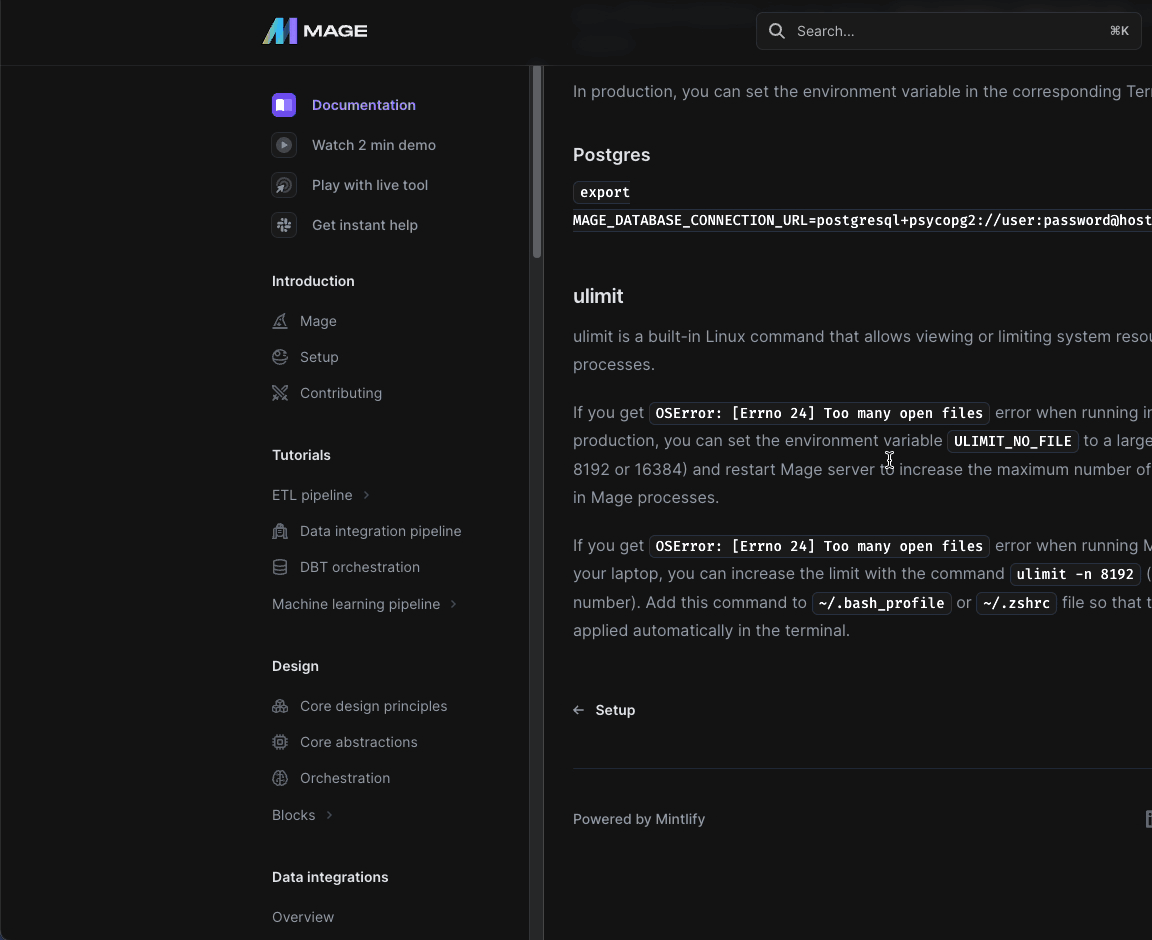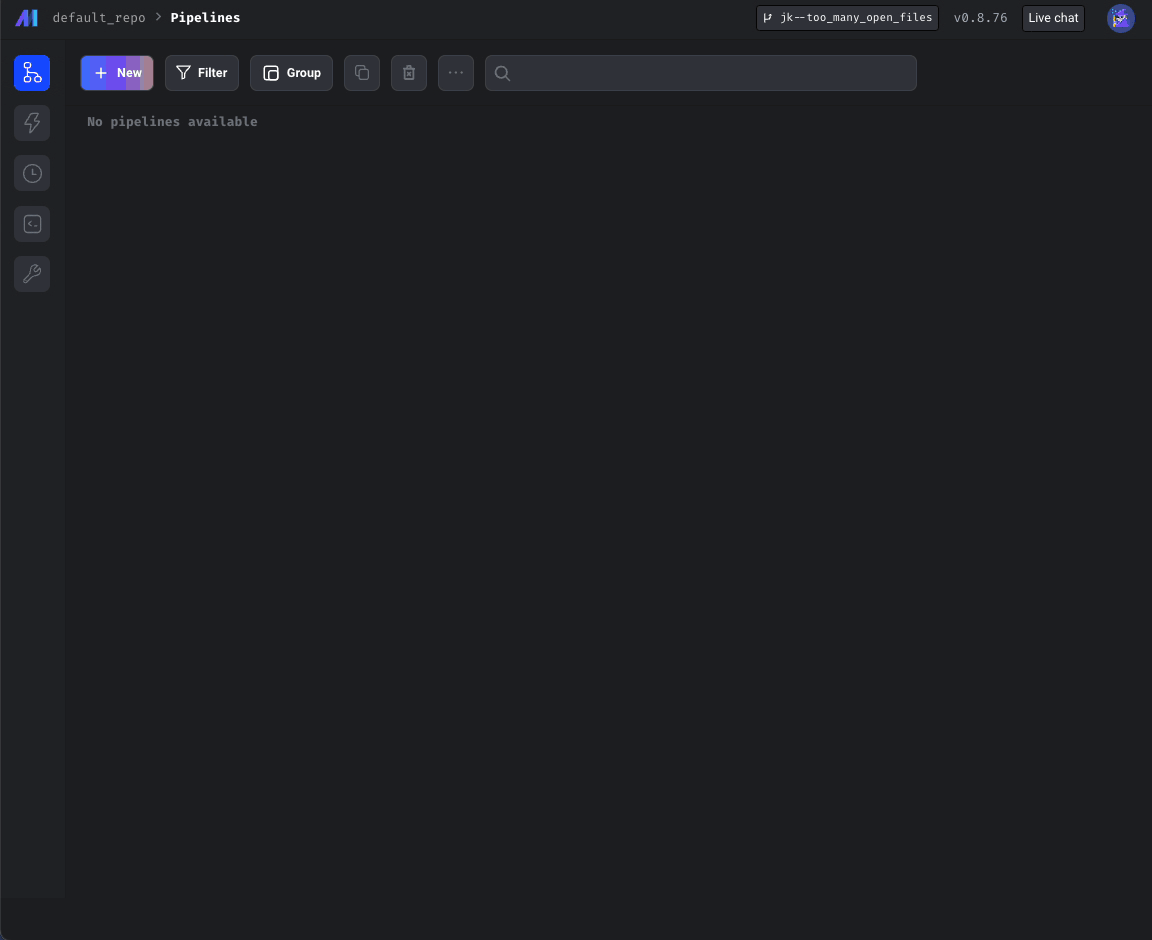
“Too many open files issue”
- Check for "Too many open files" error on all pages calling "displayErrorFromReadResponse" util method (e.g. pipeline edit page), not just Pipelines Dashboard.
- Update terraform scripts to set the
ULIMIT_NO_FILEenvironment variable to increase maximum number of open files in Mage deployed on AWS, GCP and Azure.
-
Fix git_branch resource blocking page loads. The
git clonecommand could cause the entire app to hang if the host wasn't added to known hosts.git clonecommand is updated to run as a separate process with the timeout, so it won't block the entire app if it's stuck. -
Fix bug: when adding a block in between blocks in pipeline with two separate root nodes, the downstream connections are removed.
-
Fix DBT error:
KeyError: 'file_path'. Check forfile_pathbefore callingparse_attributesmethod to avoid KeyError. -
Improve the coding experience when working with Snowflake data provider credentials. Allow more flexibility in Snowflake SQL block queries. Doc: https://docs.mage.ai/integrations/databases/Snowflake#methods-for-configuring-database-and-schema
-
Pass parent block’s output and variables to its callback blocks.
-
Fix missing input field and select field descriptions in charts.
-
Fix bug: Missing values template chart doesn’t render.
-
Convert
numpy.ndarraytolistif column type is list when fetching input variables for blocks. -
Fix runtime and global variables not available in the keyword arguments when executing block with upstream blocks from the edit pipeline page.
View full Changelog
0.8.83 | Fury of the Gods Release

Support more complex streaming pipeline
More complex streaming pipeline is supported in Mage now. You can use more than transformer and more than one sinks in the streaming pipeline.
Here is an example streaming pipeline with multiple transformers and sinks.
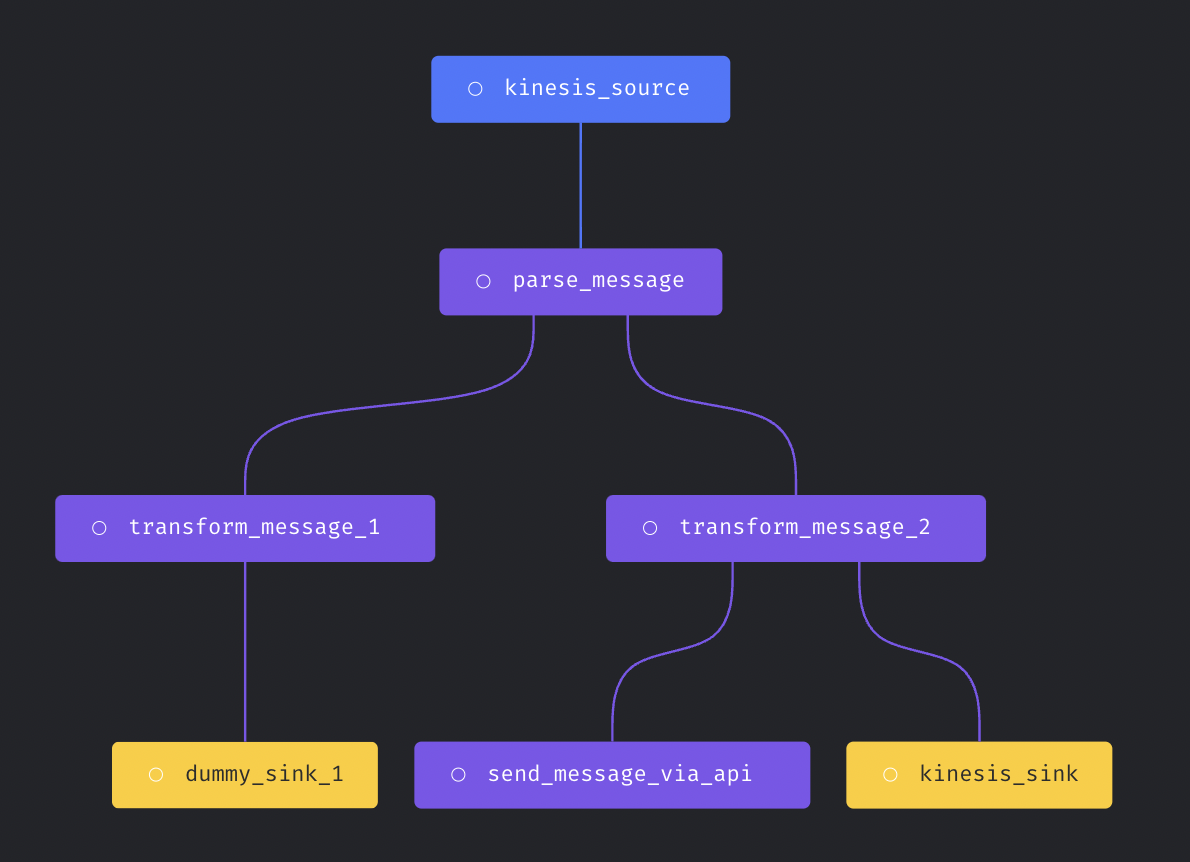
Doc for streaming pipeline: https://docs.mage.ai/guides/streaming/overview
Custom Spark configuration
Allow using custom Spark configuration to create Spark session used in the pipeline.
spark_config:
# Application name
app_name: 'my spark app'
# Master URL to connect to
# e.g., spark_master: 'spark://host:port', or spark_master: 'yarn'
spark_master: 'local'
# Executor environment variables
# e.g., executor_env: {'PYTHONPATH': '/home/path'}
executor_env: {}
# Jar files to be uploaded to the cluster and added to the classpath
# e.g., spark_jars: ['/home/path/example1.jar']
spark_jars: []
# Path where Spark is installed on worker nodes,
# e.g. spark_home: '/usr/lib/spark'
spark_home: null
# List of key-value pairs to be set in SparkConf
# e.g., others: {'spark.executor.memory': '4g', 'spark.executor.cores': '2'}
others: {}Doc for running PySpark pipeline: https://docs.mage.ai/integrations/spark-pyspark#standalone-spark-cluster
Data integration pipeline
DynamoDB source
New data integration source DynamoDB is added.
Bug fixes
- Use
timestamptzas data type for datetime column in Postgres destination. - Fix BigQuery batch load error.
Show file browser outside edit pipeline
Improved the file editor of Mage so that user can edit the files without going into a pipeline.
Add all file operations
Speed up writing block output to disk
Mage uses Polars to speed up writing block output (DataFrame) to disk, reducing the time of fetching and writing a DataFrame with 2 million rows from 90s to 15s.
Add default .gitignore
Mage automatically adds the default .gitignore file when initializing project
.DS_Store
.file_versions
.gitkeep
.log
.logs/
.preferences.yaml
.variables/
__pycache__/
docker-compose.override.yml
logs/
mage-ai.db
mage_data/
secrets/
Other bug fixes & polish
- Include trigger URL in slack alert.

- Fix race conditions for multiple runs within one second
- If DBT block is language YAML, hide the option to add upstream dbt refs
- Include event_variables in individual pipeline run retry
- Callback block
- Include parent block uuid in callback block kwargs
- Pass parent block’s output and variables to its callback blocks
- Delete GCP cloud run job after it's completed.
- Limit the code block output from print statements to avoid sending excessively large payload request bodies when saving the pipeline.
- Lock typing extension version to fix error
TypeError: Instance and class checks can only be used with @runtime protocols. - Fix git sync and also updates how we save git settings for users in the backend.
- Fix MySQL ssh tunnel: close ssh tunnel connection after testing connection.
View full Changelog
0.8.78 | Rise of the Machines Release

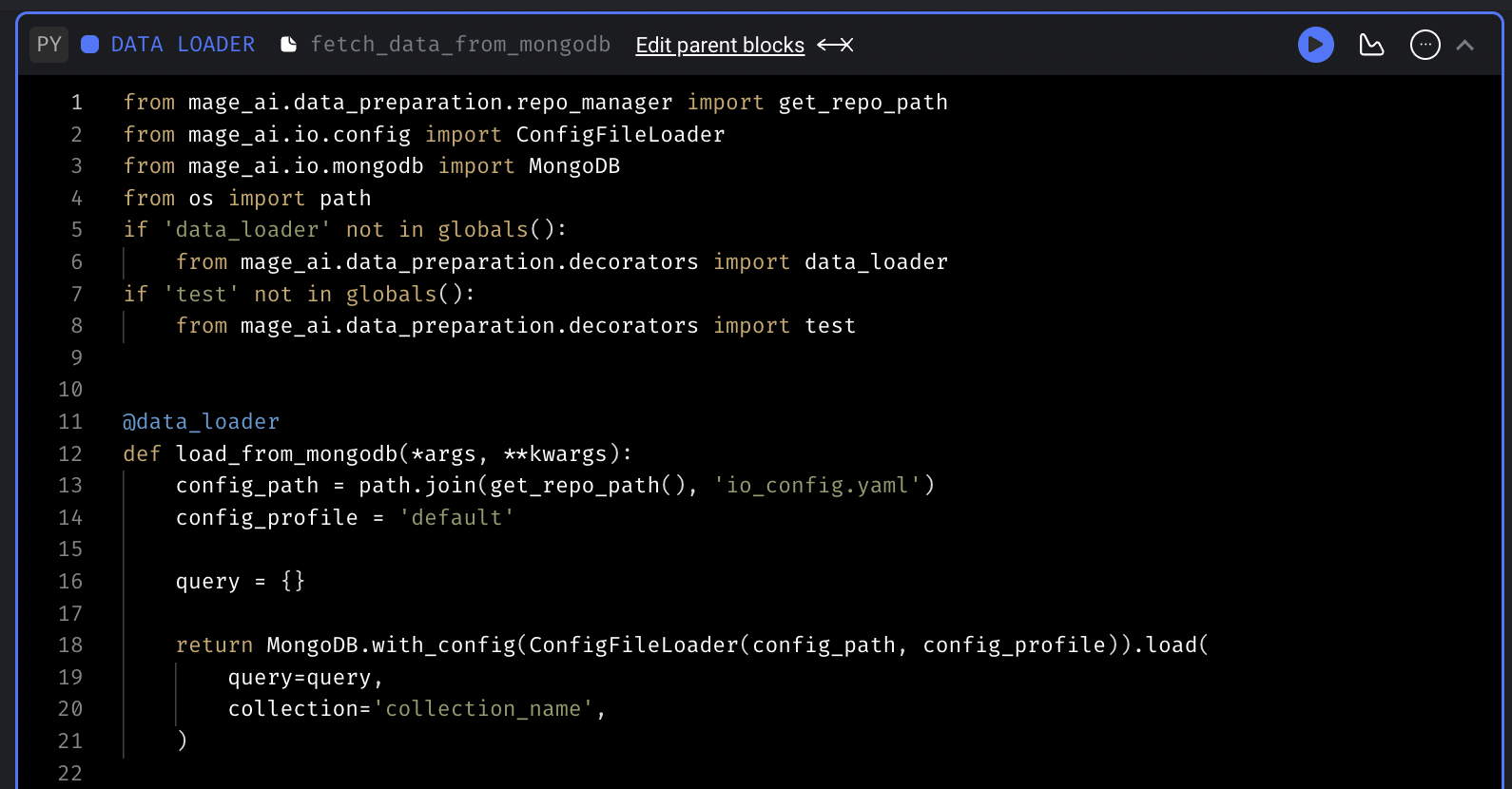
MongoDB code templates
Add code templates to fetch data from and export data to MongoDB.
Example MongoDB config in io_config.yaml :
version: 0.1.1
default:
MONGODB_DATABASE: database
MONGODB_HOST: host
MONGODB_PASSWORD: password
MONGODB_PORT: 27017
MONGODB_COLLECTION: collection
MONGODB_USER: userData loader template
Data exporter template
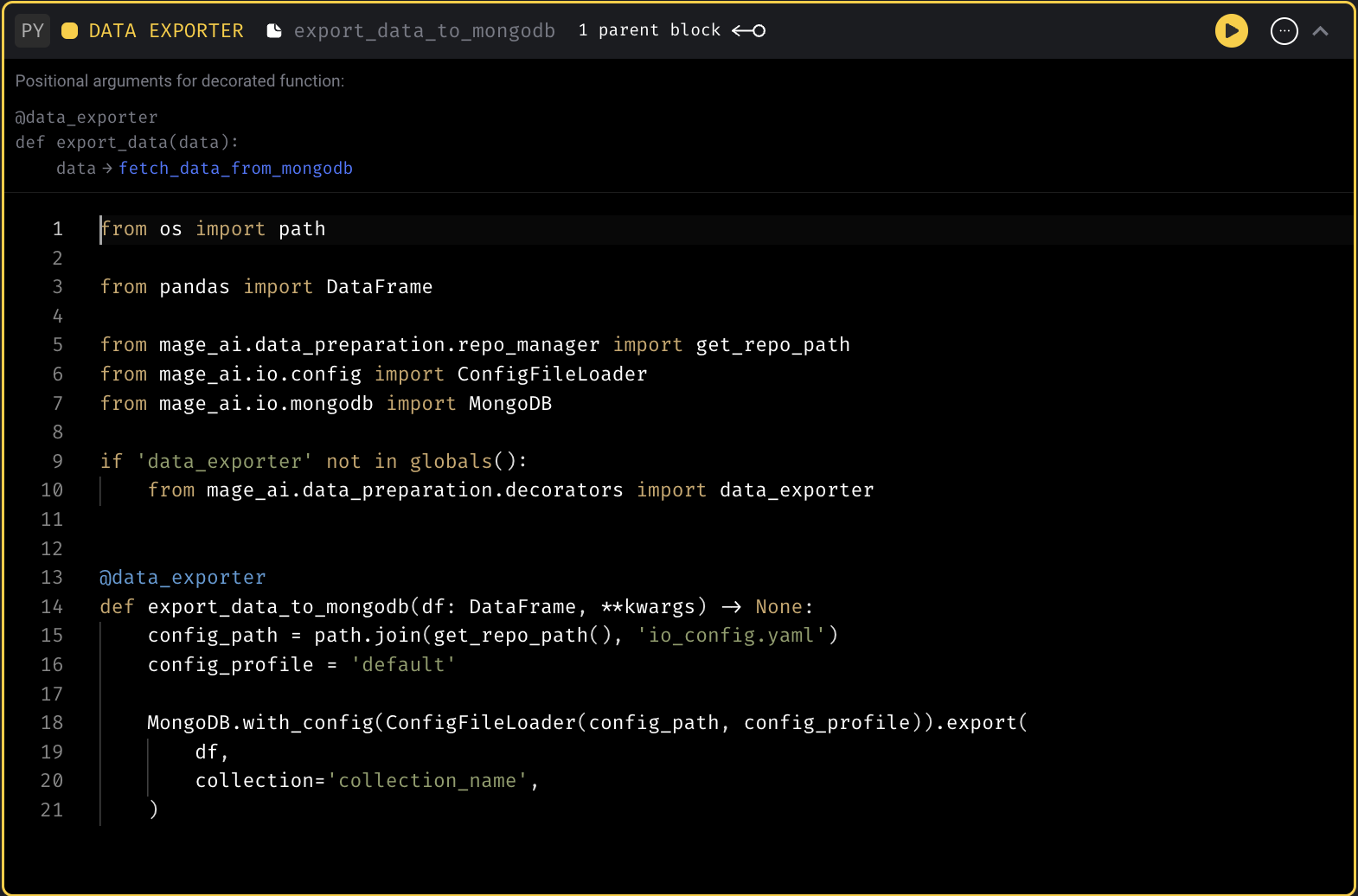
Support using renv for R block
renv is installed in Mage docker image by default. User can use renv package to manage R dependency for your project.
Doc for renv package: https://cran.r-project.org/web/packages/renv/vignettes/renv.html
Run streaming pipeline in separate k8s pod
Support running streaming pipeline in k8s executor to scale up streaming pipeline execution.
It can be configured in pipeline metadata.yaml with executor_type field. Here is an example:
blocks:
- ...
- ...
executor_count: 1
executor_type: k8s
name: test_streaming_kafka_kafka
uuid: test_streaming_kafka_kafkaWhen cancelling the pipeline run in Mage UI, Mage will kill the k8s job.
DBT support for Spark
Support running Spark DBT models in Mage. Currently, only the connection method session is supported.
Follow this doc to set up Spark environment in Mage. Follow the instructions in https://docs.mage.ai/tutorials/setup-dbt to set up the DBT. Here is an example DBT Spark profiles.yml
spark_demo:
target: dev
outputs:
dev:
type: spark
method: session
schema: default
host: localDoc for staging/production deployment
- Add doc for setting up the CI/CD pipeline to deploy Mage to staging and production environments: https://docs.mage.ai/production/ci-cd/staging-production/github-actions
- Provide example Github Action template for deployment on AWS ECS: https://github.com/mage-ai/mage-ai/blob/master/templates/github_actions/build_and_deploy_to_aws_ecs_staging_production.yml
Enable user authentication for multi-development environment
Update the multi-development environment to go through the user authentication flow. Multi-development environment is used to manage development instances on cloud.
Doc for multi-development environment: https://docs.mage.ai/developing-in-the-cloud/cloud-dev-environments/overview
Refined dependency graph
- Add buttons for zooming in/out of and resetting dependency graph.
- Add shortcut to reset dependency graph view (double-clicking anywhere on the canvas).
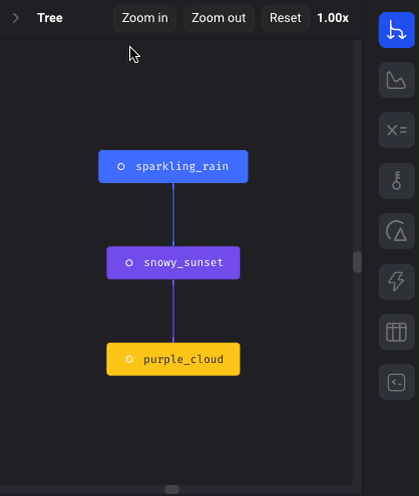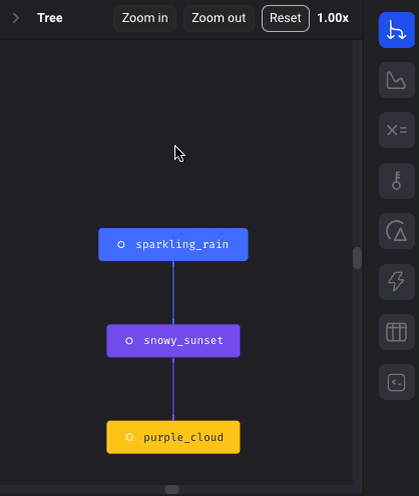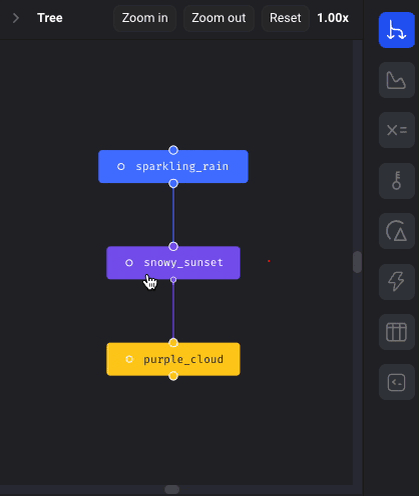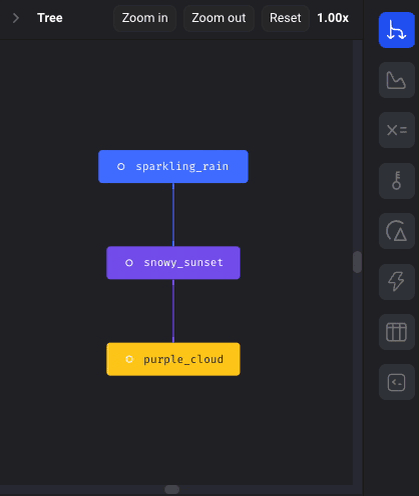
Add new block with downstream blocks connected
- If a new block is added between two blocks, include the downstream connection.
- If a new block is added after a block that has multiple downstream blocks, the downstream connections will not be added since it is unclear which downstream connections should be made.
- Hide Add transformer block button in integration pipelines if a transformer block already exists (Mage currently only supports 1 transformer block for integration pipelines).
Improve UI performance
- Reduce number of API requests made when refocusing browser.
- Decrease notebook CPU and memory consumption in the browser by removing unnecessary code block re-renders in Pipeline Editor.
Add pre-commit and improve contributor friendliness
Shout out to Joseph Corrado for his contribution of adding pre-commit hooks to Mage to run code checks before committing and pushing the code.
Doc: https://github.com/mage-ai/mage-ai/blob/master/README_dev.md
Create method for deleting secret keys
Shout out to hjhdaniel for his contribution of adding the method for deleting secret keys to Mage.
Example code:
from mage_ai.data_preparation.shared.secrets import delete_secret
delete_secret('secret_name')Retry block
Retry from selected block in integration pipeline
If a block is selected in an integration pipeline to retry block runs, only the block runs for the selected block's stream will be ran.
Automatic retry for blocks
Mage now automatically retries blocks twice on failures (3 total attempts).
Other bug fixes & polish
-
Display error popup with link to docs for “too many open files” error.
-
Fix DBT block limit input field: the limit entered through the UI wasn’t taking effect when previewing the model results. Fix this and set a default limit of 1000.
-
Fix BigQuery table id issue for batch load.
-
Fix unique conflict handling for BigQuery batch load.
-
Remove startup_probe in GCP cloud run executor.
-
Fix run command for AWS and GCP job runs so that job run logs can be shown in Mage UI correctly.
-
Pass block configuration to
kwargsin the method. -
Fix SQL block execution when using different schemas between upstream block and current block.
View full Changelog