A curated list for Efficient Large Language Models
- Knowledge Distillation
- Network Pruning / Sparsity
- Quantization
- Inference Acceleration
- Efficient MOE
- Efficient Architecture of LLM
- KV Cache Compression
- Text Compression
- Low-Rank Decomposition
- Hardware / System
- Tuning
- Survey
- Leaderboard
Please check out all the papers by selecting the sub-area you're interested in. On this page, we're showing papers released in the past 60 days.
- May 29, 2024: We've had this awesome list for a year now 🥰! It's grown pretty long, so we're reorganizing it and would divide the list by their specific areas into different readme.
- Sep 27, 2023: Add tag
for papers accepted at NeurIPS'23.
- Sep 6, 2023: Add a new subdirectory project/ to organize those projects that are designed for developing a lightweight LLM.
- July 11, 2023: In light of the numerous publications that conduct experiments using PLMs (such as BERT, BART) currently, a new subdirectory efficient_plm/ is created to house papers that are applicable to PLMs but have yet to be verified for their effectiveness on LLMs (not implying that they are not suitable on LLM).
Paper from May 26, 2024 - Now (see Full List from May 22, 2023 here)
| Title & Authors | Introduction | Links |
|---|---|---|
| LLM and GNN are Complementary: Distilling LLM for Multimodal Graph Learning Junjie Xu, Zongyu Wu, Minhua Lin, Xiang Zhang, Suhang Wang |
 |
Paper |
 Adversarial Moment-Matching Distillation of Large Language Models Chen Jia |
 |
Github Paper |







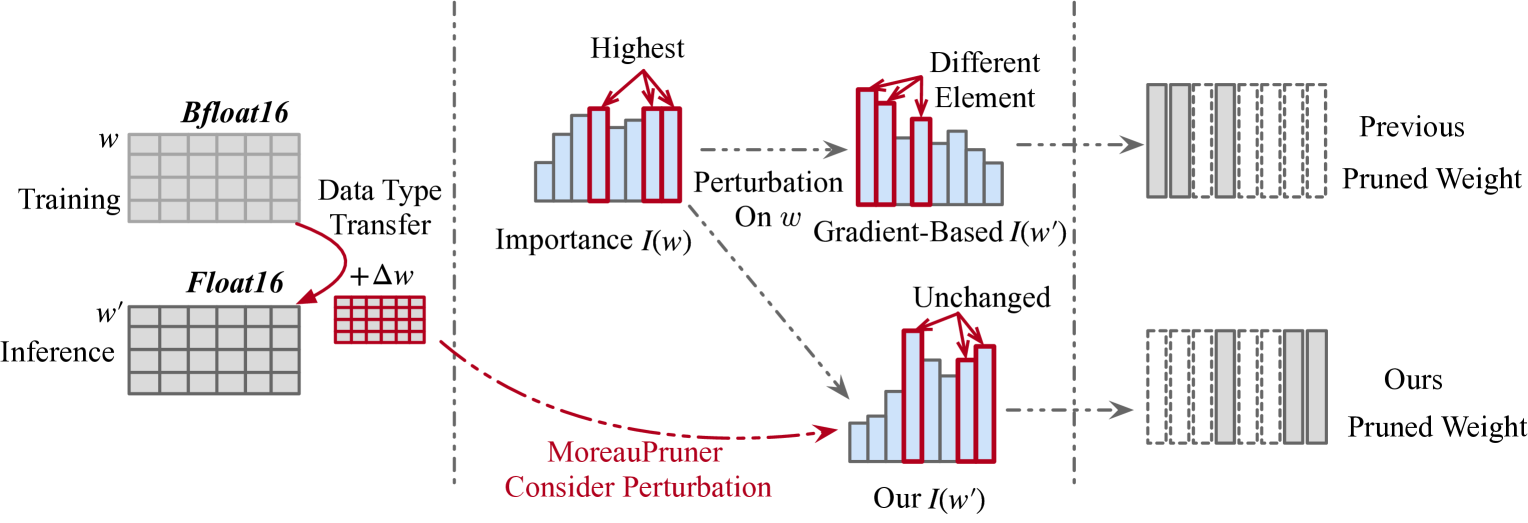

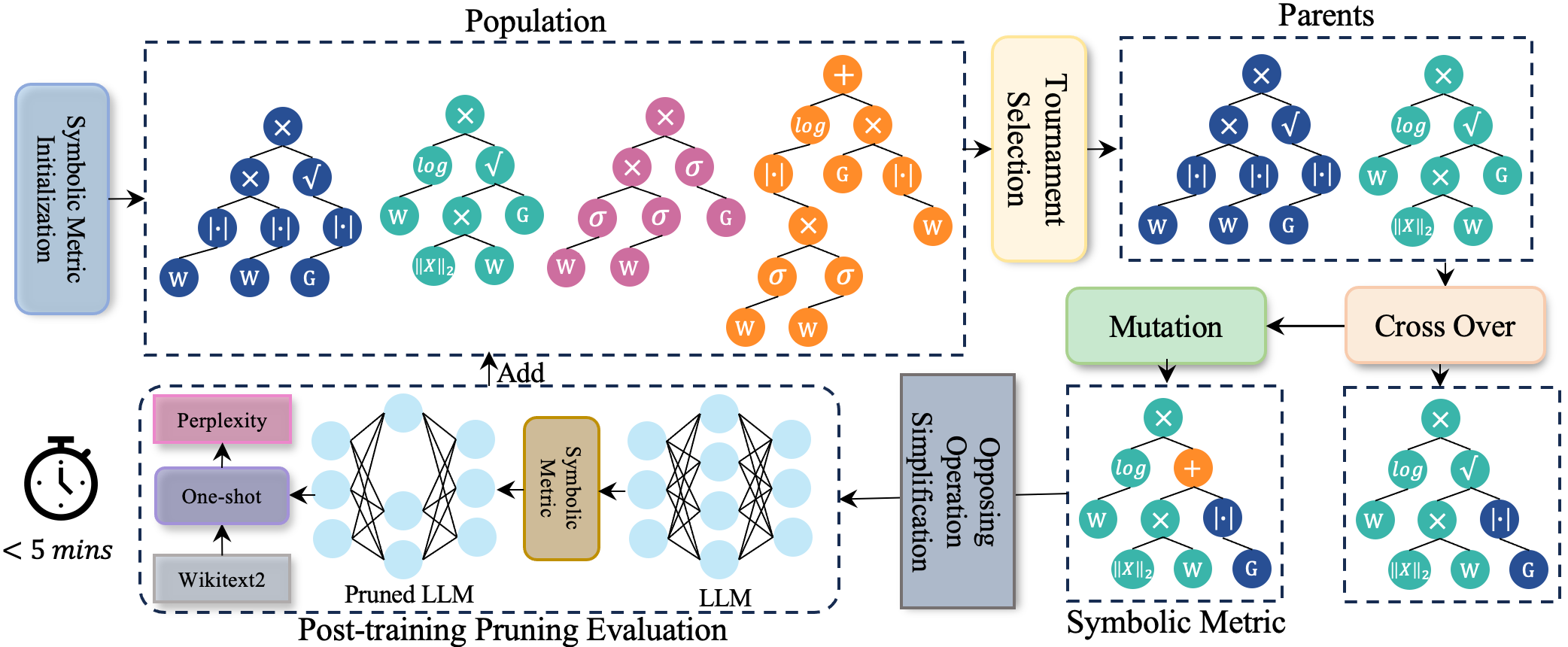


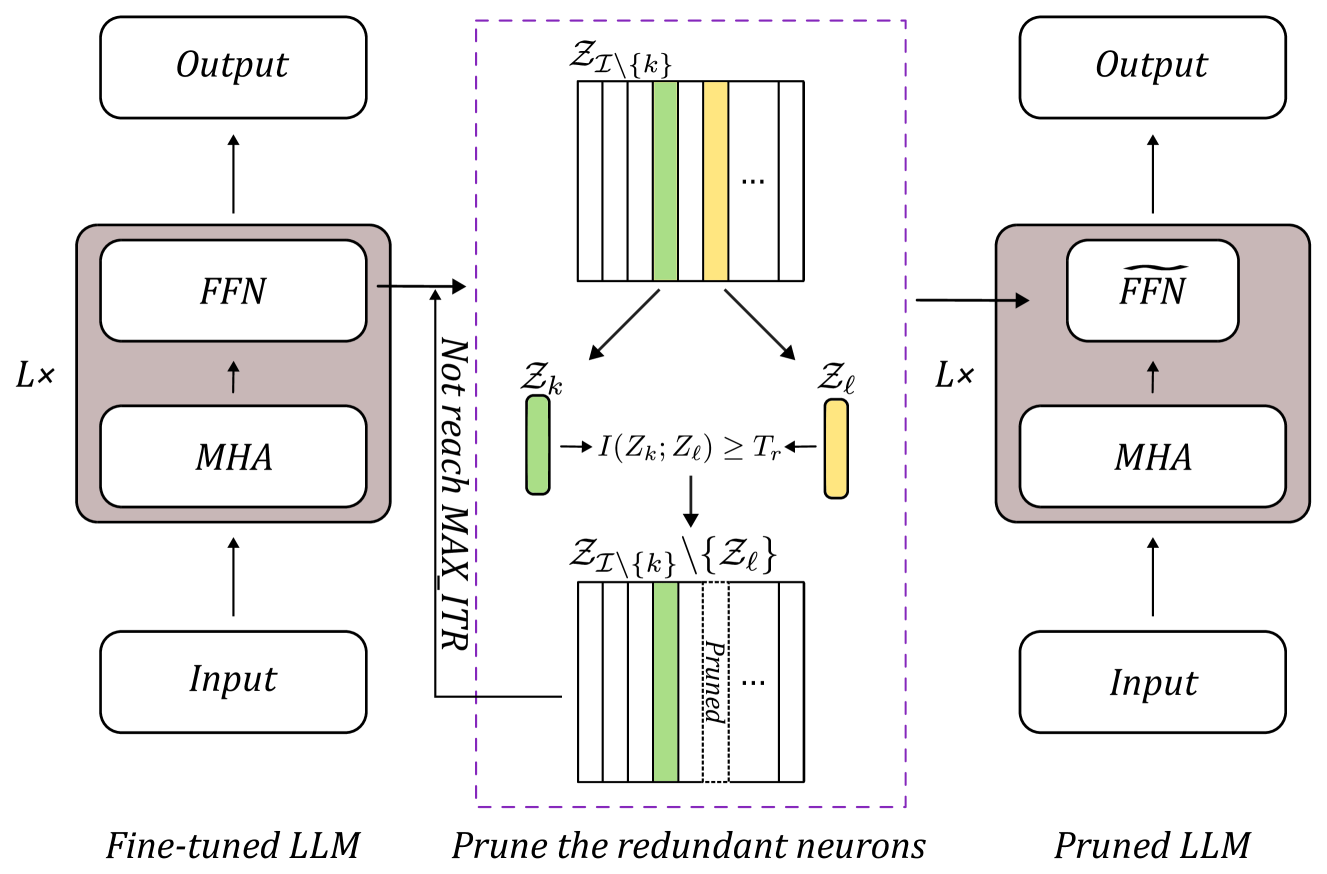
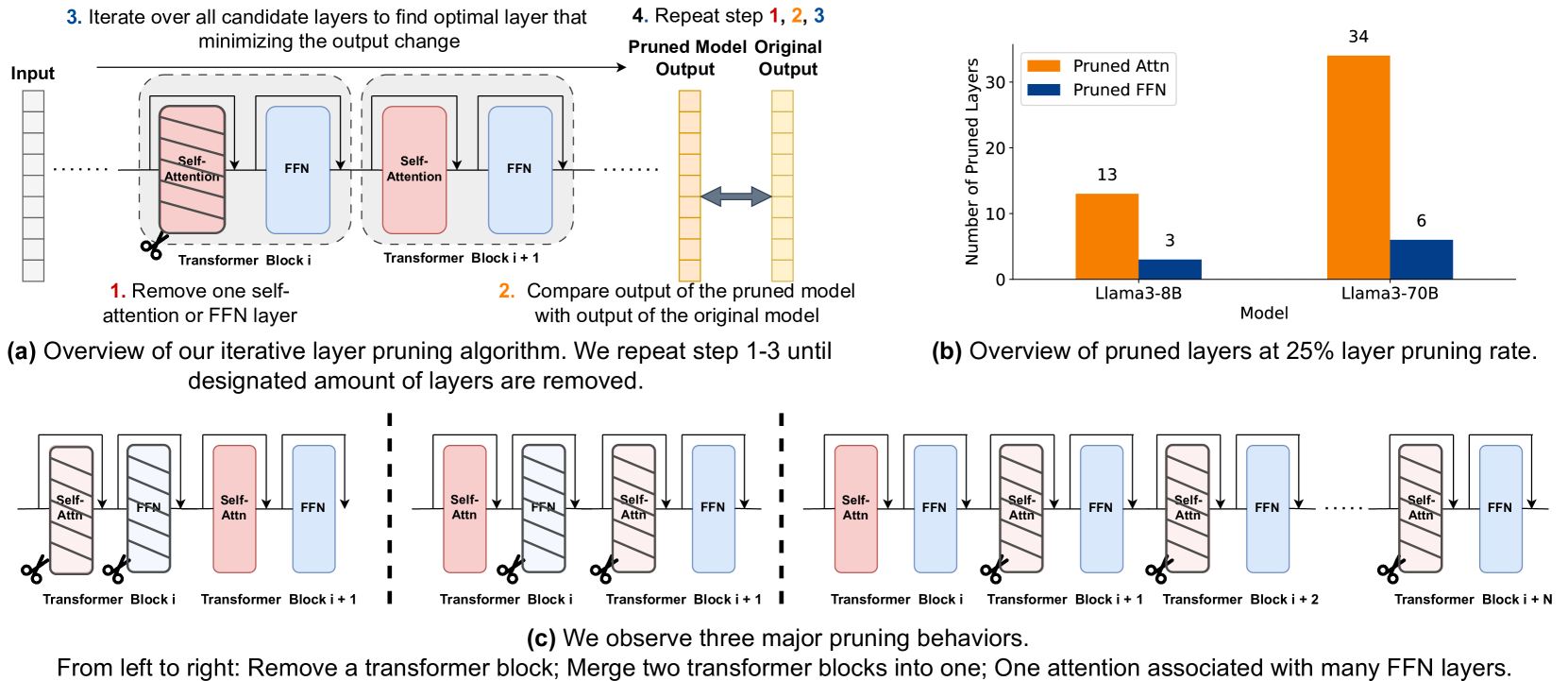




| Title & Authors | Introduction | Links |
|---|---|---|
 T-MAC: CPU Renaissance via Table Lookup for Low-Bit LLM Deployment on Edge Jianyu Wei, Shijie Cao, Ting Cao, Lingxiao Ma, Lei Wang, Yanyong Zhang, Mao Yang |
 |
Github Paper |
 Variable Layer-Wise Quantization: A Simple and Effective Approach to Quantize LLMs Razvan-Gabriel Dumitru, Vikas Yadav, Rishabh Maheshwary, Paul-Ioan Clotan, Sathwik Tejaswi Madhusudhan, Mihai Surdeanu |
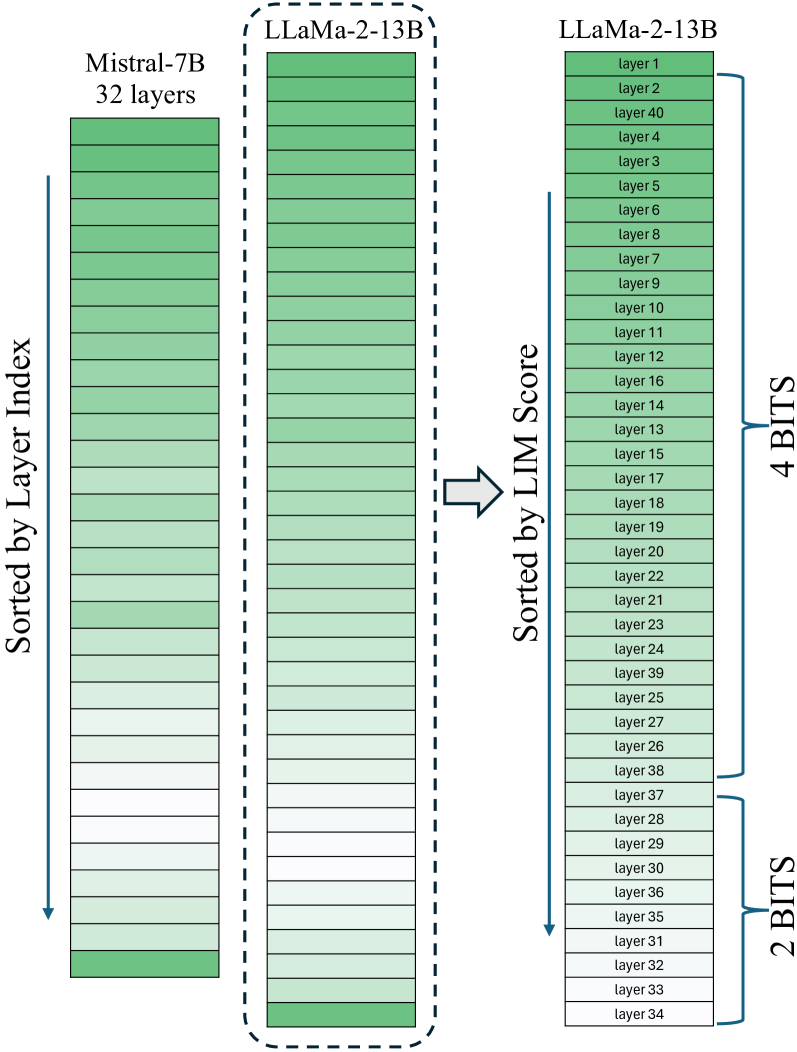 |
Github Paper |
| CDQuant: Accurate Post-training Weight Quantization of Large Pre-trained Models using Greedy Coordinate Descent Pranav Ajit Nair, Arun Sai Suggala |
 |
Paper |
| SDQ: Sparse Decomposed Quantization for LLM Inference Geonhwa Jeong, Po-An Tsai, Stephen W. Keckler, Tushar Krishna |
 |
Paper |
| Prefixing Attention Sinks can Mitigate Activation Outliers for Large Language Model Quantization Seungwoo Son, Wonpyo Park, Woohyun Han, Kyuyeun Kim, Jaeho Lee |
 |
Paper |
| Attention-aware Post-training Quantization without Backpropagation Junhan Kim, Ho-young Kim, Eulrang Cho, Chungman Lee, Joonyoung Kim, Yongkweon Jeon |
 |
Paper |
| Mixture of Scales: Memory-Efficient Token-Adaptive Binarization for Large Language Models Dongwon Jo, Taesu Kim, Yulhwa Kim, Jae-Joon Kim |
 |
Paper |
 QQQ: Quality Quattuor-Bit Quantization for Large Language Models Ying Zhang, Peng Zhang, Mincong Huang, Jingyang Xiang, Yujie Wang, Chao Wang, Yineng Zhang, Lei Yu, Chuan Liu, Wei Lin |
 |
Github Paper |
 ShiftAddLLM: Accelerating Pretrained LLMs via Post-Training Multiplication-Less Reparameterization Haoran You, Yipin Guo, Yichao Fu, Wei Zhou, Huihong Shi, Xiaofan Zhang, Souvik Kundu, Amir Yazdanbakhsh, Yingyan Lin |
 |
Github Paper |
| Low-Rank Quantization-Aware Training for LLMs Yelysei Bondarenko, Riccardo Del Chiaro, Markus Nagel |
 |
Paper |
| LCQ: Low-Rank Codebook based Quantization for Large Language Models Wen-Pu Cai, Wu-Jun Li |
 |
Paper |
| MagR: Weight Magnitude Reduction for Enhancing Post-Training Quantization Aozhong Zhang, Naigang Wang, Yanxia Deng, Xin Li, Zi Yang, Penghang Yin |
 |
Paper |
| Outliers and Calibration Sets have Diminishing Effect on Quantization of Modern LLMs Davide Paglieri, Saurabh Dash, Tim Rocktäschel, Jack Parker-Holder |
Paper | |
 Compressing Large Language Models using Low Rank and Low Precision Decomposition Rajarshi Saha, Naomi Sagan, Varun Srivastava, Andrea J. Goldsmith, Mert Pilanci |
 |
Github Paper |
| I-LLM: Efficient Integer-Only Inference for Fully-Quantized Low-Bit Large Language Models Xing Hu, Yuan Chen, Dawei Yang, Sifan Zhou, Zhihang Yuan, Jiangyong Yu, Chen Xu |
 |
Paper |
 Exploiting LLM Quantization Kazuki Egashira, Mark Vero, Robin Staab, Jingxuan He, Martin Vechev |
 |
Github Paper |
| CLAQ: Pushing the Limits of Low-Bit Post-Training Quantization for LLMs Haoyu Wang, Bei Liu, Hang Shao, Bo Xiao, Ke Zeng, Guanglu Wan, Yanmin Qian |
 |
Paper |
| SpinQuant -- LLM quantization with learned rotations Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, Tijmen Blankevoort |
 |
Paper |
 SliM-LLM: Salience-Driven Mixed-Precision Quantization for Large Language Models Wei Huang, Haotong Qin, Yangdong Liu, Yawei Li, Xianglong Liu, Luca Benini, Michele Magno, Xiaojuan Qi |
 |
Github Paper |
 PV-Tuning: Beyond Straight-Through Estimation for Extreme LLM Compression Vladimir Malinovskii, Denis Mazur, Ivan Ilin, Denis Kuznedelev, Konstantin Burlachenko, Kai Yi, Dan Alistarh, Peter Richtarik |
 |
Github Paper |
| Integer Scale: A Free Lunch for Faster Fine-grained Quantization of LLMs Qingyuan Li, Ran Meng, Yiduo Li, Bo Zhang, Yifan Lu, Yerui Sun, Lin Ma, Yuchen Xie |
 |
Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
| Sparser is Faster and Less is More: Efficient Sparse Attention for Long-Range Transformers Chao Lou, Zixia Jia, Zilong Zheng, Kewei Tu |
 |
Paper |
 EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees Yuhui Li, Fangyun Wei, Chao Zhang, Hongyang Zhang |
 |
Github Paper |
| Interpreting Attention Layer Outputs with Sparse Autoencoders Connor Kissane, Robert Krzyzanowski, Joseph Isaac Bloom, Arthur Conmy, Neel Nanda |
 |
Paper |
| Near-Lossless Acceleration of Long Context LLM Inference with Adaptive Structured Sparse Attention Qianchao Zhu, Jiangfei Duan, Chang Chen, Siran Liu, Xiuhong Li, Guanyu Feng, Xin Lv, Huanqi Cao, Xiao Chuanfu, Xingcheng Zhang, Dahua Lin, Chao Yang |
 |
Paper |
 MoA: Mixture of Sparse Attention for Automatic Large Language Model Compression Tianyu Fu, Haofeng Huang, Xuefei Ning, Genghan Zhang, Boju Chen et al |
 |
Github Paper |
| Optimized Speculative Sampling for GPU Hardware Accelerators Dominik Wagner, Seanie Lee, Ilja Baumann, Philipp Seeberger, Korbinian Riedhammer, Tobias Bocklet |
 |
Paper |
| HiP Attention: Sparse Sub-Quadratic Attention with Hierarchical Attention Pruning Heejun Lee, Geon Park, Youngwan Lee, Jina Kim, Wonyoung Jeong, Myeongjae Jeon, Sung Ju Hwang |
 |
Paper |
 When Linear Attention Meets Autoregressive Decoding: Towards More Effective and Efficient Linearized Large Language Models Haoran You, Yichao Fu, Zheng Wang, Amir Yazdanbakhsh, Yingyan (Celine)Lin |
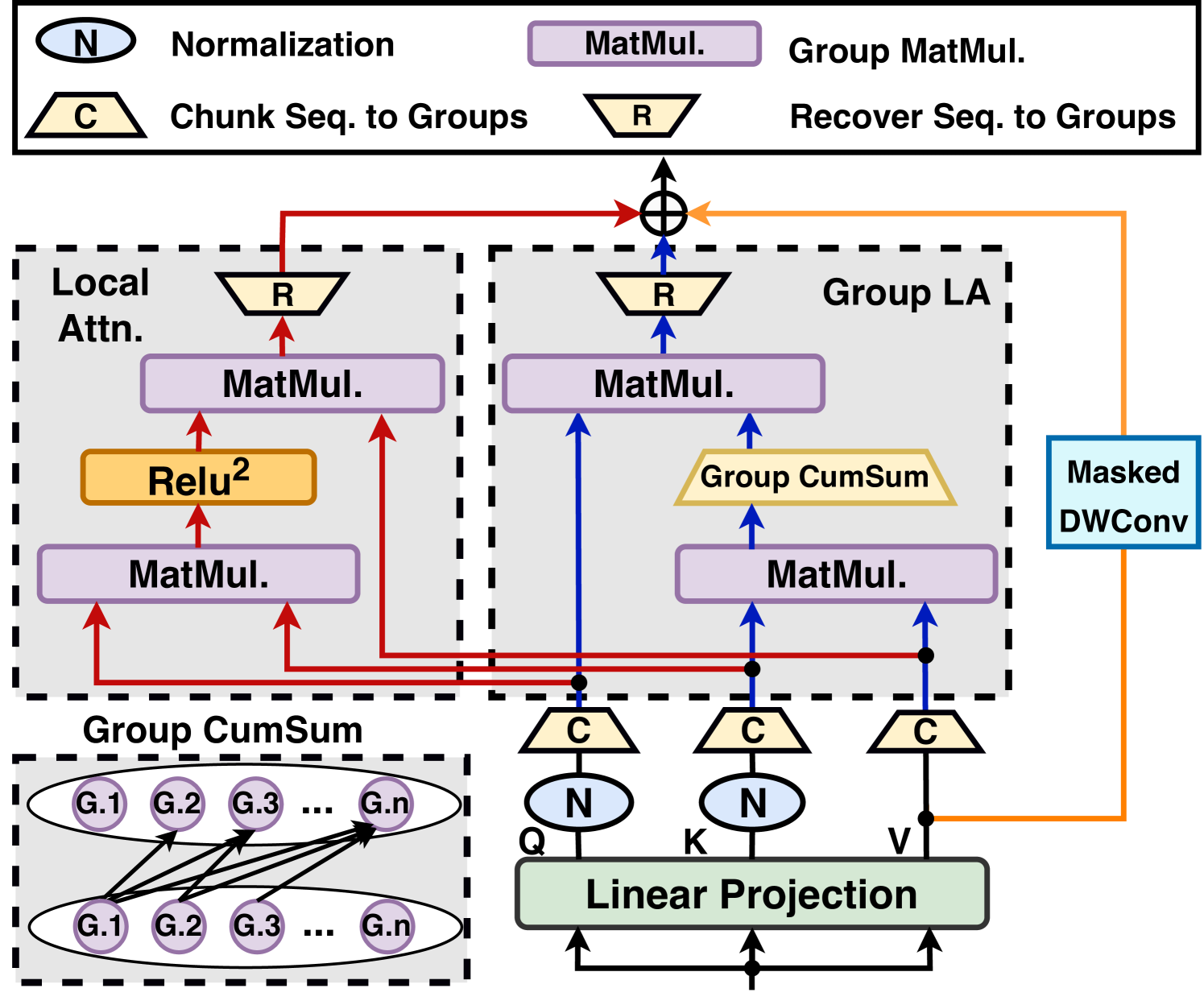 |
Github Paper |
 QuickLLaMA: Query-aware Inference Acceleration for Large Language Models Jingyao Li, Han Shi, Xin Jiang, Zhenguo Li, Hong Xu, Jiaya Jia |
 |
Github Paper |
Speculative Decoding via Early-exiting for Faster LLM Inference with Thompson Sampling Control Mechanism Jiahao Liu, Qifan Wang, Jingang Wang, Xunliang Cai |
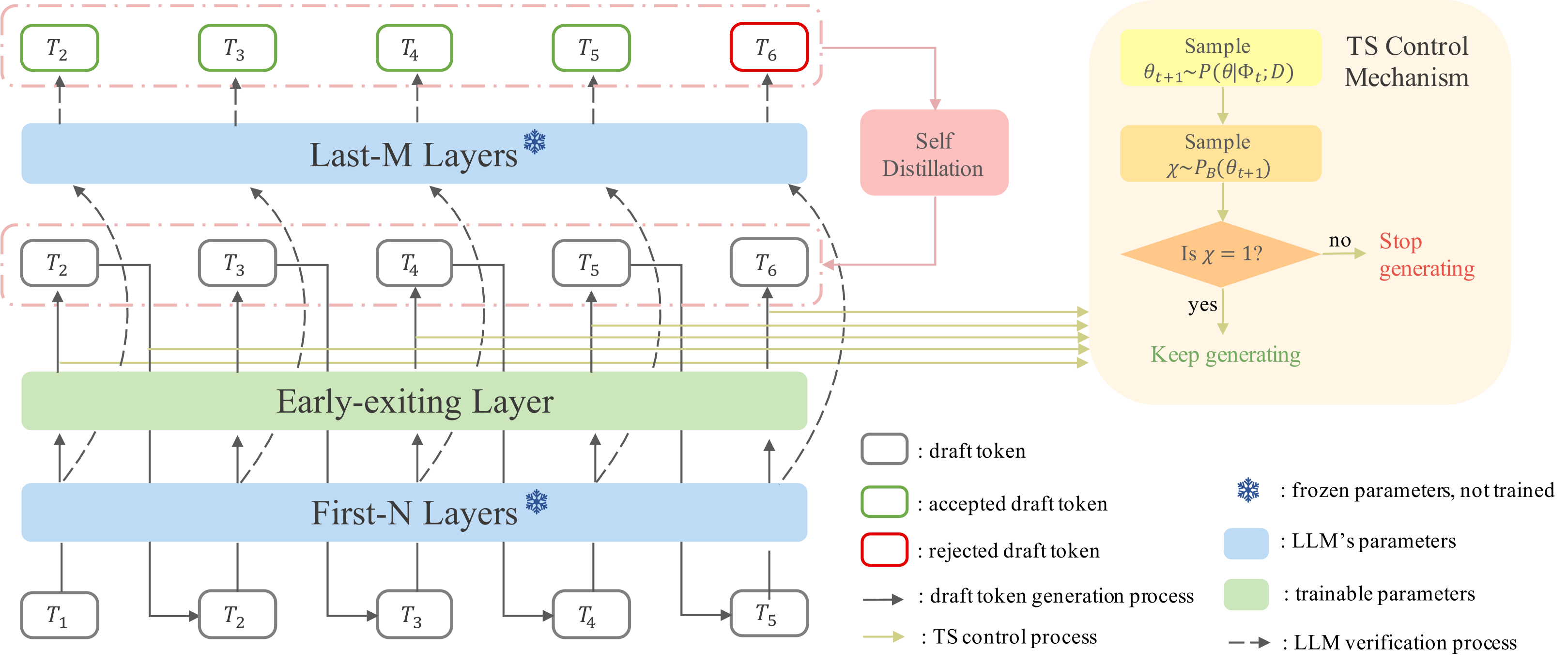 |
Paper |
| Faster Cascades via Speculative Decoding Harikrishna Narasimhan, Wittawat Jitkrittum, Ankit Singh Rawat, Seungyeon Kim, Neha Gupta, Aditya Krishna Menon, Sanjiv Kumar |
 |
Paper |
 Hardware-Aware Parallel Prompt Decoding for Memory-Efficient Acceleration of LLM Inference Hao (Mark)Chen, Wayne Luk, Ka Fai Cedric Yiu, Rui Li, Konstantin Mishchenko, Stylianos I. Venieris, Hongxiang Fan |
 |
Github Paper |




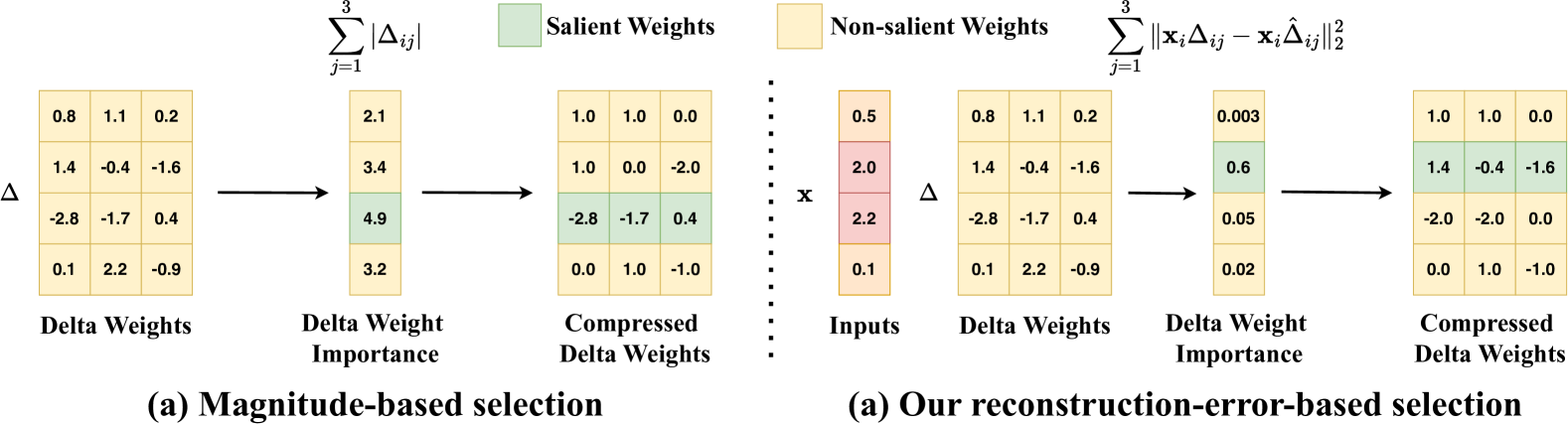





| Title & Authors | Introduction | Links |
|---|---|---|
Block Transformer: Global-to-Local Language Modeling for Fast Inference Namgyu Ho, Sangmin Bae, Taehyeon Kim, Hyunjik Jo, Yireun Kim, Tal Schuster, Adam Fisch, James Thorne, Se-Young Yun |
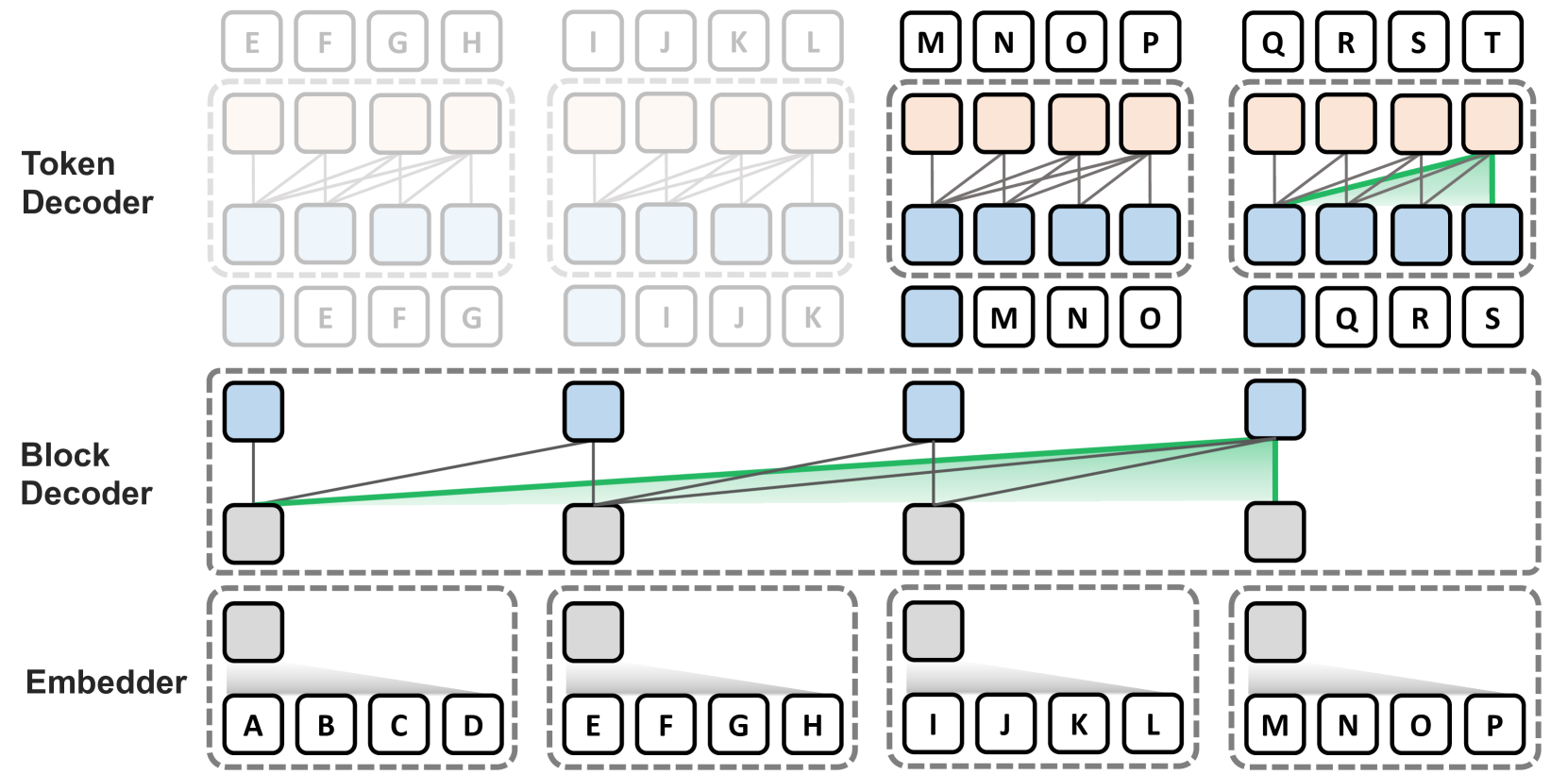 |
Github Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
 KV Cache Compression, But What Must We Give in Return? A Comprehensive Benchmark of Long Context Capable Approaches Jiayi Yuan, Hongyi Liu, Shaochen (Henry)Zhong, Yu-Neng Chuang, Songchen Li et al |
 |
Github Paper |
 MLKV: Multi-Layer Key-Value Heads for Memory Efficient Transformer Decoding Zayd Muhammad Kawakibi Zuhri, Muhammad Farid Adilazuarda, Ayu Purwarianti, Alham Fikri Aji |
 |
Github Paper |
| Loki: Low-Rank Keys for Efficient Sparse Attention Prajwal Singhania, Siddharth Singh, Shwai He, Soheil Feizi, Abhinav Bhatele |
 |
Paper |
 QJL: 1-Bit Quantized JL Transform for KV Cache Quantization with Zero Overhead Amir Zandieh, Majid Daliri, Insu Han |
 |
Github Paper |
| ZipCache: Accurate and Efficient KV Cache Quantization with Salient Token Identification Yefei He, Luoming Zhang, Weijia Wu, Jing Liu, Hong Zhou, Bohan Zhuang |
 |
Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
| Brevity is the soul of wit: Pruning long files for code generation Aaditya K. Singh, Yu Yang, Kushal Tirumala, Mostafa Elhoushi, Ari S. Morcos |
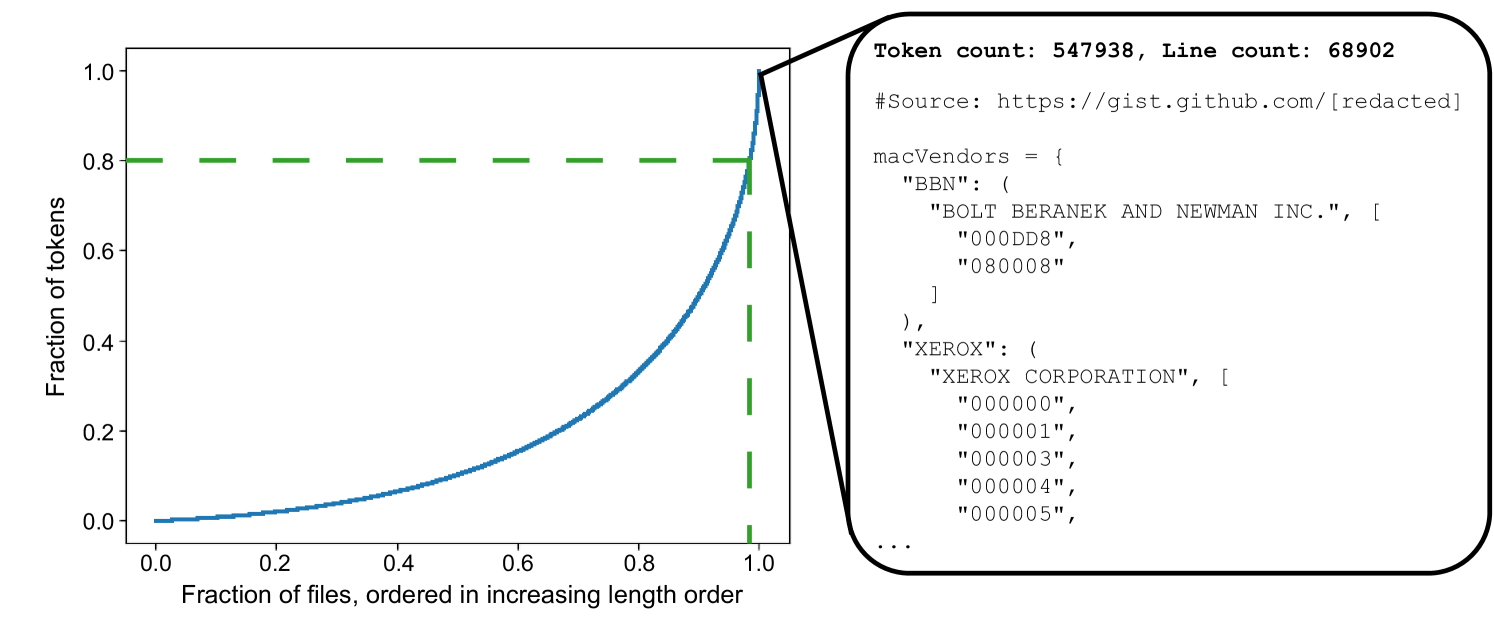 |
Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
| MCNC: Manifold Constrained Network Compression Chayne Thrash, Ali Abbasi, Parsa Nooralinejad, Soroush Abbasi Koohpayegani, Reed Andreas, Hamed Pirsiavash, Soheil Kolouri |
 |
Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
| Preble: Efficient Distributed Prompt Scheduling for LLM Serving Vikranth Srivatsa, Zijian He, Reyna Abhyankar, Dongming Li, Yiying Zhang |
 |
Paper |
 EDGE-LLM: Enabling Efficient Large Language Model Adaptation on Edge Devices via Layerwise Unified Compression and Adaptive Layer Tuning and Voting Zhongzhi Yu, Zheng Wang, Yuhan Li, Haoran You, Ruijie Gao, Xiaoya Zhou, Sreenidhi Reedy Bommu, Yang Katie Zhao, Yingyan Celine Lin |
 |
Github Paper |
Tender: Accelerating Large Language Models via Tensor Decomposition and Runtime Requantization Jungi Lee, Wonbeom Lee, Jaewoong Sim |
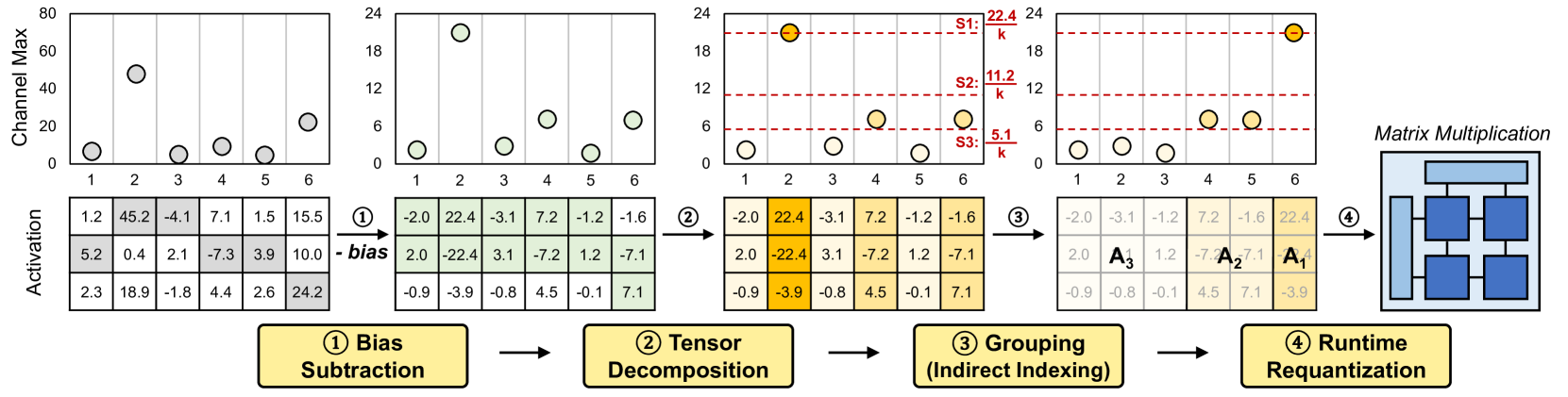 |
Paper |
| PowerInfer-2: Fast Large Language Model Inference on a Smartphone Zhenliang Xue, Yixin Song, Zeyu Mi, Le Chen, Yubin Xia, Haibo Chen |
 |
Paper |
Parrot: Efficient Serving of LLM-based Applications with Semantic Variable Chaofan Lin, Zhenhua Han, Chengruidong Zhang, Yuqing Yang, Fan Yang, Chen Chen, Lili Qiu |
 |
Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
 Increasing Model Capacity for Free: A Simple Strategy for Parameter Efficient Fine-tuning Haobo Song, Hao Zhao, Soumajit Majumder, Tao Lin |
 |
Github Paper |
| Compress then Serve: Serving Thousands of LoRA Adapters with Little Overhead Rickard Brüel-Gabrielsson, Jiacheng Zhu, Onkar Bhardwaj, Leshem Choshen et al |
 |
Paper |
| BlockLLM: Memory-Efficient Adaptation of LLMs by Selecting and Optimizing the Right Coordinate Blocks Amrutha Varshini Ramesh, Vignesh Ganapathiraman, Issam H. Laradji, Mark Schmidt |
 |
Paper |
 Light-PEFT: Lightening Parameter-Efficient Fine-Tuning via Early Pruning Naibin Gu, Peng Fu, Xiyu Liu, Bowen Shen, Zheng Lin, Weiping Wang |
 |
Github Paper |
| Zeroth-Order Fine-Tuning of LLMs with Extreme Sparsity Wentao Guo, Jikai Long, Yimeng Zeng, Zirui Liu, Xinyu Yang et al |
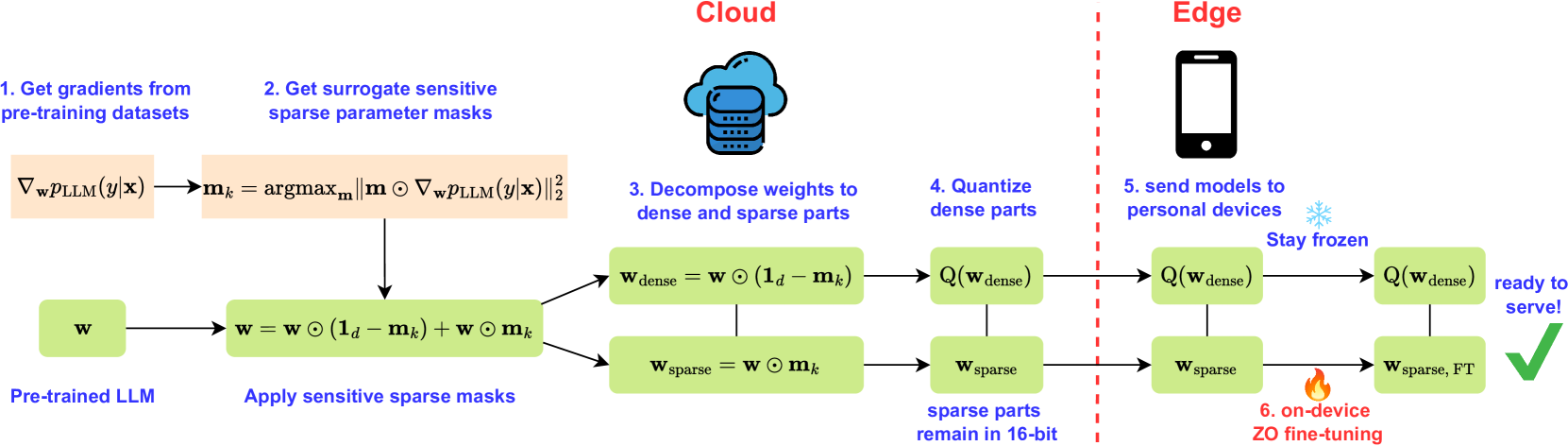 |
Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
| Memory Is All You Need: An Overview of Compute-in-Memory Architectures for Accelerating Large Language Model Inference Christopher Wolters, Xiaoxuan Yang, Ulf Schlichtmann, Toyotaro Suzumura |
 |
Paper |
If you'd like to include your paper, or need to update any details such as conference information or code URLs, please feel free to submit a pull request. You can generate the required markdown format for each paper by filling in the information in generate_item.py and execute python generate_item.py. We warmly appreciate your contributions to this list. Alternatively, you can email me with the links to your paper and code, and I would add your paper to the list at my earliest convenience.