SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot
Elias Frantar, Dan Alistarh |
 |
Github paper |
  
LLM-Pruner: On the Structural Pruning of Large Language Models
Xinyin Ma, Gongfan Fang, Xinchao Wang |
 |
Github paper |

The Emergence of Essential Sparsity in Large Pre-trained Models: The Weights that Matter
Ajay Jaiswal, Shiwei Liu, Tianlong Chen, Zhangyang Wang |
 |
Github
Paper |
 
Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity
Haojun Xia, Zhen Zheng, Yuchao Li, Donglin Zhuang, Zhongzhu Zhou, Xiafei Qiu, Yong Li, Wei Lin, Shuaiwen Leon Song |
 |
Github
Paper |
 
A Simple and Effective Pruning Approach for Large Language Models
Mingjie Sun, Zhuang Liu, Anna Bair, J. Zico Kolter |
 |
Github
Paper |

Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning
Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, Danqi Chen |
 |
Github
Paper |

Plug-and-Play: An Efficient Post-training Pruning Method for Large Language Models
Yingtao Zhang, Haoli Bai, Haokun Lin, Jialin Zhao, Lu Hou, Carlo Vittorio Cannistraci |
 |
Github
Paper |
 
Fluctuation-based Adaptive Structured Pruning for Large Language Models
Yongqi An, Xu Zhao, Tao Yu, Ming Tang, Jinqiao Wang |
 |
Github
Paper |
 
NASH: A Simple Unified Framework of Structured Pruning for Accelerating Encoder-Decoder Language Models
Jongwoo Ko, Seungjoon Park, Yujin Kim, Sumyeong Ahn, Du-Seong Chang, Euijai Ahn, Se-Young Yun |
 |
Github
Paper |
LoRAPrune: Pruning Meets Low-Rank Parameter-Efficient Fine-Tuning
Mingyang Zhang, Hao Chen, Chunhua Shen, Zhen Yang, Linlin Ou, Xinyi Yu, Bohan Zhuang |
 |
Paper |
Pruning Large Language Models via Accuracy Predictor
Yupeng Ji, Yibo Cao, Jiucai Liu |
 |
Paper |

Compressing LLMs: The Truth is Rarely Pure and Never Simple
Ajay Jaiswal, Zhe Gan, Xianzhi Du, Bowen Zhang, Zhangyang Wang, Yinfei Yang |
 |
Paper |

Junk DNA Hypothesis: A Task-Centric Angle of LLM Pre-trained Weights through Sparsity
Lu Yin, Shiwei Liu, Ajay Jaiswal, Souvik Kundu, Zhangyang Wang |
 |
Github
Paper |

Outlier Weighed Layerwise Sparsity (OWL): A Missing Secret Sauce for Pruning LLMs to High Sparsity
Lu Yin, You Wu, Zhenyu Zhang, Cheng-Yu Hsieh, Yaqing Wang, Yiling Jia, Mykola Pechenizkiy, Yi Liang, Zhangyang Wang, Shiwei Liu |
 |
Github
Paper |
Compresso: Structured Pruning with Collaborative Prompting Learns Compact Large Language Models
Song Guo, Jiahang Xu, Li Lyna Zhang, Mao Yang |
 |
Github
Paper |

Sparse Finetuning for Inference Acceleration of Large Language Models
Eldar Kurtic, Denis Kuznedelev, Elias Frantar, Michael Goin, Dan Alistarh |
 |
Github
Paper |

ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models
Iman Mirzadeh, Keivan Alizadeh, Sachin Mehta, Carlo C Del Mundo, Oncel Tuzel, Golnoosh Samei, Mohammad Rastegari, Mehrdad Farajtabar |
 |
Paper |
The Cost of Down-Scaling Language Models: Fact Recall Deteriorates before In-Context Learning
Tian Jin, Nolan Clement, Xin Dong, Vaishnavh Nagarajan, Michael Carbin, Jonathan Ragan-Kelley, Gintare Karolina Dziugaite |
 |
Paper |
 
One-Shot Sensitivity-Aware Mixed Sparsity Pruning for Large Language Models
Hang Shao, Bei Liu, Bo Xiao, Ke Zeng, Guanglu Wan, Yanmin Qian |
 |
Github
Paper |

LoRAShear: Efficient Large Language Model Structured Pruning and Knowledge Recovery
Tianyi Chen, Tianyu Ding, Badal Yadav, Ilya Zharkov, Luming Liang |
 |
Github
Paper |
 
Divergent Token Metrics: Measuring degradation to prune away LLM components -- and optimize quantization
Björn Deiseroth, Max Meuer, Nikolas Gritsch, Constantin Eichenberg, Patrick Schramowski, Matthias Aßenmacher, Kristian Kersting |
 |
Github
Paper |

Beyond Size: How Gradients Shape Pruning Decisions in Large Language Models
Rocktim Jyoti Das, Liqun Ma, Zhiqiang Shen |
 |
Github
Paper |

Dynamic Sparse No Training: Training-Free Fine-tuning for Sparse LLMs
Yuxin Zhang, Lirui Zhao, Mingbao Lin, Yunyun Sun, Yiwu Yao, Xingjia Han, Jared Tanner, Shiwei Liu, Rongrong Ji |
 |
Github
Paper |
 E-Sparse: Boosting the Large Language Model Inference through Entropy-based N:M Sparsity E-Sparse: Boosting the Large Language Model Inference through Entropy-based N:M Sparsity
Yun Li, Lin Niu, Xipeng Zhang, Kai Liu, Jianchen Zhu, Zhanhui Kang |
 |
Paper |

PERP: Rethinking the Prune-Retrain Paradigm in the Era of LLMs
Max Zimmer, Megi Andoni, Christoph Spiegel, Sebastian Pokutta |
 |
Github
Paper |

Fast and Optimal Weight Update for Pruned Large Language Models
Vladimír Boža |
 |
Github
Paper |

Pruning for Protection: Increasing Jailbreak Resistance in Aligned LLMs Without Fine-Tuning
Adib Hasan, Ileana Rugina, Alex Wang |
 |
Github
Paper |

SliceGPT: Compress Large Language Models by Deleting Rows and Columns
Saleh Ashkboos, Maximilian L. Croci, Marcelo Gennari do Nascimento, Torsten Hoefler, James Hensman |
 |
Github
Paper |
APT: Adaptive Pruning and Tuning Pretrained Language Models for Efficient Training and Inference
Bowen Zhao, Hannaneh Hajishirzi, Qingqing Cao |
 |
Paper |
ReLU2 Wins: Discovering Efficient Activation Functions for Sparse LLMs
Zhengyan Zhang, Yixin Song, Guanghui Yu, Xu Han, Yankai Lin, Chaojun Xiao, Chenyang Song, Zhiyuan Liu, Zeyu Mi, Maosong Sun |
 |
Paper |

Everybody Prune Now: Structured Pruning of LLMs with only Forward Passes
Lucio Dery, Steven Kolawole, Jean-Francois Kagey, Virginia Smith, Graham Neubig, Ameet Talwalkar |
 |
Github
Paper |

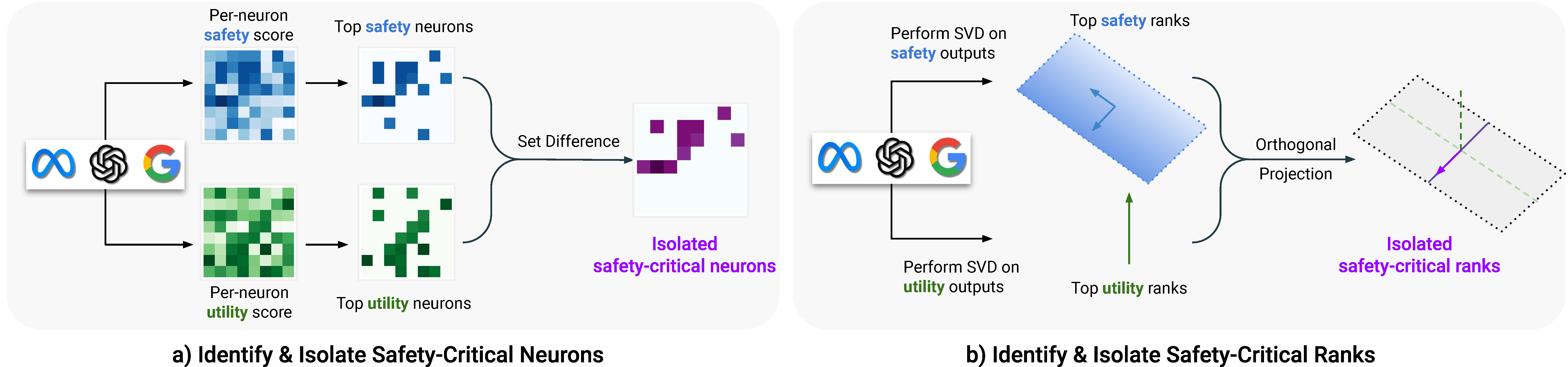
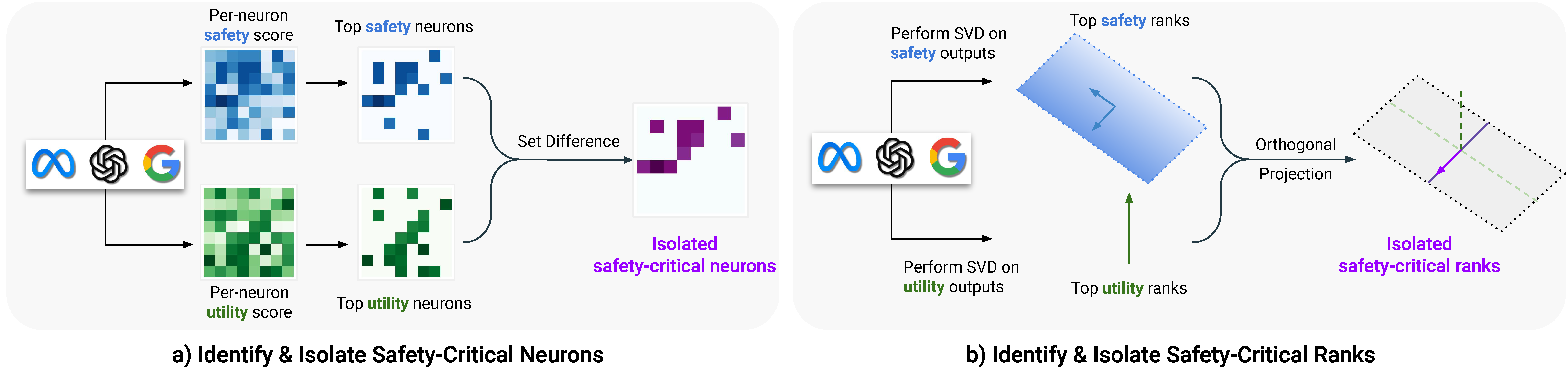
Assessing the Brittleness of Safety Alignment via Pruning and Low-Rank Modifications
Boyi Wei, Kaixuan Huang, Yangsibo Huang, Tinghao Xie, Xiangyu Qi, Mengzhou Xia et al |
 |
Github
Paper
Project |
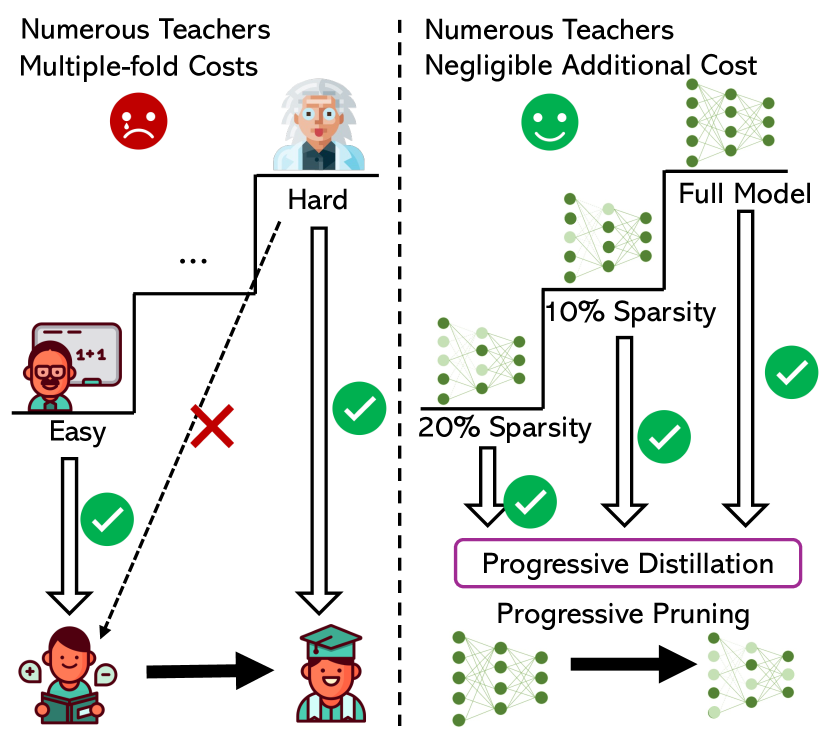
NutePrune: Efficient Progressive Pruning with Numerous Teachers for Large Language Models
Shengrui Li, Xueting Han, Jing Bai |
 |
Paper |
Learn To be Efficient: Build Structured Sparsity in Large Language Models
Haizhong Zheng, Xiaoyan Bai, Beidi Chen, Fan Lai, Atul Prakash |
 |
Paper |
 
Shortened LLaMA: A Simple Depth Pruning for Large Language Models
Bo-Kyeong Kim, Geonmin Kim, Tae-Ho Kim, Thibault Castells, Shinkook Choi, Junho Shin, Hyoung-Kyu Song |
 |
Github
Paper |

SLEB: Streamlining LLMs through Redundancy Verification and Elimination of Transformer Blocks
Jiwon Song, Kyungseok Oh, Taesu Kim, Hyungjun Kim, Yulhwa Kim, Jae-Joon Kim |
 |
Github
Paper |
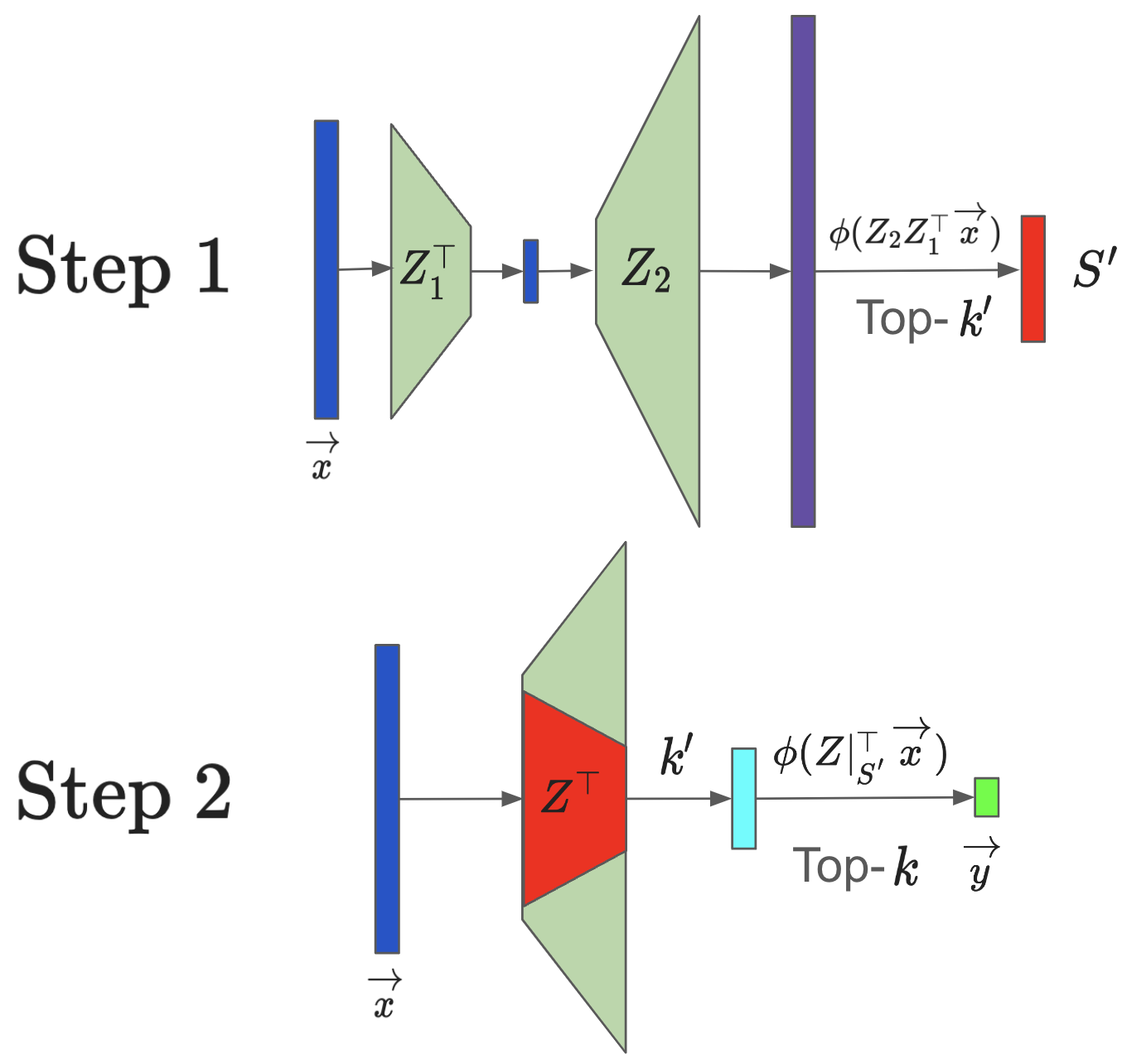
HiRE: High Recall Approximate Top-k Estimation for Efficient LLM Inference
Yashas Samaga B L, Varun Yerram, Chong You, Srinadh Bhojanapalli, Sanjiv Kumar, Prateek Jain, Praneeth Netrapalli |
 |
Paper |
LaCo: Large Language Model Pruning via Layer Collapse
Yifei Yang, Zouying Cao, Hai Zhao |
 |
Paper |

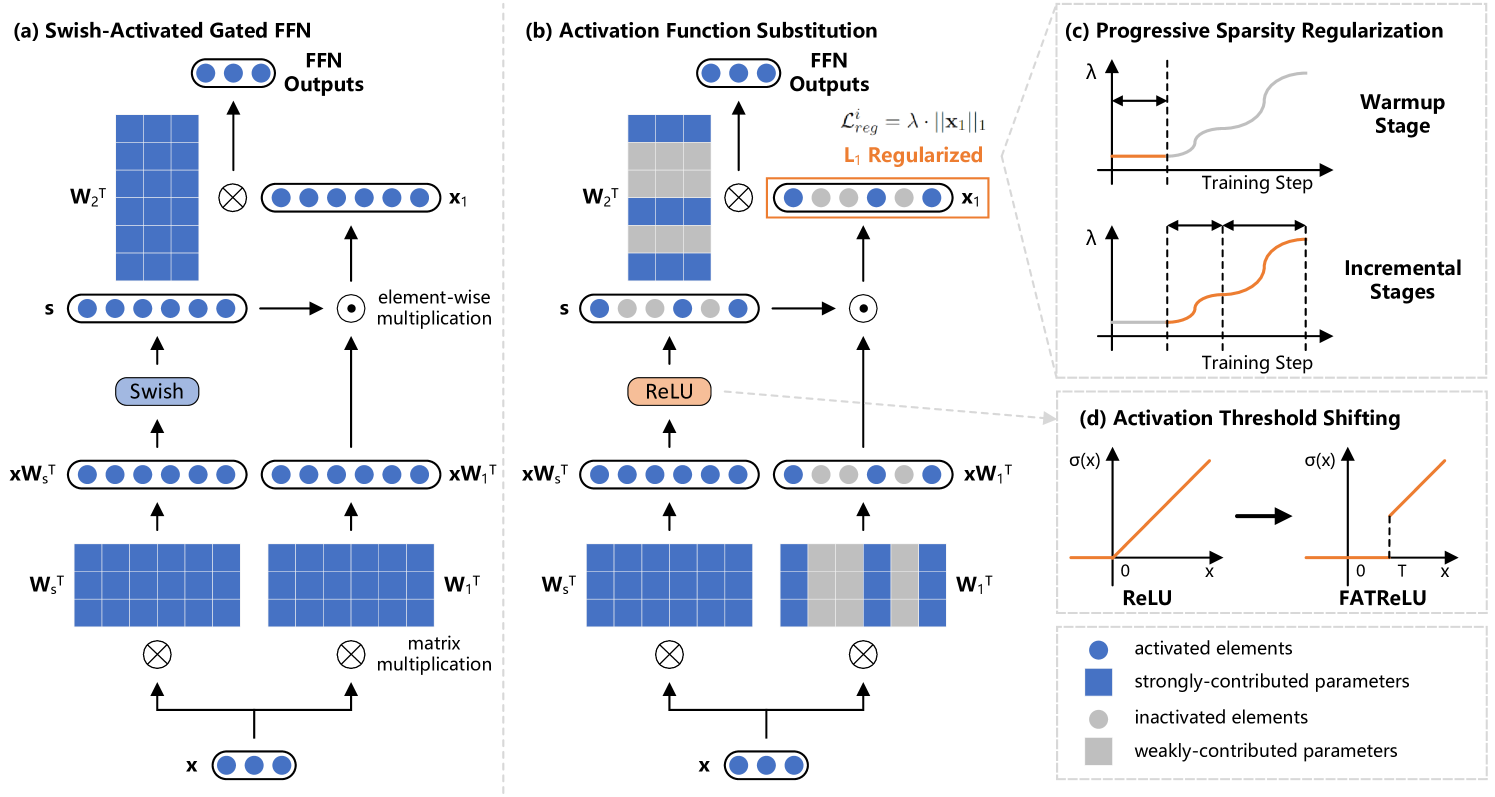
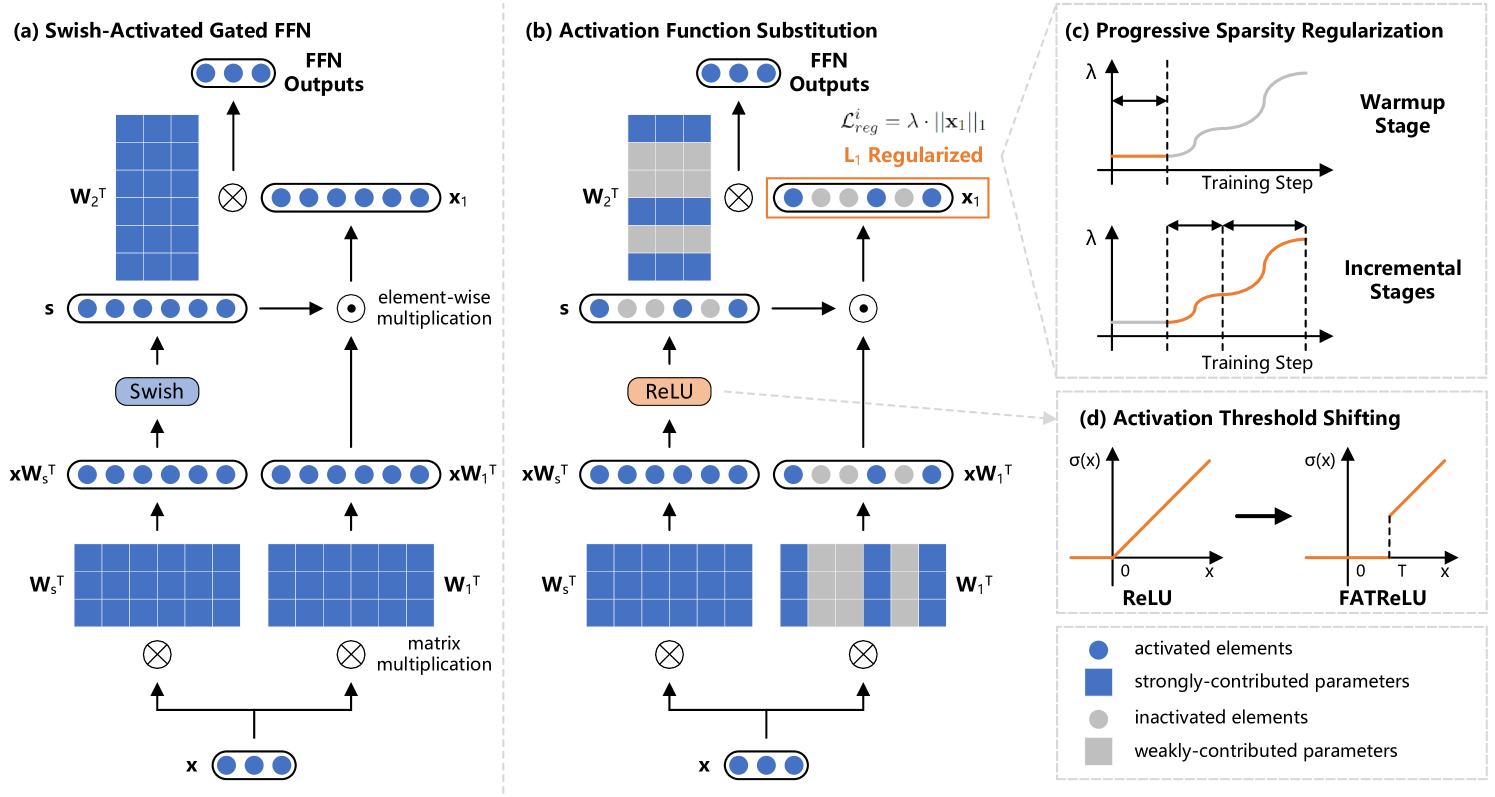
ProSparse: Introducing and Enhancing Intrinsic Activation Sparsity within Large Language Models
Chenyang Song, Xu Han, Zhengyan Zhang, Shengding Hu, Xiyu Shi, Kuai Li et al |
 |
Github
Paper
[Model-7B] [Model-13B] |

EBFT: Effective and Block-Wise Fine-Tuning for Sparse LLMs
Song Guo, Fan Wu, Lei Zhang, Xiawu Zheng, Shengchuan Zhang, Fei Chao, Yiyu Shi, Rongrong Ji |
 |
Github
Paper |

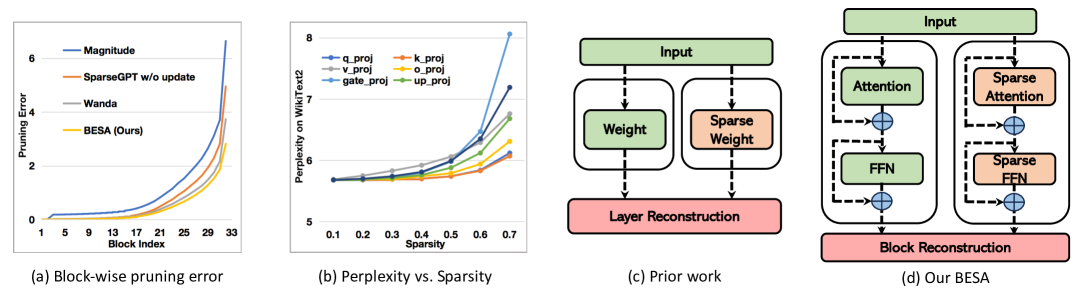
BESA: Pruning Large Language Models with Blockwise Parameter-Efficient Sparsity Allocation
Peng Xu, Wenqi Shao, Mengzhao Chen, Shitao Tang, Kaipeng Zhang, Peng Gao, Fengwei An, Yu Qiao, Ping Luo |
 |
Github
Paper |
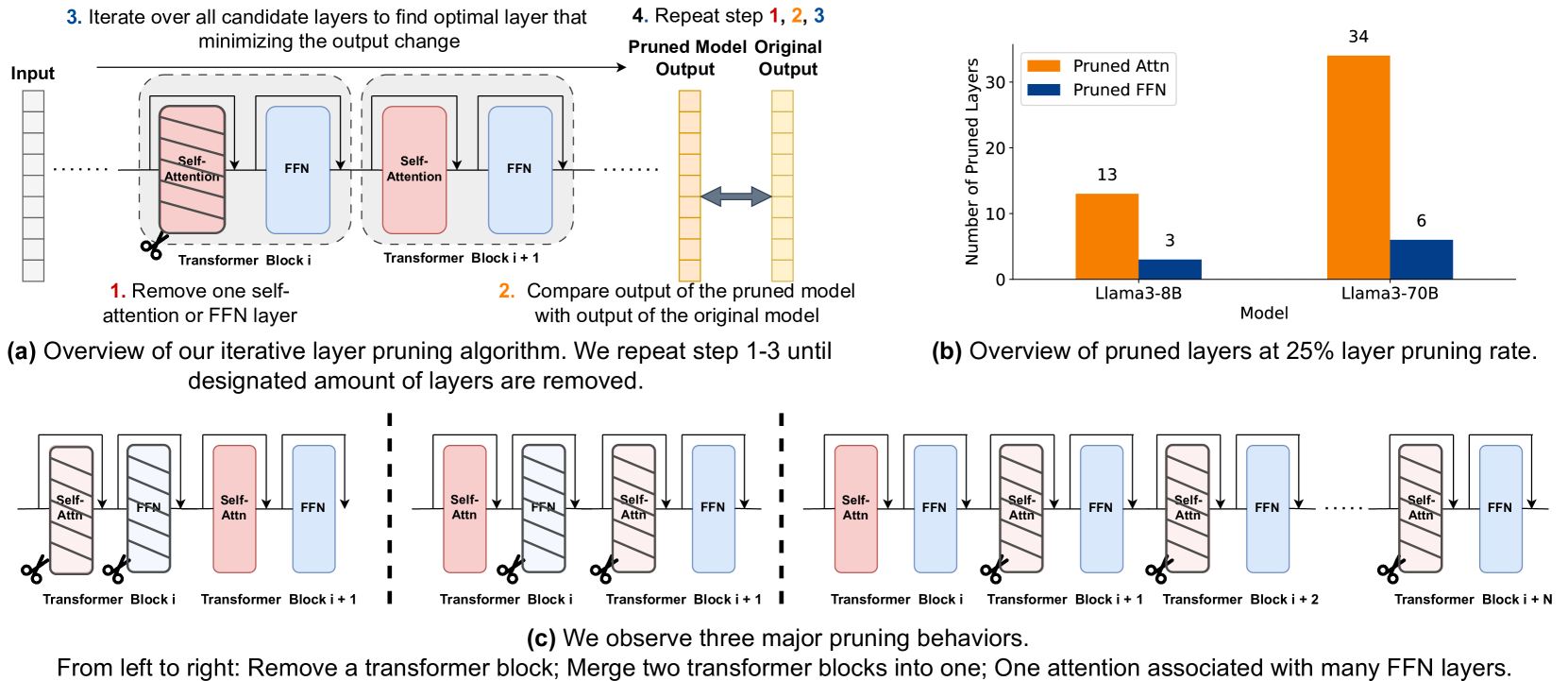
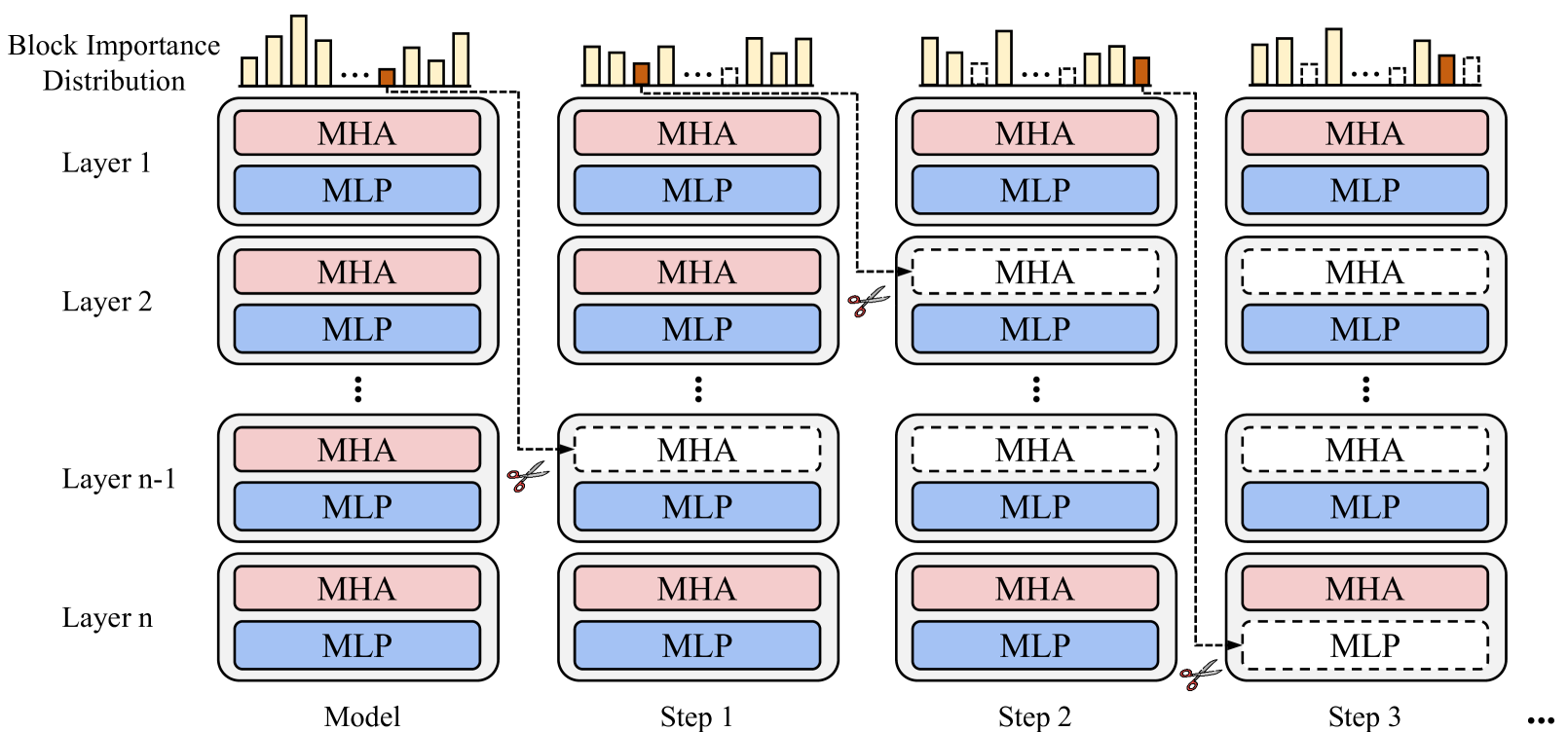
ShortGPT: Layers in Large Language Models are More Redundant Than You Expect
Xin Men, Mingyu Xu, Qingyu Zhang, Bingning Wang, Hongyu Lin, Yaojie Lu, Xianpei Han, Weipeng Chen |
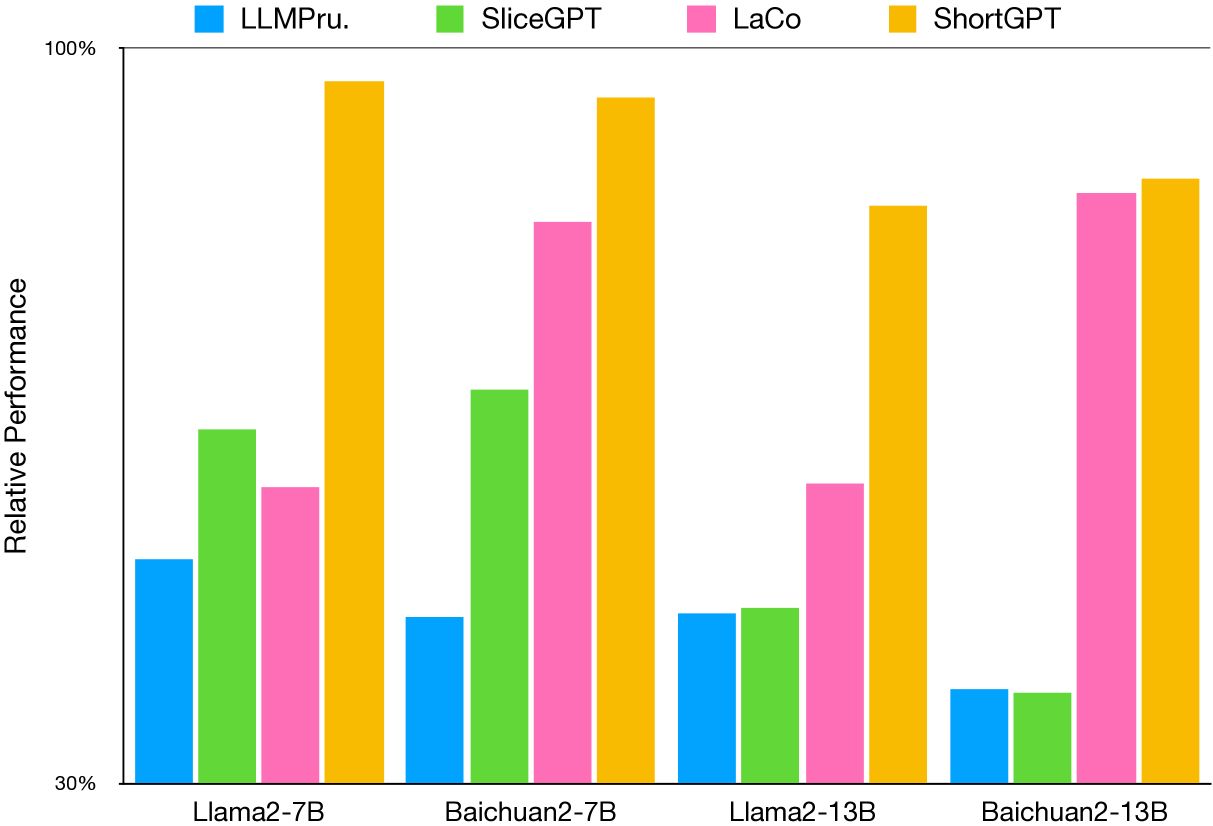 |
Paper |
Efficient Pruning of Large Language Model with Adaptive Estimation Fusion
Jun Liu, Chao Wu, Changdi Yang, Hao Tang, Haoye Dong, Zhenglun Kong, Geng Yuan, Wei Niu, Dong Huang, Yanzhi Wang |
 |
Paper |
 
Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
Junyuan Hong, Jinhao Duan, Chenhui Zhang, Zhangheng Li, Chulin Xie et al |
 |
Github
Paper
Project |
Compressing Large Language Models by Streamlining the Unimportant Layer
Xiaodong Chen, Yuxuan Hu, Jing Zhang |
 |
Paper |

Multilingual Brain Surgeon: Large Language Models Can be Compressed Leaving No Language Behind
Hongchuan Zeng, Hongshen Xu, Lu Chen, Kai Yu |
 |
Github
Paper |

Accelerating Inference in Large Language Models with a Unified Layer Skipping Strategy
Yijin Liu, Fandong Meng, Jie Zhou |
 |
Github
Paper |
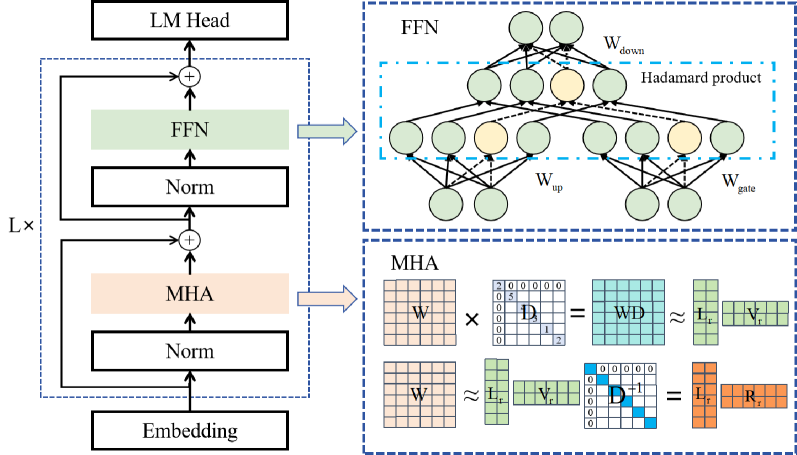
LoRAP: Transformer Sub-Layers Deserve Differentiated Structured Compression for Large Language Models
Guangyan Li, Yongqiang Tang, Wensheng Zhang |
 |
Paper |
CATS: Contextually-Aware Thresholding for Sparsity in Large Language Models
Je-Yong Lee, Donghyun Lee, Genghan Zhang, Mo Tiwari, Azalia Mirhoseini |
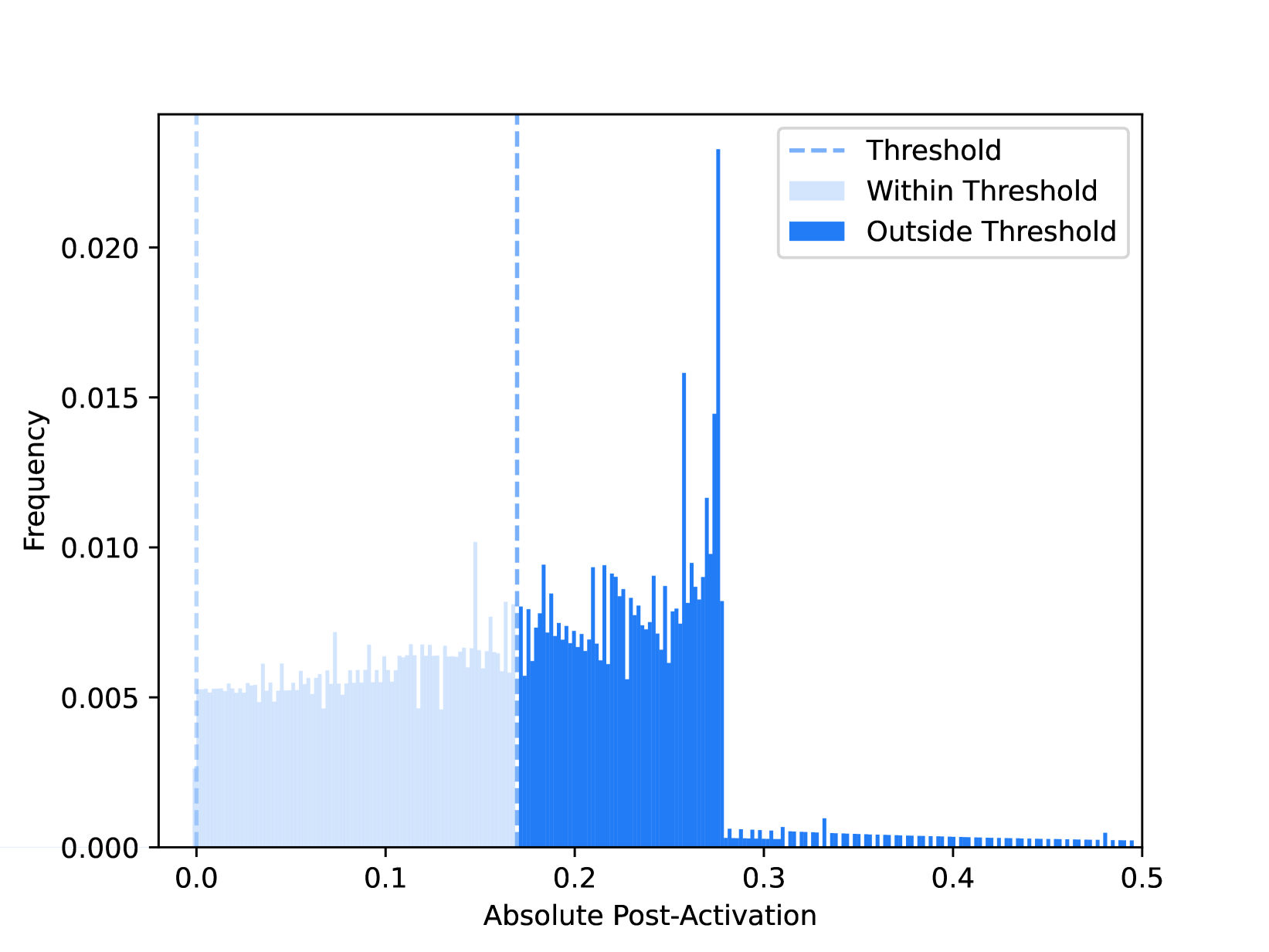 |
Paper |
Layer Skip: Enabling Early Exit Inference and Self-Speculative Decoding
Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer et al |
 |
Paper |
Enabling High-Sparsity Foundational Llama Models with Efficient Pretraining and Deployment
Abhinav Agarwalla, Abhay Gupta, Alexandre Marques, Shubhra Pandit, Michael Goin, Eldar Kurtic, Kevin Leong, Tuan Nguyen, Mahmoud Salem, Dan Alistarh, Sean Lie, Mark Kurtz |
 |
Paper |
Dependency-Aware Semi-Structured Sparsity of GLU Variants in Large Language Models
Zhiyu Guo, Hidetaka Kamigaito, Taro Wanatnabe |
 |
Paper |
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
David Raposo, Sam Ritter, Blake Richards, Timothy Lillicrap, Peter Conway Humphreys, Adam Santoro |
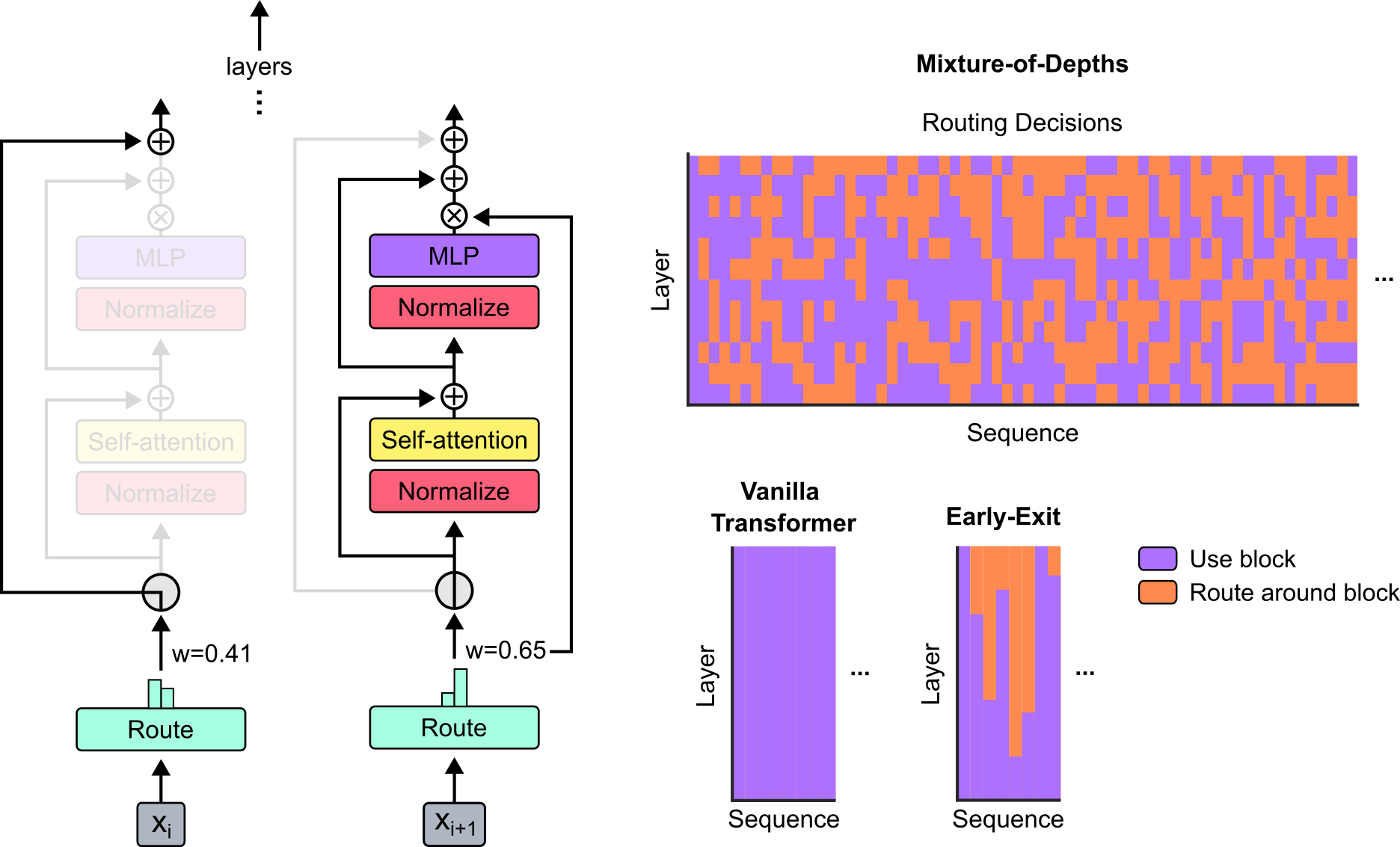 |
Paper |
 
Pruning as a Domain-specific LLM Extractor
Nan Zhang, Yanchi Liu, Xujiang Zhao, Wei Cheng, Runxue Bao, Rui Zhang, Prasenjit Mitra, Haifeng Chen |
 |
Github
Paper |
 
Language-Specific Pruning for Efficient Reduction of Large Language Models
Maksym Shamrai |
|
Github
Paper |

OpenBA-V2: Reaching 77.3% High Compression Ratio with Fast Multi-Stage Pruning
Dan Qiao, Yi Su, Pinzheng Wang, Jing Ye, Wenjing Xie et al |
 |
Github
Paper |
FinerCut: Finer-grained Interpretable Layer Pruning for Large Language Models
Yang Zhang, Yawei Li, Xinpeng Wang, Qianli Shen, Barbara Plank, Bernd Bischl, Mina Rezaei, Kenji Kawaguchi |
 |
Paper |

SLoPe: Double-Pruned Sparse Plus Lazy Low-Rank Adapter Pretraining of LLMs
Mohammad Mozaffari, Amir Yazdanbakhsh, Zhao Zhang, Maryam Mehri Dehnavi |
 |
Github
Paper |

SPP: Sparsity-Preserved Parameter-Efficient Fine-Tuning for Large Language Models
Xudong Lu, Aojun Zhou, Yuhui Xu, Renrui Zhang, Peng Gao, Hongsheng Li |
 |
Github
Paper |
Large Language Model Pruning
Hanjuan Huang, Hao-Jia Song, Hsing-Kuo Pao |
 |
Paper |
Effective Interplay between Sparsity and Quantization: From Theory to Practice
Simla Burcu Harma, Ayan Chakraborty, Elizaveta Kostenok, Danila Mishin, Dongho Ha, Babak Falsafi, Martin Jaggi, Ming Liu, Yunho Oh, Suvinay Subramanian, Amir Yazdanbakhsh |
|
Paper |
VTrans: Accelerating Transformer Compression with Variational Information Bottleneck based Pruning
Oshin Dutta, Ritvik Gupta, Sumeet Agarwal |
 |
Paper |
Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters
Yixin Song, Haotong Xie, Zhengyan Zhang, Bo Wen, Li Ma, Zeyu Mi, Haibo Chen |
 |
Paper
Model |
 
Pruner-Zero: Evolving Symbolic Pruning Metric from scratch for Large Language Models
Peijie Dong, Lujun Li, Zhenheng Tang, Xiang Liu, Xinglin Pan, Qiang Wang, Xiaowen Chu |
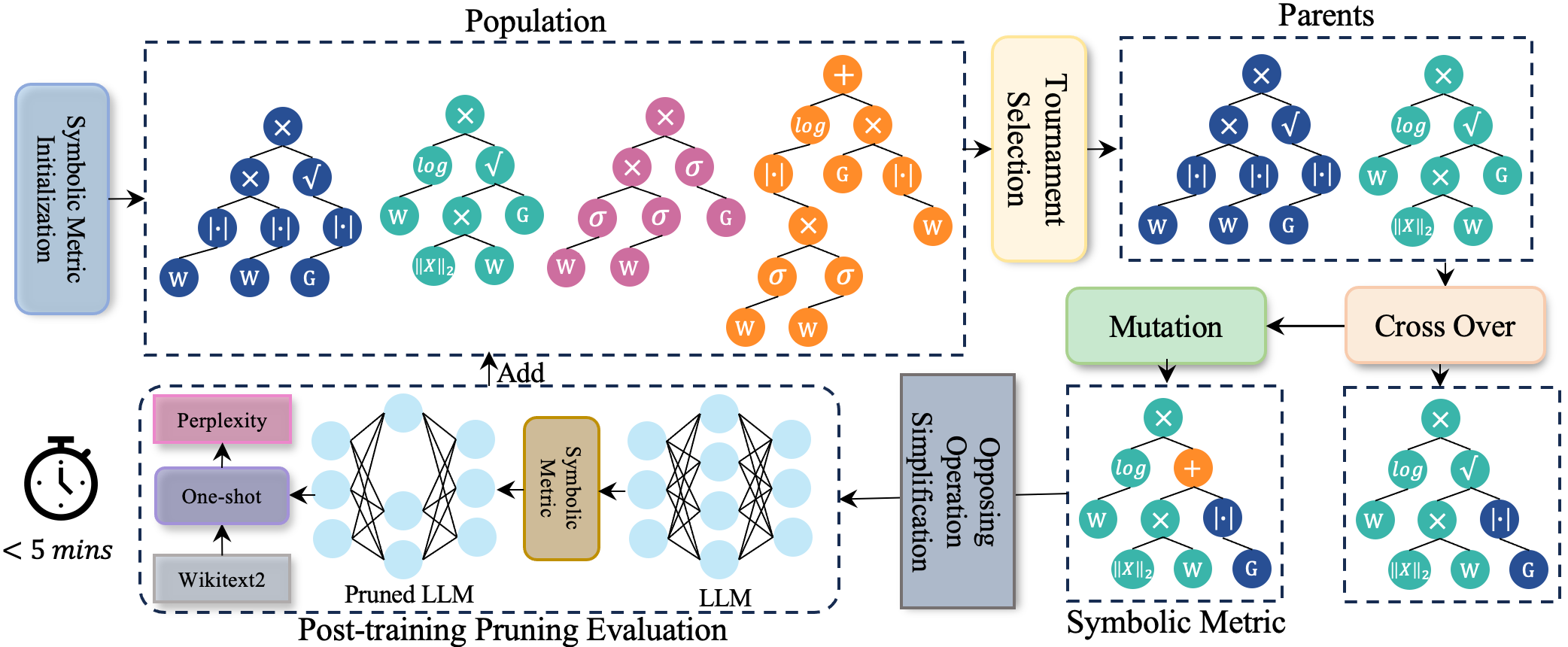 |
Github
Paper |

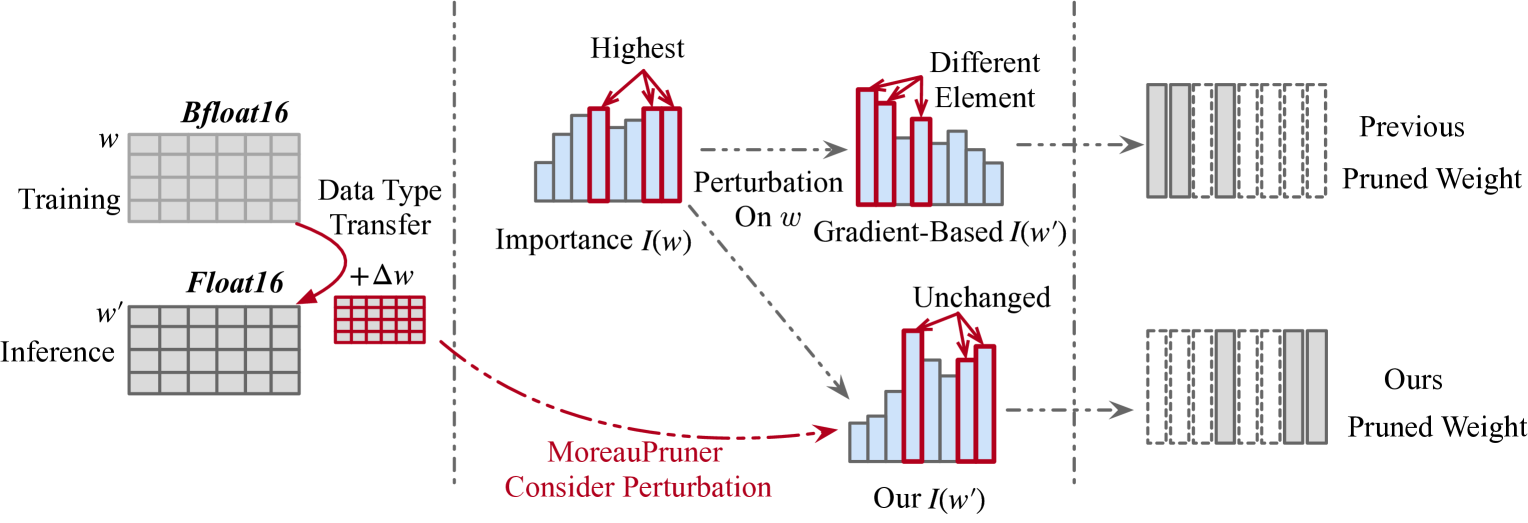
MoreauPruner: Robust Pruning of Large Language Models against Weight Perturbations
Zixiao Wang, Jingwei Zhang, Wenqian Zhao, Farzan Farnia, Bei Yu |
 |
Github
Paper |
ALPS: Improved Optimization for Highly Sparse One-Shot Pruning for Large Language Models
Xiang Meng, Kayhan Behdin, Haoyue Wang, Rahul Mazumder |
 |
Paper |
Optimization-based Structural Pruning for Large Language Models without Back-Propagation
Yuan Gao, Zujing Liu, Weizhong Zhang, Bo Du, Gui-Song Xia |
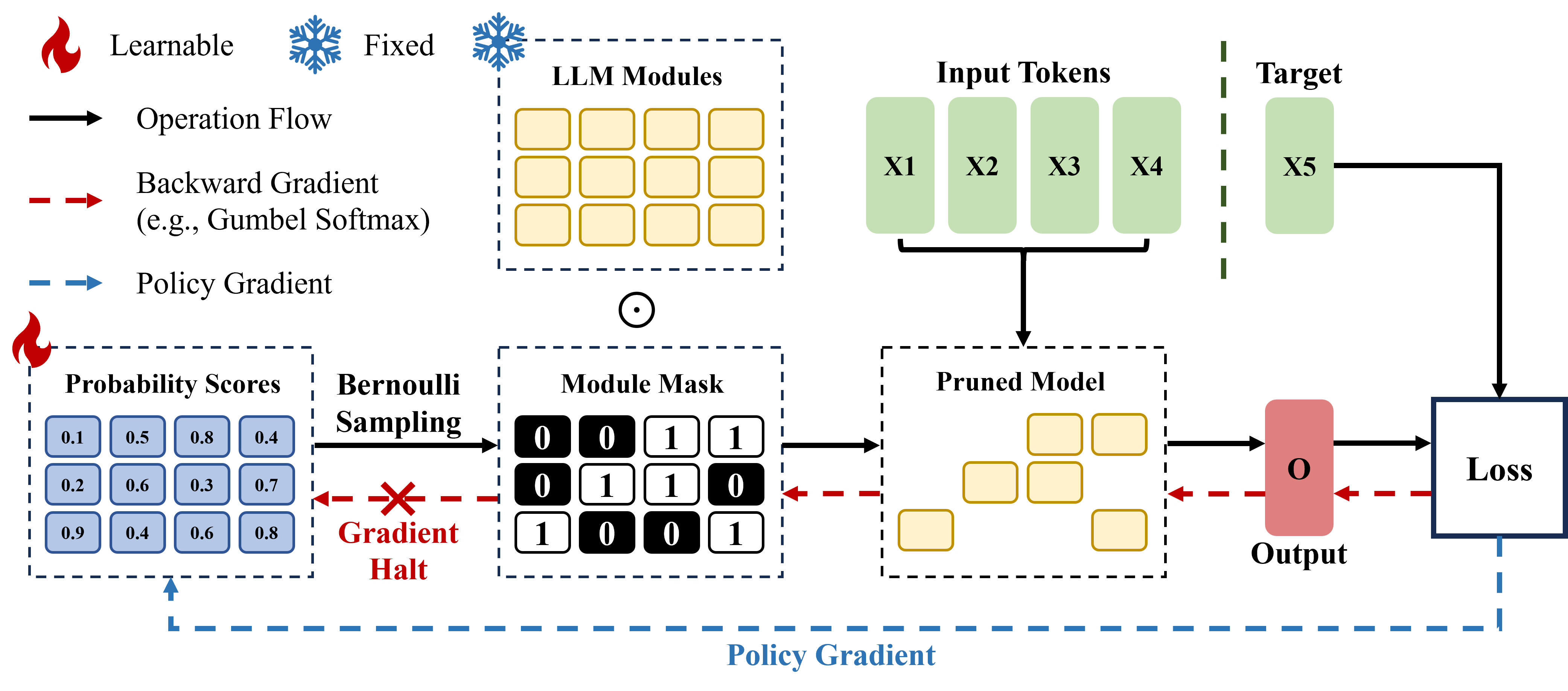 |
Paper |

ShadowLLM: Predictor-based Contextual Sparsity for Large Language Models
Yash Akhauri, Ahmed F AbouElhamayed, Jordan Dotzel, Zhiru Zhang, Alexander M Rush, Safeen Huda, Mohamed S Abdelfattah |
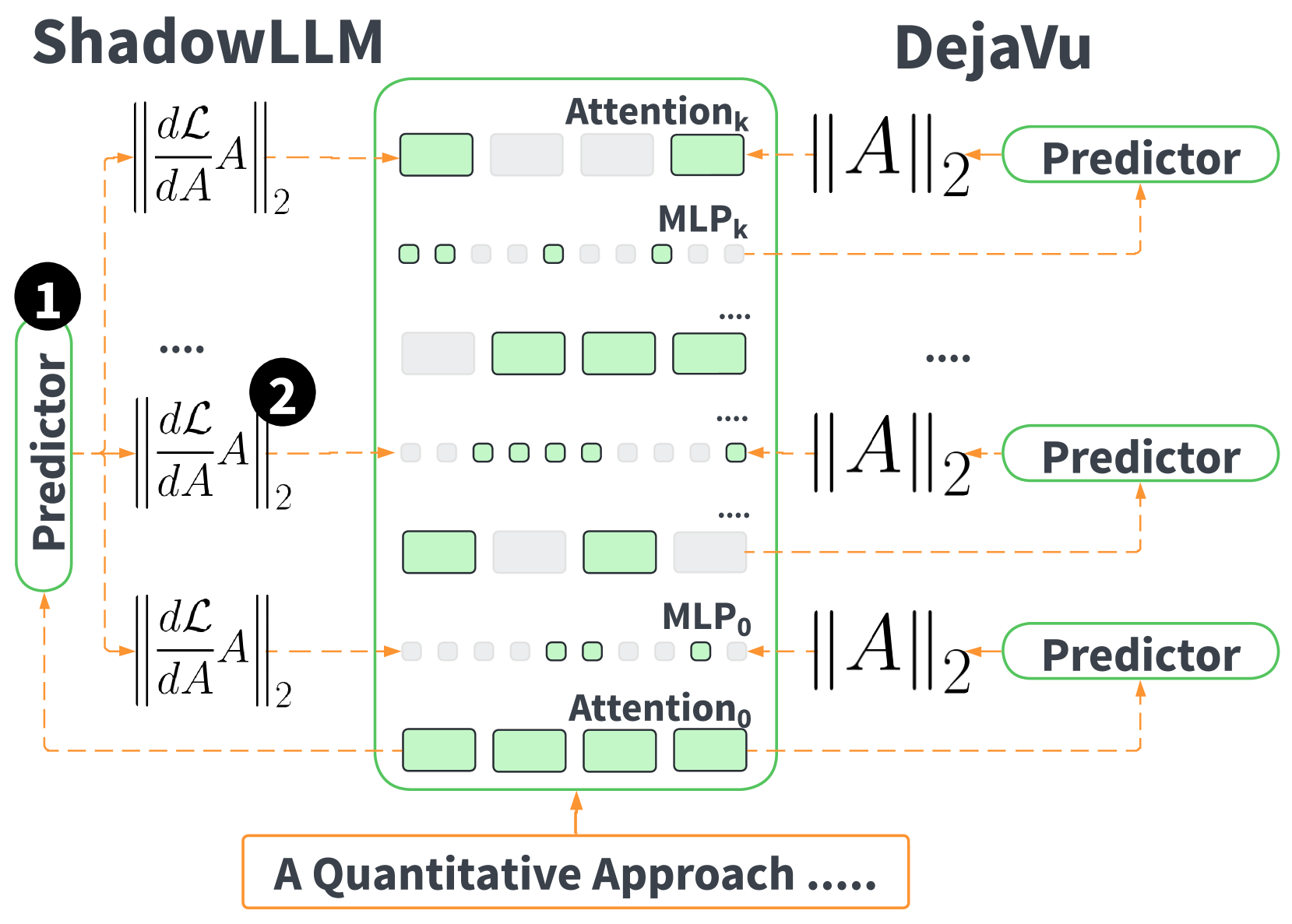 |
Github
Paper |
Rethinking Pruning Large Language Models: Benefits and Pitfalls of Reconstruction Error Minimization
Sungbin Shin, Wonpyo Park, Jaeho Lee, Namhoon Lee |
 |
Paper |

Learning Neural Networks with Sparse Activations
Pranjal Awasthi, Nishanth Dikkala, Pritish Kamath, Raghu Meka |
|
Paper |
FoldGPT: Simple and Effective Large Language Model Compression Scheme
Songwei Liu, Chao Zeng, Lianqiang Li, Chenqian Yan, Lean Fu, Xing Mei, Fangmin Chen |
 |
Paper |
Structured Pruning for Large Language Models Using Coupled Components Elimination and Minor Fine-tuning
Honghe Zhang, XiaolongShi XiaolongShi, Jingwei Sun, Guangzhong Sun |
 |
Paper |

BlockPruner: Fine-grained Pruning for Large Language Models
Longguang Zhong, Fanqi Wan, Ruijun Chen, Xiaojun Quan, Liangzhi Li |
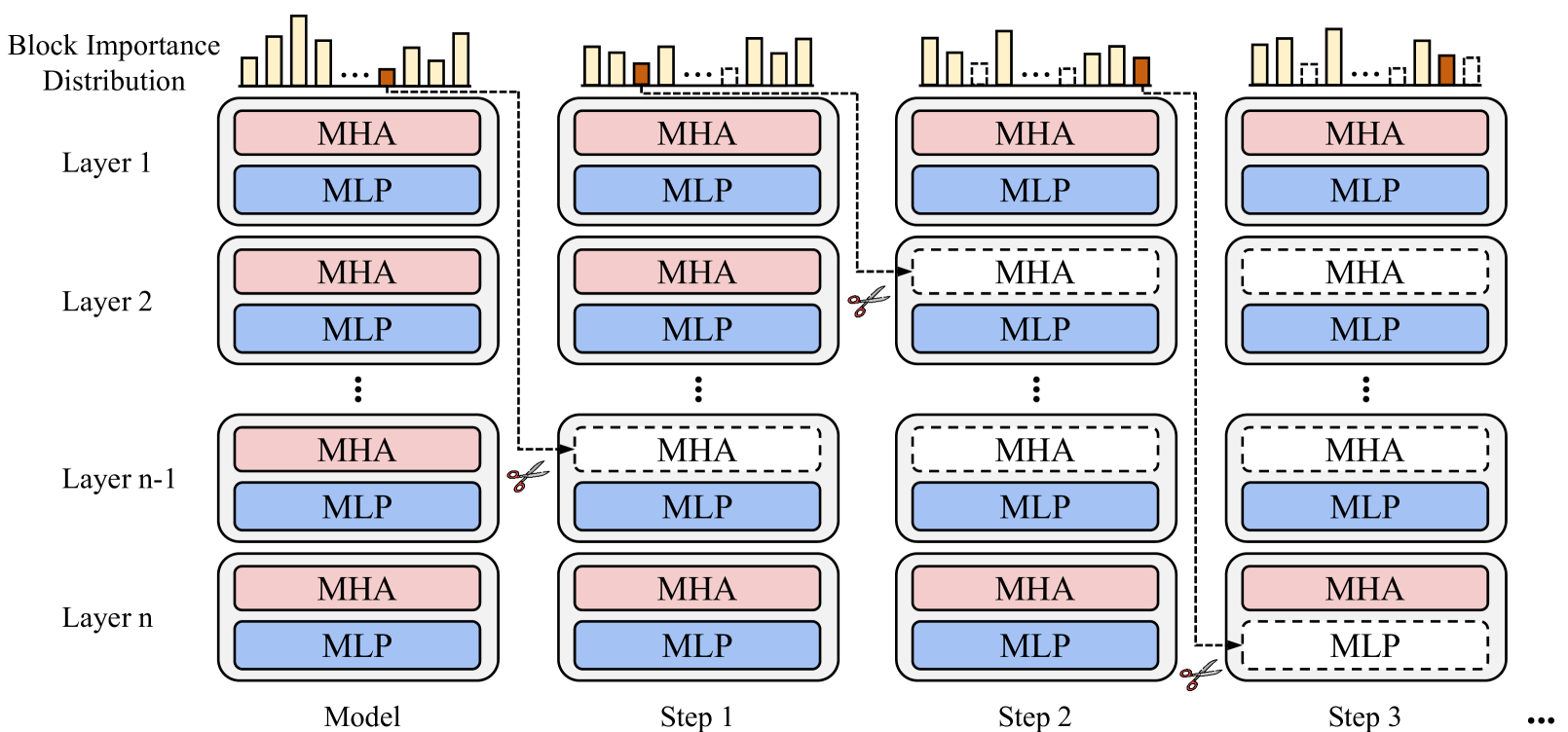 |
Github
Paper |
Flextron: Many-in-One Flexible Large Language Model
Ruisi Cai, Saurav Muralidharan, Greg Heinrich, Hongxu Yin, Zhangyang Wang, Jan Kautz, Pavlo Molchanov |
 |
Paper |