Matrix Android TraceCanary
Baby 不要再哭泣,这一幕多么熟悉~

在使用 App 时,有些人遇上这弹框应该会是一本正经,而有些人看到了估计一脸懵逼(黑人❓)。 当然,这里我们要讨论的不是什么初恋,实际是对大多数开发者来说,戏虐你千百遍,回头对它如初恋的卡顿。
曾经有篇杂志说“使用一款应用,犹如谈一场恋爱”,当时我觉得这是一本正经地在胡说八道,你手机装了上百款应用,能说这像谈恋爱?但现在想想,其实并非没有道理,当你喜欢上一款应用,往往是因为它的功能足够吸引你,就像你喜欢他的外表,再然后你体验了一段时间(交往),发现这款确实是你喜欢的,你才会渐渐地对它产生了依赖,但如果你在这过程中,发现用户体验很不好,经常卡顿,甚至无响应(爱理不理),最终我相信你选择了卸载(分手),这不就是类似恋爱的过程吗?所以用户体验的好坏,往往决定了用户的留存,而解决卡顿则是其中至关重要的一步。
事实上,搞客户端开发的同学应该知道,解决卡顿的过程往往是曲折的,有些并没有我们想的那样简单、浅表,但我们依旧不屈不挠地想尽一切办法去发现它,解决它。如对初恋般真诚,这就是我们对待卡顿的一种态度。
什么是卡顿,很多人能马上联系到的是帧率 FPS (每秒显示帧数)。那么多低的 FPS 才是卡顿呢?又或者低 FPS 真的就是卡顿吗?(以下 FPS 默认指平均帧率)
其实并非如此,举个例子,游戏玩家通常追求更流畅的游戏画面体验一般要达到 60FPS 以上,但我们平时看到的大部分电影或视频 FPS 其实不高,一般只有 25FPS ~ 30FPS,而实际上我们也没有觉得卡顿。 在人眼结构上看,当一组动作在 1 秒内有 12 次变化(即 12FPS),我们会认为这组动作是连贯的;而当大于 60FPS 时,人眼很难区分出来明显的变化,所以 60FPS 也一直作为业界衡量一个界面流畅程度的重要指标。一个稳定在 30FPS 的动画,我们不会认为是卡顿的,但一旦 FPS 很不稳定,人眼往往容易感知到。
FPS 低并不意味着卡顿发生,而卡顿发生 FPS 一定不高。 FPS 可以衡量一个界面的流程性,但往往不能很直观的衡量卡顿的发生,这里有另一个指标(掉帧程度)可以更直观地衡量卡顿。
什么是掉帧(跳帧)? 按照理想帧率 60FPS 这个指标,计算出平均每一帧的准备时间有 1000ms/60 = 16.6667ms,如果一帧的准备时间超出这个值,则认为发生掉帧,超出的时间越长,掉帧程度越严重。假设每帧准备时间约 32ms,每次只掉一帧,那么 1 秒内实际只刷新 30 帧,即平均帧率只有 30FPS,但这时往往不会觉得是卡顿。反而如果出现某次严重掉帧(>300ms),那么这一次的变化,通常很容易感知到。所以界面的掉帧程度,往往可以更直观的反映出卡顿。
我们将掉帧数划分出几个区间进行定级,掉帧数小于 3 帧的情况属于最佳,依次类推,见下表:
| Best | Normal | Middle | High | Frozen |
|---|---|---|---|---|
| [0:3) | [3:9) | [9:24) | [24:42) | [42:∞) |
相比单看平均帧率,掉帧程度的分布可以明显的看出,界面卡顿(平均帧率低)的原因是因为连续轻微的掉帧(下图1),还是某次严重掉帧造成的(下图2)。
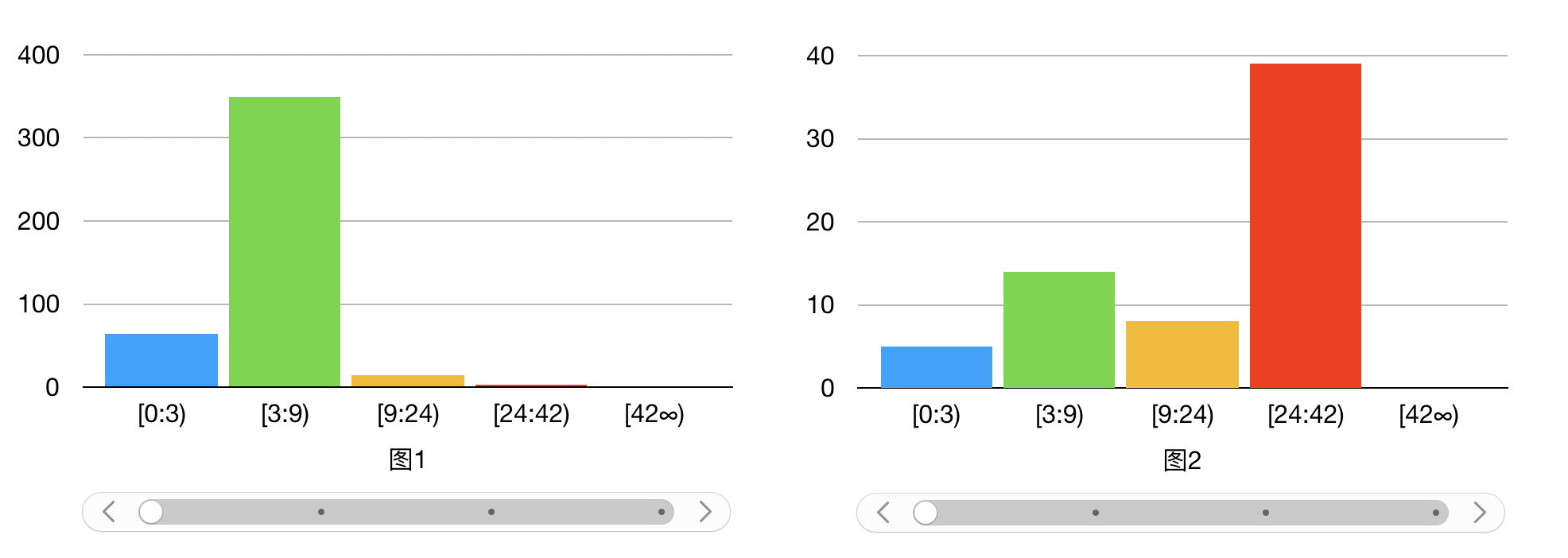 再通过 Activity 区分不同场景,计算每个界面在有效绘制的时间片内,掉帧程度的分布情况及平均帧率,从而来评估出一个界面的整体流畅程度。
再通过 Activity 区分不同场景,计算每个界面在有效绘制的时间片内,掉帧程度的分布情况及平均帧率,从而来评估出一个界面的整体流畅程度。
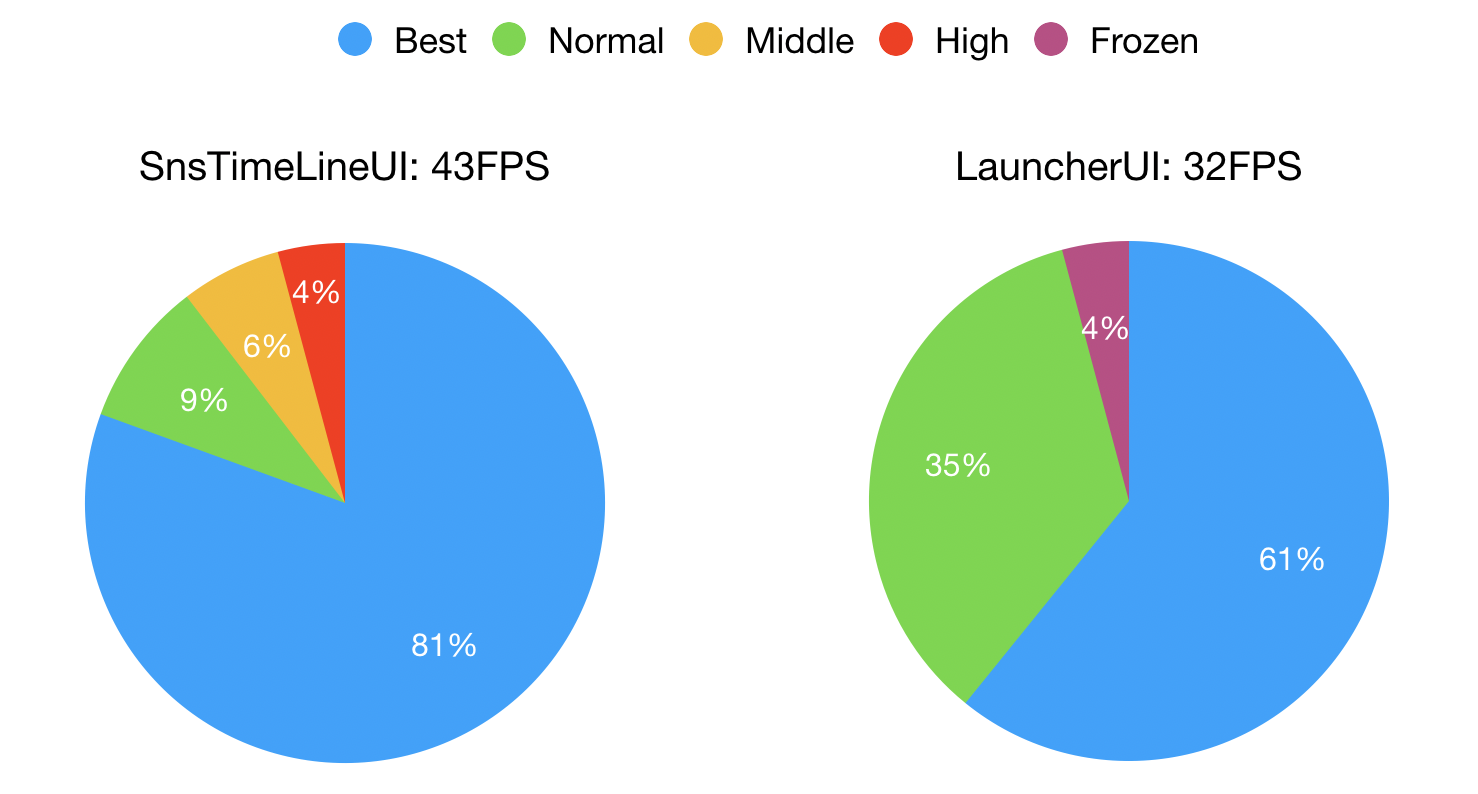
具体如何计算界面在有交互的场景下的平均帧率及掉帧情况,可见Matrix中TraceCannary模块。
在微信Android客户端中,每天都面临着各式各样的卡顿,其中有一部分通常是可本地复现的,对于这种容易重现的场景,一般我们在开发及体验测试阶段容易注意得到,而定位卡顿的根源,我们常用的方法是通过系统工具 TraceView 来抓取卡顿过程中函数的执行情况(堆栈,耗时,调用次数等),此方法支持在代码中进行打点,也支持在 TraceView/Android Studio Profiler 中手动启动收集。
trace 的信息如下:
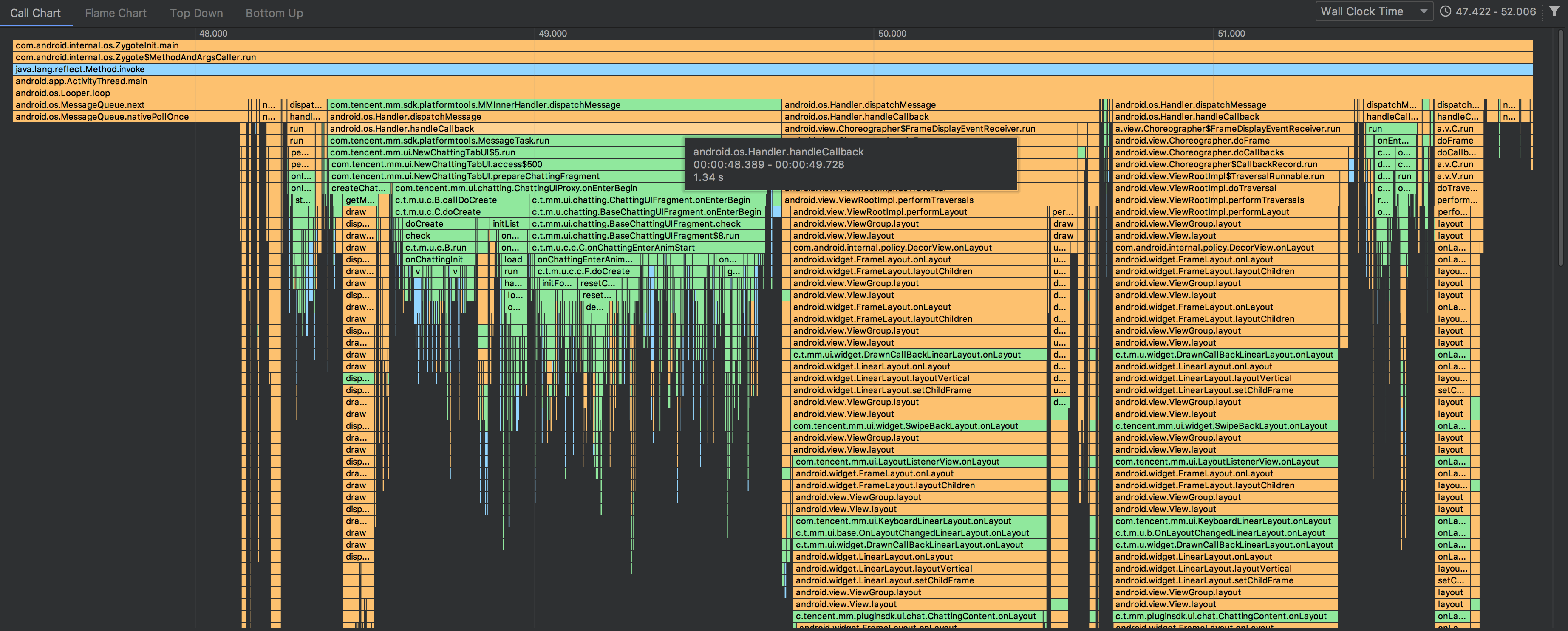 通过 TraceView 的可视化界面,我们可以具体知道某个过程中的调用栈信息及各个函数的执行次数与耗时,能比较直观的找到严重耗时的函数,帮助我们快速解决卡顿问题。
通过 TraceView 的可视化界面,我们可以具体知道某个过程中的调用栈信息及各个函数的执行次数与耗时,能比较直观的找到严重耗时的函数,帮助我们快速解决卡顿问题。
但往往大部分卡顿是很难及时发现的,不可重现的卡顿,经常出现在线上用户的真实使用过程中,这种卡顿往往跟机器性能,手机环境,甚至是操作偏好等因素息息相关。一般也是从用户反馈中得到,通常表述为“新版本变卡了”,“朋友圈很卡”,“聊天经常无响应”,我们很难在这种描述中,直接洞察到卡顿的根源,甚至有些连卡顿的场景都不知道,很难准确重现,所以这种卡顿容易让人摸不着头脑。 当然作为开发者,我更希望用户反馈的是,“亲爱的开发同志,本次卡顿罪魁祸首是,某某函数耗时666ms,请速速解决它。” 那么面对这种卡顿,我们是不是就束手无策了呢?并非如此。
我们知道造成卡顿的直接原因通常是,主线程执行繁重的UI绘制、大量的计算或IO等耗时操作。
业界有几种常见解决方案,都可以从一定程度上,帮助开发者快速定位到卡顿的堆栈,如 BlockCanary、ArgusAPM、LogMonitor 。这些方案的主要思想是,监控主线程执行耗时,当超过阈值时,dump出当前主线程的执行堆栈,通过堆栈分析找到卡顿原因。
从监控主线程的实现原理上,主要分为两种:
1、依赖主线程 Looper,监控每次 dispatchMessage 的执行耗时。(BlockCanary)
2、依赖 Choreographer 模块,监控相邻两次 Vsync 事件通知的时间差。(ArgusAPM、LogMonitor)
简单看下这两种方案的实现原理:
第一种方案,看下 Looper#loop 代码片段:
public static void loop() {
...
for (;;) {
...
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
...
}
}主线程所有执行的任务都在 dispatchMessage 方法中派发执行完成,我们通过 setMessageLogging 的方式给主线程的 Looper 设置一个 Printer ,因为 dispatchMessage 执行前后都会打印对应信息,在执行前利用另外一条线程,通过 Thread#getStackTrace 接口,以轮询的方式获取主线程执行堆栈信息并记录起来,同时统计每次 dispatchMessage 方法执行耗时,当超出阈值时,将该次获取的堆栈进行分析上报,从而来捕捉卡顿信息,否则丢弃此次记录的堆栈信息。
第二种方案,利用系统 Choreographer 模块,向该模块注册一个 FrameCallback 监听对象,同时通过另外一条线程循环记录主线程堆栈信息,并在每次 Vsync 事件 doFrame 通知回来时,循环注册该监听对象,间接统计两次 Vsync 事件的时间间隔,当超出阈值时,取出记录的堆栈进行分析上报。
简单代码实现如下:
Choreographer.getInstance().postFrameCallback(new Choreographer.FrameCallback() {
@Override
public void doFrame(long frameTimeNanos) {
if(frameTimeNanos - mLastFrameNanos > 100) {
...
}
mLastFrameNanos = frameTimeNanos;
Choreographer.getInstance().postFrameCallback(this);
}
});这两种方案,可以较方便的捕捉到卡顿的堆栈,但其最大的不足在于,无法获取到各个函数的执行耗时,对于稍微复杂一点的堆栈,很难找出可能耗时的函数,也就很难找到卡顿的原因。另外,通过其他线程循环获取主线程的堆栈,如果稍微处理不及时,很容易导致获取的堆栈有所偏移,不够准确,加上没有耗时信息,卡顿也就不好定位。
所以我们希望寻求一种可以在线上准确地捕捉卡顿堆栈,又能计算出各个函数执行耗时的方案。 而要计算函数的执行耗时,最关键的点在于如何对执行过程中的函数进行打点监控。
这里介绍两种方式:
1、在应用启动时,默认打开 Trace 功能(Debug.startMethodTracing),应用内所有函数在执行前后将会经过该函数(dalvik 上 dvmMethodTraceAdd 函数 或 art 上 Trace::LogMethodTraceEvent 函数), 通过hack手段代理该函数,在每个执行方法前后进行打点记录。
2、修改字节码的方式,在编译期修改所有 class 文件中的函数字节码,对所有函数前后进行打点插桩。
第一种方案,最大的好处是能统计到包括系统函数在内的所有函数出入口,对代码或字节码不用做任何修改,所以对apk包的大小没有影响,但由于方式比较hack,在兼容性和安全性上存在一定的风险。
第二种方案,利用 Java 字节码修改工具(如 BCEL、ASM、Javassis等),在编译期间收集所有生成的 class 文件,扫描文件内的方法指令进行统一的打点插桩,同样也可以高效的记录函数执行过程中的信息,相比第一种方案,除了无法统计系统内执行的函数,其它应用内实现的函数都可以覆盖到。而往往造成卡顿的函数并不是系统内执行的函数,一般都是我们应用开发实现的函数,所以这里无法统计系统内执行的函数对卡顿的定位影响不大。此方案无需 hook 任何函数,所以在兼容性方面会比第一个方案更可靠。
在这考虑上,我们最终选择了修改字节码的方案,来实现 Matrix-TraceCannary 模块,解决其它方案中卡顿堆栈无耗时信息的主要问题,来帮助开发者发现及定位卡顿问题。
通过代理编译期间的任务 transformClassesWithDexTask,将全局 class 文件作为输入,利用 ASM 工具,高效地对所有 class 文件进行扫描及插桩。
插桩过程有几个关键点:
1、选择在该编译任务执行时插桩,是因为 proguard 操作是在该任务之前就完成的,意味着插桩时的 class 文件已经被混淆过的。而选择 proguard 之后去插桩,是因为如果提前插桩会造成部分方法不符合内联规则,没法在 proguard 时进行优化,最终导致程序方法数无法减少,从而引发方法数过大问题。
2、为了减少插桩量及性能损耗,通过遍历 class 方法指令集,判断扫描的函数是否只含有 PUT/READ FIELD 等简单的指令,来过滤一些默认或匿名构造函数,以及 get/set 等简单不耗时函数。
3、针对界面启动耗时,因为要统计从 Activity#onCreate 到 Activity#onWindowFocusChange 间的耗时,所以在插桩过程中需要收集应用内所有 Activity 的实现类,并覆盖 onWindowFocusChange 函数进行打点。
4、为了方便及高效记录函数执行过程,我们为每个插桩的函数分配一个独立 ID,在插桩过程中,记录插桩的函数签名及分配的 ID,在插桩完成后输出一份 mapping,作为数据上报后的解析支持。
归纳起来,编译期所做的工作如下图:
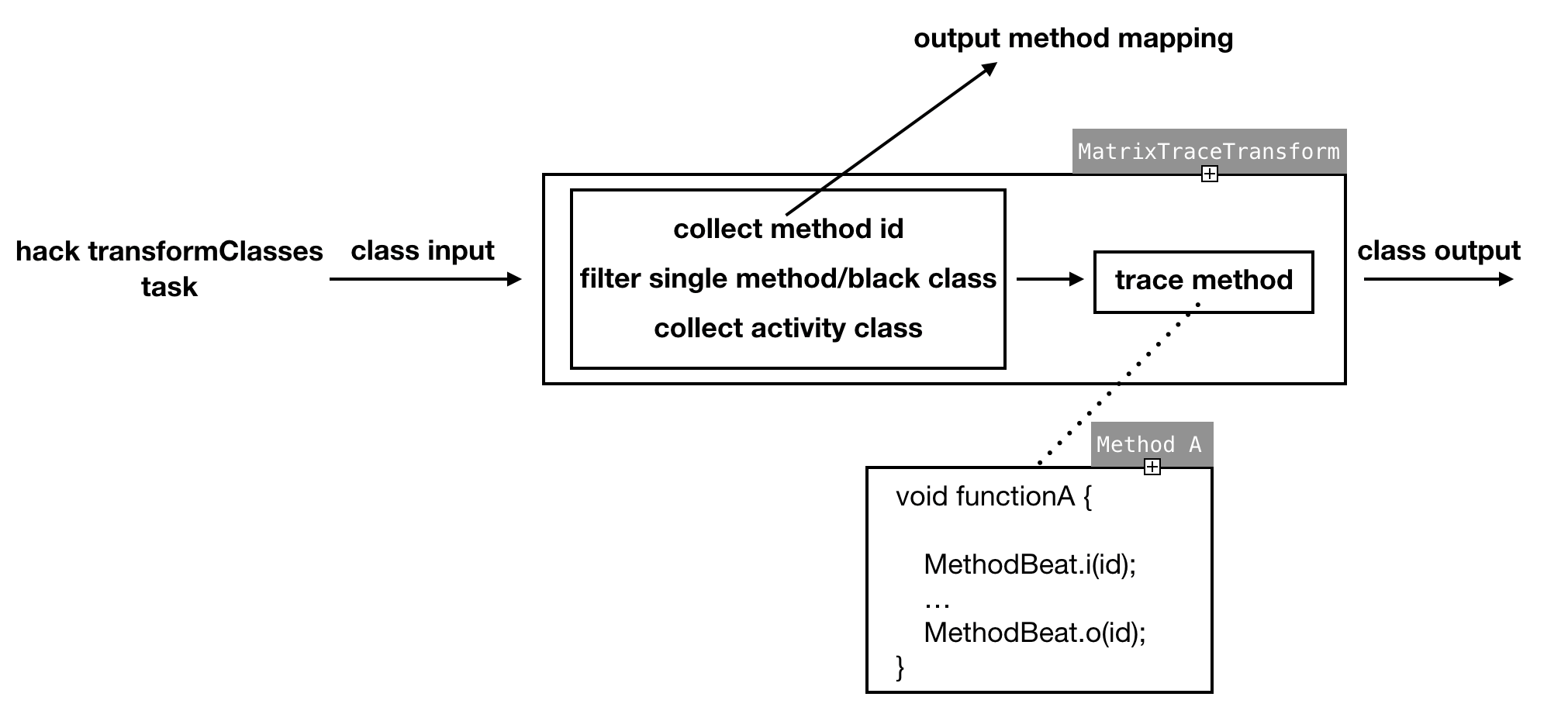
编译期已经对全局的函数进行插桩,在运行期间每个函数的执行前后都会调用 MethodBeat.i/o 的方法,如果是在主线程中执行,则在函数的执行前后获取当前距离 MethodBeat 模块初始化的时间 offset(为了压缩数据,存进一个long类型变量中),并将当前执行的是 MethodBeat i或者o、mehtod id 及时间 offset,存放到一个 long 类型变量中,记录到一个预先初始化好的数组 long[] 中 index 的位置(预先分配记录数据的 buffer 长度为 100w,内存占用约 7.6M)。数据存储如下图:
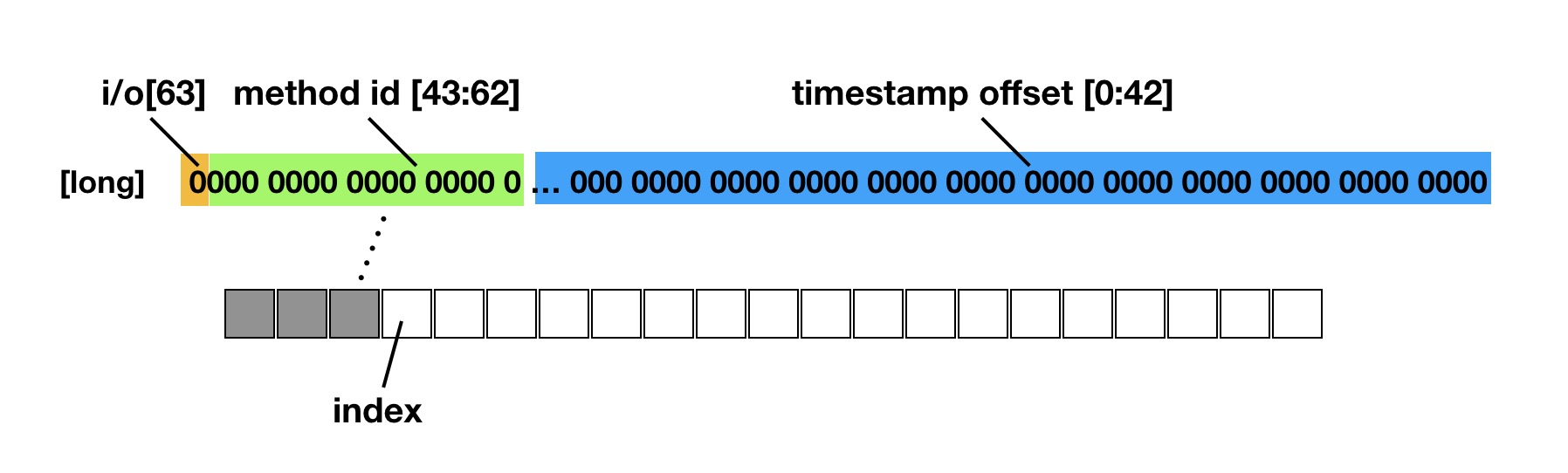 通过向 Choreographer 注册监听,在每一帧 doframe 回调时判断距离上一帧的时间差是否超出阈值(卡顿),如果超出阈值,则获取数组 index 前的所有数据(即两帧之间的所有函数执行信息)进行分析上报。
同时,我们在每一帧 doFrame 到来时,重置一个定时器,如果 5s 内没有 cancel,则认为 ANR 发生,这时会主动取出当前记录的 buffer 数据进行独立分析上报,对这种 ANR 事件进行单独监控及定位。
通过向 Choreographer 注册监听,在每一帧 doframe 回调时判断距离上一帧的时间差是否超出阈值(卡顿),如果超出阈值,则获取数组 index 前的所有数据(即两帧之间的所有函数执行信息)进行分析上报。
同时,我们在每一帧 doFrame 到来时,重置一个定时器,如果 5s 内没有 cancel,则认为 ANR 发生,这时会主动取出当前记录的 buffer 数据进行独立分析上报,对这种 ANR 事件进行单独监控及定位。
另外,考虑到每个方法执行前后都获取系统时间(System.nanoTime)会对性能影响比较大,而实际上,单个函数执行耗时小于 5ms 的情况,对卡顿来说不是主要原因,可以忽略不计,如果是多次调用的情况,则在它的父级方法中可以反映出来,所以为了减少对性能的影响,通过另一条更新时间的线程每 5ms 去更新一个时间变量,而每个方法执行前后只读取该变量来减少性能损耗。
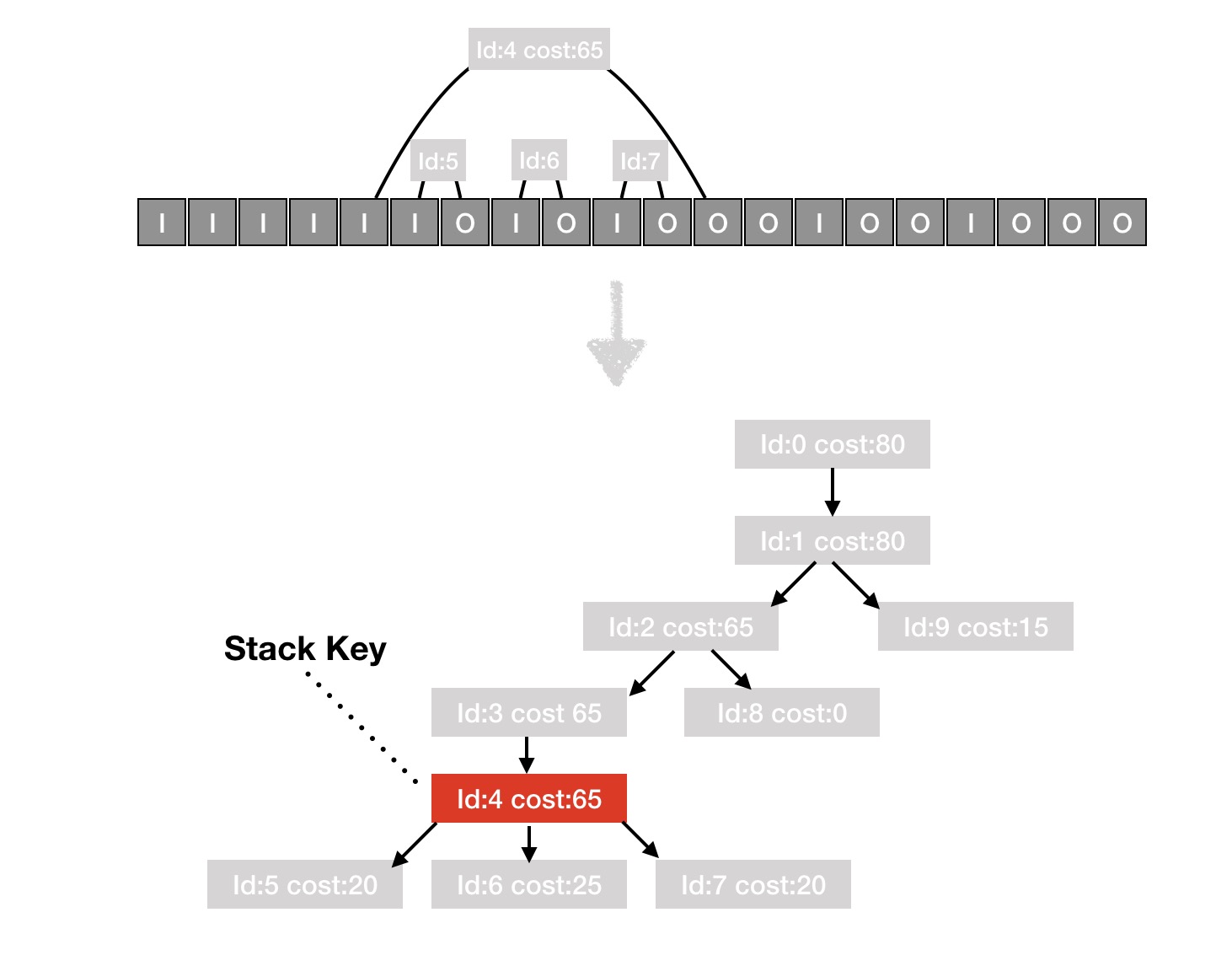
堆栈聚类问题: 如果将收集的原始数据进行上报,数据量很大而且后台很难聚类有问题的堆栈,所以在上报之前需要对采集的数据进行简单的整合及裁剪,并分析出一个能代表卡顿堆栈的 key,方便后台聚合。
通过遍历采集的 buffer ,相邻 i 与 o 为一次完整函数执行,计算出一个调用树及每个函数执行耗时,并对每一级中的一些相同执行函数做聚合,最后通过一个简单策略,分析出主要耗时的那一级函数,作为代表卡顿堆栈的key。
TraceCanary 其本身作为一款性能检测工具,对自身性能的损耗要求比较高,以下是插桩前后的对比数据:
| item | trace | untrace | info |
|---|---|---|---|
| FPS | 56.16 | 56.19 | Android7.0 好机器朋友圈帧率 |
| FPS | 41.18 | 42.70 | Android4.2 差机器朋友圈帧率 |
| apk size | 81.91 MB | 81.12 MB | 实际插桩方法总数 163141 |
| memory | +7.6M | ~ | 运行时内存 |
从实测数据上看,TraceCanary 对于好机器的性能影响可忽略,对差机器性能稍有损耗,但影响很小。 对安装包大小影响,对于微信这种大体量的应用,实际插桩函数 16w+,对安装包增加了 800K 左右。
以下是对比系统工具及一些比较热门的方案
| Matrix-TraceCanary | TraceView | BlockCanary | BlockCanaryEx | ArgusAPM | ANR-WatchDog | 广研卡顿系统 | |
|---|---|---|---|---|---|---|---|
| 定位精确度 | 高 | 高 | 中 | 高 | 中 | 中 | 中 |
| 字节码修改 | 是 | 否 | 否 | 是 | 否 | 否 | 否 |
| 资源占用 | 较低 | 较低 | 较低 | 较低 | 较低 | 较低 | 较低 |
| 线上采集 | 支持 | 不支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 性能损耗 | 可忽略 | 非常大 | 可忽略 | 大 | 可忽略 | 可忽略 | 可忽略 |
| 界面展示 | 不支持 | 支持 | 支持 | 支持 | 支持 | 支持 | 未知 |
| 帧率计算 | 支持 | 不支持 | 不支持 | 不支持 | 支持 | 不支持 | 支持 |
| ANR监控 | 支持 | 不支持 | 不支持 | 不支持 | 支持 | 支持 | 支持 |
| 启动耗时 | 支持 | 不支持 | 不支持 | 不支持 | 不支持 | 不支持 | 不支持 |
最终,我们希望通过观察大盘整体的帧率及掉帧程度,来评估并监控一些重要场景的流畅性。通过一个闭环的流程,利用 Matrix-TraceCanary 模块从客户端对卡顿进行捕捉与分析上报,通过后台聚类问题堆栈及版本对比,找到卡顿堆栈的责任人,通知其进行解决优化,而最终处理的效果也会在 Matrix 平台中反应出来。在这样不断发现卡顿,解决卡顿的过程中,希望尽可能地优化微信Android客户端的流畅性,给用户带来更好的体验。
如今 Matrix 已经开源,TraceCanary 模块依然在不断优化中,解决卡顿问题,我们一直在路上。