DataGenerator V2 Requirements
Ability to generate all paths, all edges and all nodes coverage on a dependency graph.
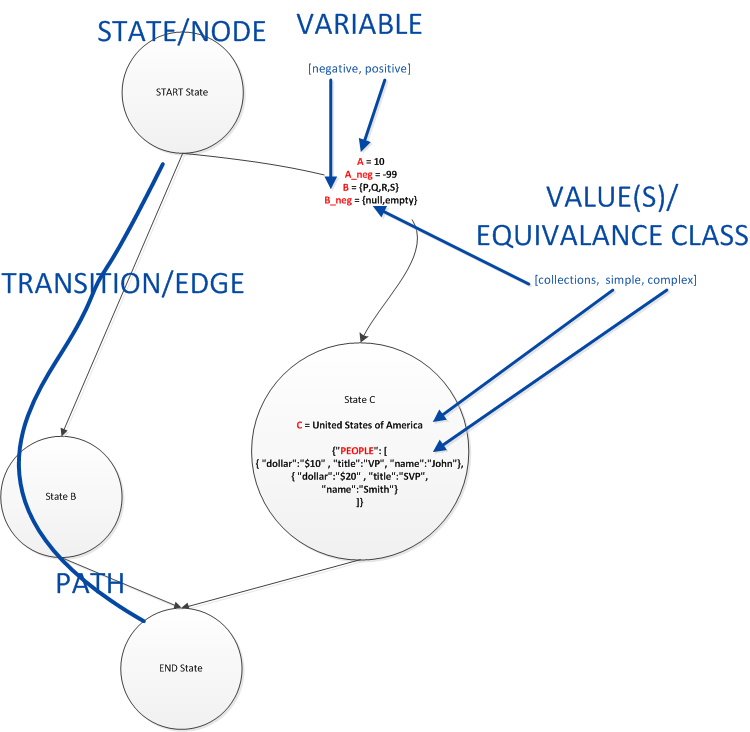
Ability to generate all combinations and all pairs combinations on a list of variables with defined equivalence classes.
Ability to generate data such that all path combinations of a dependency model will be exercised in the final resultant data set.
Ability to generate data such that all edges of a dependency model will be exercised in the final resultant data set.
Ability to generate data such that all node of a dependency model will be exercised in the final resultant data set.
R1.4.1: Ability to define variables with single values on nodes (R1.4.1.1) and edges (R1.4.1.2) of a dependency graph.
R1.4.2: Ability to set simple strings and integers as variables. (On both nodes and edges)
R1.4.3: Ability to set arrays/collections of integers(R1.4.3.1.1), strings(R1.4.3.1.2) and complex(R1.4.3.1.3) variables. It is given that a single node or an edge can have multiple variables with collections; refer to requirement R1.4.20 in order to determine how multiple collections on a single node/edge can be combined.
- When a collection variable is defined on an edge, decompose the problem graph to have multiple edges with a single value on each edge for the collection variable. (R1.4.3.2)
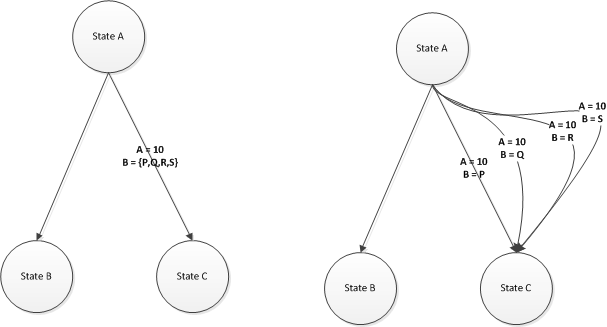
- When a collection variable is defined on a node, decompose the problem graph to have multiple nodes with a single value on each node for the collection variable. (R1.4.3.3)
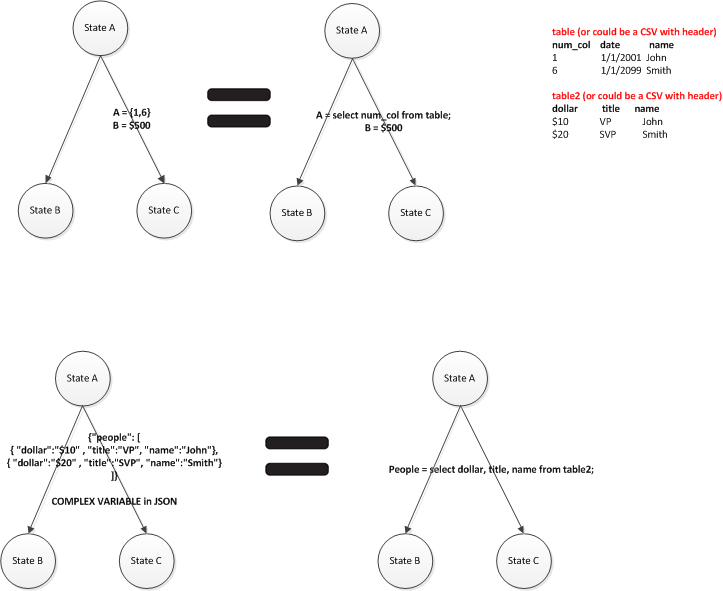
R1.4.4: Ability to set complex variables such as objects. (e.g. Using JSON, XML, CSV...etc) (On both nodes and edges).
- e.g. The following would be a JSON representation of a single complex variable named people with 2 values. Each value within people contain 3 attributes named dollar, title and name.

R1.4.5: Ability to set global variables of types described in R1.4.2 to R1.4.4. (On both nodes and edges).
R1.4.6: Ability to override/reset(R1.4.6.1) and add(R1.4.6.2) variables of types described in R1.4.2 to R1.4.5. (On both nodes and edges)
R1.4.7: Availability of commonly known equivalence class value generators. (On both nodes and edges) [General details on Equivalence Partitioning.] At a minimum the following equivalence class generators need to be supported.
- R1.4.7.1: Dates with format specification(Past, Future, Today, Custom Range)
- R1.4.7.2: String (Ability accept any regular expression as the format specification)
- R1.4.7.3: Numbers (Integers and Floats with Custom Ranges)
R1.4.8: Ability define expressions and calculations on nodes and edges. Expressions should be able to reference variable types described in R1.4.2 to R1.4.5.
- R1.4.8.1: Simple mathematical expressions. (Add, Subtract, Divide, Multiply)
- R1.4.8.2: Simple string manipulation. (Concatenate, Replace, Trim, Sub String, RegEx replace)
R1.4.9: Ability define a database queries(R1.4.9.1) and simple flat files(R1.4.9.2) as a way to define variable assignments. Look at the diagram below; the specification on the left is identical to the specification on the right. The only difference is the specification on the right is using a SQL query to define its dataset. Note the SQL can be replaced with a file URL which would contain the table/joined data in a CSV format.
R1.4.10: Ability to access inject arbitrary code on nodes (R1.4.10.1) and edges (R1.4.10.2). Code injected should have access (R1.4.10.3) to variables set earlier on a traversed path and any global variables set (For all types described in R1.4.2 to R1.4.5). The code should also have the ability to set and update/modify (R1.4.10.4) variables of types described in R1.4.2 to R1.4.5.
R1.4.11: Ability to execute formatting directives(code and templates) on the generated dataset so that the output could be custom formatted and code logic can be added before the output is generated.
R1.4.12: Ability define conditionals on nodes and edges which would effectively enable selective traversal dependent on the condition evaluating to true.
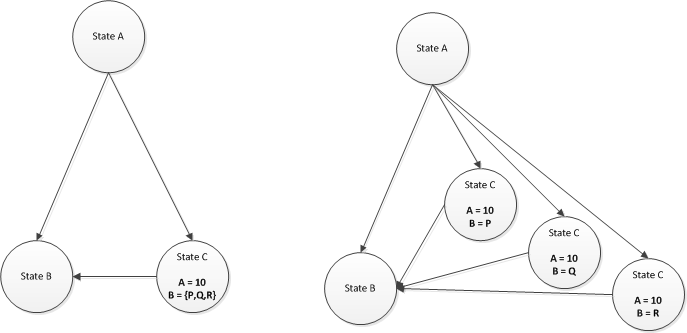
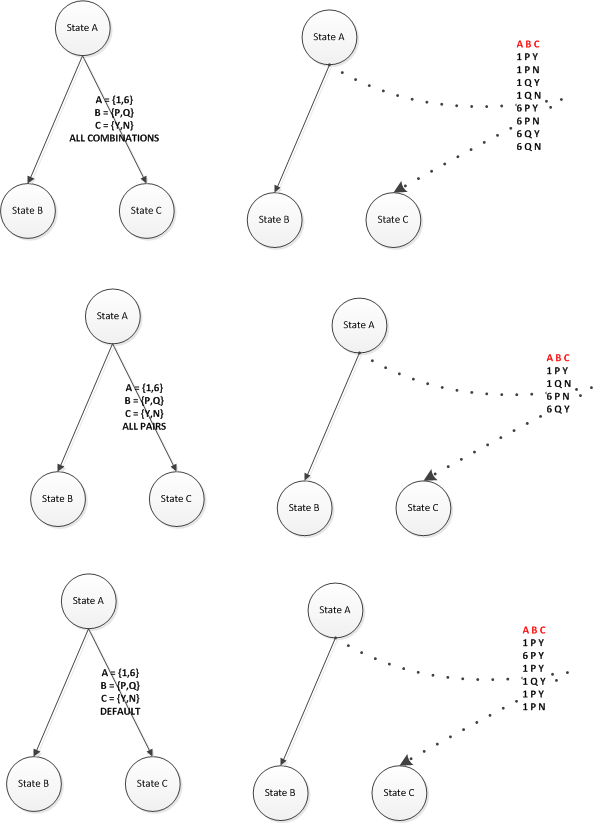
R1.4.20: When multiple collections as defined in R1.4.3 are specified on a single edge or node, the model generator should have the ability to generate combinations across the collections as follows.
-
R1.4.20.1 Option 1: Ability to do all combinations across multiple collections. This is a mathematical combinations across a set of variables on all its values. [LOOK AT DIAGRAM BELOW]
-
R1.4.20.2 Option 2: Ability to do pairwise combinations across multiple collections. (All Pairs Testing Wiki Link). This is a way to reduce the test data set by only concentrating on covering all combinations between only a pair of variables as opposed to all variables. [LOOK AT DIAGRAM BELOW]
-
R1.4.20.3 Option 3: Ability to expand each of the values in a single collection using the first value as the default value on other collections. When combining the values of variable A, always combine the first value of the other collection variables, B and C. [LOOK AT DIAGRAM BELOW]
R1.4.30: GUI editor for dependency modeling. (Features to be hashed out) TBD
R1.4.40: State diagrams can contain other state diagrams within them.
R1.5.1: Ability generate data that targets injecting a single negative value at a time into a given dataset.
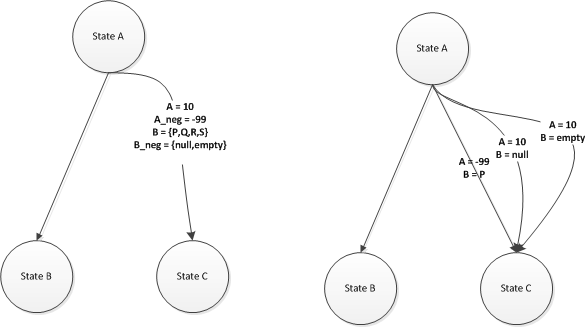
- R1.5.2.1: Ability to classify and partition a particular variable (of types described in R1.4.2 to R1.4.5) as negative or positive.
- R1.5.2.2: Using the negative classification defined in R1.5.2.1, have the ability to generate negative scenarios where each scenario would only have a single negative value in the dataset. When using positive values in a collection, use the first value (default value). When combining the negatives of values of variable A, only combine the first positive value of the other collection variable. The goal of this requirement is for the user to have the ability to make sure all negative values defined to be covered once in the resultant dataset. NOTE: Negative scenario generation should be applicable to all traversal techniques defined in R1.1, R1.2 and R1.3. When applied to all edges, only negative values on edges would be covered and when applied to all nodes, only negative values on nodes would be covered. [LOOK AT DIAGRAM BELOW]
TBD
TBD - Need to look into pre-existing data analytics solutions.
R3.1: The data set can be in flat file(R3.1.1) or in a relational database table (R3.1.2). R3.2: Ability report on critical data patterns and statistics.
- R3.2.1: Report on column level data frequencies. (e.g. The percentage of a particular variable observed within a single column)
- R3.2.2: Multiple variable correlation frequency. (e.g. Frequency of co-occurrence between 2 or more variables within a data set)
R3.10.2: Ability generate a model from the identified data patterns and statistics on R3.2.
Performance: Generate 1 TB size output of worth R1.0(all combinations, all pairs) data within 1 Hour. (Multi-threaded execution and distributed execution are suggested for performance gain)
Performance: Generate 1 TB size output of worth R2.0(all paths, all edges, all nodes) with 50 nodes and 100 edges with minimalistic output template logic, one variable per edge & node and no edge/node code execution within 1 Hour. (Multi-threaded execution and distributed execution are suggested for performance gain)