참고한 사이트는 다음과 같습니다.
- Docker 공식 문서
- Docker Swarm의 주요 용어, 활성화 방법 및 노드(Node) 관리법 살펴보기
- [Docker] Docker Swarm Cluster 구축하기(Swarm Mode)
- Docker Swarm에서 서비스(Service) 생성하고 다루기
- [Docker] Docker Swarm이란
EC2 3개를 사용하여 Docker swarm 실습을 진행했습니다.
- worker host: docker-swarm-1, docker-swarm-2
- manager host: docker-swarm-3
- 컨테이너 오케스트레이션이란 컨테이너의 배포, 관리, 확장, 네트워킹을 자동화하는 것이다.
- 프로비저닝 및 배포
- 구성 및 일정 조정
- 리소스 할당
- 컨테이너 가용성
- 컨테이너 스케일링 또는 제거
- 로드 밸런싱 및 트래픽 라우팅
- 컨테이너 모니터링
- 실행된 컨테이너를 기반으로 애플리케이션 설정
- 컨테이너간 보안 유지
- 일반적으로 Docker 사용법은 하나의 호스트를 기준으로 한다.
docker ps,docker run,docker create등과 같은 명령어들은 모두 하나의 컨테이너를 대상으로 실행된다.- 하지만 실제로 도커를 운영 환경에 적용한다고 한다면, 하나의 호스트에 도커를 설치해 운영하는 것은 어렵다.
- 단일 호스트로 구성된 환경은 확장성(Scalability), 가용성(Availability), 장애 허용성(Fault Tolerance) 측면에서 많은 한계점을 가진다.
- 이를 해결하기 위해 가장 많이 사용되는 방법은 여러 대의 서버를 하나의 클러스터로 묶어 리소스를 병렬로 확장하는 것이다.
- 도커 스웜은 이처럼 서로 다른 호스트에 있는 여러 대의 컨테이너를 하나로 묶어 마치 하나의 호스트인 것처럼 사용할 수 있도록 도와주는 컨테이너 오케스트레이션 도구이다.
- 쿠버네티스만큼은 아니더라도, 여러 대의 호스트로 구성된 중소 규모의 클러스터에서 컨테이너 기반 애플리케이션 구동을 제어하기에 충분한 기능을 갖추고 있다.
- 도커 엔진이 설치된 환경이라면, 별도의 구축 비용 없이 스웜 모드를 활성화하는 것만으로도 가능하다.
- Docker compose를 사용해본 사람이라면 도커 스웜의 스택(stack)을 이용한 애플리케이션 운영에 곧바로 적응할 수 있다.
- Docker desktop으로도 클러스터 관리와 배포가 모두 가능한 단일 노드 클러스터를 바로 만들 수 있다.
- 따라서 최소한의 자원으로 컨테이너 오케스트레이션 환경을 만들어 실험해볼 수 있다.
- 여러 개의 도커 서버를 하나의 클러스터로 구성하기 위해 각종 정보를 저장하고 동기화한다.
- 각 서버를 제어하는 역할을 한다.
- 실제 컨테이너가 생성되고 관리되는 도커 서버이다.
- 워커 노드는 없을 수도 있다.
- 클러스터 내의 워커 노드를 관리하기 위한 도커 서버이다.
- 매니저 노드는 워커 노드의 역할도 포함하고 있다.
- 매니저 노드는 무조건 1개 이상 존재해야 한다.
- 도커 스웜에는 스웜 클래식, 스웜 모드 두 종류가 있다.
- 스웜 클래식은 여러 대의 도커 서버를 하나의 지점에서 사용할 수 있도록 단일 접근점을 제공한다면, 스웜 모드는 마이크로 아키텍처의 컨테이너를 다루기 위한 클러스터링 기능에 초점을 맞추고 있다.
- 스웜 모드가 서비스 확장성과 안정성 등 여러 측면에서 스웜 클래식보다 뛰어나기 때문에 일반적으로 스웜 모드를 더 많이 사용한다.
- 도커 버전 1.6 이후부터 사용할 수 있다.
docker run,docker ps등 일반적인 도커 명령어와 도커 API로 클러스터의 서버를 제어하고 관리할 수 있는 기능을 제공한다.- 분산 코디네이터, 에이전트 등을 별도로 실행해야 한다.
- 도커 버전 1.12 이후부터 사용할 수 있다.
- 같은 컨테이너를 여러개 생성해 필요에 따라 유동적으로 컨테이너의 수를 조절할 수 있으며, 컨테이너로의 연결을 분산하는 로드밸런싱 기능을 자체적으로 지원한다.
- 분산 코디네이터, 에이전트 등이 모두 도커 엔진 자체에 내장되어 있다.
| 이름 | 설명 |
|---|---|
| 노드(Node) | 클러스터를 구성하는 개별 도커 서버를 의미한다. |
| 매니저 노드(Manager Node) | • 클러스터 관리와 컨테이너 오케스트레이션을 담당한다. ◦ 쿠버네티스의 마스터 노드와 같은 역할이라고 할 수 있다. |
| 워커 노드(Worker Node) | • 컨테이너 기반 서비스들이 실제 구동되는 노드를 의미한다. ◦ 쿠버네티스와 다른 점이 있다면, Docker swarm에서는 매니저 노드도 기본적으로 워커 노드의 역할을 같이 수행할 수 있다. ◦ 스케줄링을 임의로 막는 것도 가능하다. |
| 스택(Stack) | • 하나 이상의 서비스(Service)로 구성된 다중 컨테이너 애플리케이션 묶음을 의미한다. ◦ 도커 컴포즈와 유사한 양식의 yaml 파일로 스택 배포를 진행한다. |
| 서비스(Service) | • 노드에서 수행하고자 하는 작업들을 정의해놓은 것으로, 클러스터 안에서 구동시킬 컨테이너 묶음을 정의한 객체이다. ◦ 도커 스웜에서의 기본적인 배포 단위로 취급된다. ◦ 하나의 서비스는 하나의 이미지를 기반으로 구동되며, 이들 각각이 전체 애플리케이션의 구동에 필요한 개별적인 마이크로서비스(microservice)로 기능한다. |
| 테스크(Task) | • 클러스터를 통해 서비스를 구동시킬 때, 도커 스웜은 해당 서비스의 요구 사항에 맞춰 실제 마이크로서비스가 동작할 도커 컨테이너를 구성하여 노드에 분배하는데, 이를 테스크라고 한다. ◦ 하나의 서비스는 지정된 복제본(replica) 수에 따라 여러 개의 테스크를 가질 수 있으며, 각각의 테스크에는 하나씩의 컨테이너가 포함된다. |
| 스케줄링(Scheduling) | • 서비스 명세에 따라 테스크를 노드에 분배하는 작업을 의미한다. ◦ 2022년 8월 기준으로 도커 스웜에서는 오직 균등 분배(spread) 방식만 지원하고 있다. |
# AWS 인바웃드 규칙도 편집해야한다.
sudo ufw allow {port}2377/tcp: 클러스터 관리에 사용되는 포트7946/tcp,7946/udp: 노드 간 통신에 사용되는 포트4789/udp: 클러스터에서 사용되는 Ingress 오버레이 네트워크 트래픽에 사용된다.
docker swarm init --advertise-addr { private_ip }- 매니저 호스트에 접속해 위 명령어를 입력해야한다.
docker swarm join --token { token } { private_ip }:2377
# This node joined a swarm as a worker.- 워커 호스트에 접속해 위 명령어를 입력한다.
ubuntu@ip-:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
4ekbnwh2ayfy2qo9alcarsy5q ip- Ready Active 24.0.5
f4ag8t9kczcn0sg0wzexfac3x * ip- Ready Active Leader 24.0.5
js2iuhm3i5r7qpnsrxs15ojc1 ip- Ready Active 24.0.5- 매니저 호스트에 접속해 list를 확인하면 다음과 같이 워커 노드가 추가된 것을 확인할 수 있다.
docker node ls명령어는 매니저 노드에서만 동작한다.ID값 옆에 붙은*은 조회 명령을 수행한 매니저 노드를 의미한다.
ID는 클러스터 차원에서 각 노드에 부여된 고유 값이며,HOSTNAME은 해당 노드의 이름이다.HOSTNAME은 중복이 가능하지만ID는 허용되지 않는다.- 호스트가 클러스터를 떠났다(leave)가 다시 합류(join)하는 경우 이전과 다른 새로운
ID값이 부여된다.
AVAILABILITY의 종류는 다음과 같다.Active: 정상적으로 태스크를 할당받을 수 있는 상태Pause: 스케줄러가 새로운 테스크 할당을 하지 않지만, 테스크가 구동 상태를 그대로 유지한다.Drain: 스케줄러가 새로운 테스크를 할당하지 않고, 해당 노드에서 돌아가던 테스크가 모두 종료되며,Active상태인 다른 노드로 다시 스케줄링 된다.
MANAGER STATUS의 종류는 다음과 같다.Leader: 스웜 클러스터의 관리와 오케스트레이션을 관리하는 노드이다.Reachable: 매니저 노드로서 다른 매니저 노드들과 정상적으로 통신 가능한 상태이다.- 만약
Leader노드에 장애가 발생하면, 해당 상태값을 가진 매니저 노드가 새Leader후보군이 된다.
- 만약
Unavailable:Leader를 포함한 다른 매니저 노드들과 통신이 불가능한 상태이다.
- 클러스터는 1개 이상의 매니저 노드를 가지고 있고,
**Leader로 선별된 매니저 노드가 전체 클러스터를 실질적으로 관리한다.**- 클러스터의 모든 변경 사항은 리더 노드를 통해 전파되고, 나머지 노드들이 리더 노드와 동기화된 상태를 유지한다.
docker run은 컨테이너를 새로 생성하고 구동시키는 명령어이다.- 컨테이너 이름, 이미지 이름을 지정하는 것만으로도 도커 엔진이 알아서 필요한 이미지를 내려받아 구동시킨다.
- Docker의 기본 배포 단위가 컨테이너라면, **Docker Swarm의 기본 배포 단위는 서비스(Service)**이다.
- 흔히 ‘같은 이미지에서 생성된 컨테이너의 집합’으로 알려져 있다.
- 단일 이미지 기반으로 클러스터 안에서 구동시킬 컨테이너 묶음을 정의한 객체에 더 가깝다.
- 서비스는 선언적으로 구성딘다.
- 즉, 원하는 상태를 정의하면, 도커는 그 상태를 유지하는데 필요한 작업을 지속적으로 수행한다.
- 정의할 수 있는 요소들은 다음과 같다.
- 컨테이너로 배포할 이미지의 정보
- 전체 서비스를 구성할 컨테이너의 수
- 컨테이너의 배치 형태
- 컨테이너에 붙일 볼륨 정보
- 컨테이너를 배치시킬 노드 조건
- 컨테이너의 업데이트 전략 및 정책 지정
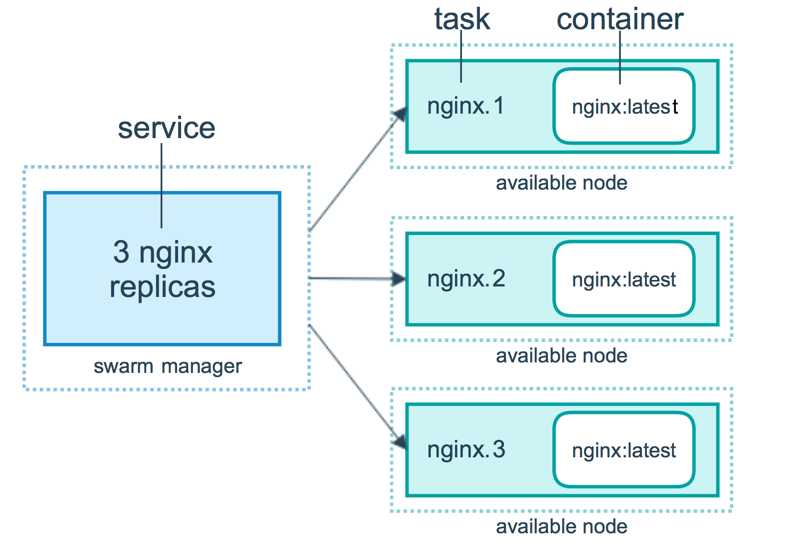
- 선언적으로 정의된 서비스의 명세에 따라 생성되어 클러스터 노드에 배치되는 개별 컨테이너의 배포 단위가 바로 테스크(Task)이다.
- 각 테스크에는
서비스명.일련번호형태의 이름이 붙게 되며, 미리 정의된 컨테이너의 수(replicas) 만큼 생성되어 가용한 노드에 제각각 배치된다. - 정의된 서비스의 명세를 스웜 매니저가 파악한 뒤, 가용한 노드에 지정된 레플리카 수 만큼의 테스크를 만들어 할당한다.
docker service create --replicas 1 --name helloworld alpine ping docker.comping docker.com명령어를 수행하는 컨테이너 서비스를 생성한다.- 서비스 생성은 매니저 호스트에서만 사용할 수 있다.
- 옵션은 다음과 같다.
--name: 서비스의 이름을 지정한다.--replicas: 서비스를 구성할 테스크(컨테이너)의 수를 지정한다. 지정된 숫자 만큼 테스크가 클러스터 노드에 배치된다.alpine ping docker.com: 테스크에 포함시킬 이미지 정보를 지정한다.
ubuntu@ip-:~$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
zpume3y3ng7r hello replicated 1/1 alpine:latest docker service ls를 입력하면 생성된 서비스 목록을 볼 수 있다.
Error response from daemon: This node is not a swarm manager.
Worker nodes can't be used to view or modify cluster state.
Please run this command on a manager node or promote the current node to a manager.- 만약 워커 호스트에서 서비스를 생성하면 다음과 같은 오류가 발생한다.
ubuntu@ip-:~$ docker service inspect --pretty helloworld
ID: m6n03eshissl401jy1ixc4j5i
Name: helloworld
Service Mode: Replicated
Replicas: 1
Placement:
UpdateConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: alpine:latest@sha256:82d1e9d7ed48a7523bdebc18cf6290bdb97b82302a8a9c27d4fe885949ea94d1
Args: ping docker.com
Init: false
Resources:
Endpoint Mode: vip
ubuntu@ip-:~$ docker service inspect helloworld
[
{
"ID": "m6n03eshissl401jy1ixc4j5i",
"Version": {
"Index": 21
},
"CreatedAt": "2023-08-02T11:35:37.50905067Z",
"UpdatedAt": "2023-08-02T11:35:37.50905067Z",
"Spec": {
"Name": "helloworld",
"Labels": {},
"TaskTemplate": {
"ContainerSpec": {
"Image": "alpine:latest@sha256:82d1e9d7ed48a7523bdebc18cf6290bdb97b82302a8a9c27d4fe885949ea94d1",
"Args": [
"ping",
"docker.com"
],
"Init": false,
"StopGracePeriod": 10000000000,
"DNSConfig": {},
"Isolation": "default"
},
"Resources": {
"Limits": {},
"Reservations": {}
},
"RestartPolicy": {
"Condition": "any",
"Delay": 5000000000,
"MaxAttempts": 0
},
"Placement": {
"Platforms": [
{
"Architecture": "amd64",
"OS": "linux"
},
{
"OS": "linux"
},
{
"OS": "linux"
},
{
"Architecture": "arm64",
"OS": "linux"
},
{
"Architecture": "386",
"OS": "linux"
},
{
"Architecture": "ppc64le",
"OS": "linux"
},
{
"Architecture": "s390x",
"OS": "linux"
}
]
},
"ForceUpdate": 0,
"Runtime": "container"
},
"Mode": {
"Replicated": {
"Replicas": 1
}
},
"UpdateConfig": {
"Parallelism": 1,
"FailureAction": "pause",
"Monitor": 5000000000,
"MaxFailureRatio": 0,
"Order": "stop-first"
},
"RollbackConfig": {
"Parallelism": 1,
"FailureAction": "pause",
"Monitor": 5000000000,
"MaxFailureRatio": 0,
"Order": "stop-first"
},
"EndpointSpec": {
"Mode": "vip"
}
},
"Endpoint": {
"Spec": {}
}
}
]docker service inspect --pretty {service_name}명령어 입력 시 서비스의 세부 정보를 볼 수 있다.--pretty옵션을 제거하면 json 형식으로 반환한다.
ubuntu@ip-:~$ docker service ps helloworld
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
xr6gphsn80x6 helloworld.1 alpine:latest docker-swarm-1 Running Running about a minute agodocker service ps {service_name}명령어 입력 시 서비스를 실행중인 노드를 확인할 수 있다.
ubuntu@docker-swarm-1:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
84c745434f77 alpine:latest "ping docker.com" 5 minutes ago Up 5 minutes helloworld.1.xr6gphsn80x6sne1gw7dpqan4- 해당 작업을 실행중인 노드에서
docker ps를 실행하면 해당 작업의 세부 정보를 확인할 수 있다.
ubuntu@ip-:~$ docker service scale helloworld=5
helloworld scaled to 5
overall progress: 5 out of 5 tasks
1/5: running
2/5: running
3/5: running
4/5: running
5/5: running
verify: Service convergeddocker service scale명령어를 사용하면 배포된 서비스의 레플리카 수를 조정할 수 있다.- 단, 도커 스웜은 쿠버네티스와 같은 오토 스케일링 기능을 제공하지 않는다.
ubuntu@ip-:~$ docker service ps helloworld
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
xr6gphsn80x6 helloworld.1 alpine:latest docker-swarm-1 Running Running 7 minutes ago
as2oomtuoxqy helloworld.2 alpine:latest docker-swarm-3 Running Running 37 seconds ago
nqtryz8kpe9t helloworld.3 alpine:latest docker-swarm-2 Running Running 36 seconds ago
h77a77vek40e helloworld.4 alpine:latest docker-swarm-2 Running Running 36 seconds ago
z88qhti23kao helloworld.5 alpine:latest docker-swarm-1 Running Running 41 seconds agodocker service ps ${service_name}를 입력하면 각 노드마다 업데이트된 작업 목록을 볼 수 있다.
docker service logs {option} {service_name}helloworld.1.xr6gphsn80x6@ip- | 64 bytes from 141.193.213.21: seq=763 ttl=46 time=2.435 ms
helloworld.1.xr6gphsn80x6@ip- | 64 bytes from 141.193.213.21: seq=764 ttl=46 time=2.361 ms
helloworld.1.xr6gphsn80x6@ip- | 64 bytes from 141.193.213.21: seq=765 ttl=46 time=2.339 ms
helloworld.1.xr6gphsn80x6@ip- | 64 bytes from 141.193.213.21: seq=766 ttl=46 time=2.409 ms
helloworld.1.xr6gphsn80x6@ip- | 64 bytes from 141.193.213.21: seq=767 ttl=46 time=2.450 ms
helloworld.1.xr6gphsn80x6@ip- | 64 bytes from 141.193.213.21: seq=768 ttl=46 time=2.373 ms
helloworld.1.xr6gphsn80x6@ip- | 64 bytes from 141.193.213.21: seq=769 ttl=46 time=2.393 ms
helloworld.1.xr6gphsn80x6@ip- | 64 bytes from 141.193.213.21: seq=770 ttl=46 time=2.464 ms
helloworld.1.xr6gphsn80x6@ip- | 64 bytes from 141.193.213.21: seq=771 ttl=46 time=2.368 ms
helloworld.1.xr6gphsn80x6@ip- | 64 bytes from 141.193.213.21: seq=772 ttl=46 time=2.365 ms- 위 명령어를 입력하면
ping docker.com서비스가 작동하는 것을 확인할 수 있다. - 설정할 수 있는 옵션으로는 다음과 같다.
--follow,-f: 로그를 콘솔에 실시간으로 계속 스트리밍하여 출력한다.--tail,-n: 로그를 가장 최근 것으로부터 몇개까지 출력시킬지 숫자로 정한다.- 만약 음수 또는 all로 지정할 경우 전체 로그를 출력한다.
--since: 지정된 시각 이후의 로그만 출력한다.--timestamp,-t: 로그의 각 줄마다 타임 스탬프를 추가하여 출력시킨다.
ubuntu@ip-:~$ docker service rm helloworld
helloworld-
관리자 노드에서 다음과 같은 명령어를 입력하면 서비스를 제거할 수 있다.
-
작업 컨테이너를 정리하는데 일정 시간이 걸리기 때문에 삭제 하고 바로 조회 시 아직 컨테이너 목록에 존재할 수 있다.
docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES db1651f50347 alpine:latest "ping docker.com" 44 minutes ago Up 46 seconds helloworld.5.9lkmos2beppihw95vdwxy1j3w 43bf6e532a92 alpine:latest "ping docker.com" 44 minutes ago Up 46 seconds helloworld.3.a71i8rp6fua79ad43ycocl4t2 5a0fb65d8fa7 alpine:latest "ping docker.com" 44 minutes ago Up 45 seconds helloworld.2.2jpgensh7d935qdc857pxulfr afb0ba67076f alpine:latest "ping docker.com" 44 minutes ago Up 46 seconds helloworld.4.1c47o7tluz7drve4vkm2m5olx 688172d3bfaa alpine:latest "ping docker.com" 45 minutes ago Up About a minute helloworld.1.74nbhb3fhud8jfrhigd7s29we docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
-
서비스가 삭제되면 서비스에 포함된 모든 테스크(컨테이너)가 노드에서 함께 제거된다.
- 단, 서비스에서 도커 볼륨을 마운트해서 사용하고 있었다면, 해당 볼륨은 별도로 삭제하지 않는 한 클러스터에 남아있게 된다.
Error response from daemon: Timeout was reached before node joined.
The attempt to join the swarm will continue in the background.
Use the "docker info" command to see the current swarm status of your node.- private가 아닌 public ip로 매니저 노드를 지정해주면 된다.
- 우분투 내부에서 port 허용, AWS 자체에서 포트를 허용해준다.
ubuntu@ip-:~$ docker service ps helloworld
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
a4vzxy4vqoux helloworld.1 alpine:latest ip- Running Running 2 hours ago
dgeqqpgl329w \_ helloworld.1 alpine:latest ip- Shutdown Failed 2 hours ago "No such container: helloworld…"
n4b623sieipy helloworld.2 alpine:latest ip- Running Running 38 seconds ago
dv6kdbneyykd helloworld.3 alpine:latest ip- Running Running 38 seconds ago-
왜 다른 노드로 클러스터 되지 않은 원인은 워커 노드가 다운되었기 때문..
ubuntu@ip-:~$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION dueqzu3vaew408t8awg6xe854 ip- Down Active 24.0.5 gb2bdfnxbqhcrqm4gqgtyxlj2 * ip- Ready Active Leader 24.0.5 dp24k5afwv6nprh0fqrty6uda ip- Down Active 24.0.5