-
Notifications
You must be signed in to change notification settings - Fork 143
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
8605419
commit f3fb1e3
Showing
21 changed files
with
402 additions
and
0 deletions.
There are no files selected for viewing
Empty file.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,17 @@ | ||
| # ESP CheatSheet | ||
|
|
||
| ESP8266,及其升级版 ESP32 系列,其本质是一个带有 Wlan 收发器的单片机,由于其内核较为冷门(Tensilica 架构 ),所以主流的开发工具几乎都不支持,目前可用的开发手段有: | ||
|
|
||
| 1.Arduino IDE,使用一种类似 C++的语言编程,多数功能已经封装好; | ||
|
|
||
| 2.刷 Node MCU 固件,使用 Lua 脚本编程,有第三方的类 IDE 工具,多数功能已经封装好; | ||
|
|
||
| 3.刷 AT 固件,将其作为从属芯片,使用额外的控制器通过串口 AT 指令来控制; | ||
|
|
||
| 4.使用官方 SDK 从底层进行开发; | ||
|
|
||
| ESP8266 是单核 Tensilica L106(32 位 MCU)的 Wi-Fi 芯片,主频最高可达 160MHz。 | ||
|
|
||
| ESP32 是双核 Tensilica L108 (32 位 MCU)的 Wi-Fi 芯片,主频更高可达 250MHz,性能更强,内存更大有 400KB SRAM。另外还集成了蓝牙 BLE。 | ||
|
|
||
| 由于 ESP32 的 MCU 性能更强,内存更大,可以处理包括音频、视频在内的更复杂 Wi-Fi 应用。还可以应用在需要蓝牙和 Wi-Fi 共存的 IOT 场景中。 |
Empty file.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,5 @@ | ||
| # 芯片 | ||
|
|
||
| # Links | ||
|
|
||
| - https://mp.weixin.qq.com/s/7-ONDI7HpRRUIc15sr2trQ |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1 @@ | ||
| > [原文地址](https://foxsen.github.io/archbase/) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,13 @@ | ||
| # CPU | ||
|
|
||
| 简而言之,计算机由连接到内存的中央处理器(CPU)组成。下图说明了所有计算机操作背后的一般原理。 | ||
|
|
||
|  | ||
|
|
||
| CPU 对寄存器中保存的值执行指令。此示例显示首先将 R1 的值设置为 100,将值从存储器位置 0x100 加载到 R2,将这两个值加在一起并将结果放入 R3,最后将新值(110)存储到 R4 以供进一步使用。CPU 执行从内存读取的指令,指令有两大类: | ||
|
|
||
| - 那些将值从存储器加载到寄存器,并将值从寄存器存储到存储器的函数。 | ||
|
|
||
| - 那些对存储在寄存器中的值进行运算的变量。例如,对两个寄存器中的值进行相加,相减或相除,执行按位运算(和,或,异或等)或执行其他数学运算(平方根,sin,cos,tan 等)。 | ||
|
|
||
| 在上面的示例中,我们仅将 100 加到存储在内存中的值,然后将此新结果存储回内存。 |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,25 @@ | ||
| # 三大定律 | ||
|
|
||
| # 摩尔定律 | ||
|
|
||
| 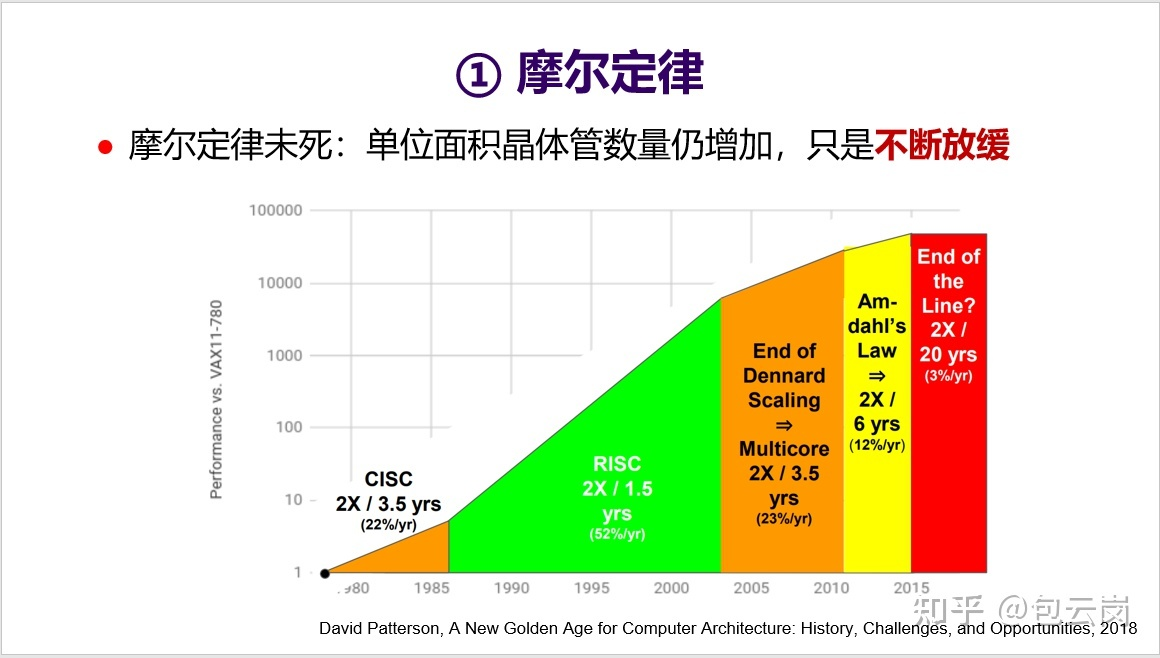 | ||
|
|
||
| ## 领域专用架构 DSA | ||
|
|
||
| 摩尔定律让芯片上的晶体管数量不断增加,但一个问题是这些晶体管都被充分用起来了吗?可以来看一下 MIT 团队开展的一个小实验(见下面 PPT):假设用 Python 实现一个矩阵乘法的性能是 1,那么用 C 语言重写后性能可以提高 50 倍,如果再充分挖掘体系结构特性(如循环并行化、访存优化、SIMD 等),那么性能甚至可以提高 63000 倍。然而,真正能如此深入理解体系结构、写出这种极致性能的程序员绝对是凤毛麟角。问题是这么大的性能差异到底算好还是坏?从软件开发角度来看,这显然不是好事。这意味着大多数程序员无法充分发挥 CPU 的性能,无法充分利用好晶体管。这不能怪程序员,更主要还是因为 CPU 微结构太复杂了,导致软件难以发挥出硬件性能。如何解决这个问题?领域专用架构 DSA(Domain-Specific Architecture)就是一个有效的方法。DSA 可以针对特定领域应用程序,定制微结构,从而实现数量级提高性能功耗比。这相当于是把顶尖程序员的知识直接实现到硬件上。 | ||
|
|
||
| 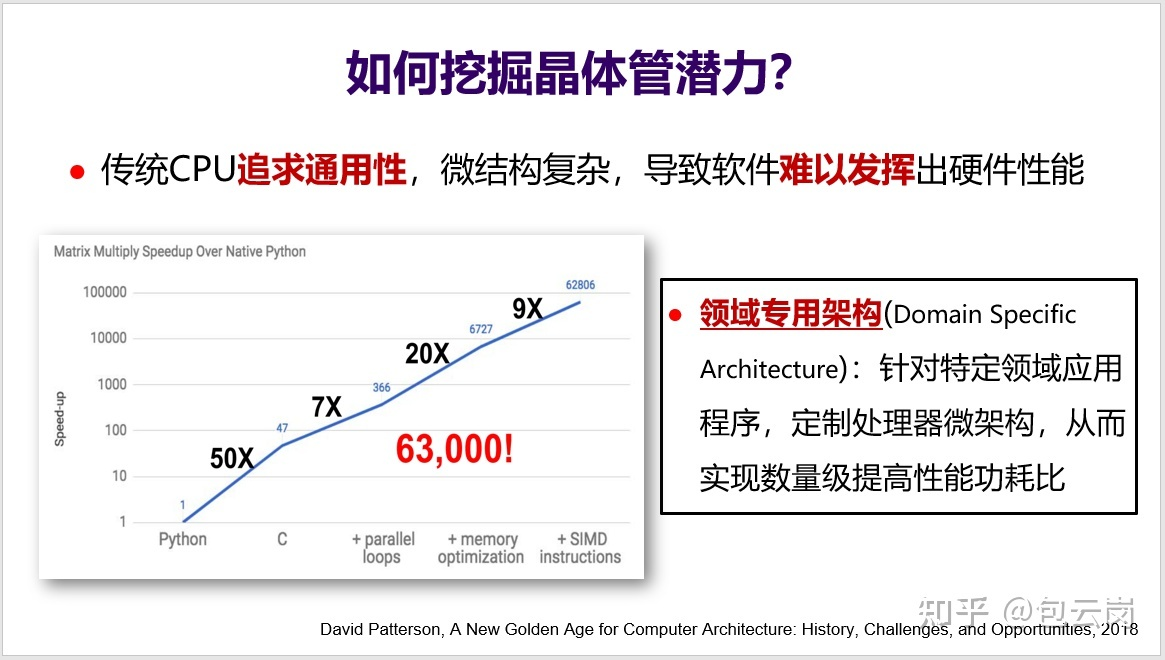 | ||
|
|
||
| # 牧本定律 | ||
|
|
||
| 1987 年,原日立公司总工程师牧本次生(Tsugio Makimoto,也有翻译为牧村次夫,故称为“牧村定律”) 提出,半导体产品发展历程总是在“标准化”与“定制化”之间交替摆动,大概每十年波动一次。牧本定律背后是性能功耗和开发效率之间的平衡。对于处理器来说,就是专用结构和通用结构之间的平衡。最近这一波开始转向了追求性能功耗,于是专用结构开始更受关注。 | ||
|
|
||
| 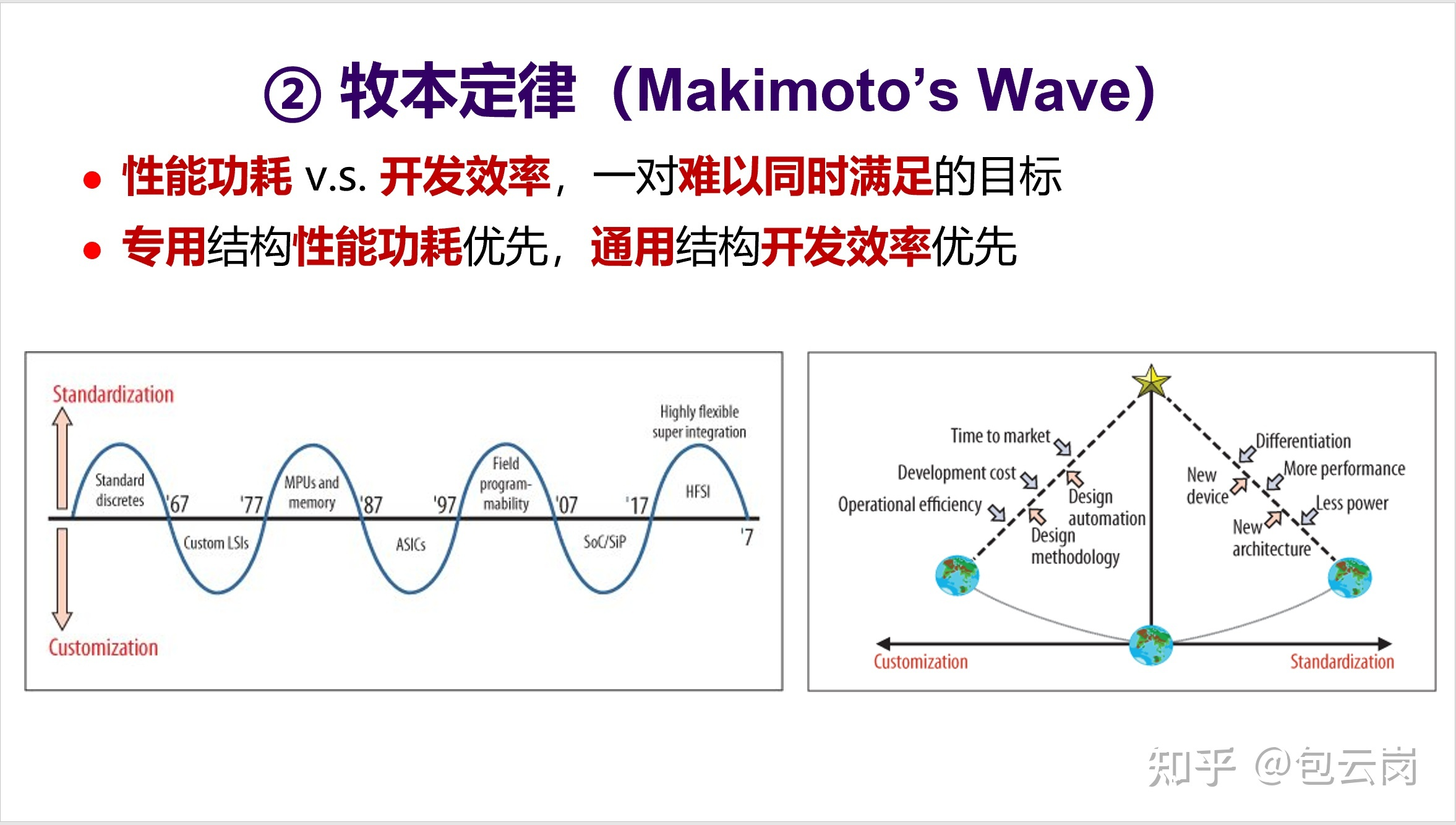 | ||
|
|
||
| # 贝尔定律 | ||
|
|
||
| 这是 Gordon Bell 在 1972 年提出的一个观察,具体内容如下面的 PPT 所述。值得一提的是超级计算机应用最高奖“戈登·贝尔奖”就是以他的名字命名。 | ||
|
|
||
| 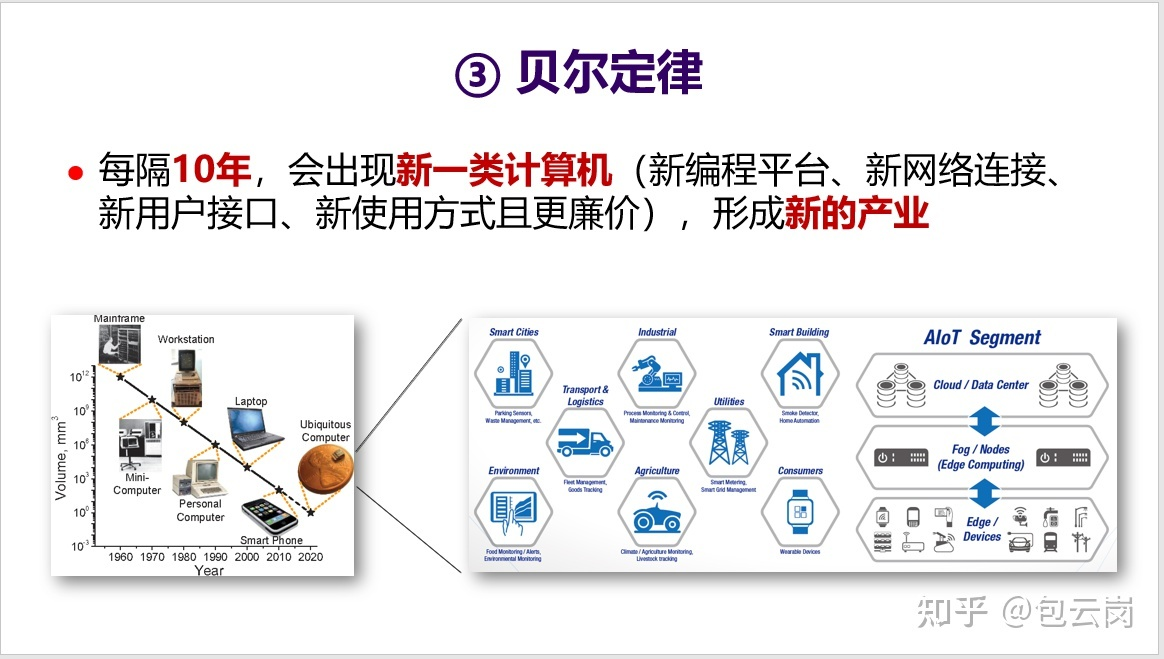 | ||
|
|
||
| 贝尔定律指明了未来一个新的发展趋势,也就是 AIoT 时代的到来。这将会是一个处理器需求再度爆发的时代,但同时也会是一个需求碎片化的时代,不同的领域、不同行业对芯片需求会有所不同,比如集成不同的传感器、不同的加速器等等。如何应对碎片化需求?这又将会是一个挑战。 |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,5 @@ | ||
| # CPU 作业调度 | ||
|
|
||
| # Links | ||
|
|
||
| - https://mp.weixin.qq.com/s/kyTZsJBQmk75A58uReabww 深入理解 CPU 的调度原理 |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,84 @@ | ||
| # 指令基础 | ||
|
|
||
| ## Branching | ||
|
|
||
| 除了加载或存储,CPU 的另一个重要操作是分支。在内部,CPU 在指令指针中保留要执行的下一条指令的记录。通常,指令指针递增以顺序指向下一条指令。分支指令通常将检查特定寄存器是否为零或是否设置了标志,如果是,则将指针修改为另一个地址。因此,下一条要执行的指令将来自程序的不同部分。这就是循环和决策语句的工作方式。 | ||
|
|
||
| 例如,可以通过查找两个寄存器中的或来实现类似 if(x == 0)的语句,其中一个保存 x,另一个保存零。如果结果为零,则比较为真(即 x 的所有位均为零),并且应采用语句的主体,否则分支通过主体代码。 | ||
|
|
||
| ## Cycles | ||
|
|
||
| 我们都熟悉以兆赫兹或千兆赫兹(每秒数百万或数亿个周期)给出的计算机速度。之所以称为时钟速度,是因为它是计算机内部时钟的脉动速度。 | ||
|
|
||
| 在处理器内使用脉冲以保持其内部同步。在每个滴答声或脉冲时,可以开始另一种操作;就像时钟拍打鼓的人一样,使划船者的桨保持同步。 | ||
|
|
||
| # Fetch, Decode, Execute, Store | ||
|
|
||
| 执行一条指令包括一个特定的事件周期。提取,解码,执行和存储。例如,要在 CPU 上方执行添加指令,必须 | ||
|
|
||
| - 提取:将指令从内存中获取到处理器中。 | ||
|
|
||
| - 解码:内部解码它要做的事情(在本例中为 add)。 | ||
|
|
||
| - 执行:从寄存器中获取值,然后将它们实际相加 | ||
|
|
||
| - 存储:将结果存储回另一个寄存器(Retiring the instruction)。 | ||
|
|
||
| ## CPU 内部结构 | ||
|
|
||
| 在内部,CPU 具有执行上述每个步骤的许多不同子组件,通常它们可以彼此独立工作。这类似于物理生产线,那里有许多工作站,每个步骤都有特定的任务要执行。完成后,它可以将结果传递到下一个测站,并接受新的输入进行处理。 | ||
|
|
||
|  | ||
|
|
||
| 您可以看到指令进入并被处理器解码。CPU 有两种主要类型的寄存器,用于整数计算的寄存器和用于浮点计算的寄存器。浮点数是一种以二进制形式用小数位表示数字的方式,并且在 CPU 中的处理方式有所不同。MMX(多媒体扩展)和 SSE(流单指令多数据)或 Altivec 寄存器类似于浮点寄存器。 | ||
|
|
||
| 寄存器文件是 CPU 内部寄存器的统称。在此之下,我们拥有真正完成所有工作的 CPU 部分。我们说过,处理器要么将一个值加载或存储到寄存器中,要么从一个寄存器加载到内存中,或者对寄存器中的值进行某些操作。 | ||
|
|
||
| 算术逻辑单元(Arithmetic Logic Unit, ALU)是 CPU 操作的核心。它获取寄存器中的值并执行 CPU 能够执行的多种操作。所有现代处理器都有许多 ALU,因此每个都可以独立工作。实际上,奔腾等处理器同时具有快速和慢速 ALU。快速的 ALU 较小(因此您可以在 CPU 上容纳更多),但只能执行最常见的操作,而慢速的 ALU 可以执行所有操作,但更大。 | ||
|
|
||
| 地址生成单元(Address Generation Unit, AGU)处理与高速缓存和主存储器的对话,以将值获取到寄存器中,以供 ALU 进行操作,并将值从寄存器中获取并返回主存储器。浮点寄存器的概念相同,但其组件使用的术语略有不同。 | ||
|
|
||
| ## Pipeling | ||
|
|
||
| 正如我们在上面看到的,当 ALU 将寄存器加在一起时,与 AGU 将值完全写回内存完全分开,因此没有理由 CPU 不能同时执行这两个操作。我们的系统中还有多个 ALU,每个 ALU 都可以处理独立的指令。最终,CPU 可能会使用其浮点逻辑来执行一些浮点运算,而整数指令也在运行中。这个过程称为流水线,可以做到这一点的处理器称为超标量架构。所有现代处理器都是超标量的。 | ||
|
|
||
| 另一个比喻可能是将管道想象为填充大理石的软管,除非大理石是 CPU 的指令。理想情况下,您将大理石放在一端,另一端(每个时钟脉冲一个),填满管道。一旦装满,对于每一个弹子(指令),您推入所有其他弹子将移至下一个位置,一个弹子将掉出末端(结果)。 | ||
|
|
||
| 但是,分支指令会对这种模型造成严重破坏,因为它们可能会或可能不会导致执行从另一个地方开始。如果您正在流水线工作,则基本上必须猜测分支将走的路,因此您知道将哪些指令带入管道。相反,如果处理器的预测不正确,则一切正常。相反,如果处理器的预测不正确,则会浪费大量时间,必须清理管道并重新启动。此过程通常称为管道冲洗,类似于必须停止并清空软管中的所有弹珠。 | ||
|
|
||
| ## Reordering | ||
|
|
||
| 实际上,如果 CPU 是软管,则可以自由排序软管中的弹子,只要它们以与放入它们相同的顺序弹出末端即可。我们将其称为程序顺序,因为这是在计算机程序中给出指令的顺序。 | ||
|
|
||
| ```s | ||
| 1: r3 = r1 * r2 | ||
| 2: r4 = r2 + r3 | ||
| 3: r7 = r5 * r6 | ||
| 4: r8 = r1 + r7 | ||
| ``` | ||
|
|
||
| 指令 2 需要等待指令 1 完全完成才能开始。这意味着管道在等待计算值时必须停顿。类似地,指令 3 和 4 也依赖于 r7。但是,指令 2 和 3 完全没有依赖性。这意味着它们在完全独立的寄存器上运行。如果我们交换指令 2 和 3,由于处理器可以做有用的工作,而不是等待流水线完成以获得上一条指令的结果,因此可以更好地对流水线进行排序。 | ||
|
|
||
| 但是,在编写非常底层的代码时,某些指令可能需要一些有关操作顺序的安全性。我们称这种需求记忆语义。如果您需要获取语义,这意味着对于此说明,您必须确保所有先前说明的结果均已完成。如果您需要发布语义,则是说此之后的所有指令都必须查看当前结果。另一个更为严格的语义是内存屏障或内存屏障,它要求操作在继续之前已提交给内存。 | ||
|
|
||
| 在某些体系结构上,处理器可以为您保证这些语义,而在另一些体系结构上,则必须明确指定它们。尽管您可能会看到这些术语,但大多数程序员无需直接担心它们。 | ||
|
|
||
| # CISC v RISC | ||
|
|
||
| 划分计算机体系结构的常见方法是复杂指令集计算机(CISC)和精简指令集计算机(RISC)。在第一个示例中,我们已将值显式加载到寄存器中,执行了加法运算并将保存在另一个寄存器中的结果值存储回内存。这是 RISC 计算方法的示例-仅对寄存器中的值执行运算,并显式地将值加载到存储器中或从存储器中存储值。 | ||
|
|
||
| CISC 方法可能只是一条指令,该指令从内存中获取值,在内部执行加法并将结果写回。这意味着指令可能需要花费很多时间,但是最终两种方法都达到了相同的目标。所有现代架构都可以看做 RISC 架构: | ||
|
|
||
| - 尽管 RISC 使汇编编程变得更加复杂,但是由于几乎所有程序员都使用高级语言,而将汇编代码的生成工作留给了编译器,因此其他优点胜过了这个缺点。 | ||
|
|
||
| - 因为 RISC 处理器中的指令要简单得多,所以芯片内部有更多的寄存器空间。从内存层次结构中我们知道,寄存器是最快的内存类型,最终所有指令都必须对寄存器中保存的值执行,因此在其他条件相同的情况下,更多的寄存器将导致更高的性能。 | ||
|
|
||
| - 由于所有指令都在同一时间执行,因此可以进行流水线操作。我们知道流水线化要求将指令流不断地输入到处理器中,因此,如果某些指令花费很长时间而另一些指令却不需要,流水线就变得很复杂,无法有效执行。 | ||
|
|
||
| ## EPIC | ||
|
|
||
| 在本书的许多示例中都使用过的 Itanium 处理器是经过修改的架构的示例,该架构称为“显式并行指令计算”。我们已经讨论了超标度处理器如何具有在处理器的不同部分中同时运行着许多指令的流水线。显然,为使此功能正常工作,应按照可以充分利用 CPU 可用元素的顺序为处理器提供可能的指令。 | ||
|
|
||
| 传统上组织进入的指令流是硬件的工作。程序按顺序发布指令;处理器必须向前看,并尝试做出有关如何组织传入指令的决定。EPIC 背后的理论是,在更高级别上有更多可用信息,这些信息可以使这些决策比处理器更好。像当前处理器一样,分析汇编语言指令流会丢失程序员可能在原始源代码中提供的许多信息。可以将其视为研究莎士比亚戏剧和阅读相同剧本的 Cliff's Notes 版本之间的区别。两者都能为您提供相同的结果,但是原始图像具有各种额外的信息,可以设置场景并深入了解角色。 | ||
|
|
||
| 因此,订购指令的逻辑可以从处理器转移到编译器。这意味着编译器编写者需要更聪明地尝试为处理器找到最佳的代码顺序。由于处理器的许多工作已移交给编译器,因此处理器也得到了显着简化。 |
3 changes: 3 additions & 0 deletions
3
00~计算机体系结构/GPU/99~参考资料/2024~Demystifying GPU Compute Architectures.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,3 @@ | ||
| > [原文地址](https://thechipletter.substack.com/p/demystifying-gpu-compute-architectures) | ||
| # Demystifying GPU Compute Architectures |
Oops, something went wrong.