Using VDK DAGs to orchestrate data jobs
DAGs allow VDK users to schedule jobs in a directed acyclic graph. This means that jobs can be configured to run only when a set of previous jobs have finished successfully.
In this example we will use the Versatile Data Kit to develop four Data jobs - two of these jobs will read data from separate json files, and will subsequently insert the data into Trino tables. The third job will read the data inserted by the previous two jobs, and will print the data to the terminal. The fourth Data Job will be a DAG which will manage the other three and ensure that the third job runs only when the previous two finish successfully.
The DAG uses a separate job input object separate from the one usually used for job operations in VDK Data Jobs and must be imported.
The graph for our DAG will look like this:
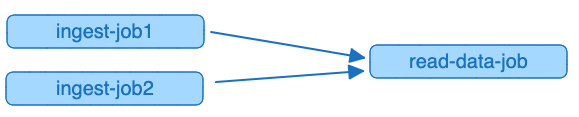
Before you continue, make sure you are familiar with the Getting Started section of the wiki.
The relevant Data Job code is available here.
You can follow along and run this DAG on your machine; alternatively, you can use the available code as a template and extend it to make a DAG that fits your use case more closely.
We will use two json files which store some data about fictional people: their names, city and country, where they live, and their phone numbers.
To run this example, you need
- Versatile Data Kit
- Trino DB
-
vdk-trino- VDK plugin for a connection to a Trino database -
vdk-dag- VDK plugin for DAG functionality
If you have not done so already, you can install Versatile Data Kit and the plugins required for this example by running the following commands from a terminal:
pip install quickstart-vdk
pip install vdk-dagNote that Versatile Data Kit requires Python 3.7+. See the See the main guide for getting started with quickstart-vdk for more details. Also, make sure to install quickstart-vdk in a separate Python virtual environment.
This example also requires Trino DB installed. See the Trino Official Documentation for more details about installation.
Please note that this example requires deploying Data jobs in a Kubernetes environment, which means that you would also need to install the VDK Control Service.
Prerequisites:
Then run:
vdk server --installOur three Datajobs have the following structure:
ingest-job1/
├── 01_drop_table.sql
├── 10_insert_data.py
├── config.ini
├── data.json
├── requirements.txt
01_drop_table.sql
drop table if exists memory.default.test_dag_one10_insert_data.py
import json
import pathlib
from vdk.api.job_input import IJobInput
def run(job_input: IJobInput):
data_job_dir = pathlib.Path(job_input.get_job_directory())
data_file = data_job_dir / "data.json"
if data_file.exists():
with open(data_file) as f:
data = json.load(f)
rows = [tuple(i.values()) for i in data]
insert_query = """
INSERT INTO memory.default.test_dag_one VALUES
""" + ", ".join(str(i) for i in rows)
job_input.execute_query(
"""
CREATE TABLE IF NOT EXISTS memory.default.test_dag_one
(
id varchar,
first_name varchar,
last_name varchar,
city varchar,
country varchar,
phone varchar
)
"""
)
job_input.execute_query(insert_query)
print("Success! The data was send trino.")
else:
print("No data File Available! Exiting job execution!")config.ini
; Supported format: https://docs.python.org/3/library/configparser.html#supported-ini-file-structure
; This is the only file required to deploy a Data Job.
; Read more to understand what each option means:
; Information about the owner of the Data Job
[owner]
; Team is a way to group Data Jobs that belonged to the same team.
team = my-team
; Configuration related to running data jobs
[job]
db_default_type = TRINOdata.json
[{"id":"18","FirstName":"Michelle","LastName":"Brooks","City":"New York","Country":"USA","Phone":"+1 (212) 221-3546"},{"id":"19","FirstName":"Tim","LastName":"Goyer","City":"Cupertino","Country":"USA","Phone":"+1 (408) 996-1010"},{"id":"20","FirstName":"Dan","LastName":"Miller","City":"Mountain View","Country":"USA","Phone":"+ 1(650) 644 - 3358"},{"id":"21","FirstName":"Kathy","LastName":"Chase","City":"Reno","Country":"USA","Phone":"+1 (775) 223-7665"},{"id":"22","FirstName":"Heather","LastName":"Leacock","City":"Orlando","Country":"USA","Phone":"+1 (407) 999-7788"},{"id":"23","FirstName":"John","LastName":"Gordon","City":"Boston","Country":"USA","Phone":"+1 (617) 522-1333"},{"id":"24","FirstName":"Frank","LastName":"Ralston","City":"Chicago","Country":"USA","Phone":"+1 (312) 332-3232"},{"id":"25","FirstName":"Victor","LastName":"Stevens","City":"Madison","Country":"USA","Phone":"+1 (608) 257-0597"},{"id":"26","FirstName":"Richard","LastName":"Cunningham","City":"Fort Worth","Country":"USA","Phone":"+1 (817) 924-7272"},{"id":"27","FirstName":"Patrick","LastName":"Gray","City":"Tucson","Country":"USA","Phone":"+1 (520) 622-4200"},{"id":"28","FirstName":"Julia","LastName":"Barnett","City":"Salt Lake City","Country":"USA","Phone":"+1 (801) 531-7272"},{"id":"29","FirstName":"Robert","LastName":"Brown","City":"Toronto","Country":"Canada","Phone":"+1 (416) 363-8888"},{"id":"30","FirstName":"Edward","LastName":"Francis","City":"Ottawa","Country":"Canada","Phone":"+1 (613) 234-3322"}]requirements.txt
vdk-trino
ingest-job2/
├── 01_drop_table.sql
├── 10_insert_data.py
├── config.ini
├── data.json
├── requirements.txt
01_drop_table.sql
drop table if exists memory.default.test_dag_two10_insert_data.py
import json
import pathlib
from vdk.api.job_input import IJobInput
def run(job_input: IJobInput):
data_job_dir = pathlib.Path(job_input.get_job_directory())
data_file = data_job_dir / "data.json"
if data_file.exists():
with open(data_file) as f:
data = json.load(f)
rows = [tuple(i.values()) for i in data]
insert_query = """
INSERT INTO memory.default.test_dag_two VALUES
""" + ", ".join(str(i) for i in rows)
job_input.execute_query(
"""
CREATE TABLE IF NOT EXISTS memory.default.test_dag_two
(
id integer,
first_name varchar,
last_name varchar,
city varchar,
country varchar,
phone varchar
)
"""
)
job_input.execute_query(insert_query)
print("Success! The data was send trino.")
else:
print("No data File Available! Exiting job execution!")config.ini
; Supported format: https://docs.python.org/3/library/configparser.html#supported-ini-file-structure
; This is the only file required to deploy a Data Job.
; Read more to understand what each option means:
; Information about the owner of the Data Job
[owner]
; Team is a way to group Data Jobs that belonged to the same team.
team = my-team
; Configuration related to running data jobs
[job]
db_default_type = TRINOdata.json
[{"id": 31, "FirstName": "Martha", "LastName": "Silk", "City": "Halifax", "Country": "Canada", "Phone": "+1 (902) 450-0450"}, {"id": 32, "FirstName": "Aaron", "LastName": "Mitchell", "City": "Winnipeg", "Country": "Canada", "Phone": "+1 (204) 452-6452"}, {"id": 33, "FirstName": "Ellie", "LastName": "Sullivan", "City": "Yellowknife", "Country": "Canada", "Phone": "+1 (867) 920-2233"}, {"id": 34, "FirstName": "Jo\u00e3o", "LastName": "Fernandes", "City": "Lisbon", "Country": "Portugal", "Phone": "+351 (213) 466-111"}, {"id": 35, "FirstName": "Madalena", "LastName": "Sampaio", "City": "Porto", "Country": "Portugal", "Phone": "+351 (225) 022-448"}, {"id": 36, "FirstName": "Hannah", "LastName": "Schneider", "City": "Berlin", "Country": "Germany", "Phone": "+49 030 26550280"}, {"id": 37, "FirstName": "Fynn", "LastName": "Zimmermann", "City": "Frankfurt", "Country": "Germany", "Phone": "+49 069 40598889"}, {"id": 38, "FirstName": "Niklas", "LastName": "Schr\u00f6der", "City": "Berlin", "Country": "Germany", "Phone": "+49 030 2141444"}, {"id": 39, "FirstName": "Camille", "LastName": "Bernard", "City": "Paris", "Country": "France", "Phone": "+33 01 49 70 65 65"}, {"id": 40, "FirstName": "Dominique", "LastName": "Lefebvre", "City": "Paris", "Country": "France", "Phone": "+33 01 47 42 71 71"}, {"id": 41, "FirstName": "Marc", "LastName": "Dubois", "City": "Lyon", "Country": "France", "Phone": "+33 04 78 30 30 30"}, {"id": 42, "FirstName": "Wyatt", "LastName": "Girard", "City": "Bordeaux", "Country": "France", "Phone": "+33 05 56 96 96 96"}, {"id": 43, "FirstName": "Isabelle", "LastName": "Mercier", "City": "Dijon", "Country": "France", "Phone": "+33 03 80 73 66 99"}, {"id": 44, "FirstName": "Terhi", "LastName": "H\u00e4m\u00e4l\u00e4inen", "City": "Helsinki", "Country": "Finland", "Phone": "+358 09 870 2000"}, {"id": 45, "FirstName": "Ladislav", "LastName": "Kov\u00e1cs", "City": "Budapest", "Country": "Hungary", "Phone": "+123 123 456"}, {"id": 46, "FirstName": "Hugh", "LastName": "OReilly", "City": "Dublin", "Country": "Ireland", "Phone": "+353 01 6792424"}]requirements.txt
vdk-trino
read-data-job/
├── 10_transform.py
├── 20_drop_table_one.sql
├── 30_drop_table_two.sql
├── config.ini
├── requirements.txt
10_read.py
from vdk.api.job_input import IJobInput
def run(job_input: IJobInput):
job1_data = job_input.execute_query(
"SELECT * FROM memory.default.test_dag_one"
)
job2_data = job_input.execute_query(
"SELECT * FROM memory.default.test_dag_two"
)
print(
f"Job 1 Data ===> {job1_data} \n\n\n Job 2 Data ===> {job2_data}"
)20_drop_table_one.sql
drop table if exists memory.default.test_dag_one30_drop_table_two.sql
drop table if exists memory.default.test_dag_twoconfig.ini
; Supported format: https://docs.python.org/3/library/configparser.html#supported-ini-file-structure
; This is the only file required to deploy a Data Job.
; Read more to understand what each option means:
; Information about the owner of the Data Job
[owner]
; Team is a way to group Data Jobs that belonged to the same team.
team = my-team
; Configuration related to running data jobs
[job]
db_default_type = TRINOrequirements.txt
vdk-trino
example-dag/
├── example_dag.py
├── config.ini
├── requirements.txt
example_dag.py
from vdk.plugin.dag.dag_runner import DagInput
JOBS_RUN_ORDER = [
{
"job_name": "ingest-job1",
"team_name": "my-team",
"fail_dag_on_error": True,
"depends_on": []
},
{
"job_name": "ingest-job2",
"team_name": "my-team",
"fail_dag_on_error": True,
"depends_on": []
},
{
"job_name": "read-data-job",
"team_name": "my-team",
"fail_dag_on_error": True,
"depends_on": ["ingest-job1", "ingest-job2"]
},
]
def run(job_input):
DagInput().run_dag(JOBS_RUN_ORDER)Note that the run_dag method belongs to the DagInput object which must be imported
and instantiated separately from the default IJobInput object which is passed to the run function by default.
config.ini
; Supported format: https://docs.python.org/3/library/configparser.html#supported-ini-file-structure
; This is the only file required to deploy a Data Job.
; Read more to understand what each option means:
; Information about the owner of the Data Job
[owner]
; Team is a way to group Data Jobs that belonged to the same team.
team = my-teamrequirements.txt
vdk-dag
Note that the VDK DAG does not require the vdk-trino dependency.
Component jobs are responsible for their own dependencies, and the DAG only handles their triggering.
After starting vdk-server, you now have a local kubernetes cluster and Versatile Data Kit Control Service installation. This means that you can now deploy the data jobs created in the previous step.
To do so, open a terminal, navigate to the parent directory of the data job folders that you have created, and type the following commands one by one:
vdk create -n ingest-job1 -t my-team --no-template -u http://localhost:8092 && \
vdk deploy -n ingest-job1 -t my-team -p ingest-job1 -r "dag-example" -u http://localhost:8092vdk create -n ingest-job2 -t my-team --no-template -u http://localhost:8092 && \
vdk deploy -n ingest-job2 -t my-team -p ingest-job2 -r "dag-example" -u http://localhost:8092vdk create -n read-job -t my-team --no-template -u http://localhost:8092 && \
vdk deploy -n read-job -t my-team -p read-job -r "dag-example" -u http://localhost:8092vdk create -n example-dag -t my-team --no-template -u http://localhost:8092 && \
vdk deploy -n example-dag -t my-team -p example-dag -r "dag-example" -u http://localhost:8092You can now run your DAG through the Execution API by using the following command:
vdk execute --start -n example-dag -t my-team -u http://localhost:8092Alternatively, if you would like your DAG to run on a set schedule, you can configure its cron schedule in its config.ini file as you would with any other Data Job.
You can find a list of all Versatile Data Kit examples here.