Repackage toolkit
This page is my notes about breaking up toolkit into several WAR files. At the moment they are to be:
Admin
testclient
simulator support
simulators
query/retrieve
submissions
Each part, what I'm calling assemblies for the moment, will be a separate build generating a separate WAR file. I'm still looking at what mechanism to use for communication between. The motivation is two-fold: modularization and build time. The overall build time has gotten too big and I want to be able to build a part of toolkit on its own in development. Deployment will likely continue to be in a single huge WAR. We will see. The build time killer is the compiling of GWT code into Javascript. Each assembly will have its own UI parts in its build.
Each assembly will have its own maven build. There will be two master builds - one that builds all the assemblies an a second that builds one big WAR.
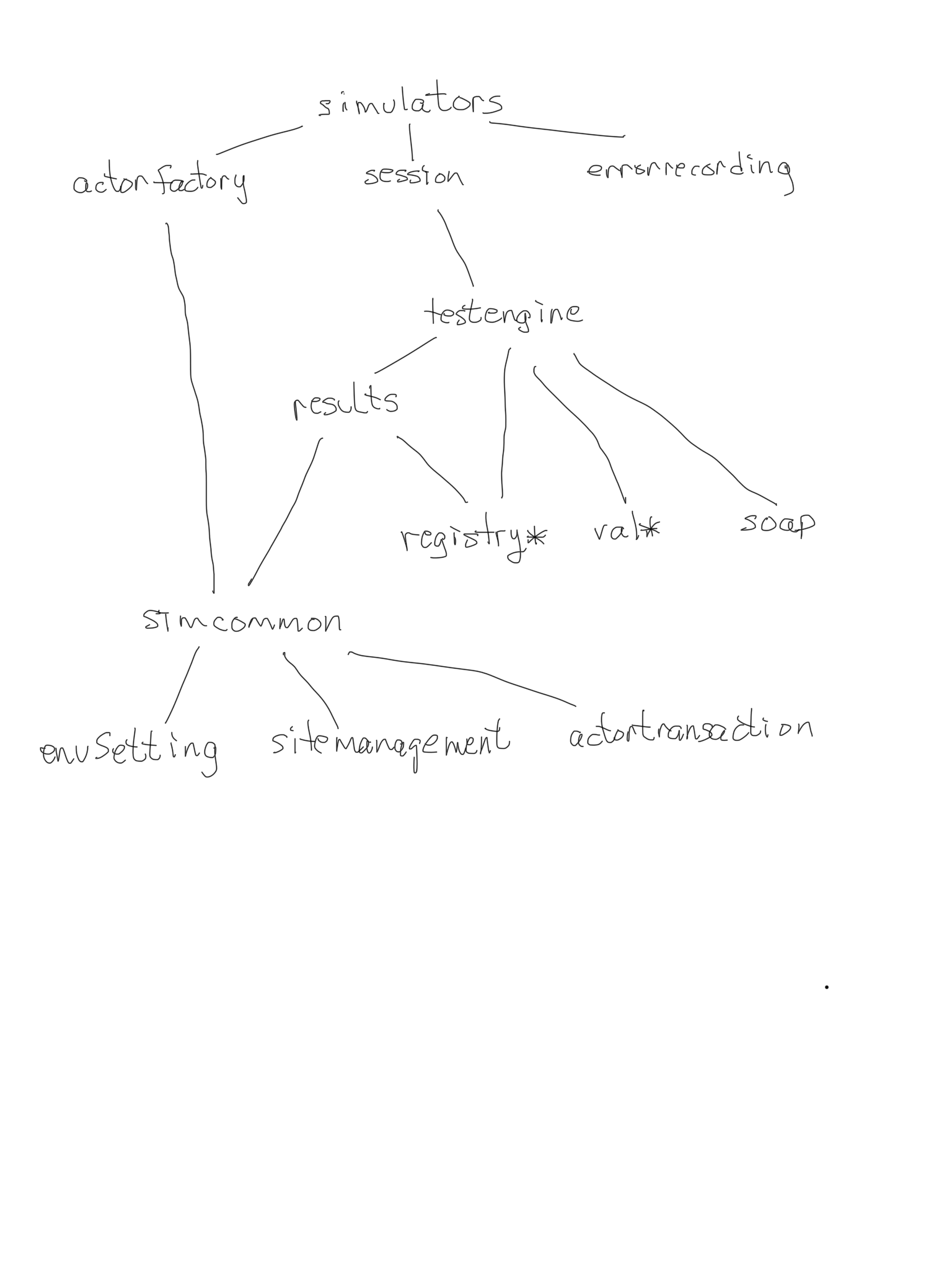
I just committed a bunch of changes that include restructuring a lot of dependencies. For the first time we have a simple dependency graph which is below.
What is not shown is the collection of modules I think of a supporting modules, things that everybody needs. They are
configDatatypes
docref
http
installation
tk
utilities
xdsexception
It may be useful to combine these into a single module but I have no plans at the moment.
Also there are a collection of modules which are empty are not useful any more. They are not in the maven build and will be deleted at some time. There are 30 of them. I won't bother listing them here.
In the diagram below, notice that simulators depends on testengine. This is because a server (simulator) after it receives a transaction frequently needs to send a secondary transaction so someone else.
Getting this organized is helpful since one of the things we need to do is break down toolkit into a small collection of individually build-able units. It is likely these units will be connected by messaging.
I have a list of use cases for motivating this work. First is the need to continue the upgrade of the GUI. With the need to keep everything working all the time it is hard to do new things. New things frequently require new structures and are risky to the current code base. If they could be separate builds and separate WARs then we could have two versions concurrently. It would be nice to field, for example, the current version of the Conformance tool and a new improved one and use them side by side. In the current code base that is not possible. The new UI structure, which works well but is hidden on its own branch, is a candidate for this approach.
The overall approach is called micro services. There are many ways to organize a code base to transition it to micro services. I have developed some ideas.
First I think the Conformance tool needs to be its own service. Next there could be services aligned around the major databases we use. Actors, simulators, test client are good candidates.
What needs to happen to make a baby step towards this. Well, the code organization below is the first. Next is that the UI code needs to be separated from the server code so that there are server modules and client modules. No mixed modules. I am thinking of using a naming convention of having a module end with -ui if it holds client code. The server modules will end up depending on client modules obviously.
Next we need a way for server modules to communicate. A common way is to use REST calls. Groovy has great support for this and when I get a chance I will build a small isolated prototype. I have found some good examples online.
Each service will expose an SPI that defines it. As we progress in this direction it is common to have a factory class that can generate two versions of the SPI: one that calls local code (compiled into this WAR) and the other that calls remote code (build into another WAR). This duality helps in the transition.
Next the REST calls need to be able to easily expose methods of the interface that are tied to the underlying code base.
For this all to work there must be a small collection of services and the interfaces must be very well defined, understood, and documented.
The next steps I will be engaging in will start with the prototyping of the REST call package. This needs to be both the server side to expose an SPI and the client side to use it. Next is the partitioning off of the client code. Server packages will include client packages since there is shared code there. A possibility is that client-only code and shared code will move into separate packages. I haven't thought that through yet. The next step is to pick a single bundle of code and package it as a service. The module sitemanagment is a good candidate. This means that creating, retrieving, editing system definitions would be the focus of its SPI.
So, how does all this fit into the plans to add FHIR support and what I have been calling workflow? FHIR support will move forward ahead of this. I think workflow depends on this. Not sure yet but the need to be able to field multiple versions of a tool in the same distribution is something I think we need to make progress with workflow.
The validation subsystem will need to be a service.
BTW, the structure shown below, for now, only exists on the feature/fhir branch.