4. Classification and Regression
A segment classification functionality is provided in the library, in order to train and use supervised models that classify an unknown audio segment to a set of predefined classes (e.g. music and speech).
Towards this end, the audioTrainTest.py file implements the following types of classifiers:
- k Nearest Neighbor kNN (implemented in the library itself)
- Support Vector Machines
- Random forests
- Extra trees
- Gradient boosting
Before proceeding to specific-purpose functionalities, let us describe the following general functions available in audioTrainTest.py, used for classification tasks:
-
classifier_wrapper(): classify an unknown sample -
random_split_features(): performs random splitting of feature data to training and testing. To be used in the context of a repeated random sampling validation process. -
train_knn(),train_svm(),train_extra_trees(),train_random_forest()andtrain_gradient_boosting(): train a kNN, SVM (linear kernel), SVM (RBF kernel), ExtraTree, Random Forest or Gradient Boosting model respectivelly using features and mappings to class labels. -
normalize_features(): normalizes a feature dataset to zero-mean and one-std -
load<methodName>Model()loads classificaton model from file
Below, we describe how to train a segment classifier from data (i.e. segments stored in WAV files, organized in directories that correspond to classes).
The function used for this purpose is feature_extraction_train(listOfDirs, mtWin, mtStep, stWin, stStep, classifierType, modelName, computeBEAT) from audioTrainTest.py.
The first argument is list of paths of directories. Each directory contains a signle audio class whose samples are stored in seperate WAV files.
Then, the function takes the mid-term window size and step and the short-term window size and step respectively.
The arguments classifierType and modelName are associated to the classifier type and name.
The latest is also used as a name of the file where the model is stored for future use (see next sections on classification and segmentation).
Finally, the last argument is a boolean, set to True if the long-term beat-related features are to be calculated (e.g. for music classification tasks).
In addition, an ARFF file is also created (with the same name as the model), where the whole set of feature vectors and respective class labels are stored.
Example:
from pyAudioAnalysis import audioTrainTest as aT
aT.feature_extraction_train(["/home/tyiannak/Desktop/MusicGenre/Classical/","/home/tyiannak/Desktop/MusicGenre/Electronic/","/home/tyiannak/Desktop/MusicGenre/Jazz/"], 1.0, 1.0, aT.shortTermWindow, aT.shortTermStep, "svm", "svmMusicGenre3", True)
aT.feature_extraction_train(["/home/tyiannak/Desktop/MusicGenre/Classical/","/home/tyiannak/Desktop/MusicGenre/Electronic/","/home/tyiannak/Desktop/MusicGenre/Jazz/"], 1.0, 1.0, aT.shortTermWindow, aT.shortTermStep, "knn", "knnMusicGenre3", True)
aT.feature_extraction_train(["/home/tyiannak/Desktop/MusicGenre/Classical/","/home/tyiannak/Desktop/MusicGenre/Electronic/","/home/tyiannak/Desktop/MusicGenre/Jazz/"], 1.0, 1.0, aT.shortTermWindow, aT.shortTermStep, "extratrees", "etMusicGenre3", True)
aT.feature_extraction_train(["/home/tyiannak/Desktop/MusicGenre/Classical/","/home/tyiannak/Desktop/MusicGenre/Electronic/","/home/tyiannak/Desktop/MusicGenre/Jazz/"], 1.0, 1.0, aT.shortTermWindow, aT.shortTermStep, "gradientboosting", "gbMusicGenre3", True)
aT.feature_extraction_train(["/home/tyiannak/Desktop/MusicGenre/Classical/","/home/tyiannak/Desktop/MusicGenre/Electronic/","/home/tyiannak/Desktop/MusicGenre/Jazz/"], 1.0, 1.0, aT.shortTermWindow, aT.shortTermStep, "randomforest", "rfMusicGenre3", True)
aT.feature_extraction_train(["/home/tyiannak/Desktop/5Class/Silence/","/home/tyiannak/Desktop/5Class/SpeechMale/","/home/tyiannak/Desktop/5Class/SpeechFemale/","/home/tyiannak/Desktop/5Class/ObjectsOther/","/home/tyiannak/Desktop/5Class/Music/"], 1.0, 1.0, aT.shortTermWindow, aT.shortTermStep, "svm", "svm5Classes")
aT.feature_extraction_train(["/home/tyiannak/Desktop/5Class/Silence/","/home/tyiannak/Desktop/5Class/SpeechMale/","/home/tyiannak/Desktop/5Class/SpeechFemale/","/home/tyiannak/Desktop/5Class/ObjectsOther/","/home/tyiannak/Desktop/5Class/Music/"], 1.0, 1.0, aT.shortTermWindow, aT.shortTermStep, "knn", "knn5Classes")
aT.feature_extraction_train(["/home/tyiannak/Desktop/5Class/Silence/","/home/tyiannak/Desktop/5Class/SpeechMale/","/home/tyiannak/Desktop/5Class/SpeechFemale/","/home/tyiannak/Desktop/5Class/ObjectsOther/","/home/tyiannak/Desktop/5Class/Music/"], 1.0, 1.0, aT.shortTermWindow, aT.shortTermStep, "extratrees", "et5Classes")
aT.feature_extraction_train(["/home/tyiannak/Desktop/5Class/Silence/","/home/tyiannak/Desktop/5Class/SpeechMale/","/home/tyiannak/Desktop/5Class/SpeechFemale/","/home/tyiannak/Desktop/5Class/ObjectsOther/","/home/tyiannak/Desktop/5Class/Music/"], 1.0, 1.0, aT.shortTermWindow, aT.shortTermStep, "gradientboosting", "gb5Classes")
aT.feature_extraction_train(["/home/tyiannak/Desktop/5Class/Silence/","/home/tyiannak/Desktop/5Class/SpeechMale/","/home/tyiannak/Desktop/5Class/SpeechFemale/","/home/tyiannak/Desktop/5Class/ObjectsOther/","/home/tyiannak/Desktop/5Class/Music/"], 1.0, 1.0, aT.shortTermWindow, aT.shortTermStep, "randomforest", "rf5Classes")
Command-line use:
python audioAnalysis.py trainClassifier -i <directory1> ... <directoryN> --method <svm, svm_rbf, knn, extratrees, gradientboosting or randomforest> -o <modelName> --beat (optional for beat extraction)
(Note that svm_rbf is used for RBF kernel, while svm for linear kernel)
Examples:
python audioAnalysis.py trainClassifier -i classifierData/speech/ classifierData/music/ --method svm -o data/svmSM
python audioAnalysis.py trainClassifier -i classifierData/speech/ classifierData/music/ --method knn -o data/knnSM
python audioAnalysis.py trainClassifier -i /media/tyiannak/My\ Passport/ResearchData/AUDIO/musicGenreClassificationData/ALL_DATA/WAVs/Electronic/ /media/tyiannak/My\ Passport/ResearchData/AUDIO/musicGenreClassificationData/ALL_DATA/WAVs/Classical/ /media/tyiannak/My\ Passport/ResearchData/AUDIO/musicGenreClassificationData/ALL_DATA/WAVs/Jazz/ --method svm --beat -o data/svmMusicGenre3
python audioAnalysis.py trainClassifier -i /media/tyiannak/My\ Passport/ResearchData/AUDIO/musicGenreClassificationData/ALL_DATA/WAVs/Electronic/ /media/tyiannak/My\ Passport/ResearchData/AUDIO/musicGenreClassificationData/ALL_DATA/WAVs/Classical/ /media/tyiannak/My\ Passport/ResearchData/AUDIO/musicGenreClassificationData/ALL_DATA/WAVs/Jazz/ --method knn --beat -o data/knnMusicGenre3
(the --beat flag is used only for the musical genre classifiers)
Note: function evaluate_classifier() from audioTrainTest.py, called by feature_extraction_train() performs a cross validation procedure in order to select
the optimal classifier parameter for the problem under study:
- The soft margin parameter C for the SVM classifier
- The number of nearest neighbors, k for the kNN classifier.
- The number of trees in the random forest classifier.
- The number of boosting stages in the gradient boosting classifier.
- The number of trees in the forest of the extra trees classifier.
Function file_classification(inputFile, modelName, modelType) from audioTrainTest.py file can be used to classify a single wav or mp3 file based on an already trained segment classifier.
In only takes three arguments: the path of the WAV or MP3 filename to be classified, the path of the classifier model and the type of model (svm, svm_rbf, knn, extratrees, gradientboosting or randomforest). The function performs feature extraction,
classifier loading and classification as a wrapper of the individual functionalities. It calls functions load<classifierType>Model() to load the model, mid_feature_extraction() to extract the mid-term features and
classifier_wrapper() to perform classification.
Example:
from pyAudioAnalysis import audioTrainTest as aT
aT.file_classification("TrueFaith.wav", "data/svmMusicGenre3","svm")
Command-line use:
python audioAnalysis.py classifyFile -i <inputFilePath> --model <svm, svm_rbf, knn, extratrees, gradientboosting or randomforest> --classifier <pathToClassifierModeL>
Examples:
python audioAnalysis.py classifyFile -i bach.wav --model svm --classifier data/svmMusicGenre3
python audioAnalysis.py classifyFile -i bach.wav --model knn --classifier data/knnMusicGenre3
This functionality provides the classification of each WAV file found in the given folder and generates stdout resutls: Command-line use examples:
python audioAnalysis.py classifyFolder -i testFolder/ --model svm --classifier data/svmSM (only generates freq counts for each audio class)
python audioAnalysis.py classifyFolder -i testFolder/ --model svm --classifier data/svmSM --details (also outputs the result of each singe WAV file)
The last argument flag provides detailed output results. If not provided, the function only prints segment counts classified to each class, while when it is enabled it also prints the complete list of files along with their respective classification results.
Finally, note that the input data folder can also contain a filename pattern, e.g. data/theodore_speech_ will process all
files data/theodore_speech_*.wav.
One can use the method evaluate_model_for_folders() in audioTrainTest.py to evaluate end2end an already trained classifier, using a dataset organized in directories (each directory representing a different audio class)
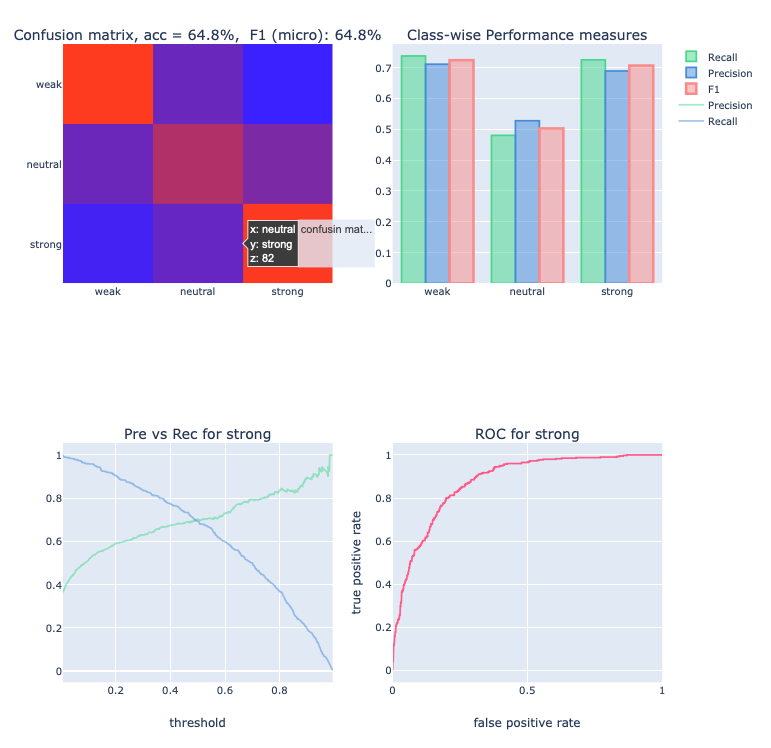
In the following example, the model arousal is evaluated for the data in folder test. The user also needs to provide a class of interest for which the ROC and Precision-Recall curves are extracted. In total, the function extracts the following (a) confusion matrix (with overall f1 and accuracy) (b) per class performance metrics (recall, precision, f1) (c) precision recall curve for the class of interest and (d) roc curve for the class of interest.
from pyAudioAnalysis import audioTrainTest as aT
cm, thr_prre, pre, rec, thr_roc, fpr, tpr = aT.evaluate_model_for_folders(["test/weak/", "test/neutral/", "test/strong/"], "arousal", "svm_rbf", "strong")
The results are shown in the following figure:
Apart from classification, regression can be rather important in audio analysis, e.g. in the context of speech emotion recognition, where the emotional state is not a discrete class but a real-valued measurement (e.g. arousal or valence).
audioTrainTest.py also provides regression-related functionalities.
Similarly to extract_features_and_train(), function feature_extraction_train_regression() reads the contents (i.e. the WAV files) of a given folder along with the respective real values and it returns a
regression model.
In the case of the classification training this is directly provided by the folder names (folders correspond to classes). In the case of regression, all files are stored in the same folder and the ground-truth information is provided through CSV files. In particular, one CSV must be present in the provided folder. It's filename provides the name of the respective variable and it has two columns: (a) the WAV filenames - without extension and (b) the value of the variable to be trained. If more than one CSV file is present in the provided folder, then the respective number of regression models are trained. The following figure shows an example of the contents of a folder to be used for training two regression models.

The function used to train one or more regression models is feature_extraction_train_regression(). It calls functions multiple_directory_feature_extraction() to extract the audio features and then repetivelly
calls evaluate_regression() to extract one optimized regression model for each learned parameter. The following example trains two regression models (valence and arousal)
related to the speech emotion recognition task (as explained above each variable corresponds to a CSV-groundtruth file that needs to be available in the data folder).
from pyAudioAnalysis import audioTrainTest as aT
aT.feature_extraction_train_regression("data/speechEmotion/", 1, 1, aT.shortTermWindow, aT.shortTermStep, "svm", "data/svmSpeechEmotion", False)
The result of the above code is two regression models (4 files in total if we consider the normalization files that store the MEAN and STANDARD DEVIATION arrays).
Finally, this functionality is also available for command-line use:
python audioAnalysis.py trainRegression -i data/speechEmotion/ --method svm -o data/svmSpeechEmotion
Notes:
- There is a "--beat" argument in the command-line use which, along with the last argument of the
feature_extraction_train_regression()function, corresponds to the boolean flag related to the usage of beat feature (see features section). - The functionality provided in
feature_extraction_train_regression()usesevaluate_regression()which performs a cross-validation procedure (using repeated random sampling, exactly as in the case of classifier training). This results in an SVM parameter tuning step that selects the C value that maximizes the Mean Square Error (MSE). This is an output example:
Regression task valence
Param MSE T-MSE R-MSE
0.0010 0.37 0.45 0.42
0.0050 0.30 0.32 0.43
0.0100 0.29 0.28 0.43 best
0.0500 0.30 0.20 0.44
0.1000 0.33 0.18 0.44
0.2500 0.46 0.16 0.42
0.5000 0.62 0.15 0.44
1.0000 0.86 0.14 0.41
5.0000 1.70 0.13 0.44
10.0000 2.41 0.12 0.42
Selected params: 0.01000
Regression task arousal
Param MSE T-MSE R-MSE
0.0010 0.22 0.34 0.24
0.0050 0.17 0.25 0.24 best
0.0100 0.20 0.22 0.26
0.0500 0.23 0.16 0.26
0.1000 0.25 0.14 0.24
0.2500 0.25 0.12 0.26
0.5000 0.30 0.11 0.25
1.0000 0.36 0.11 0.25
5.0000 0.64 0.10 0.24
10.0000 0.76 0.10 0.25
Selected params: 0.00500
The first column represents the resulting MSE for the respective SVM C param. The second column shows the MSE achieved on the training dataset (this is to provide a level of "overfitting"), while the last column shows the "baseline" MSE, i.e. the MSE achieved when the unknown variable is always set equal to the average value of the training set.
As soon as the regression model(s) has been trained, the file_regression() function can be used to estimate the regression variables for an unknown audio file.
from pyAudioAnalysis import audioTrainTest as aT
aT.file_regression("anger1.wav", "data/modelssvmSpeechEmotion", "svm")
In this example function file_regression() takes the svmSpeechEmotion as argument and searches for all model variables i.e. svmSpeechEmotion_*. In our case this leads to loading of
files svmSpeechEmotion_valence and svmSpeechEmotion_arousal and the respective normalization files. The result of the above example is two lists of regression variables and respective estimated values, i.e.:
([0.6999797228926365, -0.30015527588853286], ['arousal', 'valence'])
The equivalent command-line usage of this functionality is:
python audioAnalysis.py regressionFile -i anger1.wav --model svm --regression data/svmSpeechEmotion
Finally, the command-line batch regression of WAV files stored in a folder is also provided in audioAnalysis.py.
As with the folder classification described above, file pattern expressions can be provided as input paths (e.g. data/name_), in order to limit the files to be analyzed.
Examples:
python audioAnalysis.py regressionFolder -i ~/ResearchData/AUDIO/emotionSpeechData/germanSegments/Anger/ --model svm --regression data/svmSpeechEmotion
python audioAnalysis.py regressionFolder -i ~/ResearchData/AUDIO/emotionSpeechData/germanSegments/Sadness/ --model svm --regression data/svmSpeechEmotion
python audioAnalysis.py regressionFolder -i ~/ResearchData/AUDIO/emotionSpeechData/germanSegments/Happiness/ --model svm --regression data/svmSpeechEmotion
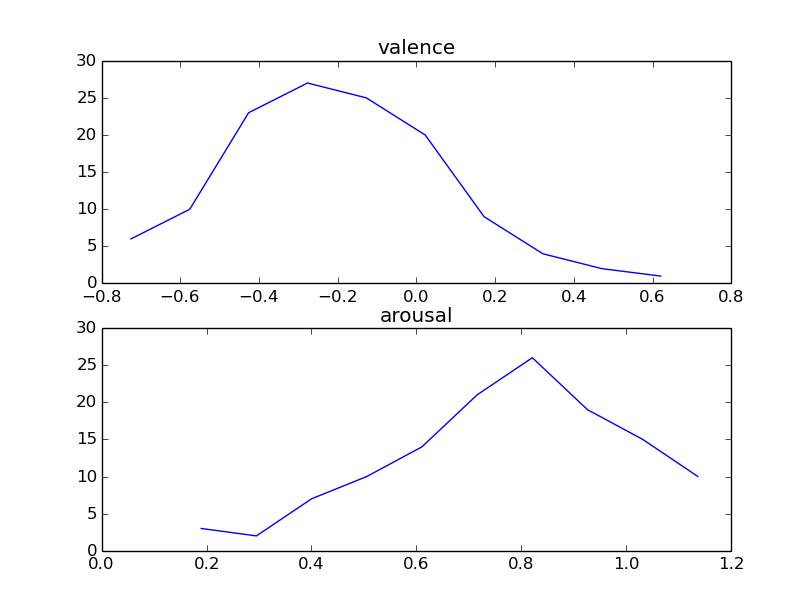
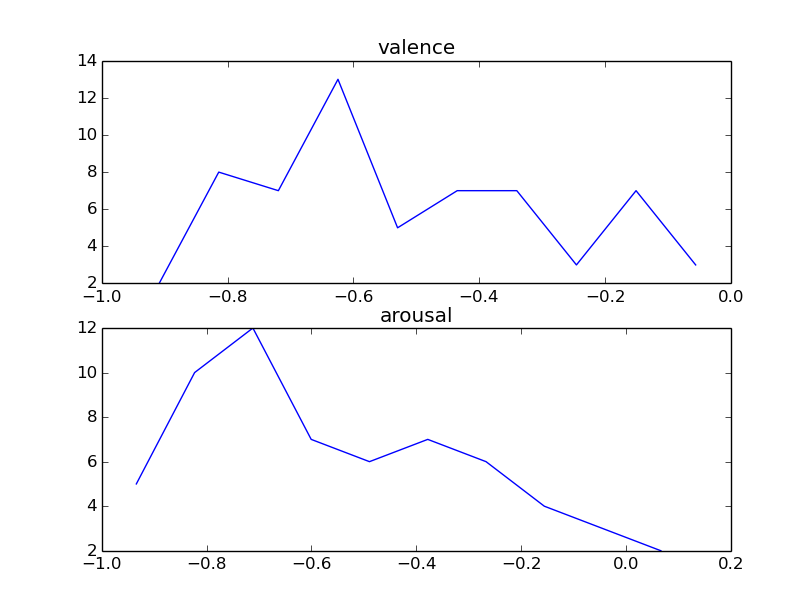
The above examples, loop over each WAV file in the provided folder and calls file_regression() using the svmSpeechEmotion model. The extracted estimates of the two variables (arousal and valence)
are aggregated and presented through two histograms. The results for the three folders that contain speech segments classified as Anger, Sadness and Happiness are shown respectively below: