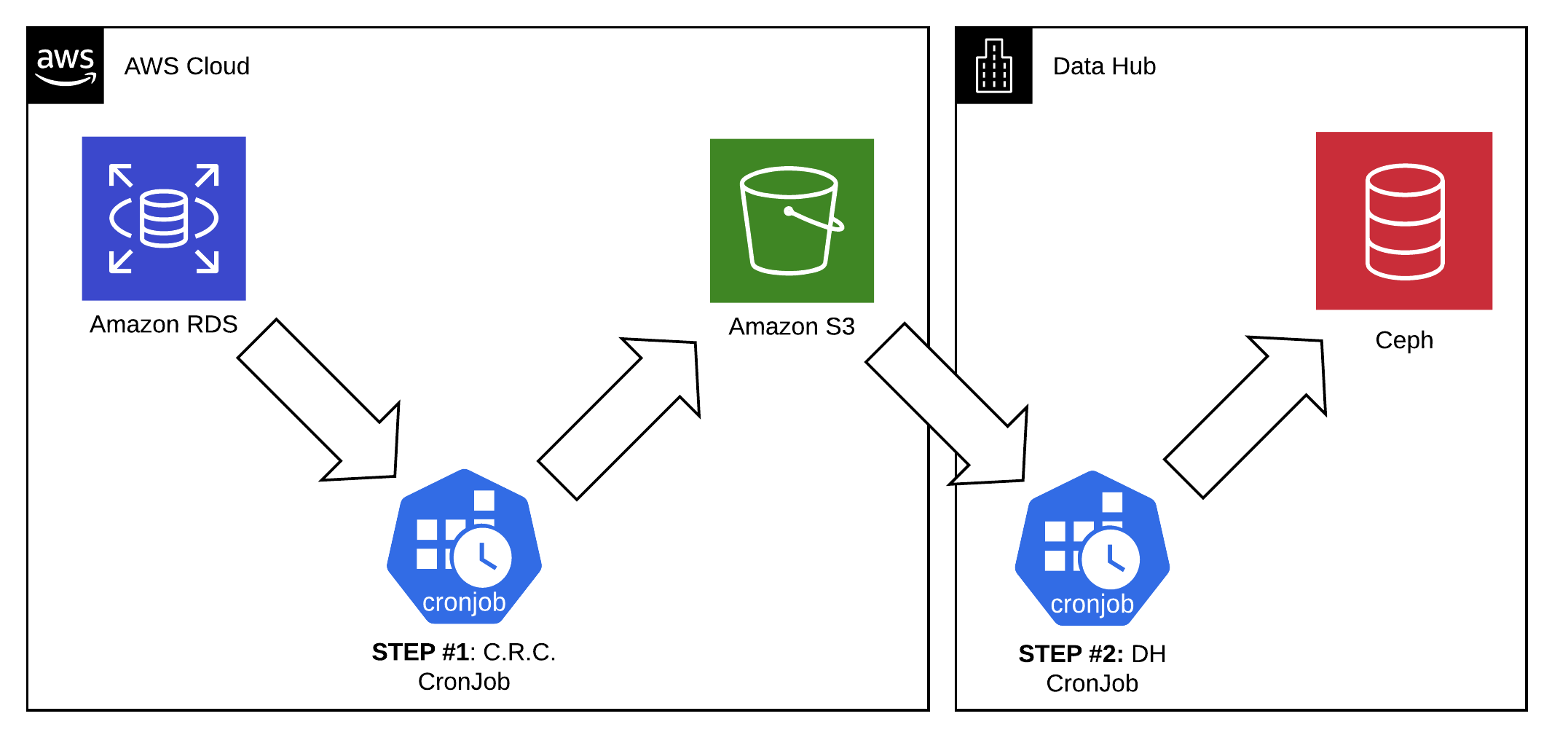
Data egress service is intended to export data from Amazon RDS to Data Hub on regular schedule and in a structured way.
- Let's presume the input data is located in a Amazon RDS or PostgreSQL database pod.
- OpenShift
CronJobon the application cluster side snapshots the database into Amazon S3 as CSV dumps. - OpenShift
CronJobon the target network side synchronizes S3 to Ceph.
Outward facing intermediate storage in the project is a necessity. Please set up an S3 bucket:
- You must have the AWS CLI installed and configured.
- See here for instructions on how to create an S3 bucket or follow this guide. Please make sure the S3 bucket has a policy that allows writing of the data with the credentials you provide to the cron job and respects the rules listed bellow.
Your S3 bucket is required to follow certain security rules:
- A separate bucket for this purpose only is required. Please don't use any shared buckets.
- A dedicated set of keys for the Sync job is required. Since these credentials are shared with team owning the Sync job, it should allow access to this bucket only.
- Ensure the bucket has AES encryption enabled.
- Set a lifecycle policy, that deletes objects older than 14 days. This is a failsafe mechanism, that allows us to retain historical data even if a sync job fails and gives us a few days to fix the issue. This also ensures that we don't keep data stored longer than our customer SLA.
To create a bucket via CLI (and upload the policies that ensures 3. and 4. rules are respected):
$ aws s3api create-bucket --bucket <BUCKET_NAME>
{
"Location": "/<BUCKET_NAME>"
}
$ aws s3api put-bucket-lifecycle-configuration \
--bucket <BUCKET_NAME> \
--lifecycle-configuration file://bucket_lifecycle.json
$ aws s3api put-bucket-encryption \
--bucket <BUCKET_NAME> \
--server-side-encryption-configuration file://bucket_encryption.jsonThis job is intended to be run on the APP side. It collects all data from given tables and stores them in a compressed CSVs in your S3 bucket.
Specification of this job is available in the openshift-crc folder. Please use this script rather as a guide than a given solution. What is important is the result - populated S3 bucket. How your team achieves that is totally up to you.
The job assumes you have a PostgreSQL secret postgresql available in your OpenShift project. Next you are required to have another secret available to you, called aws. It contains the AWS credentials the job can use:
$ oc create secret generic aws \
--from-literal=access-key-id=<CREDENTIALS> \
--from-literal=secret-access-key=<CREDENTIALS>
secret/aws createdBoth these secrets are described in the setup.yaml as well.
$ oc process -f openshift-crc/deploy.yaml \
-p S3_OUTPUT=<s3://bucket/path> \
-p TABLES="<space separated list of tables to dump>" \
-p PGHOST=<PostgreSQL hostname (default: postgresql)> \
-p PGPORT=<PostgreSQL port (default: 5432)> \
| oc create -f -
buildconfig.build.openshift.io/egress-bc created
imagestream.image.openshift.io/egress-is created
cronjob.batch/egress-cj createdAs a result a cron job is defined. It is set to run daily. On each run it would collect each table from TABLES in your database and save it as a <table>.csv.gz in s3://bucket/path/<DATE>/.
Once the cron job is run, you should be able to query for it's logs. It should look like this:
$ oc log `oc get pods -o=name --selector=job-name | tail -1`
Table 'tally_snapshots': Data collection started.
Table 'tally_snapshots': Dump uploaded to intermediate storage.
Table 'subscription_capacity': Data collection started.
Table 'subscription_capacity': Dump uploaded to intermediate storage.
Success.This is just an example. For a full, real life implementation please head to our GitLab dh-argo-workfolows repository. There you can find Argo workflows that use very similar approach as the one described bellow.
Second part of the Egress is to get the data in Amazon S3 over to Datahub's Ceph. To do so, we define a OpenShift cron job, that would sync content of your buckets using MinIO client.
Specification of this job is available in the openshift-dh folder.
Follow the prescription in openshift-dh/setup.yaml template, or use the cli:
$ oc create secret generic egress-input \
--from-literal=url=<S3_ENDPOINT> \
--from-literal=path=<S3_PATH> \
--from-literal=access-key-id=<CREDENTIALS> \
--from-literal=secret-access-key=<CREDENTIALS>
secret/egress-input created
$ oc create secret generic egress-output \
--from-literal=url=<S3_ENDPOINT> \
--from-literal=path=<S3_PATH> \
--from-literal=access-key-id=<CREDENTIALS> \
--from-literal=secret-access-key=<CREDENTIALS>
secret/egress-output createdPlease note the S3_ENDPOINT refers to the S3 host. For example:
- AWS S3 service:
https://s3.amazonaws.com - Google Cloud Storage:
https://storage.googleapis.com - etc..
The S3_PATH denotes the path for a bucket or its subfolder:
- It can be simply a bucket name:
my_bucket - It can also be a relative path to a folder within this bucket
my_bucket/folder_in_top_level/target_folder
And finally, deploy the Kubernetes cron job. This job uses a MinIO client and performs a mirror operation to sync S3 bucket to Ceph. Both input and output urls and paths are determined based on the secrets from previous step.
$ oc process -f openshift-dh/deploy.yaml | oc create -f -
cronjob.batch/egress-cj createdThe openshift-dh/deploy.yaml describes a cron job. By default this job is set to run daily. Once this job is executed, you should receive log containing all the synced files:
$ oc log `oc get pods -o=name --selector=job-name | tail -1`
Added `input` successfully.
Added `output` successfully.
`input/tcoufal/2019-11-21/subscription_capacity.csv.gz` -> `output/DH-SECURE-USIR/2019-11-21/subscription_capacity.csv.gz`
`input/tcoufal/2019-11-21/tally_snapshots.csv.gz` -> `output/DH-SECURE-USIR/2019-11-21/tally_snapshots.csv.gz`
Total: 17.38 MiB, Transferred: 17.38 MiB, Speed: 18.77 MiB/sSee LICENSE