Caption Generation is a challenging artificial intelligence problem where a textual description must be generated for a given photograph. It requires both methods from computer vision to understand the content of the image and a language model from the field of natural language processing to turn the understanding of the image into words in the right order.
Data Used The Data used is Flickr 8k. It can be downloaded by filling this form The images are distributed as
- Training Set - 6000 images
- Dev Set - 1000 images
- Test Set - 1000 images
I have used Transfer Learning for image feature extraction for this approach I used VGG16. Then the descriptions cleaning after that adding startseq at start and endseq at last for algorithms to understand start and end of captions.
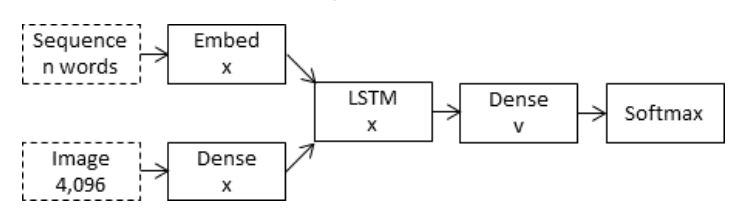
The inject model combines the encoded form of the image with each word from the text description generated so-far.
The approach uses the recurrent neural network as a text generation model that uses a sequence of both image and word information as input in order to generate the next word in the sequence
The merge model combines both the encoded form of the image input with the encoded form of the text description generated so-far.
The combination of these two encoded inputs is then used by a very simple decoder model to generate the next word in the sequence.
The approach uses the recurrent neural network only to encode the text generated so far
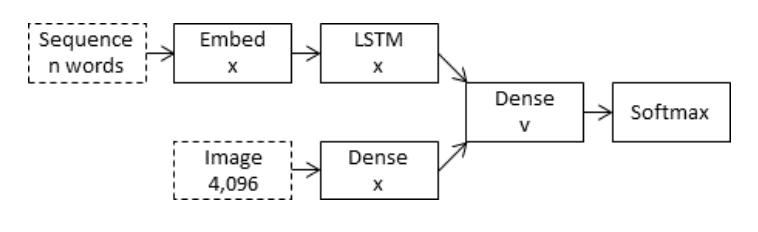
I have used Merge Model architecture
The outputs genrated so far are not that accurate but for preliminary stage they are not that bad.