Home
versalignLib creates shared objects for Alignment Kernel implementations using various parallelization technologies. For details regarding usage and implementation please refer to the usage section.
Built on top of versalignLib is a reference implementation that shows you
- how you can check for support of the technologies utilized by a given Kernel during runtime (e.g. AVX2 instruction support by your CPU).
- how to setup parameters, setup loggers and instantiate Kernels
- how to read in fasta-files and align them using a Kernel
- how to print Kernel output to a file
- how to time various Kernels using various thread timing courses
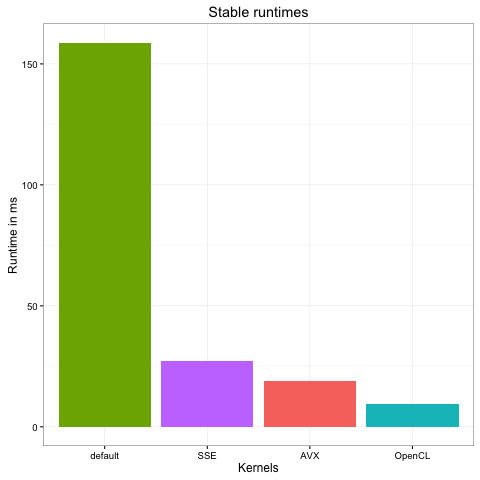
All benchmarks were run on a test dataset containing 5,000 pairs of sequences with maximum length of 50 / 52 bp.
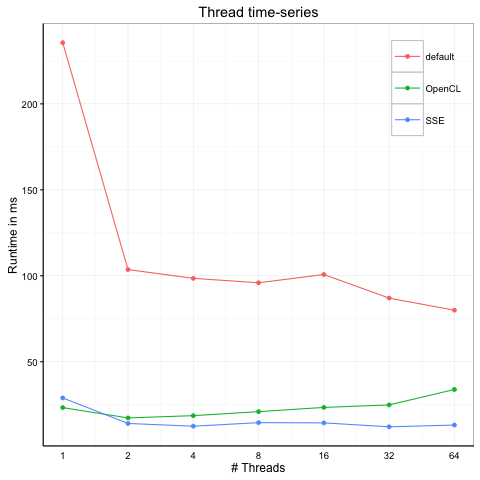
The following measurements were calculated on a Intel(R) Core(TM) i7-4850HQ CPU @ 2.30GHz MacBook Pro with 16 GB RAM memory.
The following measurements were calculated on a 2x Intel(R) Xeon(R) CPU E5-2640 0 @ 2.50GHz machine with 128 GB RAM memory. The AVX2 Kernel currently does not support multi-threading and thus was excluded from the measurement.
The default Kernel showed comparable results to the OpenCL Kernel, indicating that there was an issue with the vectorized datatypes on this run.
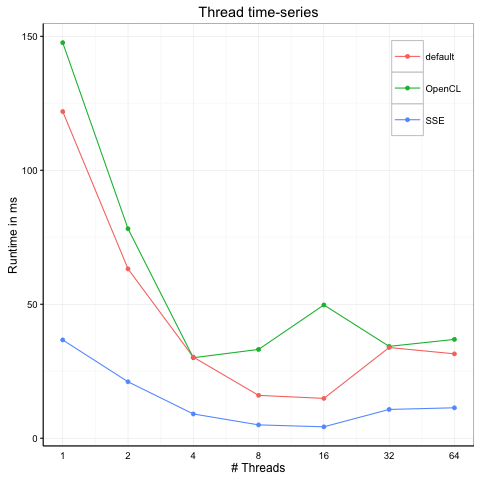
To show whether this behavior of the OpenCL Kernel also shows on another machine that is not concurrently used by several users, the timing run was repeated on a 2.4 GHz Dual-Core Intel Core i5 MacBook Pro with 8 GB RAM memory.
The CPU did not support device fission, therefore all OpenCL timings are equivalent to 4 threaded-runs. One can clearly see that OpenCL is comparable to pure SSE Kernel and several-fold faster that the default Kernel which finally shows the expected behavior.