Python/Pandas, Jupyter Notebook
Balanced Random Classifier Documentation
Easy Ensemble Classifier Documentation
This analysis was performed to simulate using various supervised machine learning models to predict credit risk with a dataset of various variables and their reported loan risk. The classes are unbalanced, as many factors contribute to whether a loan is considered "good" or "risky".
The imbalanced-learn and scikit-learn Python libraries were used to create training and testing data from the original dataset (through using the get_dummies function to convert string values into numerical ones within the columns for X, then a column from the original loaded data named "loan_status" which showed the determined risk of the loan for Y), resample those created variables, build six different models, and evaluate the performance of each to find the best machine learning model for this task.
- Two oversampling models (RandomOverSampler and SMOTE) balance the classes in the training set by raising the minority class to the value of the majority class. As it can be inferred that there's more safe loans than risky loans, there will be way more safe loans to train the model. Balancing the amount of risky loans to the amount of good loans allows for equality of testing for data with unbalanced classifications.
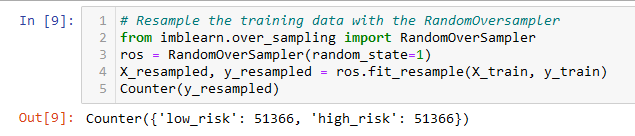
- One undersampling model (ClusterCentroids) was used to balance the classes in a similar manner to oversampling. However, the difference is that instead of raising the minority class to the majority class, the majority is lowered. The training set of low risk loans was lowered to that of the high risk loans.

- One combination model (SMOTEENN) balances the classes in another manner. Instead of an equal distribution, the minority class is oversampled, and then culled down a bit to prevent overlap with the majority class with a bit of undersampling (if the two closest points to a data point belong to two different classes, that data point is dropped to where the only data points left are still grouped with only their own class). This results in the majority still possessing a higher value, but with the gap between it and the minority being GREATLY closed. The training set goes from 51366:246 to 51359:46660.

- Two ensemble learning methods (BalancedRandomForestClassifier and EasyEnsembleClassifier) were used to combine multiple models to improve the performance of the overall model. While a bit of a convoluted process, it essentially can combine a lot of learners that are weak on their own and create an overall stronger learner. It takes a lot of bees to make a beehive. These are official quotes on the processes for both of these models from the official documentation linked at the beginning of the README.
A balanced random forest randomly under-samples each boostrap sample to balance it.
The classifier is an ensemble of AdaBoost learners trained on different balanced bootstrap samples. The balancing is achieved by random under-sampling.
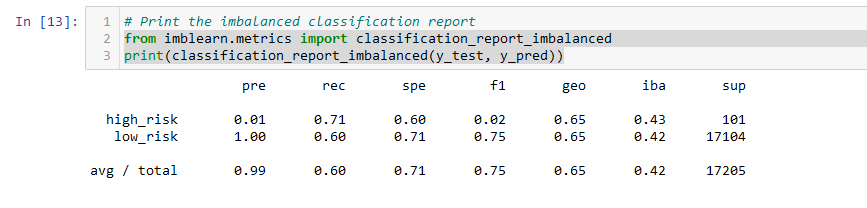

- The balanced accuracy score of the RandomOverSampler model is about 66%.
- The precision score is 99%, and the recall score is 60%.
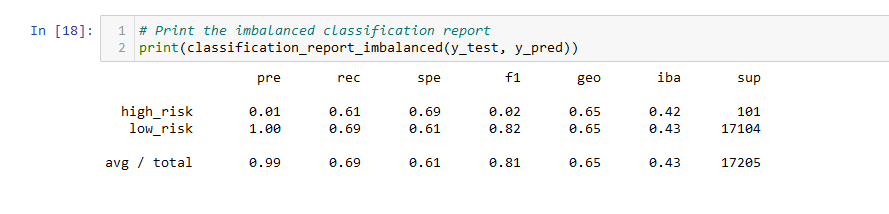

- The balanced accuracy score of the SMOTE model is about 65%.
- The precision score is 99%, and the recall score is 69%.
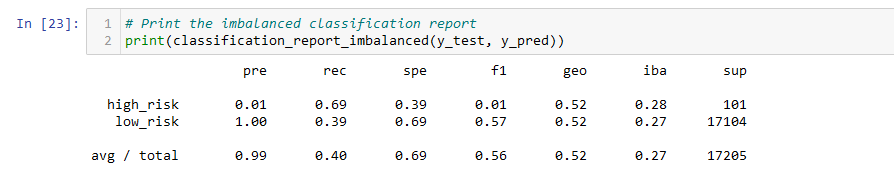

- The balanced accuracy score of the ClusterCentroids model is about 54%.
- The precision score is 99%, and the recall score is 40%.
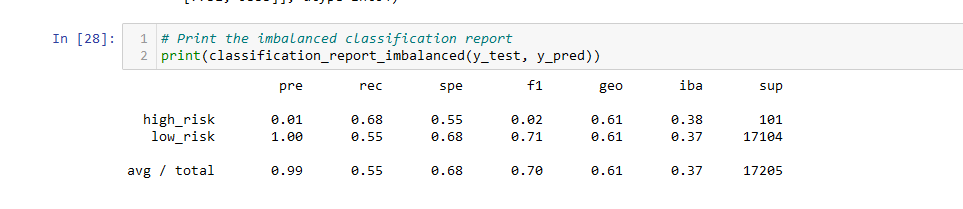

- The balanced accuracy score of the SMOTEEN model is about 61%.
- The precision score is 99%, and the recall score is 55%.
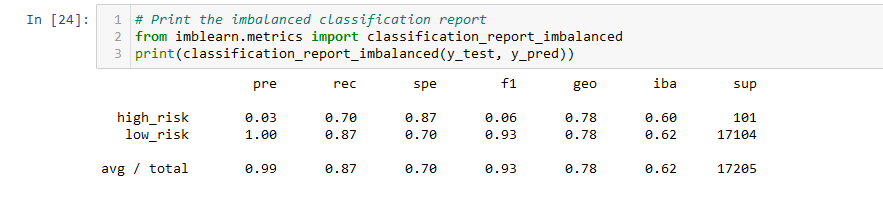

- The balanced accuracy score of the BalancedRandomForestClassifier model is about 79%.
- The precision score is 99%, and the recall score is 87%.
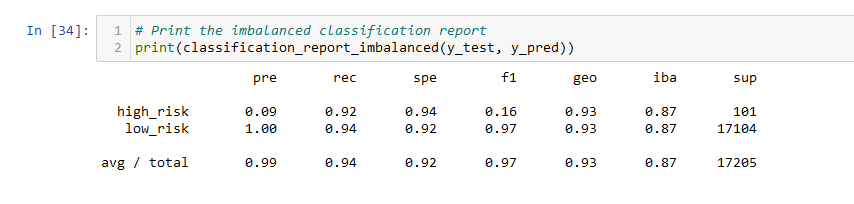
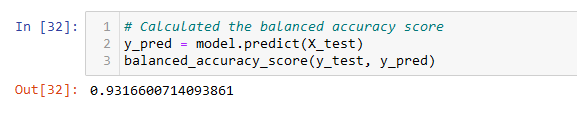
- The balanced accuracy score of the EasyEnsembleClassifier model is about 93%.
- The precision score is 99%, and the recall score is 94%.