Ensemble of Deep Convolutional Neural Networks for Learning to Detect Retinal Vessels in Fundus Images
Vision impairment due to pathological damage of the retina can largely be prevented through periodic screening using fundus color imaging. However the challenge with large scale screening is the inability to exhaustively detect fine blood vessels crucial to disease diagnosis. This work presents a computational imaging framework using deep and ensemble learning for reliable detection of blood vessels in fundus color images. An ensemble of deep convolutional neural networks is trained to segment vessel and non-vessel areas of a color fundus image. During inference, the responses of the individual ConvNets of the ensemble are averaged to form the final segmentation. In experimental evaluation with the DRIVE database, we achieve the objective of vessel detection with maximum average accuracy of 91.8% (This accuracy is different from the accuracy reported in the paper because of different libraries used) and Kappa Score of 0.7031.
| FUNDUS Image | Manual Segmentation | Predicted Segmentation |
|---|---|---|
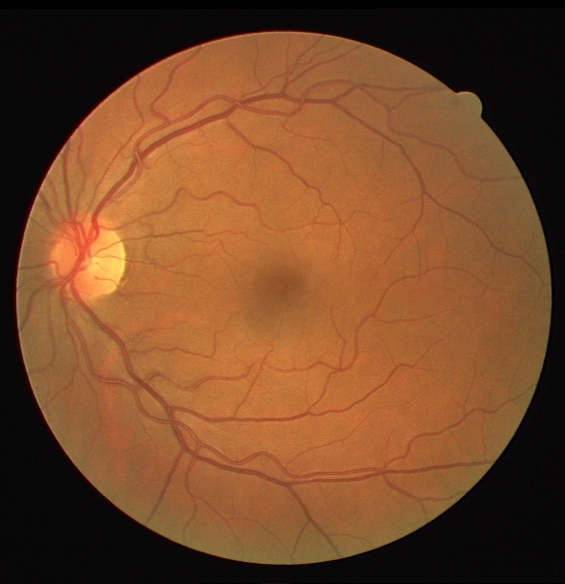 |
 |
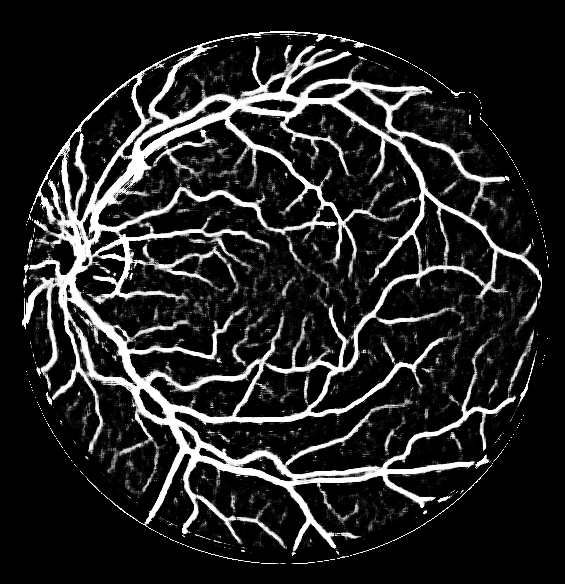 |
## Proposed Method
Ensemble learning is a technique of using multiple models or experts for solving a particular artificial intelligence problem. Ensemble methods seek to promote diversity among the models they combine and reduce the problem related to overfitting of the training data. The outputs of the individual models of the ensemble are combined (e.g. by averaging) to form the final prediction.
Convolutional neural networks (CNN or ConvNet) are a special category of artificial neural networks designed for processing data with a gridlike structure. The ConvNet architecture is based on sparse interactions and parameter sharing and is highly effective for efficient learning of spatial invariances in images. There are four kinds of layers in a typical ConvNet architecture: convolutional (conv), pooling (pool), fullyconnected (affine) and rectifying linear unit (ReLU). Each convolutional layer transforms one set of feature maps into another set of feature maps by convolution with a set of filters.
This paper makes an attempt to ameliorate the issue of subjectivity induced bias in feature representation by training an ensemble of 12 Convolutional Neural Networks (ConvNets) on raw color fundus images to discriminate vessel pixels from non-vessel ones.
Dataset: The ensemble of ConvNets is evaluated by learning with the DRIVE training set (image id. 21-40) and testing over the DRIVE test set (image id. 1-20).
Learning mechanism: Each ConvNet is trained independently on a set of 120000 randomly chosen 3×31×31 patches. Learning rate was kept constant across models at 5e − 4. Dropout probability and number of hidden units in the penultimate affine layer of the different models were sampled respectively from U ([0.5, 0.9]) and U ({128, 256, 512}) where U(.) denotes uniform probability distribution over a given range. The models were trained using Adam algorithm with minibatch size 256. Some of these parameters are different from the paper. The user can set some of these parameters using command line arguments which is explained in later sections.

The ConvNets have the same organization of layers which can be described as:
input- [conv - relu]-[conv - relu - pool] x 2 - affine - relu - [affine with dropout] - softmax
(Schematic representation below)

The system was trained on a machine with dual Intel Xeon E5-2630 v2 CPUs, 32 GB RAM and NVIDIA Tesla K-20C GPU. Average training time for each model was 3.5 hours (for 10000 epochs). Average inference time for each image was 55 secs on the said machine.
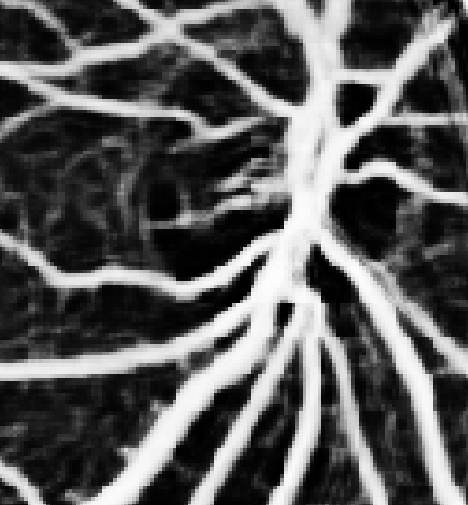
## Some Results
| FUNDUS Image | Magnified Section | Ground Truth | Prediction |
|---|---|---|---|
 |
 |
 |
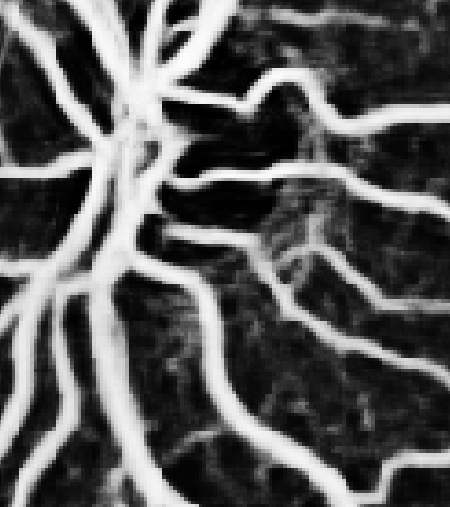 |
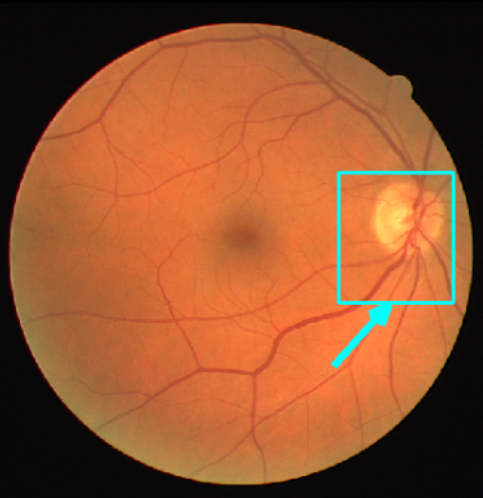 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Note that in the 3rd image the blood vessels are not easily visible to the human eye but our network does a good job at discerning the fine structure of the vessel.
The Ensemble of ConvNets efficiently captures the underlying statistics that govern the degree of vesselness of a point in a color fundus image. This is particularly demonstrated in the 4th row, where the Ensemble detects a clinically important condition called Neovascularization (which we got verified by multiple ophthalmologists) not marked in the ground truth.
Download the DRIVE dataset from this link. In order to run this code smoothly without having to change the code, please set up the directory tree in a way similar to the tree structure presented below.
Project
|-- Data
| |-- DRIVE
| | |-- test
| | | |-- Contains 4 folders
| | |-- training
| | | |-- Contains 4 folders
| |-- models
| | |-- This folder is auto-generated by the code
| | |-- It contains the saved models
| |-- logs
| | |-- Event files necessary for Tensorboard (Auto-generated folder)
|-- Deep-Vessel
| |-- Notebooks
| | |-- Contains necessary notebooks for development
| |-- Scripts
| | |-- Contains scripts needed to preprocess, train and deploy the models
| |-- arglists
| | |-- JSON files with required parameters for each model
| |-- images
| | |-- Contains images for website. You may delete this folder
| |-- README.md
All these python scripts can be invoked with --help to display a brief help message.
Preprocessor.pycrops random pathces from all training images and saves them in a PANDAS DataFramev2_graph.pytrains a single convolutional networktrain_ensemble.pytrains an esemble of convolutional networks with different parametersTest.pydecodes the test imagesensemble_decoder.pydecodes the test images using an ensemble of different saved modelscreate_json.pysmall utility script to create a json file with model args which can be edited later in a text fileSuperPixel_Decoder.pyis an experimental fast SuperPixel based decoder, but isn't very accurate and hence is not updated
Make sure to run these scripts from within the Scripts folder, otherwise it may throw an IOError as the paths used are relative
Usage: Preprocessor.py [OPTIONS]
Options:
--total_patches TOTAL_PATCHES
Total number of training images/patches to be used [Default - 4800]
--patch_dim PATCH_DIM
Dimension of window to be used as a training patch [Default - 31]
--positive POSITIVE Proportion of positive classes to be kept in training data [Default - 0.5]
Example usage:
We used
python Preprocessor.py --total_patches 120000
To save 30000 patches with dimension of 3*31*31 and a 4:1 proportion of positive classes, use
python Preprocessor.py --total_patches 30000 --patch_dim 15 --positive 0.8
Usage: v2_graph.py [OPTIONS]
Options:
--batch BATCH Batch Size [Default - 64]
--fchu1 FCHU1 Number of hidden units in FC1 layer [Default - 512]
--learning_rate LEARNING_RATE Learning rate for optimiser [Default - 5e-4]
--training_prop TRAINING_PROP Proportion of data to be used for training data [Default - 0.8]
--max_steps MAX_STEPS Maximum number of iteration till which the program must run [Default - 100]
--checkpoint_step CHECKPOINT_STEP Step after which an evaluation is carried out on validation set and model is saved [Default - 50]
--loss_step LOSS_STEP Step after which loss is printed [Default - 5]
--keep_prob KEEP_PROB Keep Probability for dropout layer [Default - 0.5]
--model_name MODEL_NAME Index of the model [Default - '1']
Example usage:
We used
python v2_graph.py --batch 256 --learning_rate 5e-4 --training_prop 0.9 --max_steps 8000 --checkpoint_step 400 --loss_step 25
Usage: train_ensemble.py [OPTIONS]
Options:
--a A Path to JSON file containing model arguments
Example usage:
We used
python train_ensemble.py --a ../arglists/heavy.json
Usage: Test.py [OPTIONS]
Options:
--fchu1 FCHU1 Number of hidden units in FC1 layer. This should be identical to the one used in the model
[Default - 256]
--out OUT Directory to put rendered images to
--inp INP Directory containing images for testing
--model MODEL Path to the saved tensorflow model checkpoint
--format FORMAT Format to save the images in. [Available formats: npz, jpg and png]
Example usage:
We used
python Test.py --fchu1 512 --format png --out ../../Data/DRIVE/tmp/ --inp ../../Data/DRIVE/test/ --model ../../Data/models/model1/model.ckpt-7999
Usage: ensemble_decoder.py [OPTIONS]
Options:
--a A Path to JSON file containing model arguments
--m M Path to JSON file containing saved model paths
--out OUT Directory to put rendered images to
--inp INP Directory containing images for testing
Example usage:
We used
python ensemble_decoder.py --m ../arglists/model_paths_heavy.json --a ../arglists/heavy.json --out ../../Data/DRIVE/ensemble_test_results --inp ../../Data/DRIVE/test/
The arglists/ folder contains JSON files that store necessary command line arguments. It is human readable and hence can be edited easily by a user.
This is necessary for training the ensemble and needs to be passed to train_ensemble.py. It contains the list of arguments that needs to be passed to v2_graph.py for every model. As the name suggests, this configuration took us 2 days to run on a server, and unless you have a powerful GPU, I would suggest editing this file before running it.
The models saved by training the ensemble are saved as checkpoints. This is a simple file that stores the paths to the best checkpoints for each model.
### Acknowledgement
This repository is a TensorFlow re-implementation by Ankush Chatterjee [during his internship with Anirban Santara and Pabitra Mitra at the Department of Computer Science and Engineering, IIT Kharagpur during the summer of 2016] of the work done by Debapriya Maji, Anirban Santara, Pabitra Mitra and Debdoot Sheet. Check out the original paper (http://arxiv.org/abs/1603.04833) for more details. The authors would like to thank Dr. Sujoy Kar, Dr. Tapas Paul and Dr. Asim Kumar Kandar from Apollo Gleneagles Hospitals Kolkata for valuable discussions in course of development of this system.