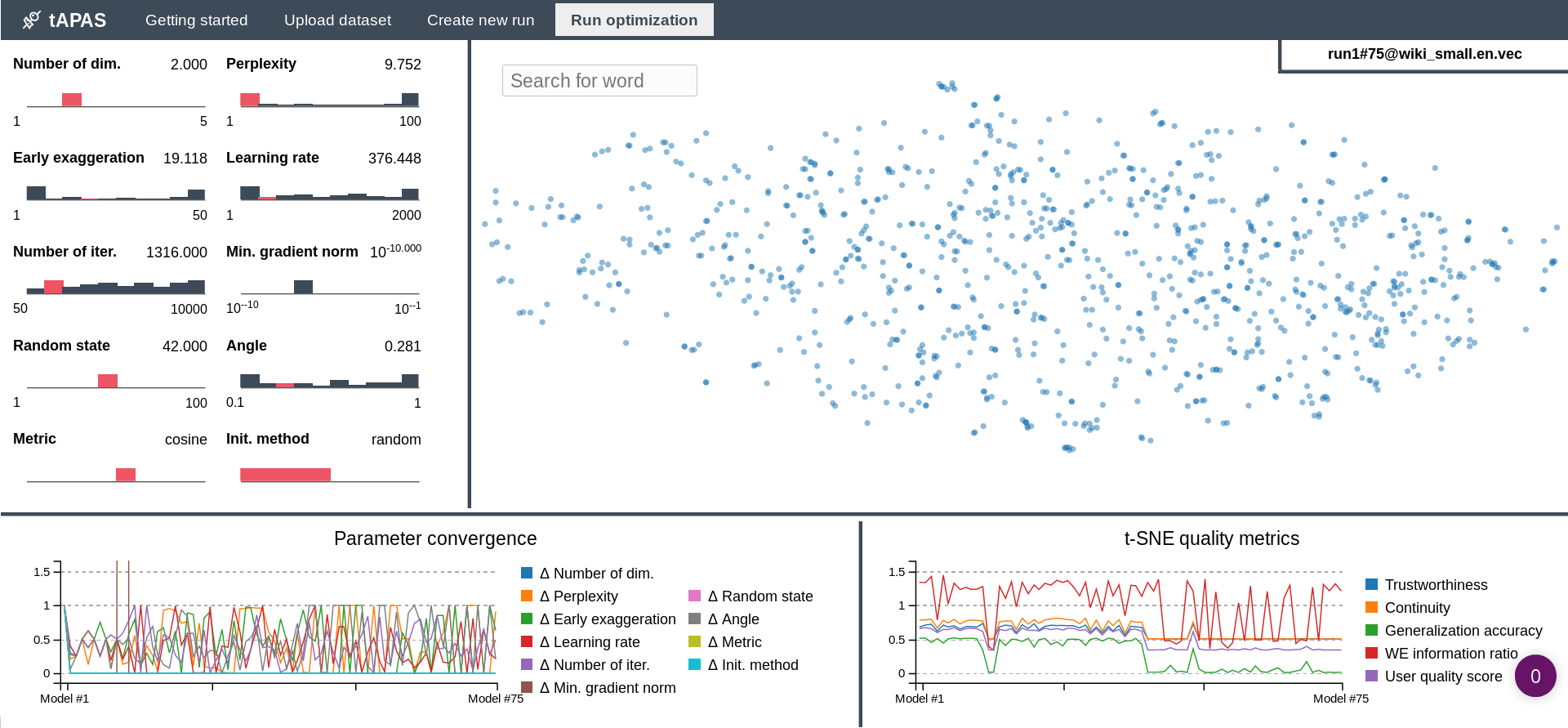
Bayesian optimization of hyperparameters for t-SNE in the context of word embeddings - i. e.: Input is a word embedding (labels + coordinates in high-dimensional space). The optimization procedure samples the parameter space to generate low-dimensional approximations of the original word embeddig data using t-SNE. The quality/truthfulness of the resulting models are evaluated with several metrics:
- Trustworthiness: Measure for proportion of points too close together1 in the low-dimensional space.
- Continuity: Measure for proportion of points too far apart1 in the low-dimensional space.
- Generalization: Generalization error of 1-nearest neighbour classifier (e. g. word embedding is clustered in high-dimensional and low-dimensional space - the higher the similarity between the cluster labels, the lower the generalization error).
- Relative word embedding quality: QVEC [1] is used to evalute the intrinsic quality of the original word embedding and its dimensionality-reduced projection. The ratio is referred to as 'relative word embedding quality'.
The first three measures were chosen following [2].
1: In terms of neighbourhood ranks, not absolute distances.
[1] Y. Tsvetkov, M. Faruqui, W. Ling, G. Lample, and C. Dyer, “Evaluation of Word Vector Representations by Subspace Alignment,” 2015, pp. 2049–2054.
[2] L. J. P. van der Maaten, E. O. Postma, and H. J. van den Herik, Dimensionality Reduction: A Comparative Review. 2008.