Click here to go to the accompanying blog post.
This project uses Keras to train a variety of Feedforward and Recurrent Neural Networks for the task of Visual Question Answering. It is designed to work with the VQA dataset.
Models Implemented:
| BOW+CNN Model | LSTM + CNN Model |
|---|---|
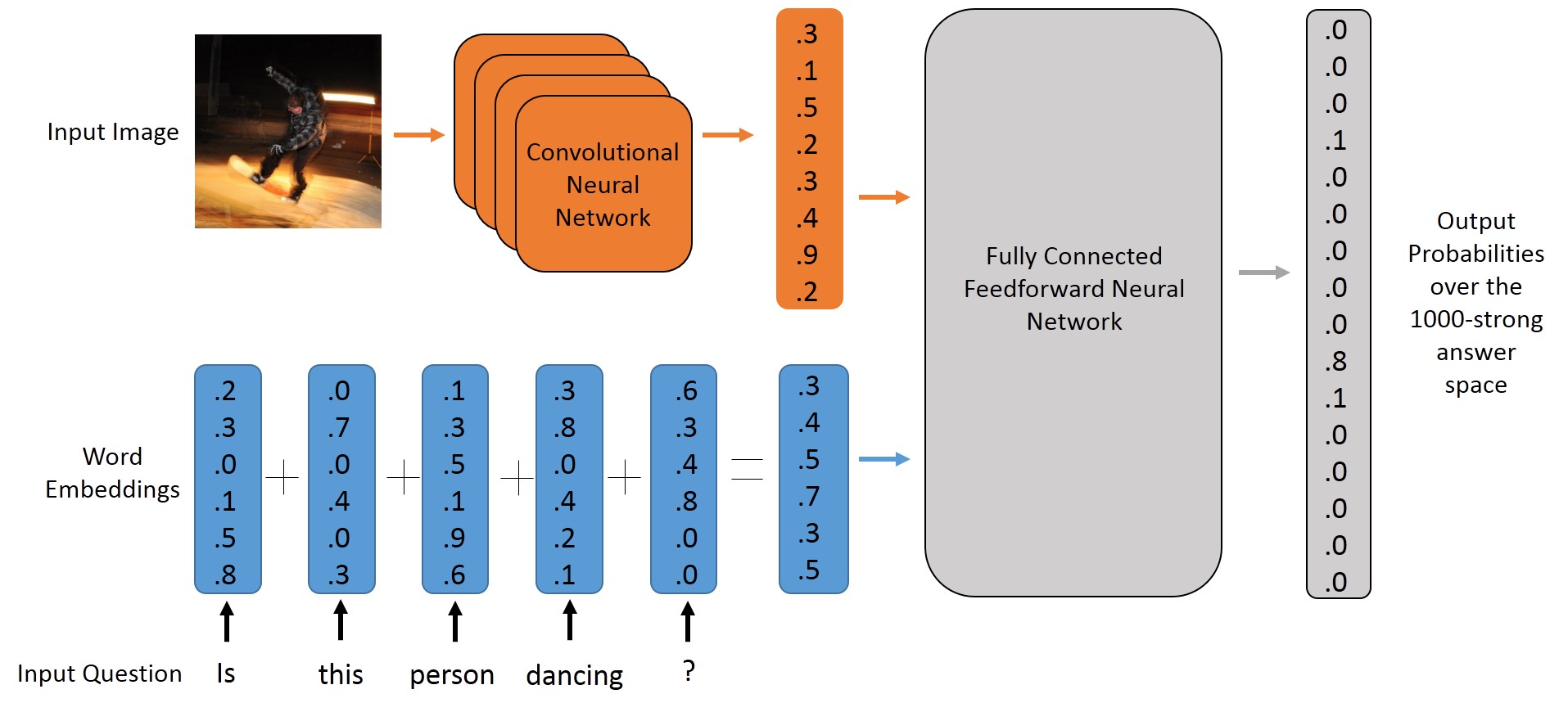 |
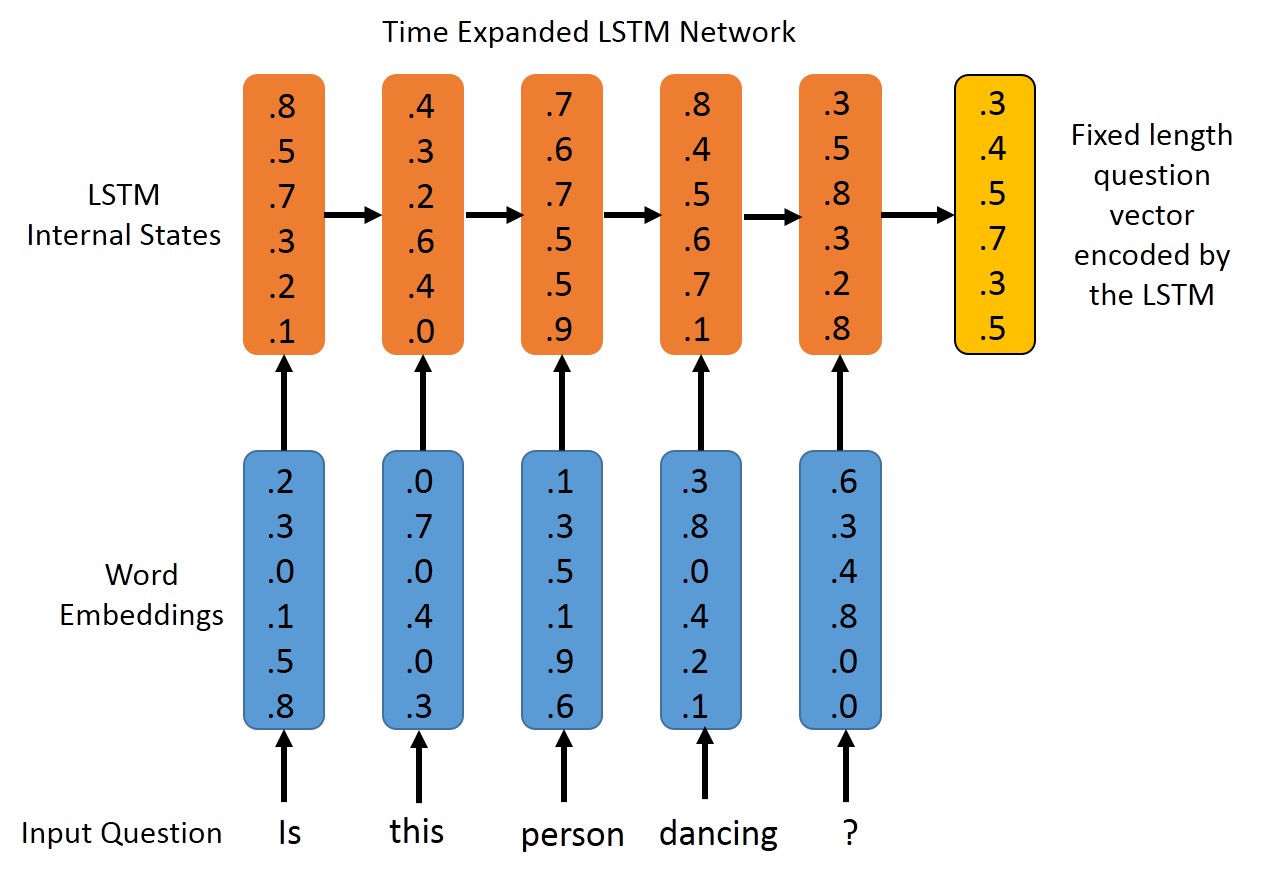 |
- Keras 0.20
- spaCy 0.94
- scikit-learn 0.16
- progressbar
- Nvidia CUDA 7.5 (optional, for GPU acceleration)
- Caffe (Optional)
Tested with Python 2.7 on Ubuntu 14.04 and Centos 7.1.
Notes:
- Keras needs the latest Theano, which in turn needs Numpy/Scipy.
- spaCy is currently used only for converting questions to a vector (or a sequence of vectors), this dependency can be easily be removed if you want to.
- spaCy uses Goldberg and Levy's word vectors by default, but I found the performance to be much superior with Stanford's Glove word vectors.
- VQA Tools is not needed.
- Caffe (Optional) - For using the VQA with your own images.
This project has a large number of dependecies, and I am yet to make a comprehensive installation guide. In the meanwhile, you can use the following guide made by @gajumaru4444:
If you intend to use my pre-trained models, you would also need to replace spaCy's default word vectors with the GloVe word vectors from Stanford. You can find more details here on how to do this.
Take a look at scripts/demo_batch.py. An LSTM-based pre-trained model has been released. It currently works only on the images of the MS COCO dataset (need to be downloaded separately), since I have pre-computed the VGG features for them. I do intend to add a pipeline for computing features for other images.
Caution: Use the pre-trained model with 300D Common Crawl Glove Word Embeddings. Do not the the default spaCy embeddings (Goldberg and Levy 2014). If you try to use these pre-trained models with any embeddings except Glove, your results would be garbage. You can find more deatails here on how to do this.
Now you can use your own images with the scripts/own_image.py script. Use it like :
python own_image.py --caffe /path/to/caffe
For now, a Caffe installation is required. However, I'm working on a Keras based VGG Net which should be up soon. Download the VGG Caffe model weights from here and place it in the scripts folder.
Performance on the validation set and the test-dev set of the VQA Challenge:
| Model | val | test-dev |
|---|---|---|
| BOW+CNN | 48.46% | TODO |
| LSTM-Language only | 44.17% | TODO |
| LSTM+CNN | 51.63% | 53.34% |
Note: For validation set, the model was trained on the training set, while it was trained on both training and validation set for the test-dev set results.
There is a lot of scope for hyperparameter tuning here. Experiments were done for 100 epochs.
Training Time on various hardware:
| Model | GTX 760 | Intel Core i7 |
|---|---|---|
| BOW+CNN | 140 seconds/epoch | 900 seconds/epoch |
| LSTM+CNN | 200 seconds/epoch | 1900 seconds/epoch |
The above numbers are valid when using a batch size of 128, and training on 215K examples in every epoch.
Have a look at the get_started.sh script in the scripts folder. Also, have a look at the readme present in each of the folders.
All kind of feedback (code style, bugs, comments etc.) is welcome. Please open an issue on this repo instead of mailing me, since it helps me keep track of things better.
MIT