Contributing
The Process Cube Explorer was developed as a research-framework and is very easy to extend. Our documentation is in German, but this page will point you in to general directions as well.
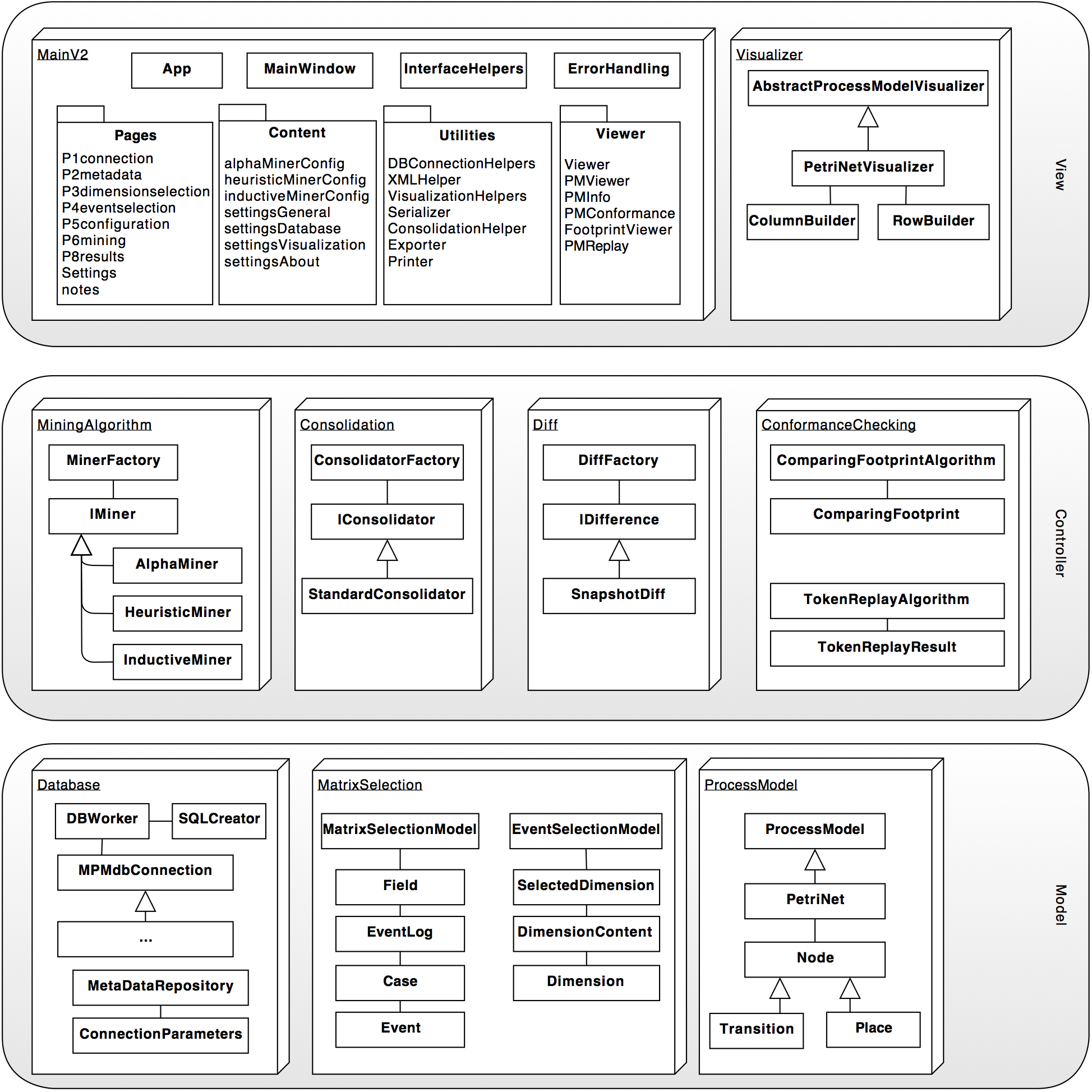
This is the basic architecture:
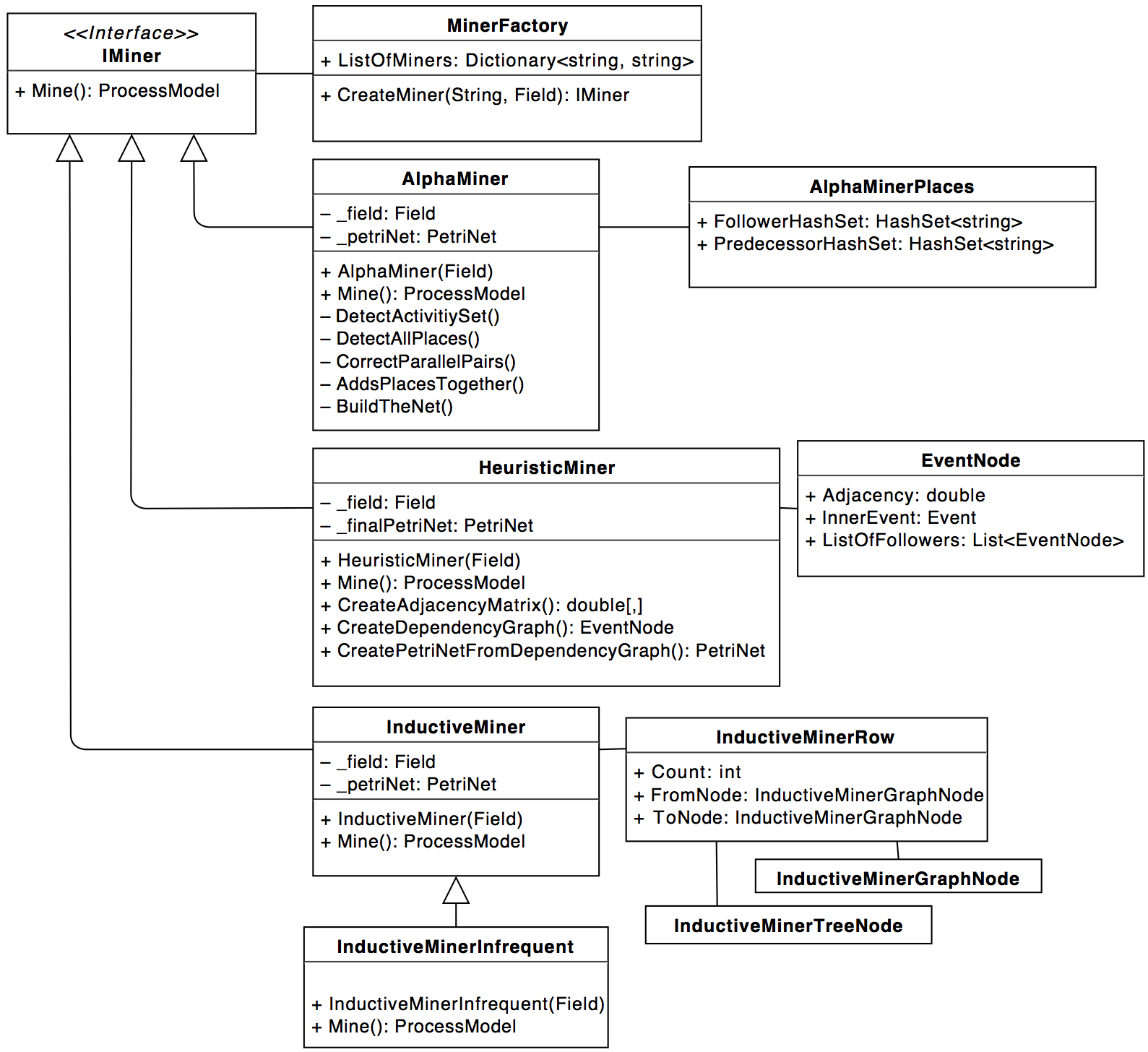
Adding a new mining-algorithm is easy: Make yourself familiar with the field-class and the IMiner-interface.
Your algorithm will need to implement the interface, which means it will be initialized with a field-
object. The field contains everything you need, most important the eventlog. Your Mine()-Method should
return a ProcessModel-Object. Currently the only implementation is for petrinets, if your algorithm
creates something different make sure to implement that kind of model as well.
To use your algorithm you just have to create a UserContent-View and add it to the ListOfMiners in the
MinerFactory.
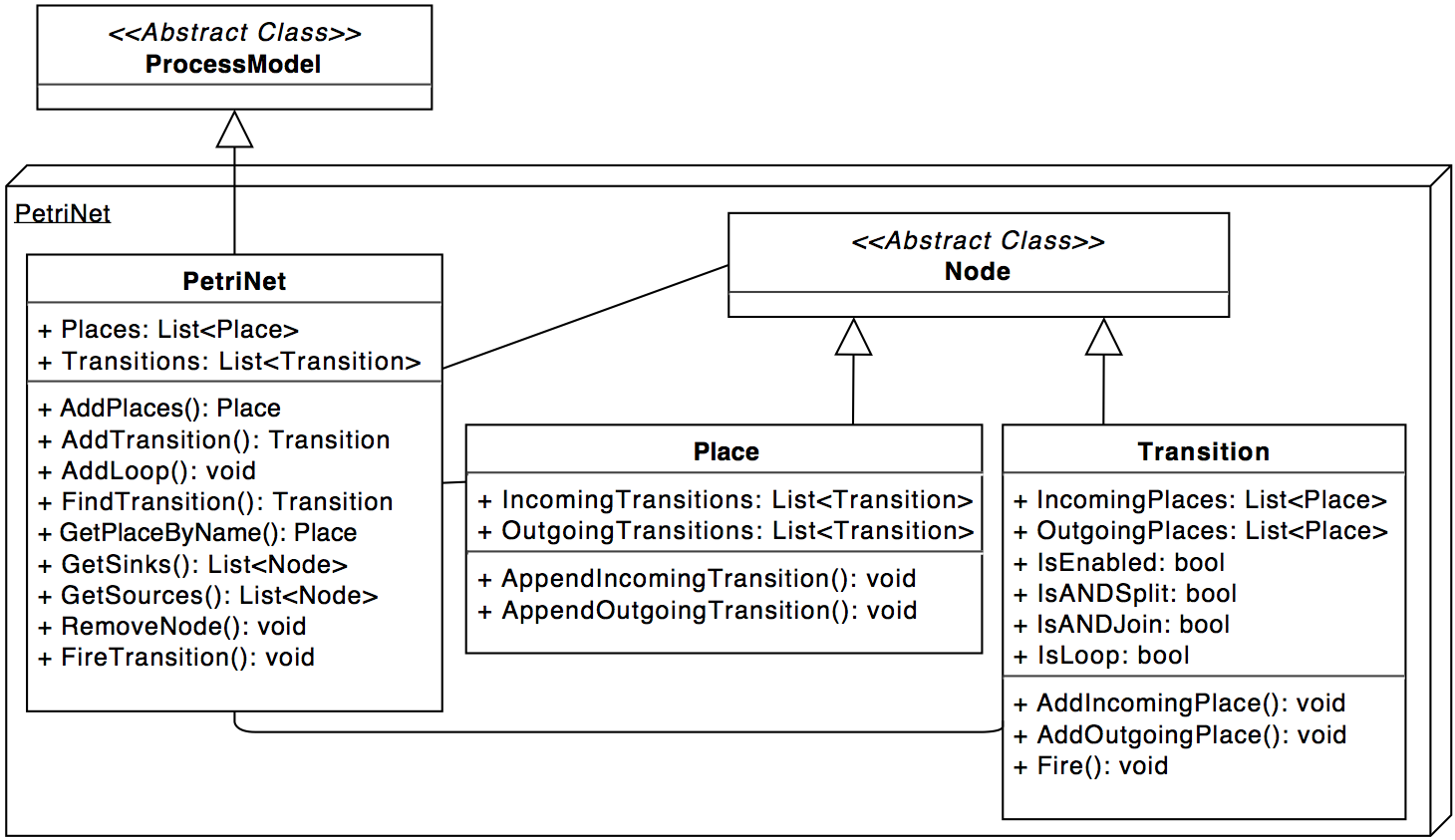
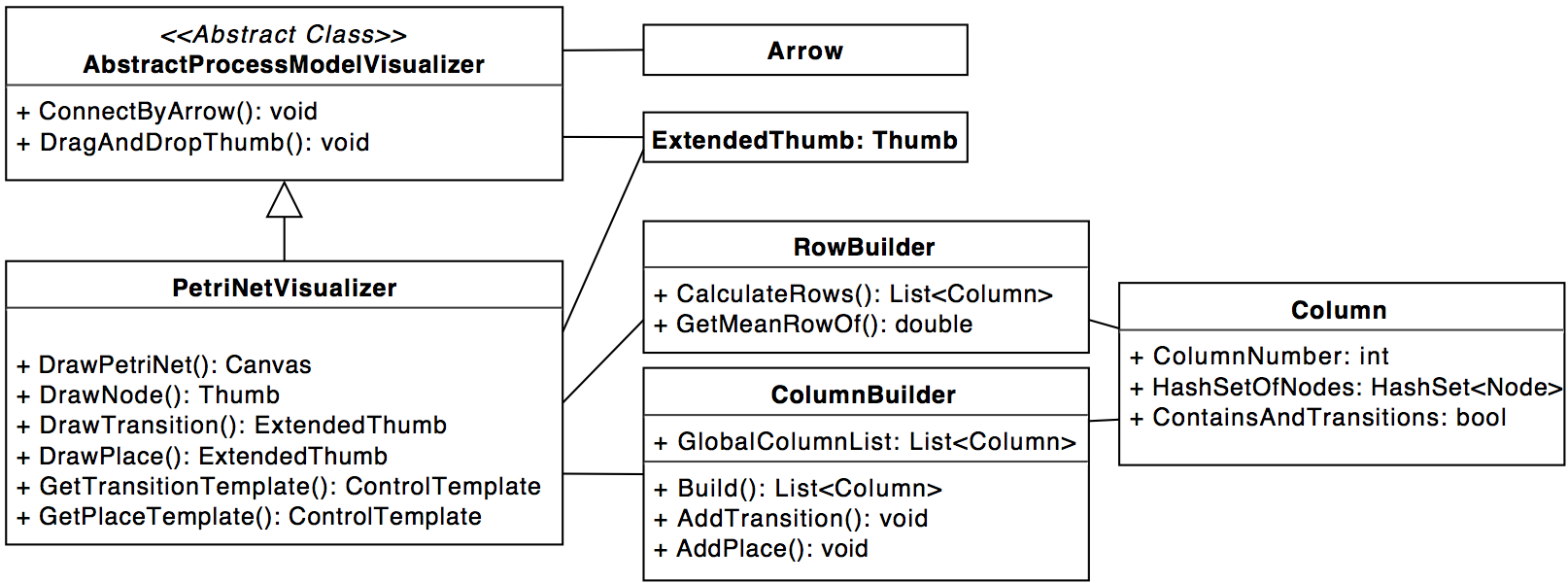
Currently all three algorithms return petrinets, so only these are implemented. There is however an abstract class
ProcessModel and we tried to use that whenever possible. This means you can just derive a new model-class
from the ProcessModel-class and use it in your mining-algorithm. You still need to implement a visualization
though, which should be derived from the abstract class AbstractProcessModelVisualizer.
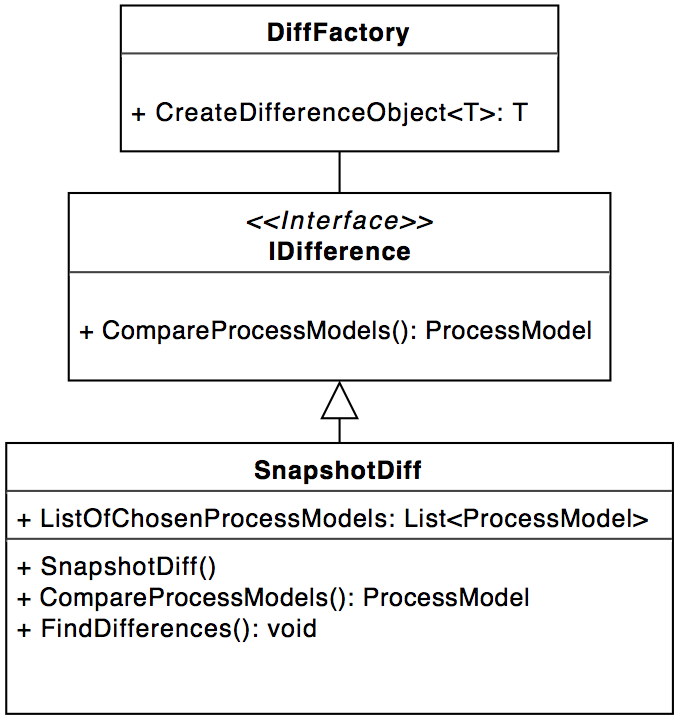
There also is an interface (IDifference) and a factory (DiffFactory) for diff-algorithms. Currently
the snapshot-diff is implemented.
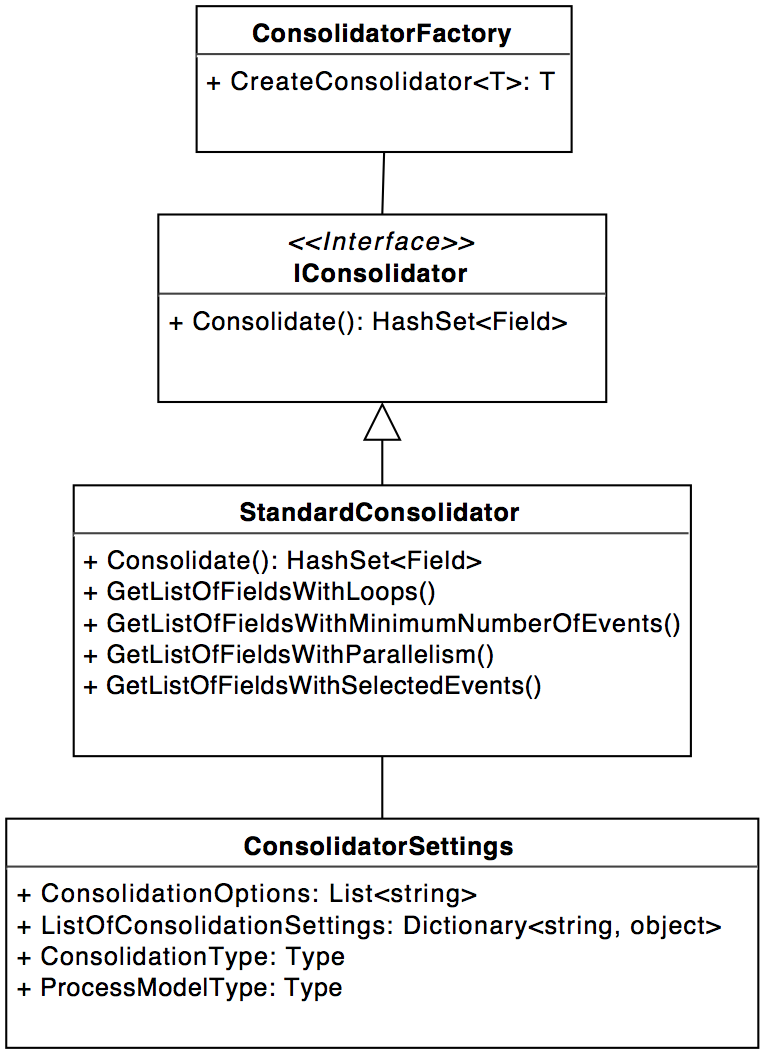
Use the IConsolidator-Interface and the ConsolidatorFactory.
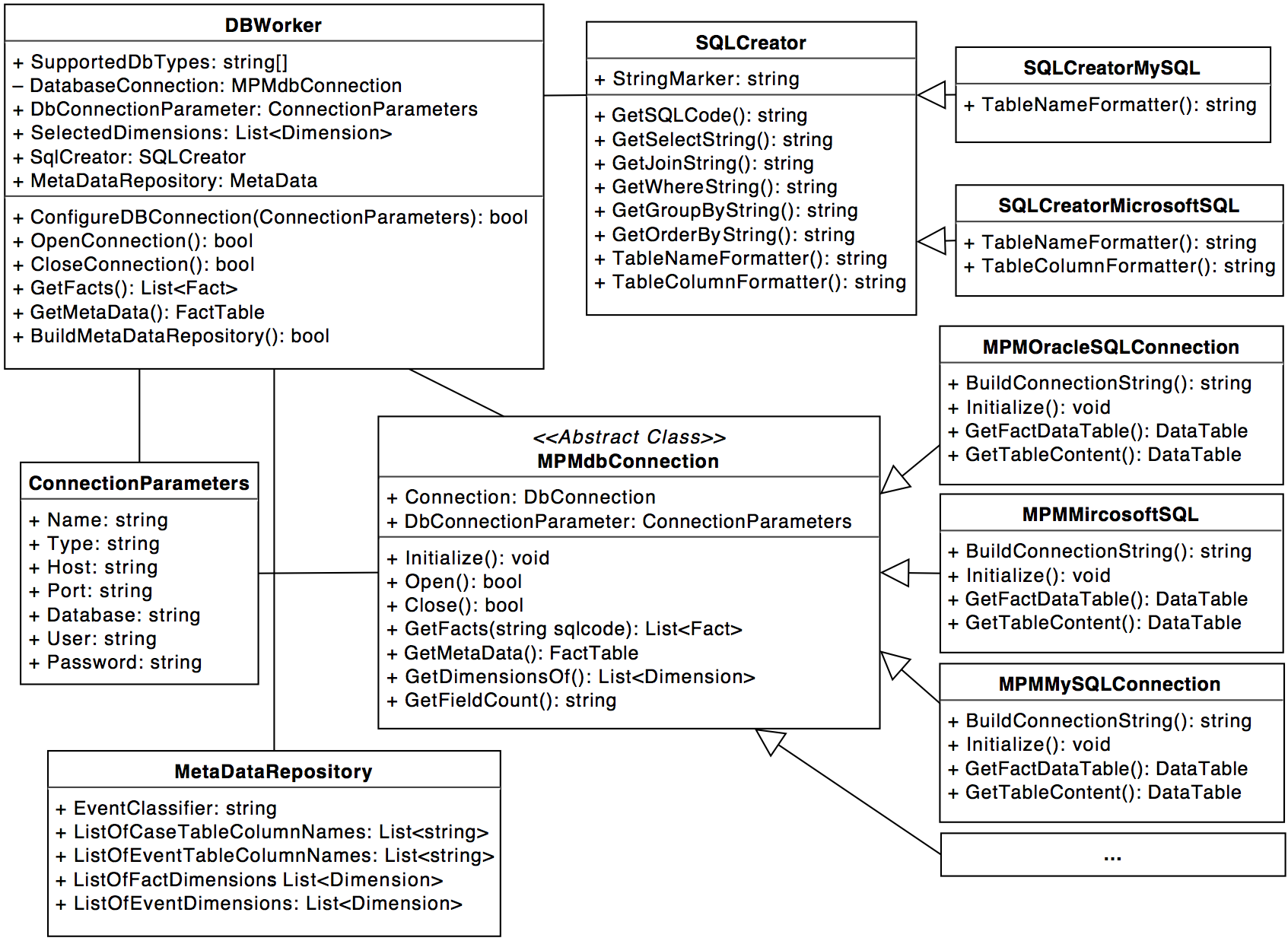
Most database-types are already supported, you can however derive your own from the abstract MPMdbConnection-class.
Keep in mind that you might need to derive another class from the SQLCreator, since dialects may differ.
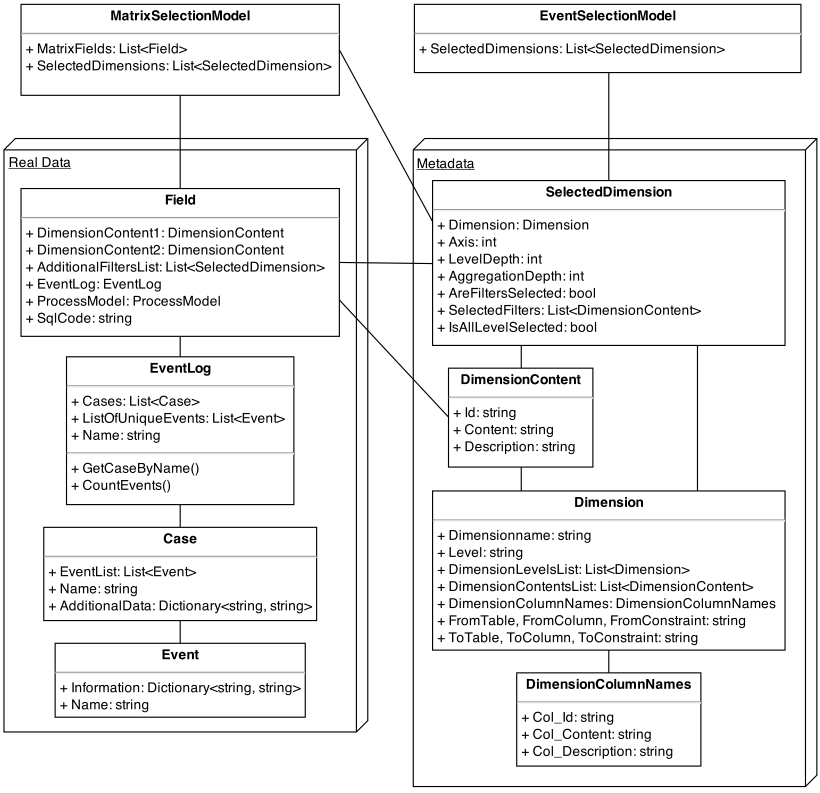
For most implementations you need to know the basics of the MatrixSelection-Package:
You also might want to have a look at the Main-Package:
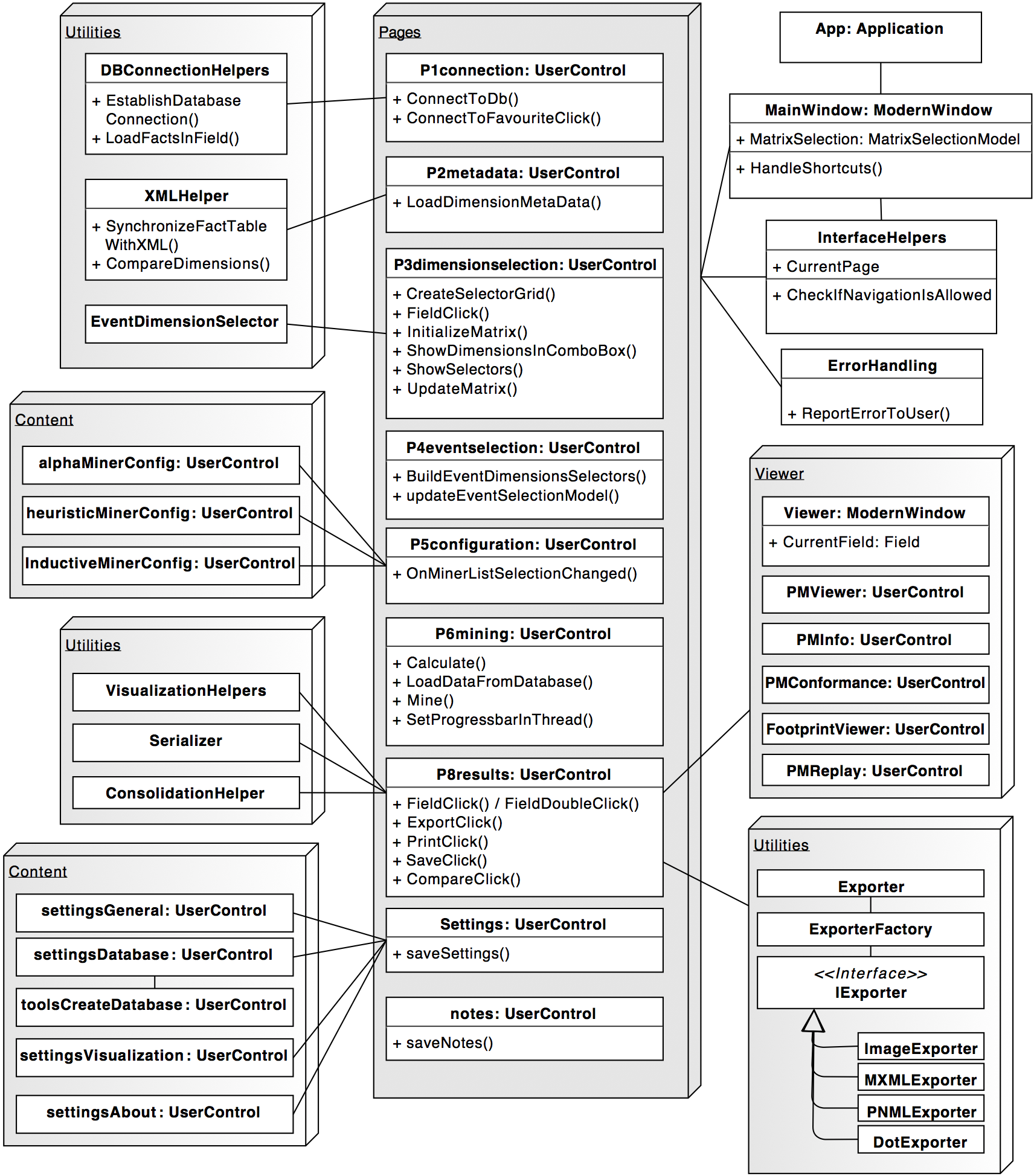
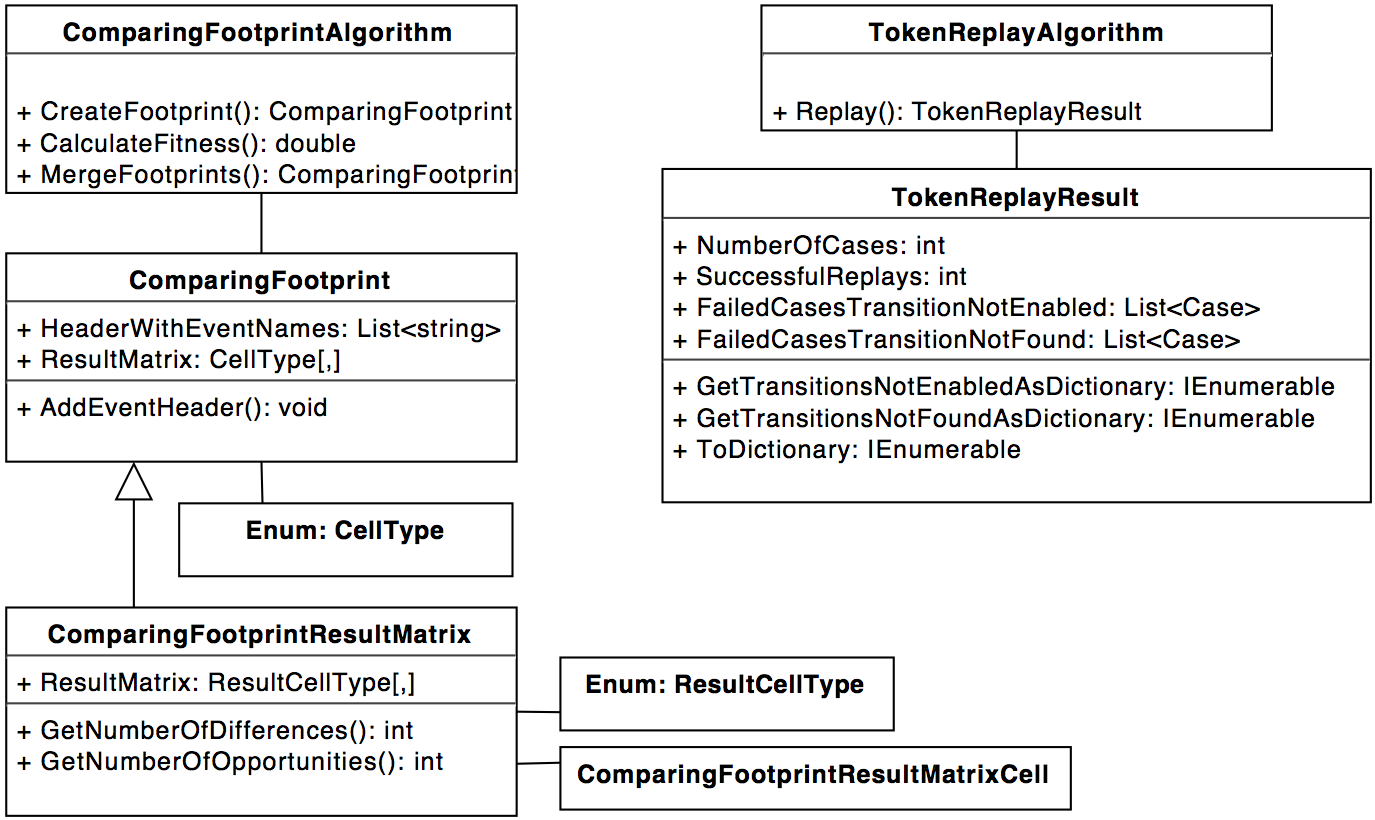
And if you're a fan of conformance checking, have a look at this: