
There are only two pieces of software that will be needed:
- Node.js (which comes with npm—the package manager for Node.js)
- Any code editor
Before writing any code to web scrape using node.js, create a folder where JavaScript files will be stored. These files will contain all the code required for web scraping.
Once the folder is created, navigate to this folder and run the initialization command:
npm init -ynpm install axiosnpm install axios cheerio json2csvOne of the most common scenarios of web scraping with JavaScript is to scrape e-commerce stores. A good place to start is a fictional book store http://books.toscrape.com/. This site is very much like a real store, except that this is fictional and is made to learn web scraping.
The first step before beginning JavaScript web scraping is creating selectors. The purpose of selectors is to identify the specific element to be queried.
Begin by opening the URL http://books.toscrape.com/catalogue/category/books/mystery_3/index.html in Chrome or Firefox. Once the page loads, right-click on the title of the genre, Mystery, and select Inspect. This should open the Developer Tools with <h1>Mystery</h1> selected in the Elements tab.
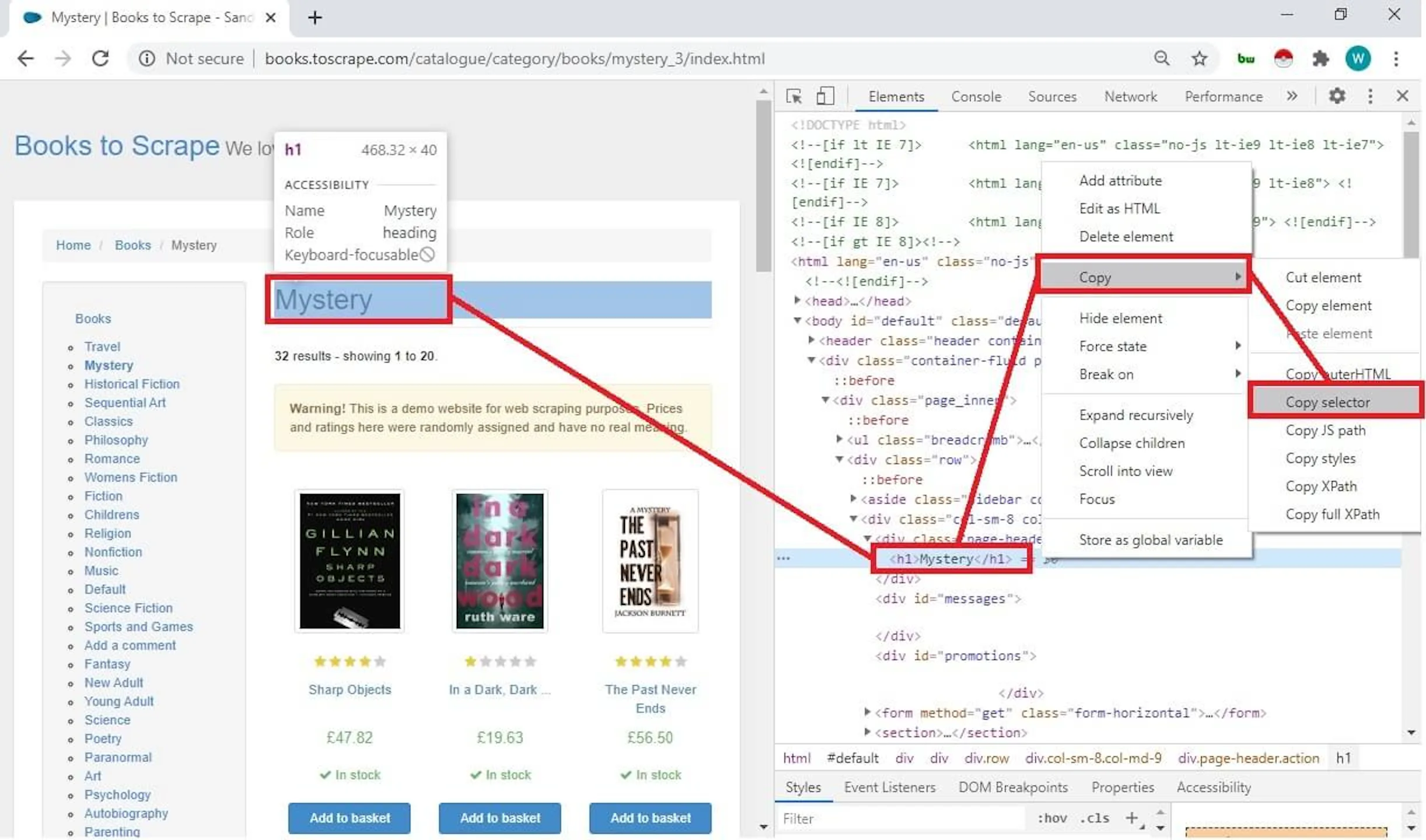
The simplest way to create a selector is to right-click this h1 tag in the Developer Tools, point to Copy, and then click Copy Selector. This will create a selector like this:
#content_inner > article > div.row > div.col-sm-6.product_main > h1This selector is valid and works well. The only problem is that this method creates a long selector. This makes it difficult to understand and maintain the code.
After spending some time with the page, it becomes clear that there is only one h1 tag on the page. This makes it very easy to create a very short selector:
h1The first step is to define the constants that will hold a reference to Axios and Cheerio.
const cheerio = require("cheerio");
const axios = require("axios");The address of the page that is being scraped is saved in the variable URL for readability
const url = "http://books.toscrape.com/catalogue/category/books/mystery_3/index.html";Axios has a method get() that will send an HTTP GET request. Note that this is asynchronous method and thus needs await prefix:
const response = await axios.get(url);If there is a need to pass additional headers, for example, User-Agent, this can be sent as the second parameter:
const response = await axios.get(url, {
headers:
{
"User-Agent": "custom-user-agent string",
}
});This particular site does not need any special header, which makes it easier to learn.
Axios supports both the Promise pattern and the async-await pattern. This tutorial focuses on the async-await pattern. The response has a few attributes like headers, data, etc. The HTML that we want is in the data attribute. This HTML can be loaded into an object that can be queried, using cheerio.load() method.
const $ = cheerio.load(response.data);Cheerio’s load() method returns a reference to the document, which can be stored in a constant. This can have any name. To make our code look and feel more like jQuery web scraping code, a $ can be used instead of a name.
Finding this specific element within the document is as easy as writing . In this particular case, it would be .
The method text() will be used everywhere when writing web scraping code with JavaScript, as it can be used to get the text inside any element. This can be extracted and saved in a local variable.
const genre = $("h1").text();Finally, console.log() will simply print the variable value on the console.
console.log(genre);To handle errors, the code will be surrounded by a try-catch block. Note that it is a good practice to use console.error for errors and console.log for other messages.
Here is the complete code put together. Save it as genre.js in the folder created earlier, where the command npm init was run.
const cheerio = require("cheerio");
const axios = require("axios");
const url = "http://books.toscrape.com/catalogue/category/books/mystery_3/index.html";
async function getGenre() {
try {
const response = await axios.get(url);
const document = cheerio.load(response.data);
const genre = document("h1").text();
console.log(genre);
} catch (error) {
console.error(error);
}
}
getGenre();The final step to run this web scraping in JavaScript is to run it using Node.js. Open the terminal and run this command:
node genre.jsThe output of this code is going to be the genre name:
MysteryCongratulations! This was the first program that uses JavaScript and Node.js for web scraping. Time to do more complex things!
Let’s try scraping listings. Here is the same page that has a book listing of the Mystery genre – http://books.toscrape.com/catalogue/category/books/mystery_3/index.html
First step is to analyze the page and understand the HTML structure. Load this page in Chrome, press F12, and examine the elements.
Each book is wrapped in <article> tag. It means that all these books can be extracted and a loop can be run to extract individual book details. If the HTML is parsed with Cheerio, jQuery function each() can be used to run a loop. Let’s start with extracting title of all the books. Here is the code:
const books = $("article"); //Selector to get all books
books.each(function ()
{ //running a loop
title = $(this).find("h3 a").text(); //extracting book title
console.log(title);//print the book title
});As it is evident from the above code that the extracted details need to be saved somewhere else inside the loop. The best idea would be to store these values in an array. In fact, other attributes of the books can be extracted and stored as a JSON in an array.
Here is the complete code. Create a new file, paste this code and save it as books.js in the same folder that where npm init was run:
const cheerio = require("cheerio");
const axios = require("axios");
const mystery = "http://books.toscrape.com/catalogue/category/books/mystery_3/index.html";
const books_data = [];
async function getBooks(url) {
try {
const response = await axios.get(url);
const $ = cheerio.load(response.data);
const books = $("article");
books.each(function () {
title = $(this).find("h3 a").text();
price = $(this).find(".price_color").text();
stock = $(this).find(".availability").text().trim();
books_data.push({ title, price, stock }); //store in array
});
console.log(books_data);//print the array
} catch (err) {
console.error(err);
}
}
getBooks(mystery);Run this file using Node.js from the terminal:
node books.jsThis should print the array of books on the console. The only limitation of this JavaScript code is that it is scraping only one page. The next section will cover how pagination can be handled.
The listings like this are usually spread over multiple pages. While every site may have its own way of paginating, the most common one is having a next button on every page. The exception is the last, which will not have a next page link.
The pagination logic for these situations is rather simple. Create a selector for the next page link. If the selector results in a value, take the href attribute value and call getBooks function with this new URL recursively.
Immediate after the books.each() loop, add these lines:
if ($(".next a").length > 0) {
next_page = baseUrl + $(".next a").attr("href"); //converting to absolute URL
getBooks(next_page); //recursive call to the same function with new URL
}Note that the href returned above is a relative URL. To convert it into an absolute URL, the simplest way is to concatenate a fixed part to it. This fixed part of the URL is stored in the baseUrl variable
const baseUrl ="http://books.toscrape.com/catalogue/category/books/mystery_3/"Once the scraper reaches the last page, the Next button will not be there and the recursive call will stop. At this point, the array will have book information from all the pages. The final step of web scraping with Node.js is to save the data.
If web scraping with JavaScript is easy, saving data into a CSV file is even easier. It can be done using these two packages —fs and json2csv. The file system is represented by the package fs, which is in-built. json2csv would need to be installed using npm install json2csv command
npm install json2csvafter the installation, create a constant that will store this package’s Parser.
const j2cp = require("json2csv").Parser;The access to the file system is needed to write the file on disk. For this, initialize the fs package.
const fs = require("fs");Find the line in the code where an array with all the scraped is available, and then insert the following lines of code to create the CSV file.
const parser = new j2cp();
const csv = parser.parse(books_data); // json to CSV in memory
fs.writeFileSync("./books.csv", csv); // CSV is now written to diskHere is the complete script put together. This can be saved as a .js file in the node.js project folder. Once it is run using node command on terminal, data from all the pages will be available in books.csv file.
const fs = require("fs");
const j2cp = require("json2csv").Parser;
const axios = require("axios");
const cheerio = require("cheerio");
const mystery = "http://books.toscrape.com/catalogue/category/books/mystery_3/index.html";
const books_data = [];
async function getBooks(url) {
try {
const response = await axios.get(url);
const $ = cheerio.load(response.data);
const books = $("article");
books.each(function () {
title = $(this).find("h3 a").text();
price = $(this).find(".price_color").text();
stock = $(this).find(".availability").text().trim();
books_data.push({ title, price, stock });
});
// console.log(books_data);
const baseUrl = "http://books.toscrape.com/catalogue/category/books/mystery_3/";
if ($(".next a").length > 0) {
next = baseUrl + $(".next a").attr("href");
getBooks(next);
} else {
const parser = new j2cp();
const csv = parser.parse(books_data);
fs.writeFileSync("./books.csv", csv);
}
} catch (err) {
console.error(err);
}
}
getBooks(mystery);Run this file using Node.js from the terminal:
node books.js