Matching
For Schema Matching and Identity Resolution, the MatchingEngine facade provides a starting point for many common operations. The following Figure gives an overview of the rule-based matching process:
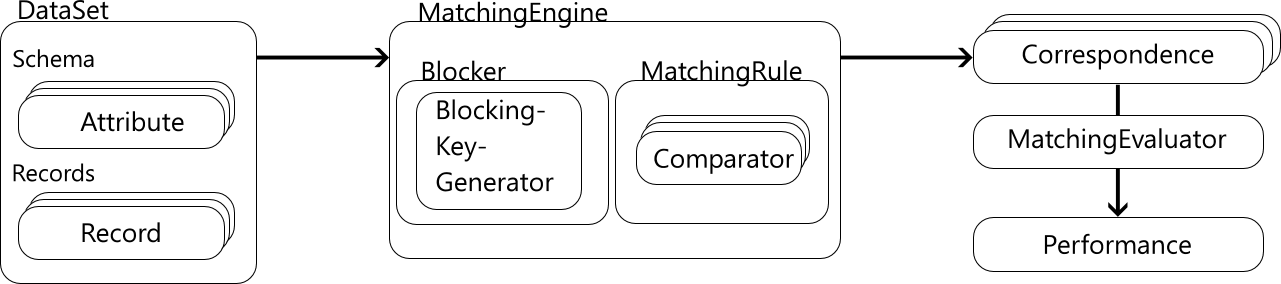
Data is stored in DataSets, which can contain a schema and records. These datasets are passed to the MatchingEngine, which first runs a Blocker such as the StandardRecordBlocker or StandardSchemaBlocker. These blockers use a BlockingKeyGenerator to generate blocking key values from attributes or records. The result of the blocking is a set of attribute or record pairs, which are then evaluated by a MatchingRule, which internally uses Comparators that calculate similarity values. For example, the LinearCombinationMatchingRule allows you to specify different weights for the comparators and a final threshold for the combined similarity value. The result of the matching operation is a set of Correspondences. Given these correspondences and a MatchingGoldStandard, the MatchingEvaluator calculates a Performance that contains Precision, Recall, and F1-Measure.
For schema matching and identity resolution, the MatchingEngine facade provides implementations for the following matching operations:
Finds duplicate records in a single data set (duplicate detection) or in two different data sets (identity resolution). Uses a Blocker to generate tokens from the records and a CorrespondenceAggregator to calculate a similarity value from the matching tokens.
Finds duplicate records in a single data set (duplicate detection) or in two different data sets (identity resolution). Accepts a MatchingRule and a Blocker as parameters. First, the Blocker is used to generate candidate pairs of records, which are then evaluated using the MatchingRule.
Finds similar attributes in two different data sets by applying a comparator to attribute names. A comparator specifies value pre-processing and a similarity measure to compare the values.
Finds similar attributes in two different data sets by comparing the values of attributes. Uses a Blocker to generate tokens from the attribute values and a CorrespondenceAggregator to calculate a similarity value from the matching tokens.
Finds similar attributes in two different data sets by comparing the values of duplicate records in both datasets. Accepts the correspondences between duplicate records, a SchemaMatchingRule and a SchemaBlocker as parameters. First, the SchemaBlocker is used to generate possible pairs of attributes. Then, the SchemaMatchingRule is applied to the values of all generated pairs for all duplicate records. Finally, the voting definition of the SchemaMatchingRule is used to aggregate the results to corespondences between attributes.
Internally, the MatchingEngine uses the algorithms from the de.uni_mannheim.informatik.wdi.matching.algorithms package. These algorithms are composed of different building blocks, which can be re-used for the implementation of further algorithms. There are three types of building blocks: blockers, matching rules and aggregators:
Blockers: A blocker transforms one or multiple datasets into pairs of records. The main objective is to reduce the number of comparisons that have to be performed in the subsequent steps while still keeping the pairs that are actual matches. The blockers can receive correspondences as additional input. These can be used to perform the blocking and/or can be added to the generated pairs to be used by the following matcher.
MatchingRule: A matching rule is applied to a pair of records and determines if they are a match or not. A pair can contain additional correspondences that can be used by the matching rule to make its decision. There are two different types of matching rules:
Filtering Matching Rule: receives a pair of records and possibly many correspondences from the blocker and decides if this pair is a match, in which case it is produced as correspondence. Non-matching pairs are filtered out.
Aggregable Matching Rule: receives a pair of records and one of the correspondences from the blocker and decides if this pair is a match, in which case it is produced as correspondence. If multiple correspondences exist for a pair, it can create multiple output correspondences (which act as votes). The rule also specifies how such correspondences should be grouped for aggregation by an Aggregator.
Aggregators: An aggregator combines multiple correspondences by aggregating their similarity scores. Such aggregations can be sum, average, voting or top-k.
These building blocks can be combined into two basic matcher architectures:
(1) Rule-based Matching
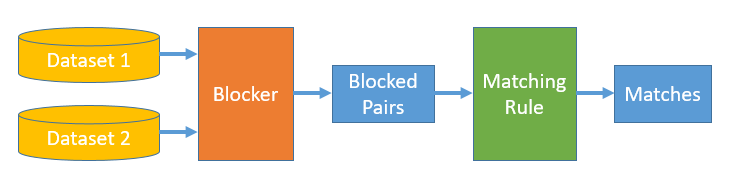
(2) Voting-based Matching

Standard Blocker: Uses a blocking key generator to define record pairs. One or multiple blocking keys are generated for each record. All records with the same blocking key form a “block”. All possible pairs of records from the same block are created as result.
Sorted Neighbourhood Method: The records are sorted by their blocking key. Then, a sliding window is applied to the data and each record is paired with its neighbours.
LinearCombinationMatchingRule (FilteringMatchingRule): Applies a pre-defined set of comparators to the pair of records and calculates a linear combination of their scores as similarity value.
VotingMatchingRule (AggregatableMatchingRule): Creates a correspondence for each causal correspondence provided by the blocker. In duplicate-based schema matching, the blocker creates the duplicates as causes for the attribute pairs and the voting rule then casts a vote for each duplicate.
CorrespondenceAggregator: Aggregates the scores of correspondences in the same group. Possible Configurations: Sum, Count, Average, Voting
TopKAggregator: Filters out all but the k correspondences with the highest similarity per group.