
 |
 |
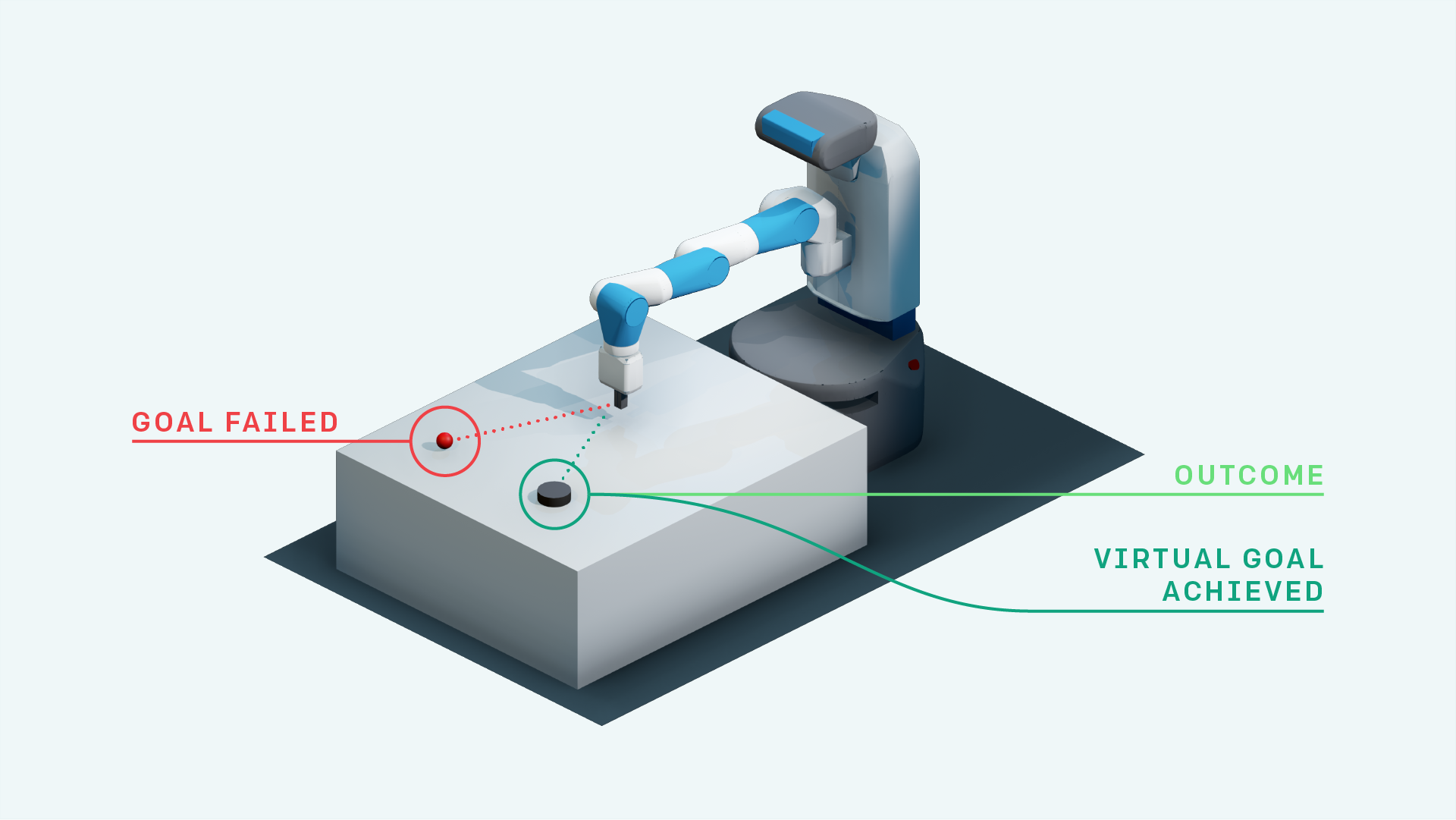 |
This repository contains all standard model-free and model-based(coming) RL algorithms in Pytorch. (May also contain some research ideas I am working on currently)
For C++ version of Pytorch-RL : Pytorch-RL-CPP
pytorch-rl implements some state-of-the art deep reinforcement learning algorithms in Pytorch, especially those concerned with continuous action spaces. You can train your algorithm efficiently either on CPU or GPU. Furthermore, pytorch-rl works with OpenAI Gym out of the box. This means that evaluating and playing around with different algorithms is easy. Of course you can extend pytorch-rl according to your own needs. TL:DR : pytorch-rl makes it really easy to run state-of-the-art deep reinforcement learning algorithms.
Install Pytorch-rl from Pypi (recommended):
pip install pytorch-policy
- Pytorch
- Gym (OpenAI)
- mujoco-py (For the physics simulation and the robotics env in gym)
- Pybullet (Coming Soon)
- MPI (Only supported with mpi backend Pytorch installation)
- Tensorboardx (https://github.com/lanpa/tensorboardX)
- DQN (with Double Q learning)
- DDPG
- DDPG with HER (For the OpenAI Fetch Environments)
- Heirarchical Reinforcement Learning
- Prioritized Experience Replay + DDPG
- DDPG with Prioritized Hindsight experience replay (Research)
- Neural Map with A3C (Coming Soon)
- Rainbow DQN (Coming Soon)
- PPO (https://github.com/ikostrikov/pytorch-a2c-ppo-acktr)
- HER with self attention for goal substitution (Research)
- A3C (Coming Soon)
- ACER (Coming Soon)
- DARLA
- TDM
- World Models
- Soft Actor-Critic
- Empowerment driven Exploration (Tensorflow implementation : https://github.com/navneet-nmk/Empowerment-driven-Exploration)
- Breakout
- Pong (coming soon)
- Hand Manipulation Robotic Task
- Fetch-Reach Robotic Task
- Hand-Reach Robotic Task
- Block Manipulation Robotic Task
- Montezuma's Revenge (Current Research)
- Pitfall
- Gravitar
- CarRacing
- Super Mario Bros (Follow instructions to install gym-retro https://github.com/openai/retro)
- OpenSim Prosthetics Nips Challenge (https://www.crowdai.org/challenges/nips-2018-ai-for-prosthetics-challenge)
Multiple GAN training tricks have been used because of the instability in training the generators and discriminators. Please refer to https://github.com/soumith/ganhacks for more information.
Even after using the tricks, it was really hard to train a GAN to convergence. However, after using Spectral Normalization (https://arxiv.org/abs/1802.05957) the infogan was trained to convergence.
For image to image translation tasks with GANs and for VAEs in general, training with Skip Connection really helps the training.
- beta-VAE
- InfoGAN
- CVAE-GAN
- Flow based generative models (Research)
- SAGAN
- Sequential Attend, Infer, Repeat
- Curiosity driven exploration
- Parameter Space Noise for Exploration
- Noisy Network
- Playing Atari with Deep Reinforcement Learning, Mnih et al., 2013
- Human-level control through deep reinforcement learning, Mnih et al., 2015
- Deep Reinforcement Learning with Double Q-learning, van Hasselt et al., 2015
- Continuous control with deep reinforcement learning, Lillicrap et al., 2015
- CVAE-GAN: Fine-Grained Image Generation through Asymmetric Training, Bao et al., 2017
- beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework, Higgins et al., 2017
- Hindsight Experience Replay, Andrychowicz et al., 2017
- InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets, Chen et al., 2016
- World Models, Ha et al., 2018
- Spectral Normalization for Generative Adversarial Networks, Miyato et al., 2018
- Self-Attention Generative Adversarial Networks, Zhang et al., 2018
- Curiosity-driven Exploration by Self-supervised Prediction, Pathak et al., 2017
- Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor, Haarnoja et al., 2018
- Parameter Space Noise for Exploration, Plappert et al., 2018
- Noisy Network for Exploration, Fortunato et al., 2018
- Proximal Policy Optimization Algorithms, Schulman et al., 2017
- Unsupervised Real-Time Control through Variational Empowerment, Karl et al., 2017
- Mutual Information Neural Estimation, Belghazi et al., 2018
- Empowerment-driven Exploration using Mutual Information Estimation, Kumar et al., 2018