

This repository contains the code for the indexed_bzip2 and rapidgzip Python modules.
Both are built upon the same basic architecture to enable block-parallel decoding based on prefetching and caching.

This module provides:
- a
rapidgzipcommand line tool for parallel decompression of gzip files with a similar command line interface togzipso that it can be used as a replacement. - a
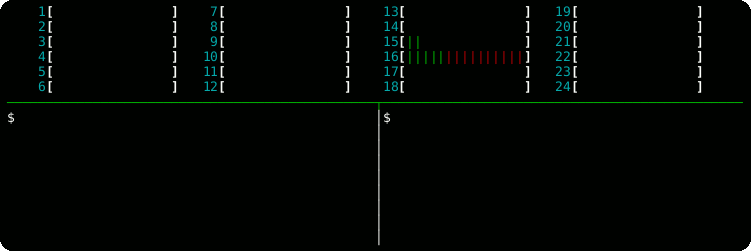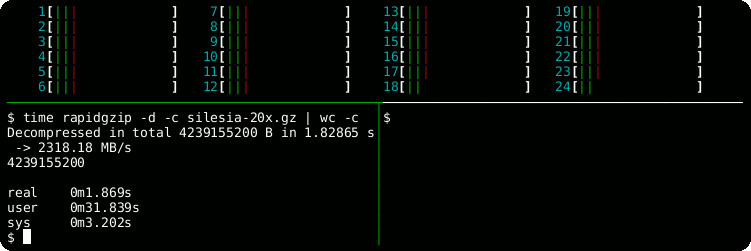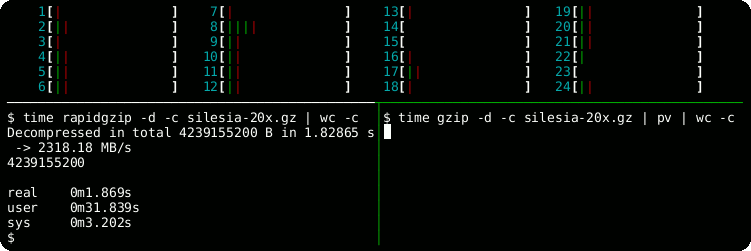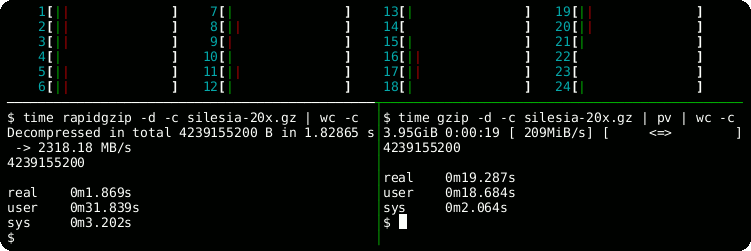
rapidgzip.openPython method for reading and seeking inside gzip files using multiple threads for a speedup of 21 over the built-in gzip module using a 12-core processor.
The random seeking support is similar to the one provided by indexed_gzip, and the parallel capabilities are effectively a working version of pugz, which is only a concept and only works with a limited subset of file contents, namely non-binary (ASCII characters 0 to 127) compressed files.
| Module | Bandwidth / (MB/s) | Speedup |
|---|---|---|
| gzip | 250 | 1 |
| rapidgzip with parallelization = 1 | 488 | 1.9 |
| rapidgzip with parallelization = 2 | 902 | 3.6 |
| rapidgzip with parallelization = 12 | 4463 | 17.7 |
| rapidgzip with parallelization = 24 | 5240 | 20.8 |
See here for the extended Readme.
There also exists a dedicated repository for rapidgzip here. It was created for visibility reasons and in order to keep indexed_bzip2 and rapidgzip releases separate. The main development will take place in this repository, while the rapidgzip repository will be updated at least for each release. Issues regarding rapidgzip should be opened at its repository.
A paper describing the implementation details and showing the scaling behavior with up to 128 cores has been submitted to and accepted in ACM HPDC'23, The 32nd International Symposium on High-Performance Parallel and Distributed Computing. If you use this software for your scientific publication, please cite it as stated here. The author's version can be found here and the accompanying presentation here.



This module provides:
- an
ibzip2command line tool to decompress bzip2 files in parallel with a similar command line interface tobzip2so that it can be used as a replacement. - an
ibzip2.openPython method for reading and seeking inside bzip2 files using multiple threads for a speedup of 6 over the built-in bzip2 module using a 12-core processor.
The parallel decompression capabilities are similar to lbzip2 but with a more permissive license and with support to be used as a library with random seeking capabilities similar to seek-bzip2.
| Module | Runtime / s | Bandwidth / (MB/s) | Speedup |
|---|---|---|---|
| bz2 | 386 | 5.2 | 1 |
| indexed_bzip2 with parallelization = 1 | 472 | 4.2 | 0.8 |
| indexed_bzip2 with parallelization = 2 | 265 | 7.6 | 1.5 |
| indexed_bzip2 with parallelization = 12 | 64 | 31.4 | 6.1 |
| indexed_bzip2 with parallelization = 24 | 63 | 31.8 | 6.1 |
See here for the extended Readme.
The CMake options have been prefixed with librapidarchive.
This difficult decision came about because neither RAPIDGZIP_ nor IBZIP2_ would have made sense.
I needed an umbrella name for both, and possibly further compression formats such as LZ4 and ZIP in the future.
I aim for something akin to libarchive, but with support for parallelized decompression and constant-time seeking instead of streaming extraction because it is to be used as a backend for ratarmount.
The project started inside the ratarmount as a random-seekable bzip2 backend.
After troubles with compiling a Python C-extension and after noticing that this backend might also find usage on its own, I created the indexed_bzip2 repository, following the naming scheme of indexed_gzip to make it easily discoverable, e.g., in the PyPI search.
After adding novel parallelized and seekable gzip decompression support and shortly before publishing the paper, I split off yet another repository and project called rapidgzip, which became more well-known than indexed_bzip2.
Reasons for not including rapidgzip in indexed_bzip2:
- Much more complicated build setup with rpmalloc, zlib, and ISA-L, which might fail to build on more systems than
indexed_bzip2when there are no wheels available. On the other hand,indexed_bzip2only requires building its own C++ header-only sources. These dependencies are also the reason for failing to get it merged into Conda while Condaindexed_bzip2exists. - The rapidgzip Python module binary is also almost 10x larger because of large precomputed lookup tables and templating.
- Releases, especially on Github. Many recent changes were only for rapidgzip, not
indexed_bzip2. It makes sense to have different releases for these projects and also to keep them on different Github release pages. - More visibility:
- Similar to how none would guess that
bsdtaris able to extract archives other than TAR, it makes no sense to expect something calledindexed_bzip2to also work for gzip, etc.libarchive, which providesbsdtar, makes much more sense as a name. - They have different ReadMe files with different usages and benchmarks. Showing these top-level in the specialized repositories is nice.
- Similar to how none would guess that
- Note that the Python package
rapidgzipdoes not even bundleindexed_bzip2. It can even natively open bzip2 withRapidGzipFile, but this uses a different algorithm, which is less specialized to bzip2 and therefore has more memory overhead and might be slightly slower. Until this does not have feature and performance parity, it makes sense to have two projects.
Downsides:
- I am not sure how well the
rapidgzipandindexed_bzip2Python modules work when loaded at the same time. There may be name collisions resulting in problems. It might be best to make the namespace, currentlyrapidgzip::, adjustable and use something else for each Python package. Currently, I am sidestepping this issue in ratarmount by includingindexed_bzip2in therapidgzipPython package because it is trivial and low-overhead to do so. So, if you need to use both, depend onrapidgzipfor now. - Contributions and attention are split between all these projects, also resulting in confusion.
I have mitigated it somewhat by adding a pull request template on the rapidgzip repository pointing to
indexed_bzip2.
I think, in the future, I'll avoid starting new repositories and simply release specialized Packages from this one or even only alias Python packages, which point to / depend on rapidgzip or a hypothetical librapidarchive.
Licensed under either of
- Apache License, Version 2.0, (LICENSE-APACHE or http://www.apache.org/licenses/LICENSE-2.0)
- MIT license (LICENSE-MIT or http://opensource.org/licenses/MIT)
at your option.
Unless you explicitly state otherwise, any contribution intentionally submitted for inclusion in the work by you, as defined in the Apache-2.0 license, shall be dual licensed as above, without any additional terms or conditions.