This project ensures secure financial transactions by seamlessly integrating an anti-fraud microservice. This solution validates every transaction, providing real-time status updates for enhanced security and transparency in the financial operations.
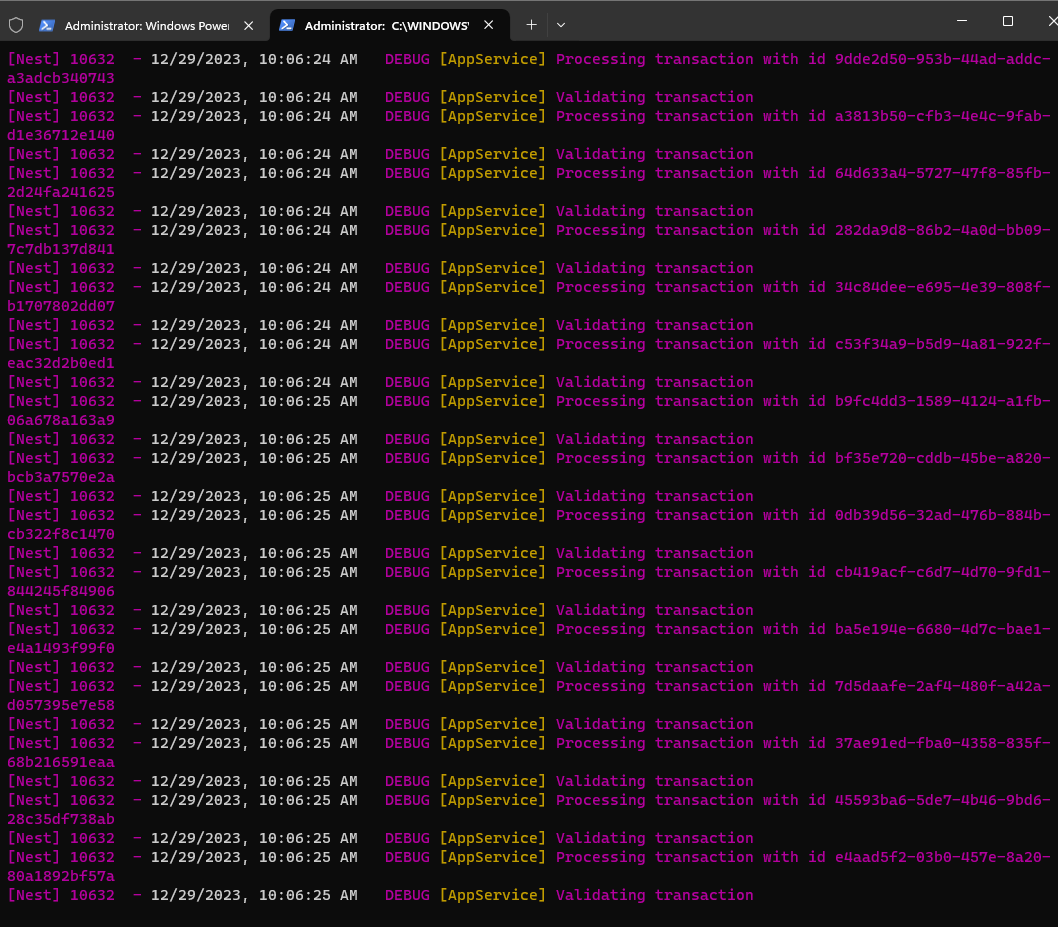
Microservices architecture, where a financial transaction triggers validation through an anti-fraud microservice, seamlessly updating its status based on a defined rule set. Transactions exceeding 1000 are automatically rejected, ensuring a dynamic and secure system with statuses of pending, approved, or rejected.
- getAll(): Get all transactions. For interacting and testing purposes.
- getOne(): Get a transaction by ID. For interacting and testing purposes.
- save(transaction): Store a transaction in PostgreSQL. For interacting and testing purposes.
- updateStatus(transactionId, newStatus): Update a transaction status by id and Status enum, based on the result of anti-fraud validation.
- processTransaction(transaction): Process transaction on creation in Kafka topic by Transaction microservice.
- validateTransaction(transaction): Performs anti-fraud checks on the transaction and process business rules (> 1000).
- sendStatus(transactionId, status): Send transaction status validation results to Kafka topic.
- Server: NodeJS v.18.19.0, NPM v.10.2.3
- Programming languages: Typescript
- Framework: NestJS
- DB: PostgreSQL
- ORM: TypeORM
- MS communications: Apache Kafka
- Logging: Log4js
- Unit testing: Jest
Important: Use the .env.template file and save it as .env.
- server=localhost // DB_HOST DB server path
- port=5432 // DB_PORT DB server port
- database=postgres // DB name
- username=postgres // DB_USERNAME DB username
- password=postgres // DB_PASSWORD DB password
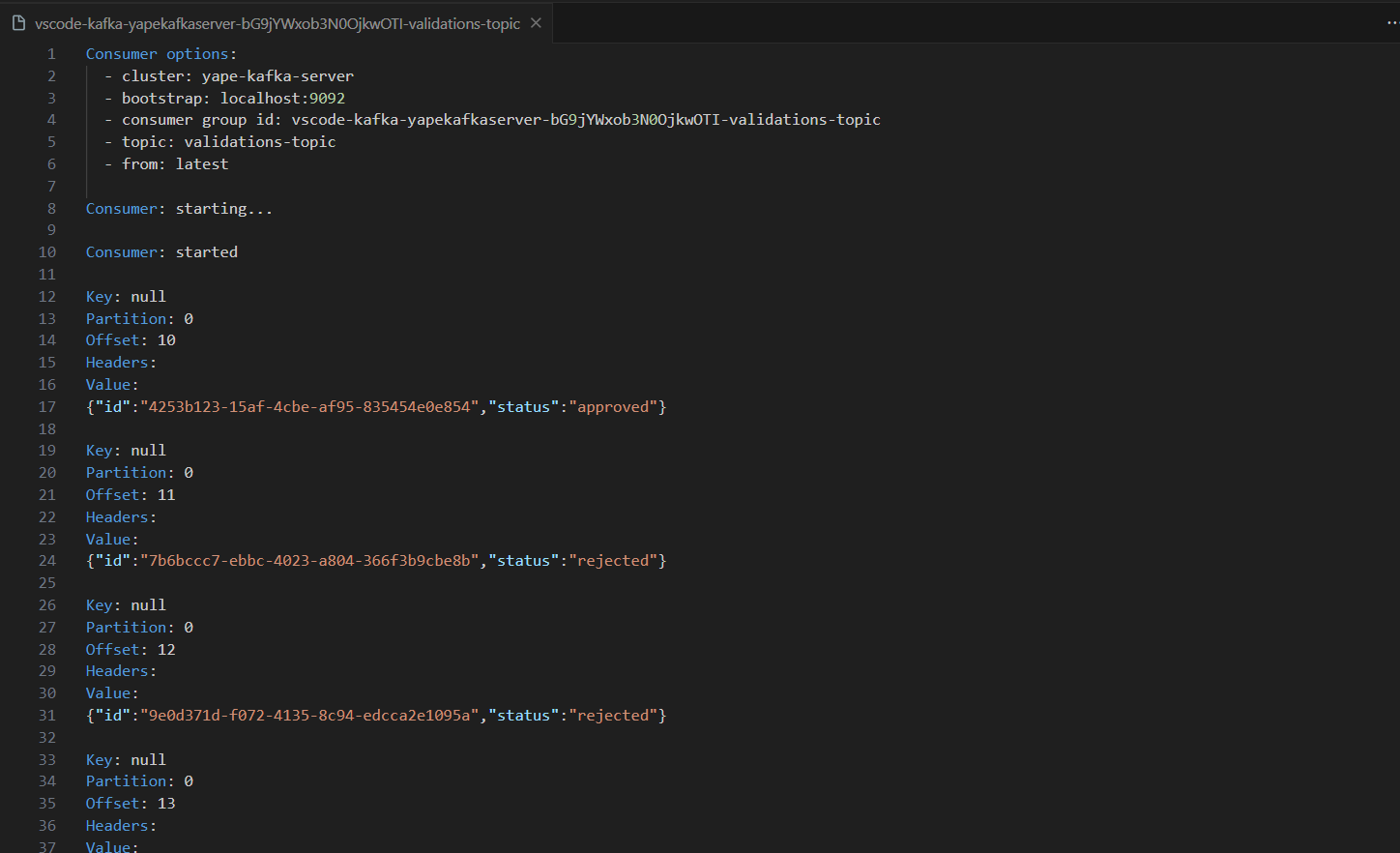
*Important: Create mandatory topics in order to run the project: 'transactions-topic' and 'validations-topic'.
Using log4js for each microservice, communications and persistance.
curl --location 'localhost:3000/transaction' \
--header 'Content-Type: application/json' \
--data '{
"accountExternalIdDebit": "Guid",
"accountExternalIdCredit": "Guid",
"transferTypeId": 1,
"value": 999
}'





To address the high-volume scenarios with a significant amount of concurrent reads and writes for transaction data, especially when utilizing GraphQL, you can employ the following strategies:
Distribute the transaction data across multiple database servers based on a shard key (e.g., transaction ID, user ID). This allows for parallel reads and writes, improving overall throughput.
Implement caching mechanisms, both at the GraphQL layer and the database layer, to reduce the load on the database for frequently accessed data. Consider using in-memory caches or distributed caching solutions.
Leverage GraphQL batch processing techniques to efficiently fetch and process multiple requests in a single database query. Tools like DataLoader can help in batching and caching requests to optimize database interactions.
Ensure that the database is properly indexed based on the common query patterns in your GraphQL schema. Optimize database queries and schema design to minimize the impact of high read and write volumes.
Set up read replicas of the database to handle read-intensive operations. This allows for horizontal scaling of read operations, distributing the load across multiple replica servers.
For operations that do not require real-time responses, consider using asynchronous processing. Offload time-consuming tasks, such as sending notifications or performing background validations, to separate worker processes or queues.
Employ load balancing techniques at both the GraphQL layer and the database layer to distribute incoming requests evenly across multiple servers. This helps prevent bottlenecks and ensures better resource utilization.
Use connection pooling to manage database connections efficiently. This helps avoid the overhead of opening and closing connections for each transaction, improving the overall performance of the system.
Implement result caching at the GraphQL layer to store and reuse the results of frequently executed queries. This can significantly reduce the load on the underlying systems.
Implement optimistic updates in the GraphQL layer, allowing the client to assume the success of a mutation while the actual update is being processed in the background. This enhances the perceived performance for users.