





Welcome to PyTorch Essentials, a comprehensive repository covering the power and versatility of PyTorch, a cutting-edge deep learning library.
PyTorch is not just a library; it's a revolution in the world of deep learning. Here are some reasons why PyTorch stands out:
-
Dynamic Computation Graph: PyTorch's dynamic computation graph allows for intuitive debugging and dynamic neural network architectures, making it ideal for research and experimentation.
-
Efficient GPU Utilization: Leveraging CUDA and cuDNN, PyTorch maximizes GPU performance, accelerating deep learning computations and training times.
-
Native Pythonic Interface: PyTorch's Pythonic syntax makes it easy to learn and use, facilitating rapid prototyping and code readability.
-
Rich Ecosystem: With support for computer vision, natural language processing, reinforcement learning, and more, PyTorch offers a rich ecosystem of tools and libraries for diverse deep learning tasks.
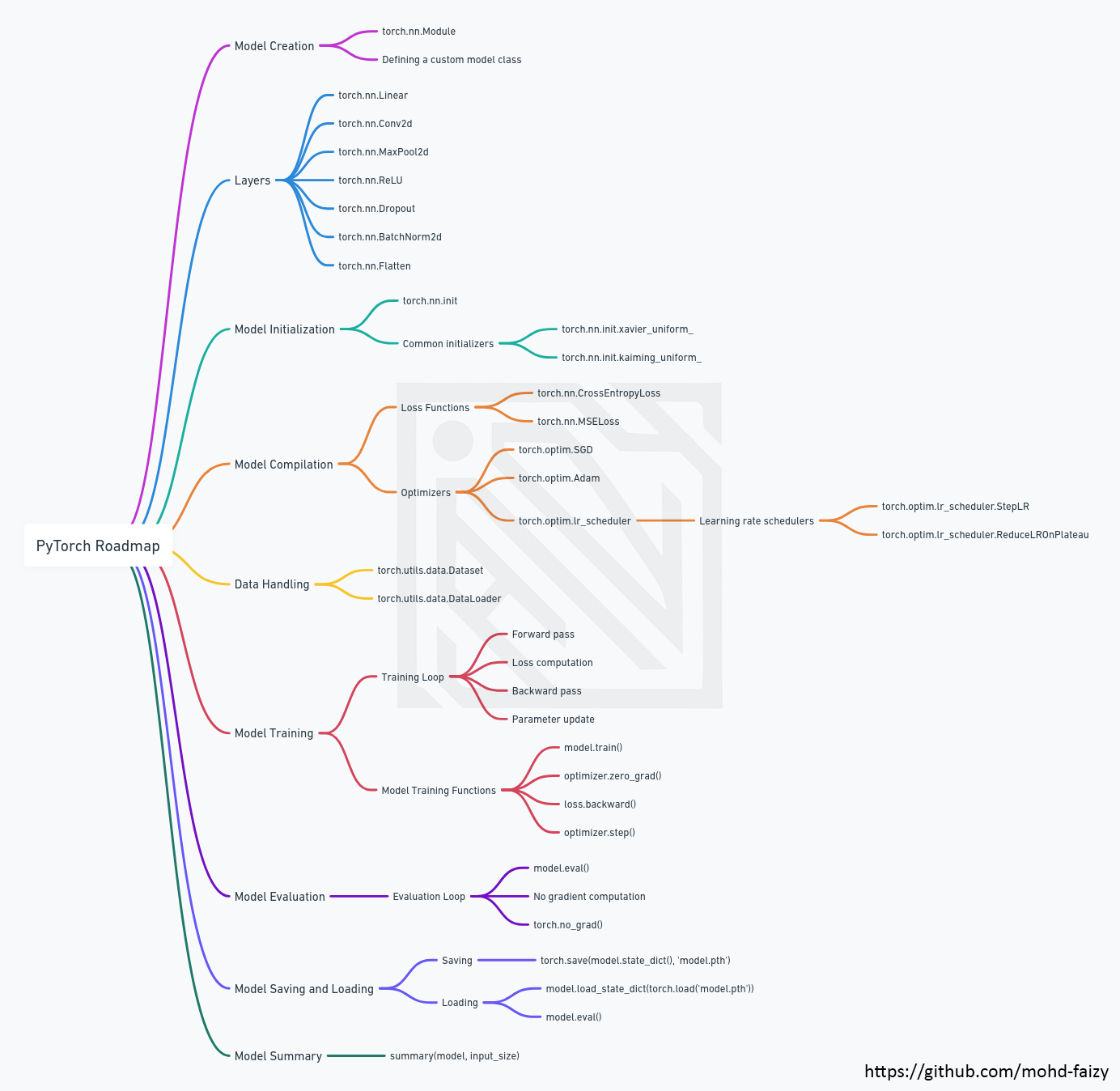
This repository covers a wide range of topics, including:
-
Fundamentals of PyTorch: Learn about tensors, operations, autograd, and optimization techniques.
-
GPU Usage Optimization: Explore strategies to efficiently utilize GPUs for accelerated deep learning workflows.
-
Delve into advanced concepts like:
- 👁️Computer Vision: Dive into image classification, object detection, image segmentation, and transfer learning using PyTorch.
- 🔊Natural Language Processing: Discover how PyTorch powers state-of-the-art NLP models for tasks like sentiment analysis, language translation, and text generation.
- 🖼️Generative Models: Explore how to create entirely new data, like generating realistic images or writing creative text.
- 🛠️Reinforcement Learning: Train models to learn optimal strategies through interaction with an environment.
-
Custom Datasets and Data Loading: Master the art of creating custom datasets and efficient data loading pipelines in PyTorch.
-
Modular Workflows: Build modular and scalable deep learning pipelines for seamless experimentation and model deployment.
-
Experiment Tracking: Learn best practices for experiment tracking, model evaluation, and hyperparameter tuning.
-
Replicating Research Papers: Replicate cutting-edge research papers and implement state-of-the-art deep learning models.
-
Model Deployment: Explore techniques for deploying PyTorch models in production environments, including cloud deployments and edge devices.
-
Bonus: Dive into the exciting world of PyTorch Lightning, a framework that streamlines the machine learning development process.
| Category | Import Code Example | Description | See |
|---|---|---|---|
| Imports | import torch |
Root package | |
from torch.utils.data import Dataset, DataLoader |
Dataset representation and loading | ||
| Neural Network API | import torch.autograd as autograd |
Computation graph | autograd |
from torch import Tensor |
Tensor node in the computation graph | ||
import torch.nn as nn |
Neural networks | nn | |
import torch.nn.functional as F |
Layers, activations, and more | functional | |
import torch.optim as optim |
Optimizers (e.g., gradient descent, ADAM, etc.) | optim | |
from torch.jit import script, trace |
Hybrid frontend decorator and tracing JIT | Torchscript | |
| TorchScript and JIT | torch.jit.trace() |
Traces computational steps of data input through the model | Torchscript |
@script |
Decorator indicating data-dependent control flow | Torchscript | |
| ONNX | torch.onnx.export(model, dummy data, xxxx.proto) |
Exports ONNX formatted model using trained model, dummy data, and file name | onnx |
model = onnx.load("alexnet.proto") |
Loads an ONNX model | onnx | |
onnx.checker.check_model(model) |
Checks that the model IR is well-formed | onnx | |
onnx.helper.printable_graph(model.graph) |
Prints a human-readable representation of the graph | onnx | |
| Vision | from torchvision import datasets, models, transforms |
Vision datasets, architectures & transforms | torchvision |
import torchvision.transforms as transforms |
Composable transforms | torchvision | |
| Distributed Training | import torch.distributed as dist |
Distributed communication | distributed |
from torch.multiprocessing import Process |
Memory sharing processes | multiprocessing | |
| Tensors | x = torch.randn(*size) |
Tensor with independent N(0,1) entries | tensor |
x = torch.[ones/zeros](*size) |
Tensor with all 1's [or 0's] tensor | ||
x = torch.tensor(L) |
Create tensor from [nested] list or ndarray L | tensor | |
y = x.clone() |
Clone of x | tensor | |
with torch.no_grad(): |
Code wrap that stops autograd from tracking tensor history | tensor | |
requires_grad=True |
Arg, when set to True, tracks computation history for future derivative calculations | tensor | |
| Dimensionality | x.size() |
Returns tuple-like object of dimensions | tensor |
x = torch.cat(tensor_seq, dim=0) |
Concatenates tensors along dim | tensor | |
y = x.view(a,b,...) |
Reshapes x into size (a,b,...) | tensor | |
y = x.view(-1,a) |
Reshapes x into size (b,a) for some b | tensor | |
y = x.transpose(a,b) |
Swaps dimensions a and b | tensor | |
y = x.permute(*dims) |
Permutes dimensions | tensor | |
y = x.unsqueeze(dim) |
Tensor with added axis | tensor | |
y = x.unsqueeze(dim=2) |
(a,b,c) tensor -> (a,b,1,c) tensor | tensor | |
y = x.squeeze() |
Removes all dimensions of size 1 (a,1,b,1) -> (a,b) | tensor | |
y = x.squeeze(dim=1) |
Removes specified dimension of size 1 (a,1,b,1) -> (a,b,1) | tensor | |
| Algebra | ret = A.mm(B) |
Matrix multiplication | math operations |
ret = A.mv(x) |
Matrix-vector multiplication | math operations | |
x = x.t() |
Matrix transpose | math operations | |
| GPU Usage | torch.cuda.is_available |
Check for CUDA | cuda |
x = x.cuda() |
Move x's data from CPU to GPU and return new object | cuda | |
x = x.cpu() |
Move x's data from GPU to CPU and return new object | cuda | |
if not args.disable_cuda and torch.cuda.is_available(): |
Device agnostic code and modularity | cuda | |
args.device = torch.device('cuda') |
Set device to CUDA | cuda | |
net.to(device) |
Recursively convert parameters and buffers to device-specific tensors | cuda | |
x = x.to(device) |
Copy tensors to a device (GPU, CPU) | cuda | |
| Deep Learning | nn.Linear(m,n) |
Fully connected layer from m to n units | nn |
nn.ConvXd(m,n,s) |
X dimensional conv layer from m to n channels where X⍷{1,2,3} and the kernel size is s | nn | |
nn.MaxPoolXd(s) |
X dimension pooling layer | nn | |
nn.BatchNormXd |
Batch norm layer | nn | |
nn.RNN/LSTM/GRU |
Recurrent layers | nn | |
nn.Dropout(p=0.5, inplace=False) |
Dropout layer for any dimensional input | nn | |
nn.Dropout2d(p=0.5, inplace=False) |
2-dimensional channel-wise dropout | nn | |
nn.Embedding(num_embeddings, embedding_dim) |
Mapping from indices to embedding vectors | nn | |
| Loss Functions | nn.X |
Where X is various loss functions | loss functions |
| Activation Functions | nn.X |
Where X is various activation functions | activation functions |
| Optimizers | opt = optim.x(model.parameters(), ...) |
Create optimizer | optimizers |
opt.step() |
Update weights | optimizers | |
| Learning rate scheduling | scheduler = optim.X(optimizer,...) |
Create LR scheduler | learning rate scheduler |
scheduler.step() |
Harness the unparalleled processing power of GPUs for:
- Faster Training: Train complex models significantly faster on GPUs compared to CPUs.
- Larger Datasets: Tackle larger and more intricate datasets that would be prohibitive on CPUs.
- Experimentation Efficiency: Accelerate your experimentation process by iterating through models more rapidly.
We'll guide you through setting up GPU acceleration with Nvidia CUDA for a seamless experience (if applicable).
- Modular Codebase: Organize your PyTorch projects for clarity, maintainability, and scalability.
- Separate data preprocessing, model definition, training, and evaluation into well-defined modules.
- Promote code reusability and streamline complex projects.
- Custom Datasets: Tailor datasets to your specific needs. Learn how to create custom datasets for diverse applications.
- Load and preprocess data efficiently for optimal model performance.
Stand on the shoulders of giants:
- Benefit from pre-trained models trained on large-scale datasets, saving time and resources.
- Fine-tune pre-trained models for your specific tasks, achieving excellent results faster.
- Implement robust experiment tracking for systematic analysis:
- Log hyperparameters, model architectures, and training details seamlessly.
- Compare and reproduce experiments effortlessly for iterative improvement.
- Integrate with tools like Weights & Biases or MLflow for enhanced visualization and collaboration (optional).
Unravel the magic behind research papers:
- Follow along with detailed walkthroughs of groundbreaking PyTorch research papers in various domains.
- Replicate research and gain an in-depth understanding of advanced deep learning techniques.
- Bridge the gap between theoretical concepts and practical implementation.
Prepare your models for real-world scenarios:
- Learn strategies for converting PyTorch models into formats suitable for deployment in production environments.
- Explore serving frameworks like TorchScript or ONNX for efficient model inference.
Contributions are welcome!
- A heartfelt thank you to the following resources that inspired this Repository:
This project is licensed under the MIT License. See LICENSE for details.
If you find this repository helpful, show your support by starring it! For questions or feedback, reach out on Twitter(X).
➤ If you have questions or feedback, feel free to reach out!!!