Analysis of Pathological Images, is an open-source project to analyze pathological images and extract as much information from them as possible. Also, it tries to use the extracted information to show the types of tumors and other issues. in the following the steps of the project is shown.

Windows (These scripts modified for windows version 10)
python >3.6
1: Preprocessing
In this step, noise, background, and useless information are removed from input images.
For example, after pre-processing source image (A), converted to (B).
A: source image

B: pre-processed image

2: OCR
In this phase, all texts are extracted from the pre-processed image.
OCR engines:
Notes:
- In the first running some models will be downloaded.
For each image two types of ocr will be extended:
1. English OCR
2. Persian ocr
3- Analysis
In the last step, information which extracted from the OCR text are analyzed: This data classified into 3 types of information:
- Personal information
- Clinical information
- Tumor information
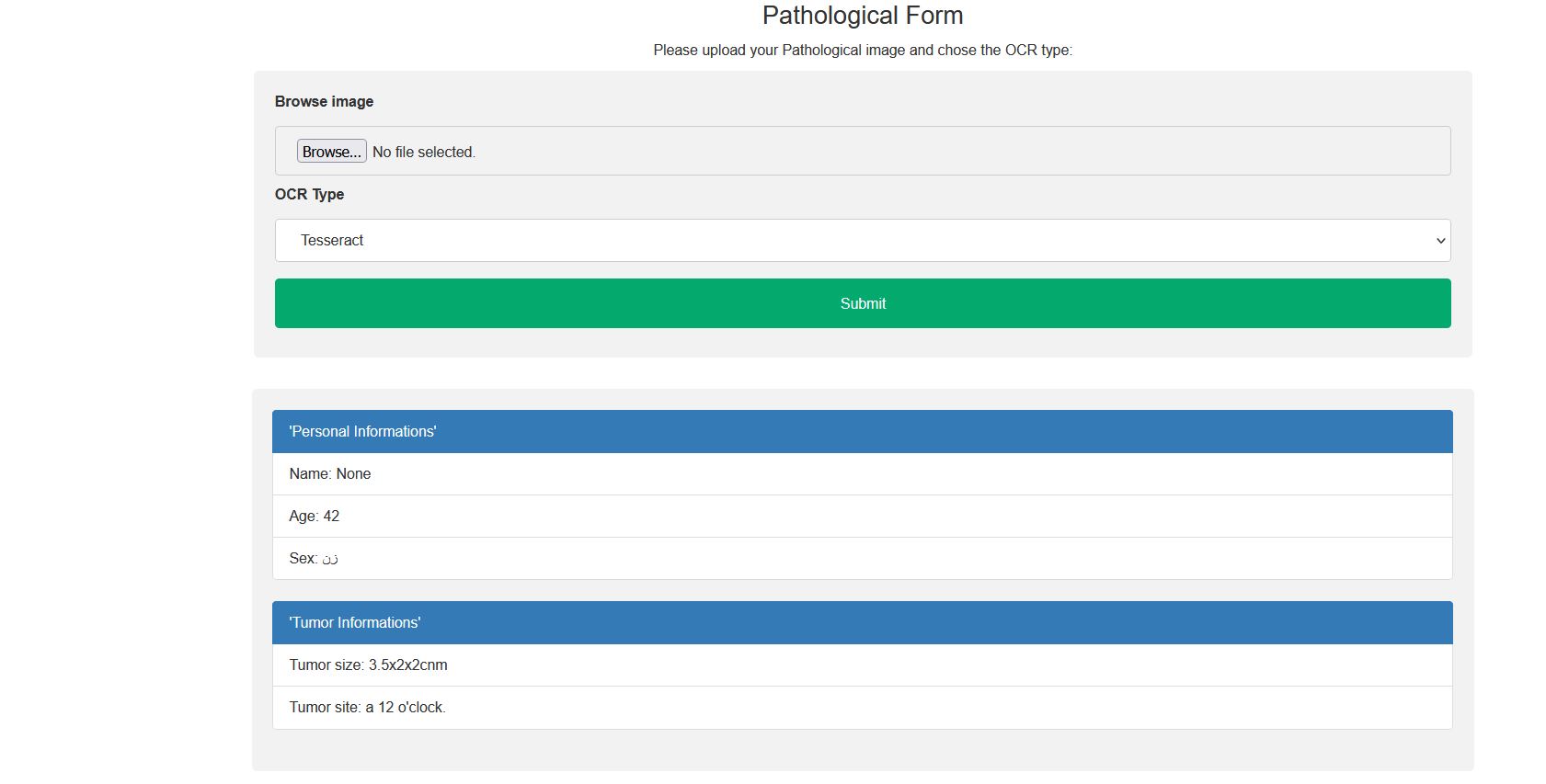
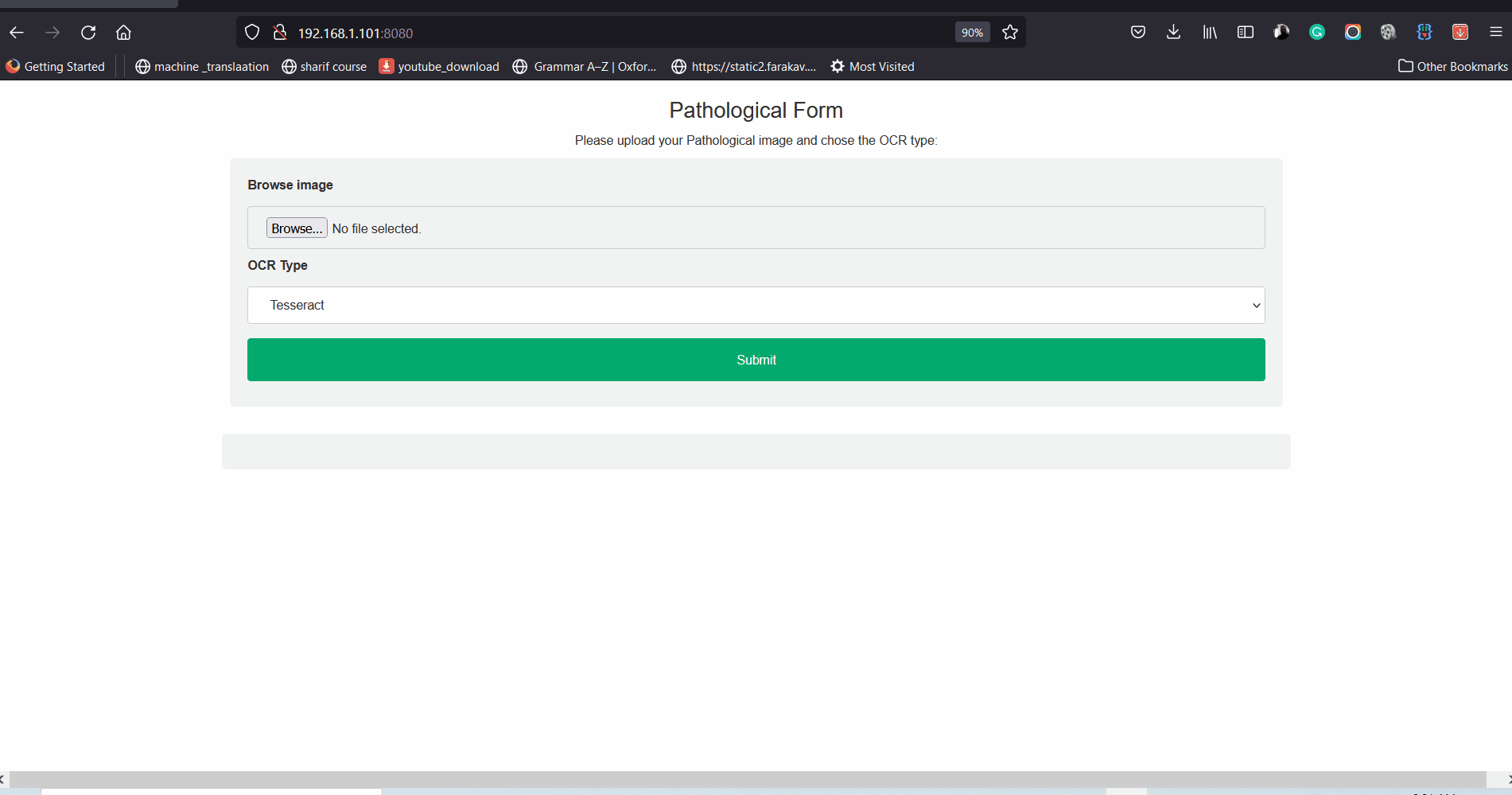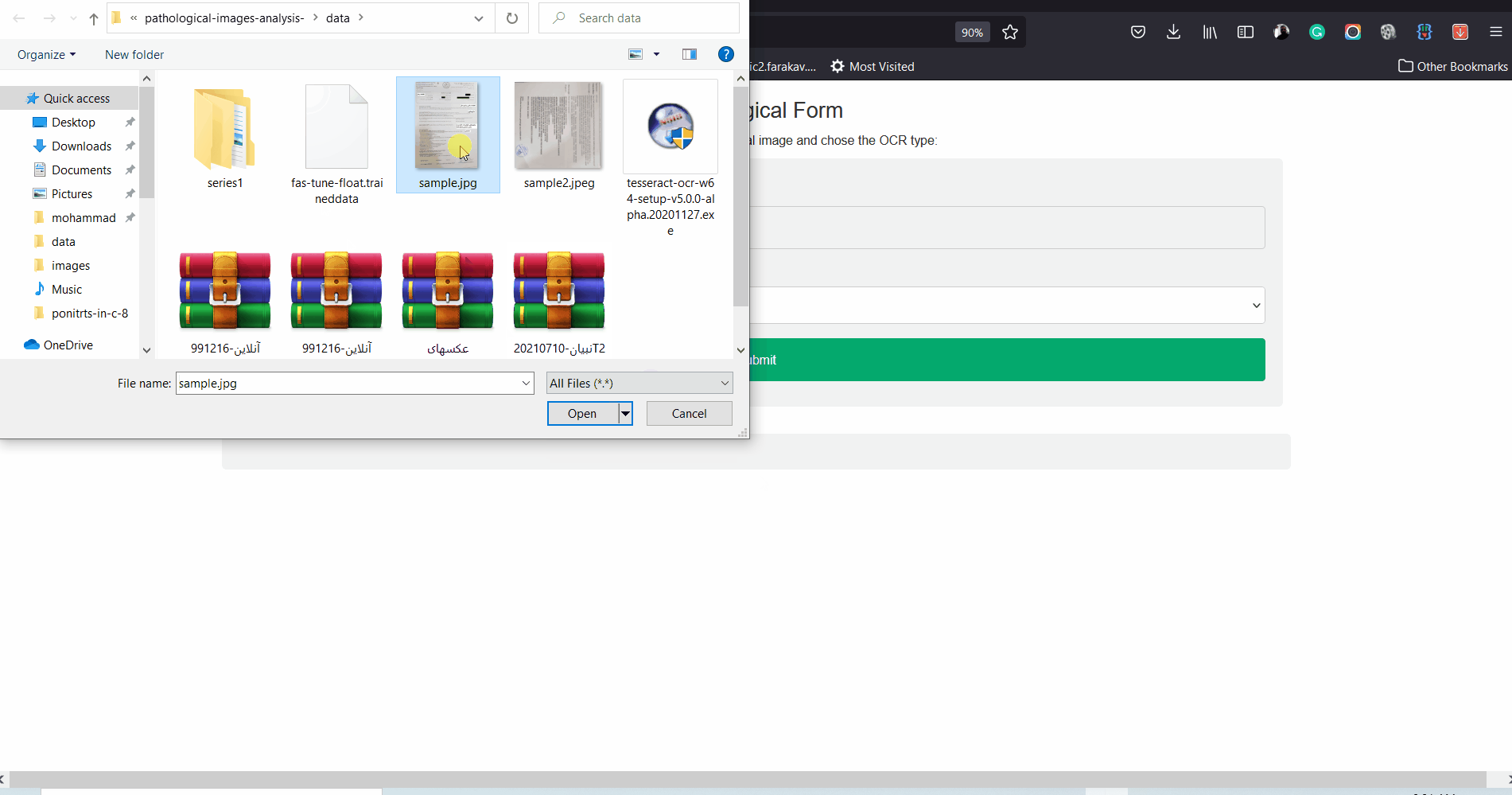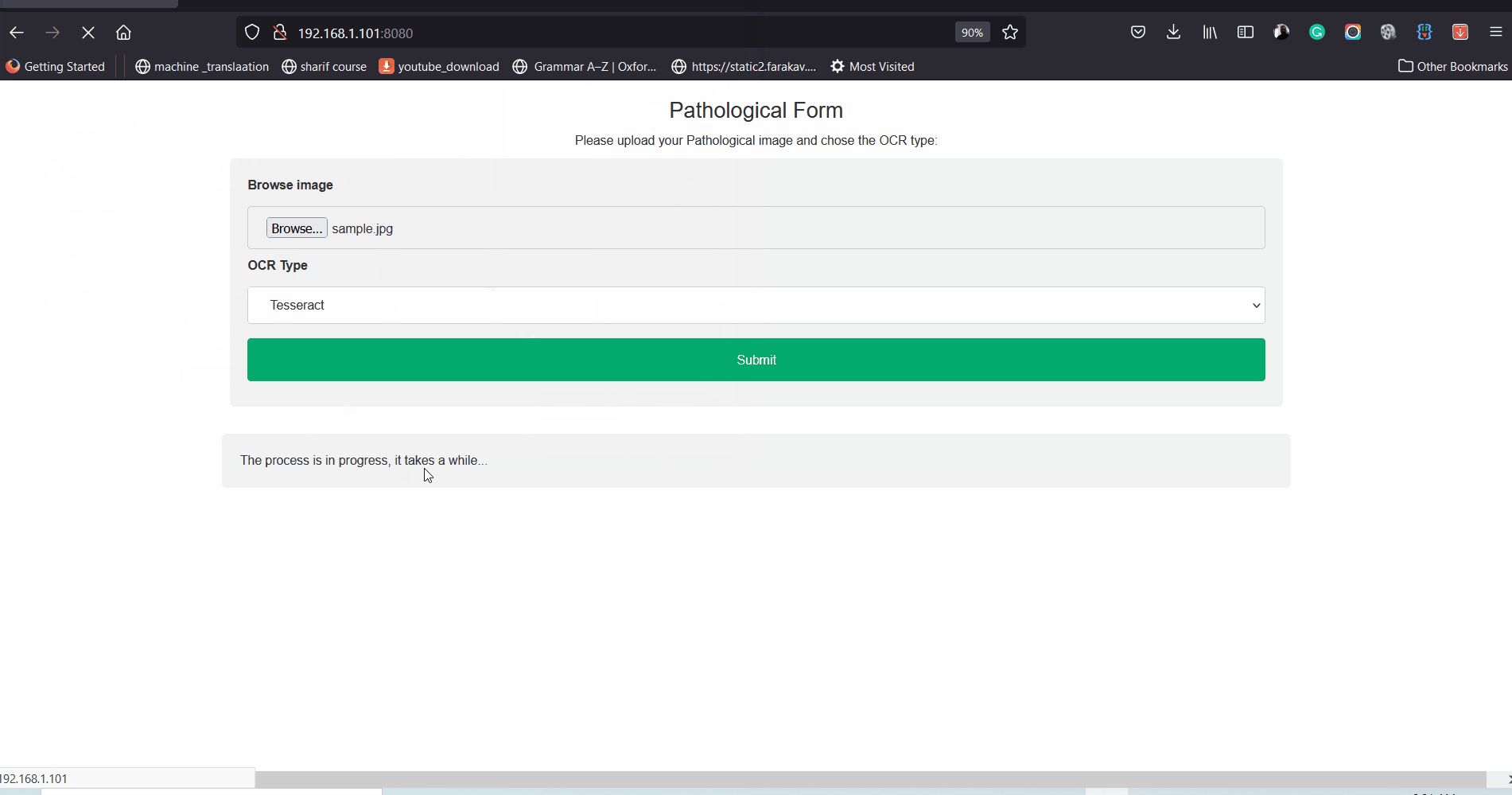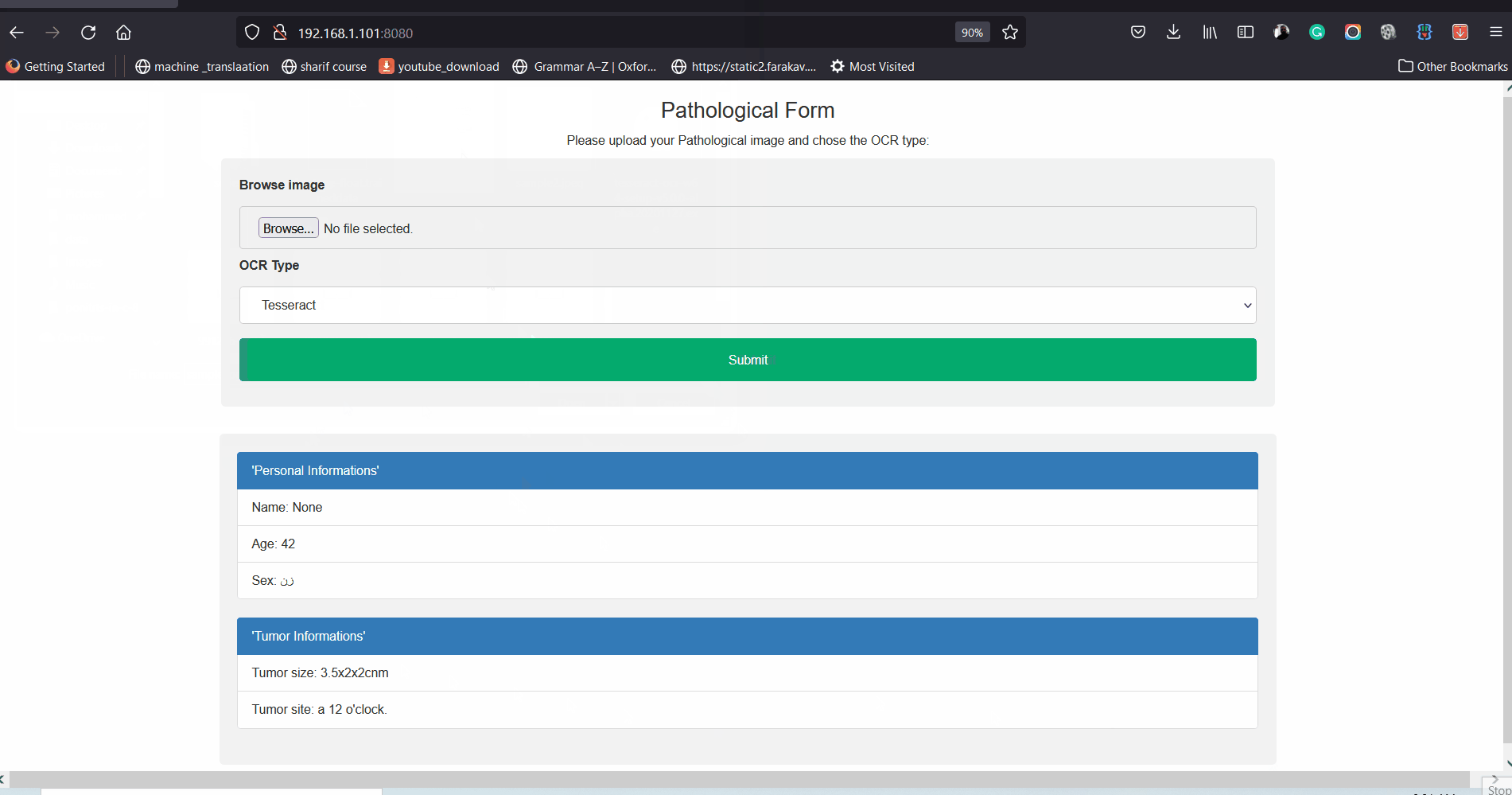
In the following a sample of output is shown:
Patient information
name: None
age: 42
sex: زن
Tumor information
tumor size: 3.5x2x2cnm
tumor site: a 12 o'clock.
-
Install Anaconda (Download the windows version)
-
Making a new enviornmnet acording to this link
-
Click on the created env and chose "open in terminal"
4- Clone or download the git project and extract it in the C:\Users\YOURCOMPUTERNAME path (for example C:\Users\mohammad)
clone https://github.com/mohammad2928/pathological-images-analysis.git
5- Run the following commands in opened terminal
cd pathological-images-analysis
pip install -r reqierments.txt
(If you are living in the IRAN, for installation maybe you need to use a VPN.)
6- Head over to https://github.com/UB-Mannheim/tesseract/wiki and get the 32-bit or 64-bit version depending on your system architecture and install it like as other programs. (Or you can use direct path in your codes), you can use installation file in ~/data/ folder.
7- Put fas-tune-float.traineddata (in the ~/data/ folder) file in the C:\Program Files\Tesseract-OCR\tessdata path
cd src
python app.py
open a browser and type the following address in your browser:
192.168.1.101:8080
In the following the images of the demo is shown: