Wirbelsturm is a Vagrant and Puppet based tool to perform 1-click local and remote deployments, with a focus on big data related infrastructure.
Wirbelsturm's goal is to make tasks such as "I want to deploy a multi-node Storm cluster" simple, easy, and fun.
It has been called the "Cluster Vagrant" and "Big Data Vagrant" by some of its users, albeit in our opinion that makes Wirbelsturm appear to be more than it really is, and it doesn't give enough credit to the tools on which it is based.
Its direct value proposition is two-fold:
- Provide a working integration of Vagrant and Puppet. Vagrant is used to create and manage machines, Puppet is used for provisioning those machines (e.g. to install and configure software packages). Because Wirbelsturm uses Vagrant you can basically deploy to any target platform that Vagrant supports -- local VMs, AWS, OpenStack, etc. -- although Wirbelsturm does not support all of those out of the box yet. While Wirbelsturm's Puppet setup is slightly opinionated with its preference for Hiera and with its notion of environments and roles, these conventions should help to jumpstart new users and, of course, you can change this behavior if needed.
- Add a thin wrapper layer around Vagrant to simplify deploying multiple machines of the same kind.
This is very helpful when deploying software such as Storm,
Kafka and Hadoop clusters, where most of the machines look
the same. In native Vagrant you would be required to (say) manually maintain 30 configuration sections in
Vagrantfilefor deploying 30 Storm slave nodes, even though only their hostnames and IP addresses would change from one to the next.
There is also an indirect, third value proposition:
- Because we happen to maintain Wirbelsturm-compatible Puppet modules such as puppet-kafka, puppet-graphite, and puppet-storm, you can benefit from Wirbelsturm's ease of use to conveniently deploy those software packages. As you may have noticed most of these Puppet modules are related to large-scale data processing infrastructure and to DevOps tools for operating and monitoring such infrastructures, all of which are based on free and open source software. See Supported Puppet modules for details.
We hope you find Wirbelsturm as useful as we do. And most importantly, have fun!
Table of Contents
- Quick start
- Features
- Is Wirbelsturm for me?
- Default configuration
- Getting started
- Usage
- Configuration
- Supported deployment platforms
- Supported Puppet modules
- Known issues and limitations
- FAQ
- How it works
- Wishlist
- Appendix
- Change log
- Contributing to Wirbelsturm
- License
- Credits
Assuming you are using a reasonably powerful computer and have already installed Vagrant
(1.7.2+) and VirtualBox you can launch a multi-node
Apache Storm cluster on your local machine with the following commands. This
Storm cluster is the default configuration example that ships with Wirbelsturm. Note that the bootstrap command
needs to be run only once, after a fresh checkout.
$ git clone https://github.com/miguno/wirbelsturm.git
$ cd wirbelsturm
$ ./bootstrap # <<< May take a while depending on how fast your Internet connection is.
$ vagrant up # <<< ...and this step also depends on how powerful your computer is.Done -- you now have a fully functioning Storm cluster up and running on your computer! The deployment should have taken you less time and effort than brewing yourself an espresso. :-)
Tip: If you run into networking related issues (e.g. "unknown host" errors), try to deploy the cluster via our
./deployscript instead of runningvagrant up. The only additional prerequisite for./deployis the installation of the GNUparalleltool -- see section Install Prerequisites for details.
Let's take a look at which virtual machines back this cluster behind the scenes:
$ vagrant status
Current machine states:
zookeeper1 running (virtualbox)
nimbus1 running (virtualbox)
supervisor1 running (virtualbox)
supervisor2 running (virtualbox)
Storm also ships with a web UI that shows you the cluster's state, e.g. how many nodes it has, whether any processing jobs (topologies) are being executed, etc. Wait 20-30 seconds after the deployment is done and then open the Storm UI at http://localhost:28080/.
What's more, Wirbelsturm also allows you to use Ansible to interact with the deployed machines via our ansible wrapper script:
$ ./ansible all -m ping
zookeeper1 | success >> {
"changed": false,
"ping": "pong"
}
supervisor1 | success >> {
"changed": false,
"ping": "pong"
}
nimbus1 | success >> {
"changed": false,
"ping": "pong"
}
supervisor2 | success >> {
"changed": false,
"ping": "pong"
}
Want to run more Storm slaves? As long as your computer has enough horsepower you only need to change a single number
in wirbelsturm.yaml:
# wirbelsturm.yaml
nodes:
...
storm_slave:
count: 2 # <<< changing 2 to 4 is all it takes
...Then run vagrant up again and shortly after supervisor3 and supervisor4 will be up and running.
Want to run a Kafka broker? Uncomment the kafka_broker section in your
wirbelsturm.yaml (only remove the leading # characters, do not remove any whitespace) then run vagrant up kafka1.
Once you have finished playing around, you can stop the cluster again by executing vagrant destroy.
Note that running a small, local Storm cluster is just the default example. You can do much more with Wirbelsturm than this.
- Launching machines: Wirbelsturm uses Vagrant to launch the machines that make up your infrastructure as VMs running locally in VirtualBox (default) or remotely in Amazon AWS/EC2 (OpenStack support is in the works).
- Provisioning machines: Machines are provisioned via Puppet.
- Wirbelsturm uses a master-less Puppet setup, i.e. provisioning is ultimately performed through
puppet apply. - Puppet modules are managed via librarian-puppet.
- Wirbelsturm uses a master-less Puppet setup, i.e. provisioning is ultimately performed through
- (Some) batteries included: We maintain a number of standard Puppet modules that work well with Wirbelsturm, some of which are included in the default configuration of Wirbelsturm. However you can use any Puppet module with Wirbelsturm, of course. See Supported Puppet modules for more information.
- Ansible support: The Ansible aficionados amongst us can use Ansible to interact with machines once deployed through Wirbelsturm and Puppet.
- Host operating system support: Wirbelsturm has been tested with Mac OS X 10.8+ and RHEL/CentOS 6 as host machines. Debian/Ubuntu should work, too.
- Guest operating system support: The target OS version for deployed machines is RHEL/CentOS 6 (64-bit). Amazon
Linux is supported, too.
- For local deployments (via VirtualBox) and AWS deployments Wirbelsturm uses a CentOS 6 box created by PuppetLabs.
- Switching to RHEL 6 only requires specifying a different Vagrant box
in bootstrap (for VirtualBox) or a different AMI image in
wirbelsturm.yaml(for Amazon AWS).
- When using tools other than Vagrant to launch machines: Wirbelsturm-compatible Puppet modules are standard Puppet modules, so of course they can be used standalone, too. This way you can deploy against bare metal machines even if you are not able to or do not want to run Wirbelsturm and/or Vagrant directly. See Wirbelsturm-less deployment documentation for details.
Here are some ideas for what you can do with Wirbelsturm:
- Evaluate new technologies such as Kafka and Storm in a temporary environment that you can set up and tear down at will. Without having to spend hours and stay late figuring out how to install those tools. Then tell your boss how hard you worked for it.
- Provide your teams with a consistent look and feel of infrastructure environments from initial prototyping to development & testing and all the way to production. Banish "But it does work fine on my machine!" remarks from your daily standups. Well, hopefully.
- Save money if (at least some of) these environments run locally instead of in an IAAS cloud or on bare-metal machines that you would need to purchase first. Make Finance happy for the first time.
- Create production-like environments for training classes. Use them to get new hires up to speed. Or unleash a Chaos Monkey and check how well your applications, DevOps tools, or technical staff can handle the mess. Bring coke and popcorn.
- Create sandbox environments to demo your product to customers. If Sales can run it, so can they.
- Develop and test-drive your or other people's Puppet modules. But see also beaker and serverspec if your focus is on testing.
Let us know how you are using Wirbelsturm!
The default configuration is what you get when you run vagrant up or ./deploy without any config customizations,
e.g. after a fresh checkout.
The purpose of the default configuration is to provide you with a simple yet non-trivial (local) deployment example that will work out of the box on a reasonably modern computer. For that purpose we opted to create a default configuration which will deploy a functional, multi-node Storm cluster that runs as multiple virtual machines locally.
The default cluster setup defined in wirbelsturm.yaml.template consists of four virtual machines:
- 1 ZooKeeper server
- 1 Storm master node running Nimbus and Storm UI daemons
- 2 Storm slave nodes, each running two Storm Supervisor daemons for a total of 4 "slots" aka worker processes
The machines are aptly named:
zookeeper1
nimbus1
supervisor1
supervisor2
The default Java version in Wirbelsturm is OpenJDK 7. That means, for instance, that you must compile your own (Kafka,
Storm, Hadoop, ...) code with Java 7, too. If needed you can change the JDK package via the Puppet class parameter
$java_package_name of puppet-wirbelsturm_common. Here is how
to do this via Hiera (the example below modifies common.yaml):
---
classes:
- wirbelsturm_common
# The config value must match the (RPM) package name of the desired JRE/JDK version
wirbelsturm_common::java_package_name: 'java-1.7.0-sun'Important: When deploying Storm in production it is recommended to use Oracle JRE/JDK 7 instead of OpenJDK 7.
The default configuration sets the Java heap size of the various Storm processes (Nimbus, UI, Supervisor, worker processes) to 256MB each. This is enough to play around with Storm but of course not sufficient to perform large-scale data processing. Make sure you use a powerful host machine and a customized configuration (see below) if you want to do more.
Note: In most cases changes to the configurations of Storm, Kafka, ZooKeeper etc. will automatically trigger a restart of the respective processes once you re-deploy.
This section brings you up to speed from zero to a running cluster. Here, we will show how to use the default cluster configuration of Wirbelsturm to deploy a Storm cluster locally on your host machine (e.g. your laptop). If you are deploying Wirbelsturm remotely -- such as on Amazon AWS -- the instructions are very similar. In the latter cases you should first read the respective sections (e.g. on deploying to AWS) further down in this document and then come back to this section because Wirbelsturm works 99% in the same way no matter to where you deploy.
Wirbelsturm depends on the following software packages on the host machine from which you run Wirbelsturm, i.e. the
machine on which you execute commands such as vagrant up. So if you are running Wirbelsturm on your laptop, you must
install those packages on that laptop.
- Vagrant 1.7.2+
- VirtualBox 4.3.x
- Optional but recommended: GNU parallel.
- This step is only needed if you want to benefit from parallel provisioning via our deploy script to
speed up deployments. If in doubt, do install
parallelbecause./deployis superior to the standardvagrant up.
- This step is only needed if you want to benefit from parallel provisioning via our deploy script to
speed up deployments. If in doubt, do install
Preferably Mac OS X users should also:
- Download version 1.7.2 of Vagrant for your OS and install accordingly.
Verify the installation of Vagrant:
$ vagrant -v
Vagrant version 1.7.2Note for Mac OS X users: To uninstall Vagrant run the uninstall.tool script that is included in the .dmg file.
- Download a VirtualBox 4.3.x platform package for your OS and install accordingly.
Note for Mac OS X users: To uninstall VirtualBox run the VirtualBox_Uninstall.tool script that is included in the
.dmg file.
You only need to install GNU parallel if you like to start your clusters via deploy to benefit from parallel
and thus faster provisioning. If you do not you can safely omit the installation of GNU parallel. If in doubt, do
install parallel because you will most likely prefer to deploy via the ./deploy script.
Install parallel on the host machine:
# Mac
# - Homebrew
$ brew install parallel
# - MacPorts
$ sudo port install parallel
# RHEL/CentOS/Fedora
$ sudo yum install parallel
$ sudo vi /etc/parallel/config # and change '--tollef' to '--gnu'
# Debian/Ubuntu
$ sudo apt-get install parallel # requires Ubuntu 13.04; earlier versions may work, too
$ sudo vi /etc/parallel/config # and change '--tollef' to '--gnu'Clone this repository and then bootstrap Wirbelsturm:
$ git clone https://github.com/miguno/wirbelsturm.git
$ cd wirbelsturm
$ ./bootstrap # <<< May take a while depending on how fast your Internet connection is.The bootstrapping step will prepare the local environment of your host machine so that it can properly run Wirbelsturm. This includes, for instance, installing a compatible version of Ruby via rvm, required Ruby gems, Vagrant plugins and Vagrant boxes, as well as any Puppet modules that are included in Wirbelsturm out of the box (see Puppetfile).
Advanced users also have the option to skip the Ruby-related part of the bootstrapping process, e.g. if you prefer to
stick to a different Ruby version. Here, replace the ./bootstrap command above with a sequence such as:
$ bundle install
$ ./bootstrap --skip-rubyThe bootstrapping step will also create a wirbelsturm.yaml from the included
wirbelsturm.yaml.template. This YAML configuration file controls which machines will be
launched and what their configuration will be.
This section uses the default configuration of Wirbelsturm as a running example.
To perform a local deployment on your host machine with the default settings you only need to run one of the following two commands:
# Option 1 (recommended):
# Deploy with parallel provisioning (faster).
# Logs are stored under `provisioning-logs/`.
$ ./deploy
# Option 2: Deploy with sequential provisioning, using native Vagrant
# (You must use this if you haven't installed the `parallel` tool)
$ vagrant upThe deploy script is a simple wrapper for vagrant up. In contrast to the standard vagrant up behavior
it will speed up the deployment by running the provisioning step in parallel. The script will launch the cluster in
two distinct phases:
- First, it will boot the virtual machines (but not provision them yet). When deploying locally via VirtualBox this step will sequentially boot the VMs. Other providers such as AWS support launching machines in parallel.
- Once all VMs are running it will then trigger provisioning (via Puppet) in parallel.
The script stores per-node provisioning log files under provisioning-logs/. Existing log files are purged when you
re-run deploy.
Tip: You can also re-run deploy if you just want to re-provision the cluster in parallel (e.g. because
you changed a single configuration file) without destroying/recreating the virtual machines from scratch. This saves
you a lot of time because recreating the VMs usually takes several minutes per VM.
Feel free to run vagrant status while Vagrant is doing its magic to see which virtual machines are already running.
Note that the "running" state of a VM only means that it is booted -- it does not necessarily mean it has already been
fully provisioned.
You can also instruct Wirbelsturm/Vagrant to use a file other than the default wirbelsturm.yaml. You only need to
set the WIRBELSTURM_CONFIG_FILE environment variable appropriately. This is one way of using Wirbelsturm to deploy
multiple environments (think: wirbelsturm-testing.yaml and wirbelsturm-production.yaml).
# Examples
$ WIRBELSTURM_CONFIG_FILE=/path/to/your/custom-wirbelsturm.yaml ./deploy
$ WIRBELSTURM_CONFIG_FILE=/path/to/your/custom-wirbelsturm.yaml vagrant status
Once the machines are up and running you can vagrant ssh <hostname> into them. You can get the list of available
hostnames via vagrant status.
By default the vagrant ssh command will connect as the user vagrant. This user has password-less sudo enabled so
that you can run privileged commands, install software, switch user ids, perform manual service restarts, etc.
# Example: ssh-connect to the nimbus1 machine
$ vagrant ssh nimbus1You can also configure SSH port forwarding to access services that run on the deployed machines. The default
configuration of Wirbelsturm allows you to access the Storm UI running on nimbus1 with your browser. Note that it
might take up to a minute after provisioning is complete (e.g. after ./deploy finishes) until the Storm UI is ready
to use. If in doubt just hit the reload button in your browser until it works. :-)
- http://localhost:28080/ -- Storm UI
The UI should provide you with a screen similar to the following. In this screenshot you can also see that there is one running topology called "exclamation-topology" (which will not be the case after a fresh restart of the cluster). In the section Submitting an example Storm topology I will walk you through submitting this topology to the cluster.
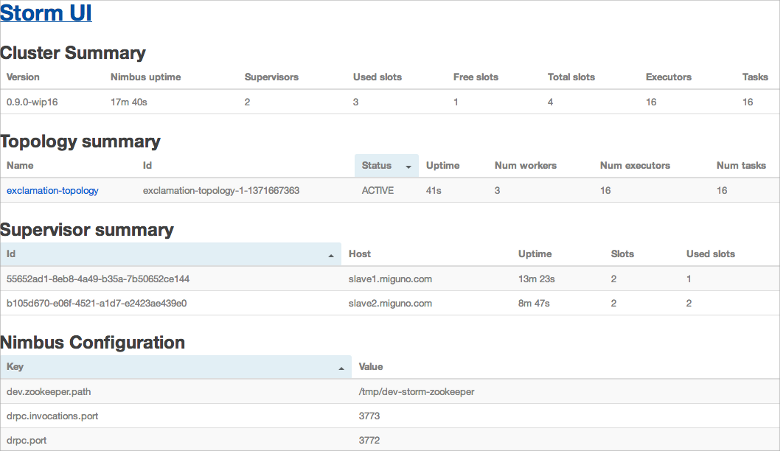
You can follow the section Submitting an example Storm topology in the appendix to run your first hands-on data analysis with Storm.
To take down the deployed machines you need to run:
# Will ask for confirmation for each machine
$ vagrant destroy
# Will take down machines without asking for any confirmation
$ vagrant destroy -fPlease refer to the Vagrant documentation for further
details on how to work with Vagrant, notably its command-line interface
vagrant.
Wirbelsturm supports Ansible to interact with deployed machines. Note however that Wirbelsturm uses Puppet -- not Ansible -- for provisioning the machines launched by Vagrant. Wirbelsturm ships with an Ansible wrapper script aptly named ansible that pre-configures several Ansible settings (such as generating a dynamic inventory of running machines by querying Vagrant) so that Ansible works out of the box with Wirbelsturm/Vagrant.
Ansible will only see running machines, i.e. those reported by vagrant status as running. So before trying to
play with Ansible make sure that you have at least one machine up and running.
Here are some examples on how to use Ansible with Wirbelsturm's ansible wrapper script.
# Show all running boxes
$ ./ansible all --list-hosts
# Ping all running boxes
$ ./ansible all -m ping
# Install 'tree' on the nimbus1 box
$ ./ansible nimbus1 -m shell -a 'yum install -y tree' --sudo
# Check the status of processes running under supervisord on all machines
$ ./ansible all -m shell -a 'supervisorctl status' --sudo
Now that you have played with Wirbelsturm and its default configuration you may want to create your own configuration. In this section we will explain how to do just that.
Before we start let us highlight that most of the "requirements" or "conventions" discussed below are in fact not specific to Wirbelsturm. They are simply driven by the way Vagrant and Puppet/Hiera work. As such the sections below are also a kind of quick introduction to the aforementioned tools and their usage. Lastly, if you are already familiar with Vagrant and/or Puppet there should be nothing in the next sections that will surprise you.
There are three key places in Wirbelsturm that you need to customize for your own deployments.
- Defining which machines will be created:
The file
wirbelsturm.yaml(see wirbelsturm.yaml.template) controls the creation of the machines in your deployment environment. Here, you define the name of your environment, how many machines will be launched, what their hostnames and "roles" are, etc. This information is subsequently used by Puppet and Hiera to determine which Puppet manifests and Hiera configuration data will be applied to each machine.wirbelsturm.yamlis automatically read by Vagrant when you run e.g.vagrant statusorvagrant up. Note thatwirbelsturm.yamlis not used of course when you are not using Wirbelsturm (and thus Vagrant) to launch your machines -- for instance, if you deploy to existing bare-metal machines. - Defining which Puppet modules you require:
Like many other Puppet-based setups Wirbelsturm uses librarian-puppet
to manage the Puppet modules that are used for your deployments (similar to how tools such as Maven or Gradle manage
library dependencies in Java).
librarian-puppettakes over the control of thepuppet/modules/directory. So if you need additional Puppet modules for your deployments, different versions of existing ones, or remove modules, you only need to update puppet/Puppetfile and then telllibrarian-puppetto update the modules underpuppet/modules/via commands such aslibrarian-puppet updateorlibrarian-puppet update <module-name>(you must runlibrarian-puppetin thepuppet/sub-directory). - Defining configuration data for Puppet via Hiera: Wirbelsturm performs the provisioning of machines in your deployment through Puppet. And a Puppet best practice is to create or use Puppet modules that support configuration through Hiera. Roughly speaking, this means that a Puppet module must expose all relevant configuration settings through Puppet class parameters. The Hiera hierarchy of Wirbelsturm is defined in puppet/manifests/hiera.yaml, and the actual Hiera configuration data is stored under puppet/manifests/hieradata/. Please take a look at the existing content in those two places to get started with Hiera in Wirbelsturm. If you are familiar with Hiera you should notice that Wirbelsturm uses a straight-forward, typical Hiera setup.
In the next sections we discuss these three key places, and thereby machine creation and provisioning, in further detail.
The cluster machines are defined in wirbelsturm.yaml. See
wirbelsturm.yaml.template for an example.
Vagrantfile is set up to dynamically read the information in wirbelsturm.yaml to configure and launch
the virtual machines.
We want to highlight the following parameters in particular, because they influence the subsequent provisioning of the machines via Puppet:
- The
environmentparameter inwirbelsturm.yaml: The value of this parameter is made available to Puppet and Hiera as the Puppet factnode_env. So if you setenvironment: foo, for instance, then Wirbelsturm will automatically inject the Puppet factnode_env = 'foo'into your machines. - The
node_roleparameter: The value of this parameter is made available to Puppet and Hiera as the Puppet factnode_role. - The
hostname_prefixandcountparameters: These two parameters determine the hostname of a machine. If, for instance,hostname_prefix: supervisorandcount: 3, then Wirbelsturm will launch three such machines and give them the respective hostnamessupervisor1,supervisor2, andsupervisor3. The hostnames are made available to Puppet as the Puppet facthostname.
The environment name as well as the hostnames of machines are important parameters because you can use them to determine which Puppet manifests should be applied to a machine -- see hiera.yaml.
Wirbelsturm relies on Puppet and Hiera for provisioning. As such the entry points for understanding provisioning are:
- hiera.yaml -- defines the Hiera hierarchy
- hieradata/ -- the actual Hiera configuration data
- site.pp -- how we control our use of Hiera in Puppet
- Puppetfile -- the collection of Puppet modules used for a deployment; managed through librarian-puppet
Machine creation settings must match provisioning settings:
When using Wirbelsturm/Vagrant for machine creation -- i.e. launching machines and such -- then what is defined in Hiera
must match what is defined in wirbelsturm.yaml; otherwise the machines will be launched (via Vagrant) but not
properly installed and configured (via Puppet) once up and running.
Puppet modules should be configurable through Hiera: In Wirbelsturm it is strongly recommended that all Puppet modules that are used for a deployment (see Puppetfile) expose any relevant configuration settings through Puppet class parameters. Otherwise you cannot use Hiera to inject configuration data into the Puppet manifests, and instead you must hardcode configuration data into your Puppet manifest code. We've been there, done that, realized it didn't work well or at all. Don't make the same mistake we did.
Informing Puppet how configuration data is made available to Puppet manifests via Hiera: Wirbelsturm currently relies on three Puppet facts to determine which Puppet manifests should be applied to a machine:
node_env: The name of the deployment environment (e.g.default-environment). This Puppet fact can be used to group settings that are shared across a deployment environment. See also the previous section on machine creation.node_role: The role of the machine (e.g.kafka_broker). See also the previous section on machine creation.hostname: The hostname of the machine (e.g.supervisor1). This is the hostname of the machine as returned by standard Unix commands such ashostname. See also the previous section on machine creation.
See hiera.yaml for the exact definition how those facts are used to determine which Hiera configuration data and thereby also which Puppet manifests should be applied to a machine.
We cover environments and roles in the next sections in further detail, and how they can be mixed and matched.
In Wirbelsturm you manage the collection of Puppet modules you require for your deployment through the popular Puppet tool librarian-puppet. In concrete terms that means you will add (or remove) any required modules to Puppetfile. Once you have added, changed, or removed modules, you must tell librarian-puppet to update its configuration.
Here is an example workflow:
$ cd puppet/ # change to the puppet/ subfolder
$ vi Puppetfile # add/modify/remove modules
$ librarian-puppet update # MUST be run from inside the puppet/ subfolder!
That's all!
See librarian-puppet for more information.
Wirbelsturm has the notion of "deployment environments". These environments are nothing fancy, they are simply a
name and used to define settings that are shared across a number of machines in the same physical location or logical
environment. For instance, "every machine in our storm-production-nyc environment should talk to this ZooKeeper
quorum".
An environment can have multiple machines, but a machine can be assigned to only one environment.
- Defining environments: Environments are defined by creating a Hiera YAML file at
environments/<environment-name>.yaml(cf. environments/). - Assigning machines to environments: You assign a machine to an environment by providing the Puppet fact
node_envto the machine. In Wirbelsturm this is done by setting theenvironmentparameter inwirbelsturm.yaml. - Resolving environments: The names of environment Hiera YAML files under
environments/are matched against thenode_envPuppet fact. Vagrant injects this variable as a custom Puppet fact into the machine viaFACTER_node_env=.... Unfortunately this custom fact is not persisted to the machine, e.g. you will not see it when you manually runfacterinside the machine.- Example: If
node_envisstorm-production-nyc, then we look for a fileenvironments/storm-production-nyc.yaml.
- Example: If
The Hiera settings in the environment file are applied to each machine that is assigned to that environment.
Wirbelsturm ships with only one environment, the default-environment:
You can easily create your own environments by following this example and standard Puppet/Hiera practices.
For each machine you can also override the default environment settings through per-host Hiera YAML files
at environments/<environment-name>/hosts/<hostname>.yaml.
- Example:
environments/storm-production-nyc/hosts/storm-slave-21.yaml
You can (and normally should) assign every machine a role. Roles are used to define settings that are shared among machines of the same kind. For instance, every Kafka broker (= the machine's role) should normally look the same, regardless of whether it's deployed in Europe or in the US (= environment/location). This is thus also the difference between environments and roles -- they have similar but distinct purposes.
Only one role can ever be assigned to a machine. If a machine should have multiple roles, then you can work around
this restriction by creating a compound role -- e.g. by combining the logical roles webserver and monitoring into a
compound role webserver_with_monitoring.
- Defining roles: Roles are defined by creating a Hiera YAML file at
roles/<role>.yaml(cf. roles/). - Assigning roles to machines: A role is assigned to a machine by providing the Puppet fact
node_roleto the machine. In Wirbelsturm this is done by setting theroleparameter inwirbelsturm.yaml. - Resolving roles: The names of role Hiera YAML files under
roles/are matched against thenode_rolePuppet fact. Vagrant injects this variable as a custom Puppet fact into the machine viaFACTER_node_role=.... Unfortunately this custom fact is not persisted to the VM, e.g. you will not see it when you manually runfacterinside the machine.- Example: If
node_roleiskafka_broker, then we look for a fileroles/kafka_broker.yaml.
- Example: If
The Hiera settings in the role file are applied to each machine that is assigned to that role.
Wirbelsturm ships with some such roles out of the box (see hieradata/roles/ for the full list):
You can easily create your own roles by following those examples and standard Puppet/Hiera practices.
For each machine you can also override the default role settings through per-host Hiera YAML files
at environments/<environment-name>/roles/<role>.yaml.
- Example:
environments/storm-production-nyc/roles/kafka_broker.yaml.
In a typical Wirbelsturm setup you will usually combine environment-level Hiera settings and role-level Hiera settings. This way you can compose exactly how machines should be deployed while minimizing duplication of configuration data.
- Example: "All Kafka brokers (= role) should normally look like this, but in our
kafka-production-nycenvironment we need a different setting for that particular configuration parameter."
The default Hiera hierarchy definition at hiera.yaml controls how this composition of data exactly happens -- notably which values override which other values in case a configuration parameter is defined more than once. This is standard Hiera 101, by the way, and not specific to Wirbelsturm in any way.
| Target platform | Code status | Documentation status |
|---|---|---|
| Local deployment (VMs) | Ready | Ready |
| Amazon AWS/EC2 | Beta | Beta |
| OpenStack | In progress | Not started |
Please refer to the individual platform sections below for detailed information.
This section covers scenarios where you instruct Wirbelsturm to run its machines locally as VMs on a host machine. For further information please read the Usage section above.
The "host" is the machine on which Wirbelsturm will start the virtual Storm cluster, i.e. the machine on which you
run vagrant up or deploy.
The minimum hardware requirements for running the default configuration are:
- 4 CPU cores
- 8 GB of RAM
- 20 GB of disk space
More is better, of course.
# Option 1: Sequential provisioning (native Vagrant)
$ vagrant up --provider=virtualbox
# Option 2: Parallel provisioning (Wirbelsturm wrapper script for `vagrant`)
# Logs are stored under `provisioning-logs/`.
$ ./deploy --provider=virtualbox
Several users have asked how they can re-use their existing Wirbelsturm setup that they created for local development and testing in order to deploy "real" environments, e.g. backed by a couple of bare-metal machines. A different but related use case is situations where you cannot or are not allowed to use Wirbelsturm and/or Vagrant to deploy to non-local environments (i.e. to anything but your local computer). Of course, it is up to you then to manage the machines (booting machines, configuring networking, etc.), which is normally taken care of by Wirbelsturm/Vagrant.
See the Wirbelsturm-less deployment documentation for details.
Wirbelsturm supports deploying to AWS. See our current AWS documentation for details.
However at this point you still need to perform a few one-time AWS preparation steps. And because this means our
users do not have the best possible AWS experience we decided to flag AWS support as "beta". What does "beta" mean
in this context? It means that it is still possible at this point that we will perform a code refactoring to change
our AWS support for the better -- and thus we may change the way Wirbelsturm users need to configure their AWS
deployments or how they interact with AWS through Wirbelsturm/Vagrant may still change. Since we first finished the
AWS-related code some time has passed, and several upstream projects such as
vagrant-aws have improved during that time. Also, plugins such as
vagrant-hostmanager may allow use to stop using (and thus requiring
you to configure) Amazon Route 53 (but right now vagrant-hostmanager is not yet compatible with Vagrant 1.5).
We therefore think that we can further simplify the way you can use Wirbelsturm to deploy to AWS, even though this may mean we have to redo certain parts of the code, and even break backwards compatibility in some areas.
This section will eventually describe how to deploy to private and public OpenStack clouds. Code contributions are welcome!
In general any Puppet module is compatible with Wirbelsturm. Yes, any module.
However we strongly recommend to write or use such Puppet modules that expose their relevant configuration settings through class parameters. This decouples the module's logic (code/manifests) from its configuration, and thereby allows you to configure the module's behavior through Hiera. This Puppet recommendation is not specific to Wirbelsturm -- in fact, you will often (always?) want to follow this best practice every time you write or use a Puppet module for your deployments.
If your favorite Puppet module does not follow this style, you can of course still use it in Wirbelsturm. However in this case you will most likely have to fork/modify the module whenever your configuration requirements change. Or write "adapter" Puppet modules that wrap the original one. Or...you get the idea. Whatever workaround you pick it will usually not make you perfectly happy. But then again, for tasks such as quick prototyping or when your under pressure it is acceptable to "just get it done". Just be aware that most likely you're adding technical debt to your setup.
The following table shows a non-comprehensive list of Puppet modules that are known to work well with Wirbelsturm, where "well" means they can be configured through Hiera. As we said in the previous section any Puppet module can be used in Wirbelsturm, it just happens that some will make your life easier than others. So treat the table below merely as a nice starting point, but not as an exclusive listing.
You will find more Puppet modules on PuppetForge and GitHub.
| Module name | Description | Must build RPM* | Included in node role** | Build status |
|---|---|---|---|---|
| puppet-diamond | Deploys Diamond, a Python-based tool that collects system metrics and publishes those to Graphite. | Yes | monitoring |

|
| puppet-kafka | Deploys Apache Kafka 0.8.x, a high-throughput distributed messaging system. | Yes | kafka_broker |

|
| puppet-graphite | Deploys Graphite 0.9.x, a monitoring-related tool for storing and rendering time-series data. | No | monitoring | n/a |
| puppet-redis | Deploys Redis 2.8+, a key-value store. | Yes | redis_server |

|
| puppet-storm | Deploys Apache Storm 0.9.x, a distributed real-time computation system. | Yes | storm_master, storm_slave, storm_single |

|
| puppet-supervisor | Deploys Supervisord 3.x, a process control system (process supervisor). | Yes | Included in most node roles. | n/a |
| puppet-zookeeper | Deploys Apache ZooKeeper 3.4.x, a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. | No | zookeeper_server |

|
(*) You must build an RPM for this software yourself because a suitable official package is not available.
(**) You can use these existing roles directly for the `node_role` parameter in your `wirbelsturm.yaml`. Of course you can modify existing node roles or define your own.This issue only affects ZK quorum deployments. Standalone ZK deployments are not affected.
This issue is caused by a known bug in ZooKeeper 3.4+ that, as of October 2014, is not yet fixed:
- ZOOKEEPER-1848: Cached InetSocketAddresses prevent proper dynamic DNS resolution
Unfortunately this issue is very reliably triggered when using Vagrant (and thus Wirbelsturm) to deploy ZK quorums to local VMs. :-(
You can quickly test whether your deployment is affected via the following Ansible command, which sends the stat Four Letter Command to all ZK servers:
# Here we test whether the machine `zookeeper1` has joined the quorum
$ ./ansible zookeeper* -m shell -a 'echo stat | nc 127.0.0.1 2181'
A negative "failure" reply includes the string "This ZooKeeper instance is not currently serving requests", which means the ZK server has not joined the quorum, which typically indicates that it is affected by the ZK issue described here:
zookeeper3 | success | rc=0 >>
This ZooKeeper instance is not currently serving requests
In comparison, a positive "success" message looks as follows:
zookeeper3 | success | rc=0 >>
Zookeeper version: 3.4.5-cdh4.7.0--1, built on 05/28/2014 16:33 GMT
Clients:
/127.0.0.1:48714[0](queued=0,recved=1,sent=0)
Latency min/avg/max: 0/0/0
Received: 1
Sent: 0
Connections: 1
Outstanding: 0
Zxid: 0x100000000
Mode: follower # <<< this ZK server has joined the quorum as a follower
Node count: 4
Another telling sign is java.net.UnknownHostException errors in the ZK log files:
$ ./ansible zookeeper* -m shell -a 'grep java.net.UnknownHostException /var/log/zookeeper/zookeeper.log | tail'
zookeeper3 | success | rc=0 >>
java.net.UnknownHostException: zookeeper2
But what is going on here? This ZK issue is triggered when the ZK process is started at a time when the hostnames of
some ZK quorum members (here: zookeeper2) are not resolvable, and due to the ZK bug above (InetSocketAddress being
cached forever) the ZK process is not to be able to recover from this condition.
Currently the only remedy is to restart the problematic ZK process, i.e. the one that is complaining about unknown hosts. You can use the ansible wrapper script in Wirbelsturm to trigger such restarts:
# Restart the ZK process on `zookeeper3`
$ ./ansible zookeeper3 -m shell -a 'supervisorctl restart zookeeper' --sudo
# Restart the ZK processes on all ZK machines
$ ./ansible zookeeper* -m shell -a 'supervisorctl restart zookeeper' --sudo
"Wirbelsturm" is German for Whirlwind, which is a kind of storm. Originally we built Wirbelsturm with the sole intent to conveniently deploy Storm clusters, but the name stuck as we moved along.
It depends on the Puppet modules you use what needs to be done to, say, tell Wirbelsturm (via Puppet) that you want
to install Storm version 0.9.2-incubating specifically.
The Puppet modules included in Wirbelsturm use Hiera for configuration, so here you must update Hiera data to configure which exact version of Storm should be installed.
The following Hiera snippet shows at the example of puppet-storm how you
tell Wirbelsturm to install Storm version 0.9.2-incubating when deploying the default environment in Wirbelsturm:
# In puppet/manifests/hieradata/environments/default-environment.yaml
# puppet-storm exposes the `package_ensure` parameter, which allows you to define which version
# of the Storm RPM package should be installed.
# See also https://docs.puppetlabs.com/references/latest/type.html#package-attribute-ensure.
#
# NOTE: The name of this parameter may be different across the Puppet modules you use,
# and some Puppet modules may not even support such a parameter at all (ours do).
storm::package_ensure: '0.9.2_incubating-1.miguno'You can find out which exact version identifier (here: 0.9.2_incubating-1.miguno) you need by inspecting the RPM
package that is used to install the software:
$ rpm -qpi storm-0.9.2_incubating.el6.x86_64.rpm
Name : storm Relocations: /opt/storm
Version : 0.9.2_incubating Vendor: Storm Project
Release : 1.miguno Build Date: Mon Jun 30 12:03:16 2014
Install Date: (not installed) Build Host: build1
Group : default Source RPM: storm-0.9.2_incubating-1.miguno.src.rpm
Size : 22881927 License: unknown
Signature : RSA/SHA1, Mon Jun 30 12:08:14 2014, Key ID b31f46760aa7be3f
Packager : <[email protected]>
URL : http://storm-project.net
Summary : Distributed real-time computation system
Architecture: x86_64
Description :
Distributed real-time computation system
In the example above, you would combine the "Version" and the "Release" fields, and use the result as the value of
storm::package_ensure.
Wirbelsturm is based on Vagrant. This means the entry point for the code is Vagrantfile. The Puppet-related provisioning code is in manifests/ and, with regard to the included Puppet modules, Puppetfile. Here you should start reading at manifests/site.pp and manifests/hiera.yaml..
Set the environment variable VAGRANT_LOG accordingly. Example:
$ VAGRANT_LOG=debug vagrant upTo upload or download data you only need to place them in the shared/ directory (host) and /shared directory
(guests aka virtual machines). Vagrant automatically syncs the contents of these folders. For instance, if you
create the file shared/foo on the host then all the cluster machines can access this file via /shared/foo.
Synced files are readable AND writable from all machines.
Note that:
- When using VirtualBox as provider then changes to the synced folder is instantaneous.
- When using AWS as provider then changes to the synced folder require another provisioning run (which triggers rsync).
You can use the scp wrapper script vagrant-scp.sh to transfer files between the host machine
and a guest machine (copying directly from guest to guest is not supported).
# Upload from the host machine to a guest machine
$ sh/vagrant-scp.sh /path/to/file/on/host/foo.txt nimbus1:/tmp
# Download from a guest machine to the host machine
$ sh/vagrant-scp.sh nimbus1:/tmp/bar.txt .On rare occasions Vagrant may fail to destroy (shutdown) a VirtualBox vm. The error message will be similar to:
There was an error while executing `VBoxManage`, a CLI used by Vagrant
for controlling VirtualBox. The command and stderr is shown below.
Command: ["unregistervm", "964f02c5-b368-44c8-840e-f47f90979791", "--delete"]
Stderr: VBoxManage: error: Cannot unregister the machine 'wirbelsturm_supervisor2_1377594297' while it is locked
VBoxManage: error: Details: code VBOX_E_INVALID_OBJECT_STATE (0x80bb0007), component Machine, interface IMachine, callee nsISupports
You can force the shutdown by executing the following steps:
-
Kill the VBoxHeadless process of the problematic VirtualBox vm.
# Find process ID $ ps axu | grep VBoxHeadless | grep <vm-hostname> $ kill <ID> -
Then run
vagrant destroy <vm-hostname>.
After an upgrade of Vagrant you may see the following error when running deploy, vagrant up or vagrant provision:
[redis1] Running provisioner: hosts...
1.3.1 isn't a recognized Vagrant version, vagrant-hosts can't reliably
detect the `change_host_name` method.
In almost all cases this problem can be solved by installing (updating) the latest version of the vagrant-hosts
plugin.
$ vagrant plugin install vagrant-hosts
Example:
$ vagrant awsinfo -m nimbus1On Mac OS X you may run into the following error when running ./bootstrap:
ruby-1.9.3-p362 - #compiling....................
Error running '__rvm_make -j 1',
showing last 15 lines of /Users/brady.doll/.rvm/log/1409157940_ruby-1.9.3-p362/make.log
f_rational_new_no_reduce1(VALUE klass, VALUE x)
^
6 warnings generated.
compiling re.c
compiling regcomp.c
compiling regenc.c
compiling regerror.c
compiling regexec.c
compiling regparse.c
regparse.c:582:15: error: implicit conversion loses integer precision: 'st_index_t' (aka 'unsigned long') to 'int' [-Werror,-Wshorten-64-to-32]
return t->num_entries;
~~~~~~ ~~~^~~~~~~~~~~
1 error generated.
make: *** [regparse.o] Error 1
++ return 2
There has been an error while running make. Halting the installation.
Installing bundler...
ERROR: While executing gem ... (Gem::FilePermissionError)
You don't have write permissions for the /Library/Ruby/Gems/2.0.0 directory.
Installing gems (if any)
bash: line 200: bundle: command not found
Thanks for using ruby-bootstrap. Happy hacking!
ruby-1.9.3-p362 is not installed.
To install do: 'rvm install ruby-1.9.3-p362'
Checking Vagrant environment...
Checking for Vagrant: OK
<rest removed>
The following steps may fix the problem.
-
Install Homebrew or MacPorts, and then run:
Homebrew
$ brew update $ brew tap homebrew/dupes $ brew install apple-gcc42MacPorts:
$ sudo port selfupdate $ sudo port install apple-gcc42 -
Compile Ruby manually
$ CC=/opt/local/bin/gcc-apple-4.2 rvm install ruby-1.9.3-p362 --enable-shared --without-tk --without-tcl -
Re-run
./bootstrap-- the install should complete successfully now.
See Error running Bootstrap on Mac OSX 10.9 for details.
You may need to tweak the BIOS settings of Dell desktop computers to allow the execution of 64-bit VMs.
- Under Performance, set Virtualization to On (factory default is Off)
- Set VT for Direct I/O to On (factory default is Off)
You may run into the following error when upgrading from Vagrant 1.4.x to 1.5.x:
/Applications/Vagrant/embedded/lib/ruby/2.0.0/rubygems/version.rb:191:in `initialize': Malformed version number string aws (ArgumentError)
Most likely this means your Vagrant upgrade did not succeed for some reason. One indication is that the file
$HOME/.vagrant.d/setup_version contains the content 1.5 instead of 1.1\n.
The following command fixes this problem:
echo "1.1" > $HOME/.vagrant.d/setup_version
Now you can try re-running Vagrant. See the discussion at Can't start my VM on Vagrant 1.5.1 for details.
The main configuration file is wirbelsturm.yaml (see wirbelsturm.yaml.template).
This configuration file defines the various machines, their roles and additional information such as how many of
each you want to deploy.
We introduced the wirbelsturm.yaml file to simplify the deployment of many machines of the same type. For instance,
here's how you can change your deployment to run 30 instead of 2 Storm slave machines:
# wirbelsturm.yaml: run 2 Storm slaves
nodes:
storm_slave:
count: 2
...# wirbelsturm.yaml: run 30 Storm slaves
nodes:
storm_slave:
count: 30 # <<< changing 2 to 30 is all it takes
...In native Vagrant you would have to copy-paste nearly identical configuration sections 30x in Vagrantfile, in which
only the hostname and IP address would change.
We use a custom Ruby module wirbelsturm.rb that parses the wirbelsturm.yaml configuration file
and hands over this data to Vagrant's Vagrantfile. Vagrant will launch the defined machines and will
then use Puppet to provision them once they have booted.
Our Puppet setup is master-less (no Puppet Master used) and node-less.
One reason to go with a master-less setup was that we have one less dependency (Puppet Master) to worry about. Also, going without a Puppet Master means we do not have to scale or HA the Puppet Master.
The nodeless approach is described at
puppet-examples/nodeless-puppet.
"Nodeless" means that we are not making use of Puppet's
node definitions, which have the form
node 'nimbus1' { ... }. Instead, Wirbelsturm relies on Puppet's so-called facts to define the role of a
machine (through wirbelsturm.yaml) and thus which Puppet code is applied to the machine. These roles determine
which Puppet manifests and which Hiera configuration data will be applied to a machine
("If machine has the 'webserver', then do X, Y, and Z."). One benefit of not using node definitions is that we are
not coupling the hostname of machines to their purpose (read: role).
Under the hood we are using Vagrant's feature of adding the required custom Puppet facts such as their role and the name of the deployment environment to the machines. In the case of deploying to AWS we are also adding the same information to the EC2 tags of the instances. This facilitates identifying and working with the instances on the EC2 console.
Note that you will not see Vagrant-injected custom Puppet facts when you run facter on a guest machine. The
custom fact is only available as a variable to the Puppet manifests/modules.
Wirbelsturm uses the Vagrant plugin vagrant-hosts to manage DNS settings
configured in /etc/hosts on the cluster machines. This only works for the VirtualBox provider though. Wirbelsturm
uses a different approach for the DNS configuration (Route 53) when deploying to
Amazon AWS.
Puppet works best when software is installed as .rpm (RHEL family) or .deb (Debian family) packages instead of
(say) tarballs.
Preferably one would use only official software packages, such as those provided by the official RHEL/CentOS repositories, EPEL or binary releases of the upstream software projects. Unfortunately a number of software projects we want to deploy (e.g. Kafka, Storm) do not provide such RPM packages yet. For this reason we create our own RPMs where needed, and also release the packaging code (see e.g. wirbelsturm-rpm-kafka).
We host our custom RPMs, where needed, in a public yum repository for the convenience of Wirbelsturm users. However we want to become neither a third-party package maintainer nor a third-party repository, so this practice may likely change.
We therefore strongly recommend that you manage your own RPM packages and associated yum repositories, particularly when you are performing production deployments.
A non-comprehensive list of features we are still considering to add to Wirbelsturm.
- Puppet:
- Investigate how we can easily reverse/clean up roles from a machine if a role does not apply anymore (cf. nodeless-puppet). Most of the work in that regard would need to happen on the side of the actual Puppet modules though.
- Amazon AWS
- Investigate whether we want to support deployments to Amazon VPC environments, too.
- Reduce SOA/TTL for Route53 entries to reduce "startup" time for DNS?
- See Creating A Records Dynamically, Can't Ping Them: "Be aware that based on your current SOA record negative responses will be cached for 5 minutes."
Note: The instructions below are subject to change.
Once you have a Storm cluster up and running you can submit your first Storm topology. We will use an example topology from storm-starter to run a first Storm topology in the cluster.
First you will need to install Apache Maven:
# Homebrew
$ brew install maven
# MacPorts
$ sudo port intall maven3
# sudo port select --set maven maven3$ cd /tmp
# Clone Storm
$ git clone git://github.com/apache/storm.git
# At this point you may want to perform a checkout of the exact version of Storm
# that is running in Wirbelsturm (or your "real" Storm cluster).
#
# The Storm team uses git tags to label release versions. The following command,
# for example, checks out the code for Storm 0.9.3:
#
# $ git checkout v0.9.3
#
# You can list all available tags by running `git tag`.
# Build Storm
$ cd storm
$ mvn clean install -DskipTests=true
# Build the storm-starter example
$ cd examples/storm-starter
$ mvn compile exec:java -Dstorm.topology=storm.starter.WordCountTopology
$ mvn packageThe last command mvn package will create a jar file of the storm-starter code at the following location:
target/storm-starter-{version}-jar-with-dependencies.jar
We can now use this jar file to submit and run the ExclamationTopology in our Storm cluster. But first we must make
this jar file available to the cluster machines. To do so you must copy the jar file to the shared/ folder on the
host machine. This folder is mounted automatically in each virtual machine under /shared (note the leading slash).
Note: The version number might be different for you, update the command to match. In the following examples we will use version 0.9.3-SNAPSHOT.
# Run the following command on the host machine in the Wirbelsturm base directory
# (i.e. where Vagrantfile is)
$ cp /tmp/storm/examples/storm-starter/target/storm-starter-0.9.3-SNAPSHOT-jar-with-dependencies.jar shared/For this example we will submit the topology from the nimbus1 machine. That being said you can use any cluster
machine on which Storm is installed.
$ vagrant ssh nimbus1
[vagrant@nimbus1 ~]$ /opt/storm/bin/storm jar \
/shared/storm-starter-0.9.3-SNAPSHOT-jar-with-dependencies.jar \
storm.starter.ExclamationTopology exclamation-topologyThe storm jar command submits a topology to the cluster. It instructs Storm to launch the ExclamationTopology
in distributed mode in the cluster. Behind the scenes the storm-starter jar file is distributed by the Nimbus daemon
across the Storm slave nodes.
You can now open the Storm UI and check how your topology is doing:
- http://localhost:28080/ -- Storm UI
To kill the topology either use the Storm UI or run the storm CLI tool:
$ /opt/storm/bin/storm kill exclamation-topologyFor more details please refer to Running a Multi-Node Storm Cluster.
See CHANGELOG.
Copyright © 2013-2014 Michael G. Noll
See LICENSE for licensing information.
All contributions are welcome: ideas, documentation, code, patches, bug reports, feature requests etc. And you don't need to be a programmer to speak up!
If you are new to GitHub please read Contributing to a project for how to send patches and pull requests to Wirbelsturm.
We want to thank the creators of Vagrant and Puppet in particular, and also the open source community in general. Wirbelsturm is only a thin integration layer between those tools, and none of the features that Wirbelsturm provides would be possible without those existing tools. Many thanks to all of you!
- deploy is based on para-vagrant.sh by Joe Miller.
See also our NOTICE file.