This repository will include source code and demo samples of the Task-aware Unified Source Separation (TUSS) model proposed in the following paper:
@InProceedings{Saijo2025_TUSS,
author = {Saijo, Kohei and Ebbers, Janek and Germain, Fran\c{c}ois G. and Wichern, Gordon and {Le Roux}, Jonathan},
title = {Task-aware Unified Source Separation},
booktitle = {Proc. IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
year = 2025,
month = apr
}We provide multiple audio examples showcasing different use cases of TUSS on our Demo Page.
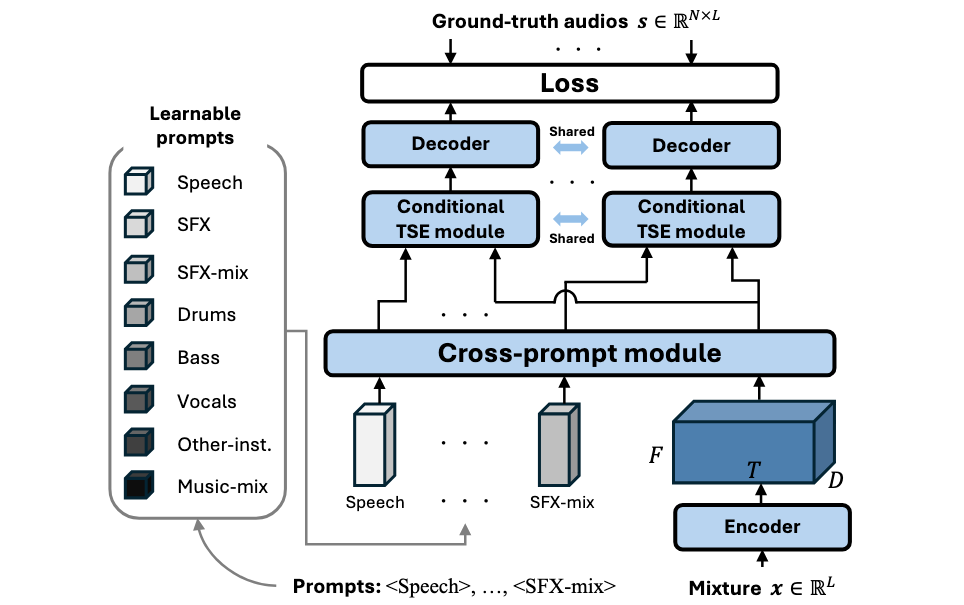
Our proposed task-aware unified source separation model can handle a varying number of input prompts that specify which types of source are present in the mixture and should be separated. Receiving the input mixture's encoded feature and learnable prompt embeddings that specify which source to separate, the cross-prompt module first jointly models both as a sequence to condition one on the other. Then, the source specified by each prompt is extracted by the conditional target source extraction (TSE) module. N sources are speparated given N prompts, where N can be a variable number.
The source code for training and using TUSS will be made available shortly.