Getting Started 🌞
Table Of Contents
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. [1]
A Kafka message is the unit of data that is collected, stored and distributed by Kafka. It is also called an event.
A message can be any piece of data (row, record, map, blob etc...).
Kafka treats all messages as a byte array. The structure is imposed by Publisher and understood by the Consumer.
The size limits exists in Kafka and it is configurable (default 1 MB).
-
Key : defined by the producer of the message
- Not mandatory and also don't need to be unique
- Used for partitioning
- Value : Content of the message. It's a byte array and the semantic of the value is defined by the user.
-
Timestamp : Every message is automatically timestamped by Kafka. Kafka supports two types of automatic time-stamping.
- Event time : when the message producer creates a timestamp.
- Ingestion time : where the Kafka broker timestamp it. (configurable)
Message 1 : Json format
key=1001
value={
"id" : 1001,
"name" : "Bob"
}Message 2 : CSV format
- Kafka assigns a random key when it's not provided by the producer
value="2022-06-26", "182.188.192.1", "200 OK"Message 3 : Image format
key="Customer101"
Value=1001101001010100101010100001111010100010101101010010000Note
- All these messages are internally stored by Kafka as byte arrays. Hence the content can take any form as long as the producers and consumers agree on the format.
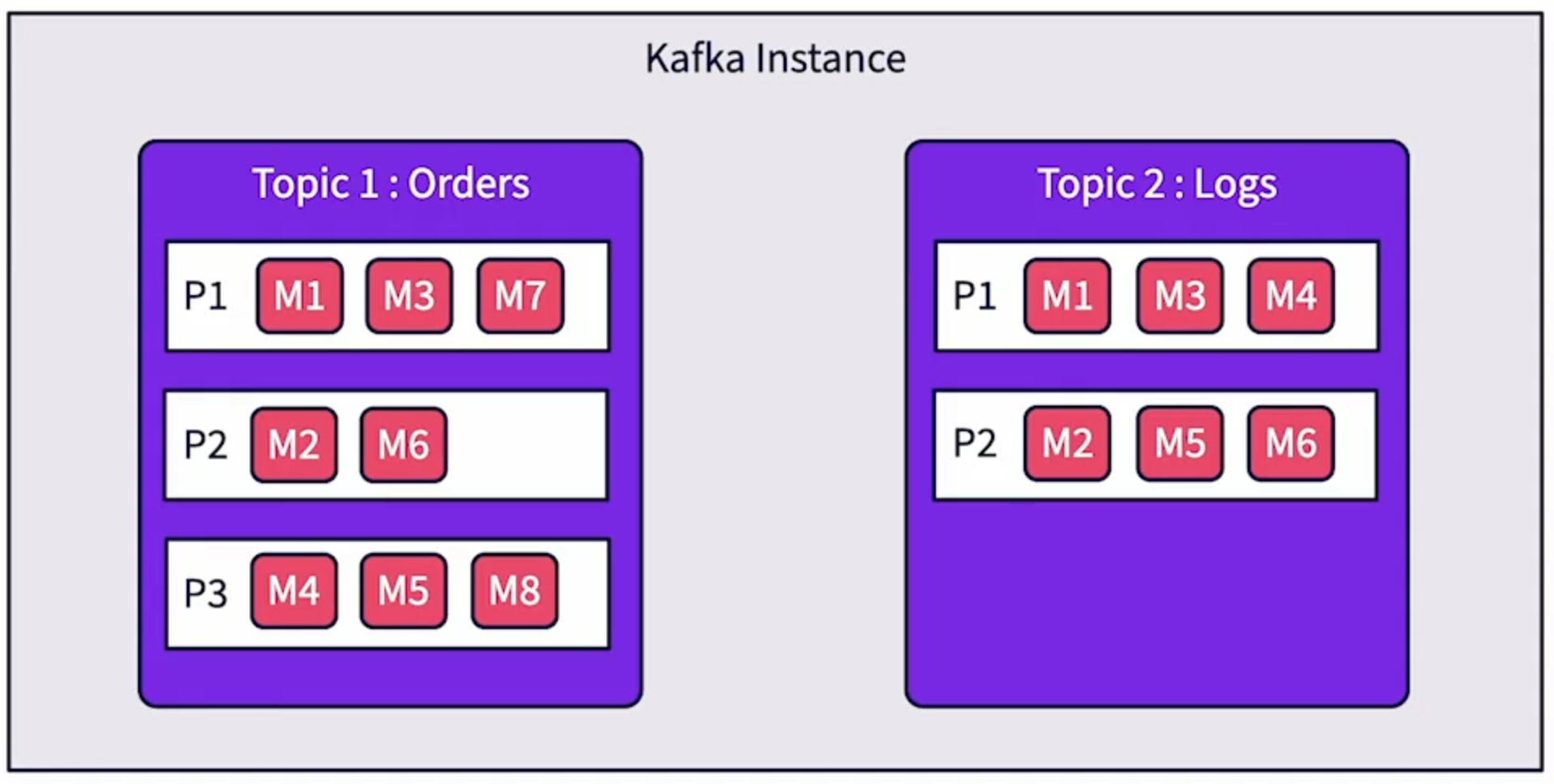
Topics in Kafka hold and manage messages. It can be considered as a queue for similar messages (in practice).
Kafka supports multiple topics per Kafka instance.
Each topic supports multiple Producers and Consumers to publish data to the topic concurrently.
Each topic has multiple partitions that physically split data across multiple files.
Source [2]
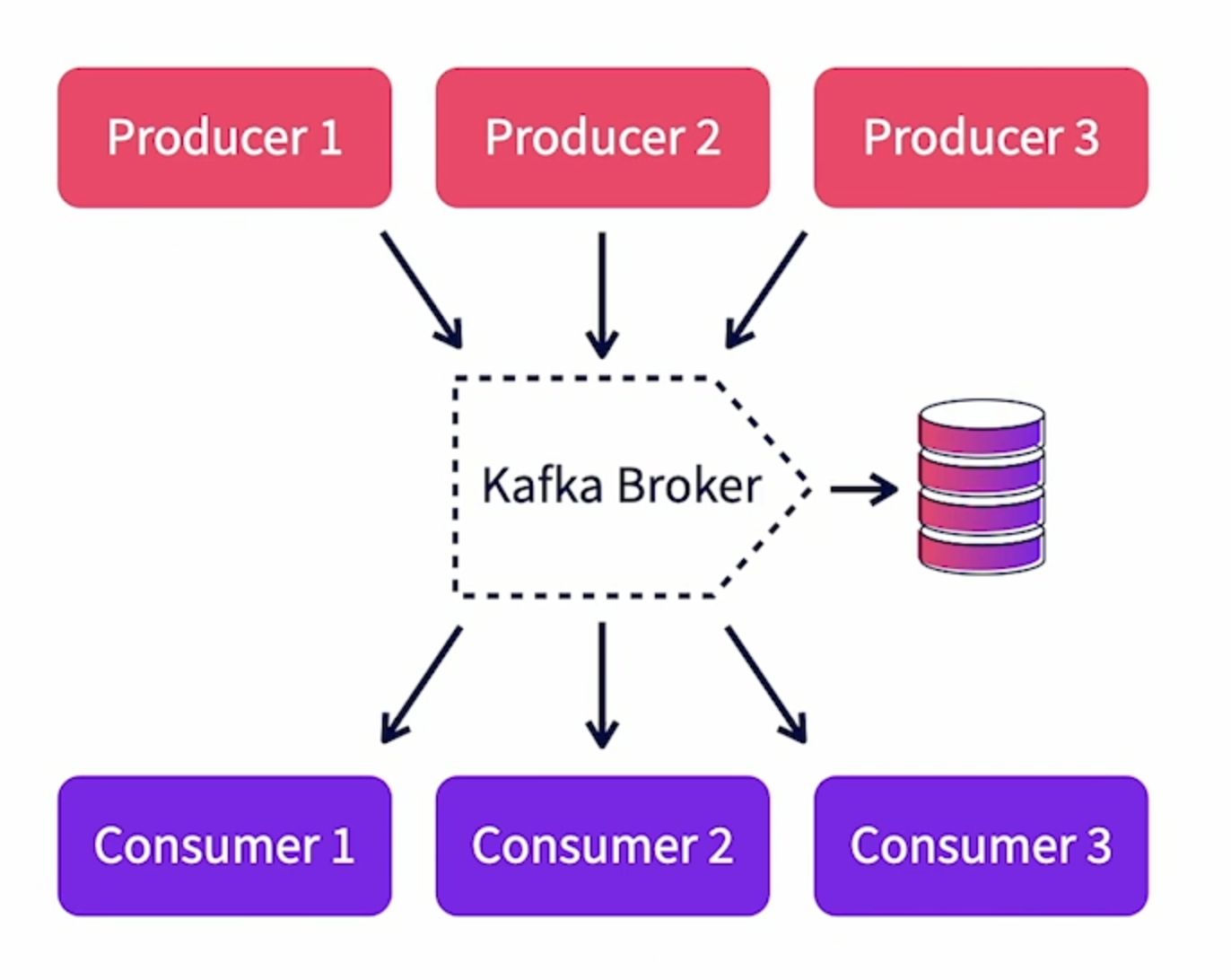
A broker is a running Kafka instance. It is a physical process that runs on the base operating system and executes all Kafka functions.
A Kafka process listens on a specific port. Usually this is 9092 (it's configurable). It receives messages from producers and stores them locally in logs. Consumers subscribe to specific topics within the Kafka broker. The broker keeps track of all active consumers. It also keep a heartbeat with every consumer. So when a consumer dies, it can track and reset.
Kafka brokers manage the life cycle of topics. They track and manage topic partitions as well as the corresponding partition logs.
Multiple Kafka brokers can be clustered together to form a single Kafka cluster. Within a Kafka cluster, there is one Kafka broker instance that will act as the active controller for that cluster.
In addition, each partition will have a corresponding broker as its leader. The leader then manages that specific partition.
A Kafka broker also takes care of replicating topic partitions across multiple brokers. In case one broker goes down, the other brokers can take over the corresponding topic partitions (this provides fault tolerance for Kafka).
Source [2]
Kafka logs are the physical files in which data is stored before being consumed by the consumers. They are managed by Kafka brokers. Each broker has an assigned log directory where it stores the log files.
There are multiple log files created in Kafka. Each broker will have its own log directory. In this directory there are separate files for each topic and partition.
Data in Kafka is only kept for a configured interval of time (7 days by default). A separate thread in Kafka keeps pruning files that are over the configured interval of time. Log files are an important consideration for managing a Kafka instance since they influence the amount of physical space that needs to be provisioned. Lack of space would lead to the broker rejecting data from producers and a breakdown of data processing pipelines.
All configuration for Kafka is in the server.properties file under the config folder of the Kafka installation root folder.
$KAFKA_ROOT/config/server.properties:log.dirs
A producer is any client that published data to Kafka. To build one, the developers needs to use a Kafka client library (libraries are available for multiple languages) within the code and publish data.
There are multiple concurrent producers for each topic (could be in different physical processes or threads in the same process).
It is the job of the producer to :
- Identify the key of the message (typical key would include customer Ids, product Ids etc...).
- Serialize the message data to byte arrays.
There are Synchronous and Asynchronous options available for publishing to Kafka.
Note
- Asynchronous option don't wait for an acknowledgement from the broker before proceeding with the next message. It's faster but results in complex tracking of acknowledgement and republishing.
Used to consume and use the messages from Kafka. Typical examples of consumers include : log filter or data archiver.
Consumers can consume a message anytime (Streaming/batching) as long as the message is stored in the log files and not pruned over.
In real time, the producer and the consumer are running at the same time and as each message is published it is immediately consumed.
There can be multiple concurrent consumers per topic and each consumer will get a complete set of messages from the topic. If scaling is needed beyond one consumer for a specific job, the consumers can be grouped into consumer groups and share the load.
Consumers are responsible for deserializing the messages in byte array format and recreating the original objects sent by the producers. They also can manage the offset for data that they would consume. They can consume from the start of the topic or from a specific offset. They also provide acknowledgement to the brokers once they have successfully consumed a message.
Apache ZooKeeper is an effort to develop and maintain an open-source server which enables highly reliable distributed coordination. [3]
Kafka needs an instance of Zookeeper provision with it on deployment. Zookeeper is a centralized service that is used for storing configuration information as well as helping with distributed synchronization. It serves as the central (real-time) information store for Kafka. There are ongoing efforts to make Kafka independent of Zookeeper ( version >= 2.8.0 [4] ).
Zookeeper helps also Kafka in broker management. When each Kafka broker starts up, they :
- Register themselves with Zookeeper.
- Discover about other Kafka brokers from the same Zookeeper.
Typically, the first broker that starts up, register itself as the active controller. It then controls and manages other brokers in the cluster. If the active controller fails, one of the other brokers will take up the role. This synchronization is handled through Zookeeper.
Zookeeper is also used to manage topics. All topics and their partitions are registered with Zookeeper. It is used to track and manage broker leaders for each of the partitions.
In production environment, it is recommended to install Zookeeper as a cluster to provide fault tolerance.