This project aims to automatically translate and summarize Huggingface's daily papers into Korean using GPT-4o.
Thanks to @AK391 for great work.

Vote: 59
Authors: Xi Chen, Zhengkai Jiang, Zhennan Chen, Ying Tai, Zhizhou Chen, Nikai Du, Jian Yang, Shan Gao
- What's New: TextCrafter는 복잡한 시각적 장면에서 다중 텍스트를 정확하게 렌더링하는 새로운 방식의 텍스트 생성 방법론을 제안합니다. 이 방법은 특히 긴 텍스트, 작은 크기 텍스트, 다양한 숫자 및 기호, 스타일 등 복잡한 시각적 텍스트 생성의 도전 과제를 극복할 수 있도록 설계되었습니다.
- Technical Details: TextCrafter는 세 가지 주요 단계로 구성됩니다: 1) 인스턴스 융합(Instance Fusion)은 시각적 텍스트와 그 주변 환경 간의 강력한 일관성을 보장합니다. 2) 지역 격리(Region Insulation)는 DiT 모델의 사전 학습된 위치 선호도를 이용하여 각 텍스트 인스턴스의 레이아웃 정보를 초기화합니다. 3) 텍스트 집중(Text Focus)은 주의 맵을 향상시켜 텍스트 렌더링의 충실도를 높입니다. 이 방법론은 텍스트의 혼란, 누락 및 흐릿함의 문제를 효과적으로 다룹니다.
- Performance Highlights: 새롭게 제안된 CVTG-2K 벤치마크 데이터셋에서 TextCrafter는 Word Accuracy, NED, CLIPScore 측정에서 기존 최첨단 방법론을 능가하는 우수한 성능을 보였습니다. 특히 TextCrafter는 Word Accuracy에서 72.6%라는 높은 정확도를 기록하였으며, 여러 시각적 텍스트를 안정적이고 정확하게 생성할 수 있음을 입증했습니다.

Vote: 59
Authors: Itay Nakash, Elad Hoffer, Nitay Calderon, Eyal Ben David, Roi Reichart
- What's New: AdaptiVocab는 대형 언어 모델(LLMs)의 효율성을 향상시키기 위해 경량의 어휘 적응 접근법을 제안합니다. 이는 새로운 n-gram 기반 토큰을 도메인에 맞게 적용하여 처리와 생성에 필요한 토큰 수를 줄입니다. 이 방식은 저자원이 필요한 환경에서도 효율성을 높이고 성능 저하 없이 LLMs를 도메인에 맞게 적응하도록 합니다.
- Technical Details: AdaptiVocab는 도메인에 맞춰 토큰을 n-gram 기반으로 교체하여 어휘를 수정합니다. 새로운 n-토큰의 임베딩은 기존 임베딩의 지수 가중 평균으로 초기화하고, 단일 GPU에서 가능한 경량의 파인튜닝을 통해 도메인 적응을 실현합니다. 이 과정은 다양한 토크나이저와 LLM 아키텍처에 적용 가능하며, 적은 연산 비용으로 효율성을 극대화합니다.
- Performance Highlights: AdaptiVocab는 입력 및 출력 토큰 사용량을 25% 이상 줄이고, 생성 품질이나 최종 작업 성능을 유지합니다. 두 개의 7B LLMs 모델을 사용하여, 지구 과학, 물리학 역사, 게임 및 장난감과 같은 세 개의 특정 도메인에서 실험한 결과 이 같은 효율성 향상을 확인했습니다.

Vote: 45
Authors: Ji Hou, Kunpeng Li, Felix Juefei-Xu, Zecheng He, Luxin Zhang, Cong Wei, Tingbo Hou, Wenhu Chen, Haoyu Ma, Animesh Sinha, Bo Sun, Xiaoliang Dai, Peter Vajda
- What's New: MoCha는 영화 수준의 토킹 캐릭터(Talking Characters) 생성 모델로, 최근 동영상 생성 기술의 한계를 극복하며 텍스트와 음성만으로 다중 캐릭터의 동작과 대화를 생성할 수 있습니다. 이는 얼굴을 넘어 전체 캐릭터의 모습과 움직임을 묘사하며, 텍스트와 음성의 동시 조건화를 통해 연속적인 장면 내 감정 표현과 대화의 일관성을 제공합니다.
- Technical Details: MoCha는 웨이브2벡(Wav2Vec2)와 3D 변조 자동 인코더(3D VAE)를 사용하여 말과 영상을 창의적으로 변환하는 디퓨전 트랜스포머(Diffusion Transformer; DiT) 모델입니다. 특히 스피치-비디오 윈도우 주의 메커니즘(Speech-Video Window Attention)을 도입하여, 음성과 비디오 입력 간의 정밀한 협력과 립 싱크를 향상시킵니다. 또한, 다중 캐릭터의 회화 생성이 가능하며, 이로 인해 AI가 생성하는 캐릭터들이 문맥을 이해하고 상황에 맞는 다이얼로그를 진행할 수 있습니다.
- Performance Highlights: MoCha는 MoCha-Bench에서 실시한 광범위한 실질적 및 자동화된 평가지표에서 뛰어난 성능을 보여주었습니다. 인간 평가와 비교기준 시험 모두에서 MoCha는 시네마틱 스토리텔링 분야에서 새로운 표준을 수립하였으며, 실제적인 감정 표현과 컨트롤 가능성, 일반화 측면에서 우수한 결과를 달성했습니다.

Vote: 38
Authors: Ruofei Zhu, Guanlin Liu, Yu Yue, Lin Yan, Wei Shen, Zheng Wu, Qingping Yang, Chao Xin
- What's New: 이번 논문에서는 인간 피드백을 통한 강화 학습(Reinforcement Learning from Human Feedback; RLHF)의 데이터 스케일링과 성능 향상에 중점을 둔 새로운 접근 방식을 제시하였습니다. 특히 보상 해킹(Reward Hacking)과 응답 다양성 저하 문제를 해결하기 위해 새로운 보상 시스템을 설계하고, 수학과 코딩 작업을 초점으로 하는 새로운 학습 전략을 도입하였습니다.
- Technical Details: 보상 해킹 문제를 해결하기 위해 추론 작업 검증자(Reasoning Task Verifiers; RTV)와 생성적 보상 모델(Generative Reward Model; GenRM)을 결합한 하이브리드 보상 시스템을 도입하였습니다. 또한, Pre-PPO라는 새로운 프롬프트 선택 방법을 통해 학습에 도전적인 훈련 프롬프트를 식별하고 우선적으로 사용하여 학습 초기 단계에서 수학 및 코딩 작업을 우선적으로 다루고 있습니다. 이 전략은 보상 해킹 문제를 감소시켜 RLHF 데이터의 스케일링 효과를 개선합니다.
- Performance Highlights: 실험 결과 벤치마크 데이터셋 V1.0에서 Pre-PPO와 수학 및 코딩 작업 우선 전략을 결합한 방법은 베이스라인보다 눈에 띄게 우수한 성능을 보였습니다. 데이터 스케일을 확대하는 것만으로는 성능이 보장되지 않음을 시사하는 결과도 발견되었으며, 티어간의 미세한 차이를 조기에 포착하는 모델의 능력 향상이 RLHF 성능 향상에 중요한 요소임을 확인했습니다.

Vote: 35
Authors: Yinmin Zhang, Heung-Yeung Shum, Xiangyu Zhang, Jingcheng Hu, Daxin Jiang, Qi Han
- What's New: Open-Reasoner-Zero는 대규모 추론 지향 강화 학습을 위해 최초로 오픈 소스 구현된 모델로서, 최적화된 접근법을 제공합니다. 이 모델은 통상적인 KL 정규화 없이도 단순한 규칙 기반 보상을 사용하여, 더욱 효율적이고 신뢰할 만한 학습 과정에서 높은 성과를 보여줍니다.
- Technical Details: Open-Reasoner-Zero는 Proximal Policy Optimization (PPO) 알고리즘을 사용하는데, 이는 Generalized Advantage Estimation (GAE)와 함께 λ=1 및 γ=1로 설정되어 있습니다. 데이터세트는 수학 및 다양한 복잡한 문제 해결 시나리오를 포함한 수만 개의 질의 응답 쌍으로 구성되어 있습니다. 또한, 강화 학습 프레임워크는 대규모 학습을 지원하기 위해 설계되었습니다.
- Performance Highlights: Open-Reasoner-Zero-32B 모델은 DeepSeek-R1-Zero-Qwen-32B보다 적은 학습 단계에서도 AIME2024, MATH500, GPQA Diamond 벤치마크에서 월등한 성능을 입증했습니다. 특히, AIME2025 벤치마크에서는 36.0%의 정확도를 달성하여 눈에 띄는 결과를 보였습니다.

Vote: 35
Authors: Yufei Wang, Zexu Sun, Lei Wang, Xue Liu, Fuyuan Lyu, Chen Ma, Weixu Zhang, Qiyuan Zhang, Irwin King, Zhihan Guo
- What's New: 이 논문은 테스트 시 확장(Test-Time Scaling; TTS)에 관한 종합적인 조사 연구를 언급하고 있습니다. 이전의 데이터 및 파라미터를 이용한 학습 확장이 아닌, 테스트 시 확장을 통해 대형 언어 모델(LLMs)의 성능을 향상시키는 다양한 방법을 제안하고 있습니다. 특히, TTS 관련 연구의 4대 핵심 차원—무엇을 확장할 것인지, 어떻게 확장할 것인지, 어디서 확장할 것인지, 그리고 얼마나 잘 확장할 것인지를 조직화한 새로운 다차원 프레임워크를 제안합니다.
- Technical Details: 제안된 TTS 연구 프레임워크는 무엇을 확장할 것인지, 어떻게 확장할 것인지, 어디서 확장할 것인지, 그리고 얼마나 잘 확장할 것인지의 네 가지 축으로 구분됩니다. 각 축은 TTS 방법론의 구조적 분류, 비교 및 확장성을 지원하며, 다양한 방법론을 체계적으로 분석하여 발전 경로 및 실제 배치를 위한 가이드를 제공합니다. 또한, O1(OpenAI) 및 R1(DeepSeek-AI)과 같은 최신 패러다임을 포함하여 현재 연구의 발전 경로를 논의합니다.
- Performance Highlights: 논문에서 언급하는 TTS의 성능 척도로는 Pass@1, Pass@k (Coverage), Cons@k (Consensus@k), 그리고 Task-Specific Metrics가 포함됩니다. Pass@1은 모델의 첫 번째 출력 시도의 정확성을 평가하며, Pass@k는 모델의 k개의 샘플 중 하나라도 정답인지 여부를 측정합니다. Cons@k는 다수의 예측에서 최빈값의 정확성을 측정하는 데 유용합니다. 이러한 측정 기준들은 LLMs의 다양한 응용분야에서 TTS의 성능을 담보하는데 사용됩니다.

Vote: 29
Authors: Jiakai Tang, Jun Xu, Xu Chen, Wen Chen, Wu Jian, Yuning Jiang, Sunhao Dai, Teng Shi
- What's New: Think Before Recommend는 시퀀스 기반 추천(Sequential Recommendation; SeqRec) 시스템을 위한 추론 단계 계산 프레임워크인 ReaRec을 소개합니다. 이 프레임워크는 기존의 전진 계산 방식이 아닌, 암묵적인 다중 단계 추론을 통해 사용자의 대표성을 향상시킵니다. ReaRec은 추천 시스템의 사용자 표현을 향상시키기 위해 다중 단계 추론을 도입한 최초의 시도입니다.
- Technical Details: ReaRec은 사용자의 마지막 숨겨진 상태(Hidden State)를 순차 추천기(Sequential Recommender)에 자동 회귀적으로 피드백하고, 특별한 추론 위치 임베딩(Reasoning Position Embeddings)을 사용하여 원래 항목 인코딩 공간과 다중 단계 추론 공간을 분리합니다. 이 프레임워크는 Ensemble Reasoning Learning (ERL)과 Progressive Reasoning Learning (PRL)이라는 두 가지 경량 추론 기반 학습 방법을 도입하여 추가로 ReaRec의 잠재 추론 역량을 효과적으로 활용합니다.
- Performance Highlights: ReaRec는 다섯 개의 실제 데이터세트와 여러 SeqRec 아키텍처에서 평균적으로 모든 메트릭에서 7.49%의 성능 향상을 보여주었으며, 실험적으로 최적의 추론 단계는 약 30%-50% 수준의 성능 향상을 보여줍니다. 이는 ReaRec가 시퀀셜 추천에 대한 성능 한계를 대폭 증가시킬 수 있음을 나타냅니다.

Vote: 27
Authors: Junxian He, Zhaochen Su, Xiaoye Qu, Peng Li, Wei Wei, Jing Shao, Yue Zhang, Dongrui Liu, Shuxian Liang, Xian-Sheng Hua, Chaochao Lu, Jianhao Yan, Ganqu Cui, Yafu Li, Daizong Liu, Yu Cheng, Weigao Sun, Bowen Zhou
- What's New: 본 논문은 대형 추론 모델(Large Reasoning Models; LRMs)의 비효율적인 추론 문제를 해결하기 위한 최근의 연구 동향을 조사합니다. LRMs는 특히 체인 오브 소트(Chain-of-Thought; CoT) 추론을 통해 성능을 향상시키지만, 긴 추론 과정이 많은 토큰을 소모하여 비효율을 초래함을 강조합니다.
- Technical Details: 이 논문은 효율적인 추론을 위해 LRM 수명 주기 전반에 걸쳐 제안된 방법들을 조사합니다. 사전 학습, 지도 학습(Supervised Fine-Tuning; SFT), 강화 학습(Reinforcement Learning; RL), 그리고 추론의 각 단계에서 방법론을 분석합니다. 특히, 라틴 공간(Latent Space) 훈련과 선형 시퀀스 모델링 등을 통해 추론 효율성을 개선하려는 노력이 포함됩니다.
- Performance Highlights: 실험 결과, CoT 추론 과정에서 토큰 수를 효율적으로 줄임으로써 모델의 성능을 유지하면서도 계산 비용을 줄일 수 있음을 보여주었습니다. 다양한 제약 조건 하에서 추론 길이를 줄이려는 다양한 방법이 조사되었습니다.
OThink-MR1: Stimulating multimodal generalized reasoning capabilities via dynamic reinforcement learning

Vote: 24
Authors: Ying Sun, Yuting Zhang, Feng Liu, Zhiyuan Liu, Jun Wang, Changwang Zhang
- What's New: OThink-MR1 모델은 동적 강화 학습(Dynamic Reinforcement Learning; DRL)을 사용하여 멀티모달 대형 언어 모델(Multimodal Large Language Models; MLLMs)의 일반화된 추론 능력을 강화하는 새로운 접근 방안을 제시합니다. 이를 통해 GRPO-D(Group Relative Policy Optimization with a Dynamic KL strategy)라는 동적 KL 전략을 도입하여 일반화된 추론 성능을 크게 향상시켰습니다.
- Technical Details: OThink-MR1은 동적 KL 발산(Dynamic KL Divergence) 전략을 활용하여 강화 학습의 탐색과 활용 사이의 균형을 동적으로 조절합니다. 시각적 카운팅(Visual Counting) 및 기하학적 추론(Geometry Reasoning) 작업에 대해 검증 가능한 보상 모델(Verifiable Reward Model)을 통해 샘플링된 출력의 품질을 평가하고 최적화합니다.
- Performance Highlights: OThink-MR1은 같은 작업 분야에서 SFT 대비 5.72% 이상, 기존 GRPO 대비 13.59% 이상의 성능 향상을 보였습니다. 교차 작업 평가에서는 SFT 대비 61.63% 향상된 결과를 기록하여, GRPO-D가 다양한 작업으로 효과적으로 지식을 전이할 수 있음을 입증하였습니다.

Vote: 22
Authors: Zhonghan Zhao, Haian Huang, Wenwei Zhang, Gaoang Wang, Kuikun Liu, Kai Chen, Jianfei Gao
- What's New: RIG는 복잡한 오픈 월드 환경에서 활동하는 구현형 에이전트에게 필수적인 Reasoning(추론)과 Imagination(상상)의 통합을 처음으로 시도한 엔드 투 엔드 Generalist policy입니다. 이 방법은 과거의 에이전트 시스템보다 17배 이상의 샘플 효율성을 개선하며, 일반화된 정책을 함께 학습할 수 있도록 설계되었습니다.
- Technical Details: RIG는 예상 결과를 예측하고 행동을 계획하여 강화하는 방법을 통해 Reasoning과 Imagination을 동시적으로 학습합니다. 이를 위해 autoregressive Transformer 구조를 사용하여 이미지 및 텍스트 추론, 그리고 저수준의 행동을 시퀀스 투 시퀀스 방식으로 모델링합니다. 데이터 수집 전략을 통해 VLM을 사용해 비전을 텍스트로 변환하여 Reasoning을 강화하고, 이후 GPT-4o를 사용해 상상된 결과들을 통해 강화된 경로로 수정함으로써 RIG를 진화시킵니다.
- Performance Highlights: RIG는 Minecraft 환경에서 실험한 결과, 기존의 구현형 작업, 이미지 생성 및 추론 벤치마크에서 각각 3.29배, 2.42배, 1.33배 향상된 최신 성능을 기록했습니다. 이는 111시간의 비디오로 RIG를 훈련하여 2000시간의 비디오를 필요로 하는 과거의 방법보다 휠씬 적은 데이터로 동일하거나 더 나은 성과를 거두었습니다. 또한, RIG는 훈련 및 테스트 시 영역 확대를 가능하게 하여 정책의 견고성과 편리성을 높였으며, 추후 연구의 새로운 방향성을 제시합니다.

Vote: 18
Authors: Jihyun Lee, Daehyeon Choi, Yunhong Min, Minhyuk Sung, Kyeongmin Yeo
- What's New: ORIGEN은 다중 객체와 다양한 카테고리에 대한 3D 방향 기준 하에서 텍스트-이미지 생성(T2I; Text-to-Image Generation)을 가능케하는 최초의 제로-샷 방법입니다. 이 기술은 텍스트 프롬프트와 결합된 지향 조건과 정확히 정렬된 고품질 이미지를 생성합니다.
- Technical Details: ORIGEN은 기존의 텍스트-이미지 생성 모델과 차별화된 샘플링 기반 접근 방식을 채택하여 이미지 현실성을 유지하면서 3D 방향 설정 문제를 해결합니다. 이 방법은 사전에 훈련된 판별 모델(Discriminative Model)을 활용한 보상 함수에 의해 가이드되어 Langevin Dynamics를 통해 샘플링을 수행합니다. 또한, 효율성을 높이기 위해 보상 적응형 시간 재조정을 도입했습니다.
- Performance Highlights: ORIGEN은 MS-COCO 데이터셋을 기반으로 구성한 벤치마크에서 기존의 이미지-지향 생성 모델들을 성능 면에서 능가하며, 다중 객체의 방향 기준에서도 뛰어난 정확성을 보였습니다. 사용자 연구에서는 ORIGEN이 사용자의 58.18%로부터 선호도를 받으며 기존 모델들보다 우수한 평가를 받았습니다.

Vote: 18
Authors: Yuho Lee, Taewon Yun, Hyangsuk Min, Jihwan Bang, Hwanjun Song, Jason Cai, Jihwan Oh
- What's New: ReFeed는 다중 차원에서 요약을 정제하기 위해 피드백을 반영하여 '반성적 추론(reflective reasoning)'을 활용하는 새로운 파이프라인을 소개합니다. 이 연구에서는 가볍고 반성적인 추론 모델을 훈련시키기 위한 대규모 Long-CoT 기반 데이터셋 SumFeed-CoT을 공개합니다.
- Technical Details: ReFeed 파이프라인은 Faithfulness, Completeness, Conciseness의 세 가지 주요 차원에서 요약을 개선하고자 대규모 추론 모델(LRM)을 통해 반성적 추론을 통합하여 요약문을 정제합니다. ReFeed는 External Feedback이 있을 때 생성되는 노이즈와 순서 편향(Order Bias)을 극복할 수 있도록 설계되었습니다. 데이터셋 생성 단계는 Goal Specification, Guideline Formulation, Quality Control로 구분되며, 고품질의 Reasoning 데이터를 수집하여 훈련합니다.
- Performance Highlights: ReFeed는 다중 차원을 고려한 멀티 피드백 싱크론화 접근 방식에서 최고의 성능을 보이며, 특히 Faithfulness에서 2.6, Completeness에서 4.0 점수의 큰 향상을 나타냈습니다. 순서나 노이즈로 인한 편향에 크게 영향을 받지 않습니다. 이는 새로운 반성적 추론 기법이 요약 정제에서 상당한 성능 개선을 가져왔음을 보여줍니다.

Vote: 17
Authors: Liao Shen, Guangcong Wang, Shoukang Hu, Zhiguo Cao, Wei Li, Ziwei Liu, Zihao Huang, Huiqiang Sun, Tianqi Liu, Zhaoxi Chen
- What's New: Free4D는 단일 이미지에서 4D 장면을 생성할 수 있는 새로운 튜닝이 필요 없는 프레임워크입니다. 기존 방법들이 개별 객체 생성에 초점을 맞추거나 대규모 멀티뷰 비디오 데이터셋 훈련에 의존하는 반면, Free4D는 사전 학습된 모델을 활용하여 효율성과 일반성 측면에서 우수한 4D 장면 표현을 제공합니다.
- Technical Details: Free4D는 처음에 입력 이미지를 이미지-비디오 변환(Diffusion) 모델과 4D 기하학적 구조 초기화를 통해 애니메이션화합니다. 이후 포인트 기반 디노이징(Point-guided Denoising)과 참조 잠재 공간 대체(Latent Replacement Strategy)를 통해 공간적 일관성과 시간적 일관성을 유지하는 멀티뷰 비디오를 생성합니다. 최종적으로는 모듈레이션 기반의 정제(Modulation-based Refinement)를 통해 생성된 데이터를 통합하여 일관된 4D 표현을 얻어냅니다.
- Performance Highlights: Free4D는 4Real, 4Dfy, Dream-in-4D와 같은 최신 텍스트-4D 생성 방법들과 비교할 때, 일관성(Consistency), 동적움직임(Dynamic Motion) 및 미적측면(Aesthetics)에서 탁월한 성능을 보였습니다. 특히, 애니메이트124 및 DimensionX와 같은 이미지-4D 생성 방법과 비교할 때 더욱 사실적이고 일관된자유 시점 영상 재구성을 보여주었으며, 사용자 선호도 조사에서도 높은 점수를 기록했습니다.
Perceptually Accurate 3D Talking Head Generation: New Definitions, Speech-Mesh Representation, and Evaluation Metrics

Vote: 16
Authors: Oh Hyun-Bin, Kim Sung-Bin, Lee Chae-Yeon, Han EunGi, Tae-Hyun Oh, Suekyeong Nam
- What's New: 이번 연구는 3D Talking Head 생성에서 지각적으로 정확한 입술 동작을 정의하고 이를 평가할 수 있는 새로운 정의와 지표를 제안하였습니다. Temporal Synchronization, Lip Readability, Expressiveness라는 세 가지 기준을 설정하여 입술 동작의 지각적 정확성을 높였습니다.
- Technical Details: 이번 연구에서는 speech-mesh synchronized representation을 제안하였으며, 이는 speech 신호와 3D 얼굴 mesh 간의 복잡한 대응 관계를 포착합니다. Transformer 기반 아키텍처를 설계하여 시간 순서에 따른 speech와 mesh 입력을 공유된 표현 공간으로 매핑하며, 2단계 학습 방법론을 사용하였습니다. 이 방법론은 대규모 2D 비디오 데이터셋을 활용하여 견고한 오디오-비주얼 speech 표현을 개발하는 것으로 시작합니다. 이를 바탕으로 speech-mesh 표현을 학습하여 지각적 손실(perceptual loss)로 사용할 수 있게 하였으며, 3D Talking Head 모델의 지각적 품질을 개선합니다.
- Performance Highlights: 제안된 지각적 손실 모델은 Temporal Synchronization, Lip Readability, Expressiveness의 세 가지 측면에서 지각적 리얼리즘을 향상시킵니다. 실험 결과, 기존 모델 대비 모든 평가 지표에서 성능을 개선한 것을 확인하였습니다. 또한, MEAD-3D 데이터셋과 VOCASET 데이터셋을 결합하여 학습했을 때, 입술 동작의 표현력을 더욱 향상시킬 수 있음을 보여줍니다.

Vote: 15
Authors: Tommie Kerssies, Niccolò Cavagnero, Bastian Leibe, Giuseppe Averta, Narges Norouzi, Daan de Geus, Gijs Dubbelman, Alexander Hermans
- What's New: Encoder-only Mask Transformer (EoMT)은 ViT(Vision Transformer) 자체를 사용하여 이미지 분할을 수행하는 새로운 접근 방식을 제안합니다. 기존의 ViT에 추가되는 여러 컴포넌트가 대규모 모델 및 광범위한 사전 학습 시 거의 필요하지 않다는 것을 입증하였습니다.
- Technical Details: EoMT는 기존 비전 트랜스포머의 구조를 유지하면서 퀘리(query)를 추가로 사용하여 교차 주의를 통해 이미지 특징과 상호작용하여 마스크와 클래스 레이블을 예측하는 모델입니다. 추가 컴포넌트를 줄이고, 마스킹된 주의(masked attention)가 필요 없는 효율적인 추론을 가능하게 하는 마스크 애닐링(mask annealing) 전략을 제안합니다.
- Performance Highlights: COCO 및 ADE20K 데이터셋에서 EoMT는 128 FPS에서 PQ 56.0을 기록하며, 이는 ViT-Adapter + Mask2Former보다 빠르고 거의 동일한 성능을 보여줍니다. 다양한 대규모 사전 학습 및 모델 크기에서, EoMT는 기존의 복잡한 구조를 가지는 모델들과 비교해 예측 속도와 분할 정확도 사이의 최적의 균형을 보여주었습니다.

Vote: 15
Authors: Chen Zhao, John Sous, Tianyu Yang, Yilun Zhao, Kaiyue Feng, Yixin Liu, Arman Cohan
- What's New: PHYSICS는 대학 수준의 물리학 문제 해결을 위한 포괄적인 벤치마크로, 1,297개의 전문가가 주석을 단 문제를 포함하여 고전역학, 양자역학, 열역학 및 통계역학, 전자기학, 원자물리, 그리고 광학 등 6개의 핵심 영역을 다룹니다. 이는 현재의 프론티어 모델들이 여전히 어려움을 겪는 높은 수준의 과학 문제 해결의 도전 과제를 밝히고 있습니다.
- Technical Details: PHYSICS 벤치마크는 각 문제에 대해 심볼릭 수학을 위한 오픈 소스 라이브러리인 SymPy를 사용하여 수학적 표현을 표준화하고 정답의 정확성을 확인하는 신뢰할 수 있는 자동 평가 시스템을 개발했습니다. 데이터세트는 PhD 자격 시험의 고난도 문제들로 구성되었으며, 이는 모델의 복잡한 문제 해결 능력을 평가하는 데 이상적입니다.
- Performance Highlights: 실험 결과, 가장 발전된 모델인 o3-mini조차도 59.9%의 정확도를 기록했습니다. 이는 현재의 모델들이 긴 추론 체인, 잘못된 가정에 대한 의존, 체계적인 오류, 이미지 이해의 오해, 문제 진술의 오해 등 중요한 과제를 안고 있음을 드러냅니다. GPT-4o와 같은 독점 모델은 대략 37%의 정확도를 기록했으며, 오픈 소스 모델들은 이보다 낮은 성능을 보였습니다.

Vote: 13
Authors: Jiachen T. Wang, Chong Xiang, Tong Wu, Prateek Mittal
- What's New: 이 논문에서는 Thinking Intervention이라는 새로운 패러다임을 제안하여 대형 언어 모델(Large Language Models; LLMs)의 내부 추론 과정을 제어하는 방법을 소개합니다. 특정 'thinking token'을 삽입하거나 수정함으로써 모델의 추론의 미세 조정을 가능하게 합니다.
- Technical Details: Thinking Intervention은 모델의 추론 단계에서 특정 지점을 목표로 하여 명시적 지침을 삽입 또는 수정할 수 있도록 설계되었습니다. 이 방법은 별도의 모델 훈련 없이도 실세계에서 쉽게 배포될 수 있으며, 기존의 프롬프트 엔지니어링이나 세밀한 튜닝 기법과도 호환됩니다.
- Performance Highlights: 이 접근 방식은 다양한 작업에서 기존의 프롬프트 기반 접근법을 능가하여 최대 6.7%의 정확도 향상, 지시 계층에 대한 추론에서 15.4% 개선, 그리고 오픈 소스 DeepSeek R1 모델을 사용하여 안전하지 않은 프롬프트에 대한 거부율을 40%까지 증가시키는 결과를 보여주었습니다.

Vote: 13
Authors: Jiaheng Zhang, Zhiqi Huang, Baolong Bi, Yufei He, Bryan Hooi, Hongcheng Gao, Yue Liu, Hongyu Chen, Jiaying Wu
- What's New: 이 논문은 대형 추론 모델(Large Reasoning Models; LRMs)의 비효율성을 개선하기 위해 설계된 최신 효율적 추론 방법을 종합적으로 검토합니다. 설문은 명시적인 간결한 체인 오브 생각(Chain-of-Thought; CoT)과 암시적 잠재 CoT 등 두 가지 주요 방법으로 나누어 공개됩니다.
- Technical Details: 논문은 명시적인 간결한 CoT와 암시적인 잠재 CoT 방법을 포함한 효율적 추론 방법들의 계층적 분류를 제시하며, 각 방법의 장단점을 토론합니다. 명시적인 방법은 토큰 사용을 줄이면서 명시적 구조를 유지하고, 암시적 방법은 숨겨진 표현을 사용해 추론 단계를 인코딩하는 방식입니다.
- Performance Highlights: 논문은 다양한 실험을 통해 효율적 추론 방법의 성능과 효율성을 조사하며, GSM8K 데이터셋에서의 다양한 모델 성능을 비교합니다. 명시적 CoT 방법과 암시적 CoT 방법 모두 추론 정확도를 유지하면서도 인퍼런스 비용을 줄이는 데 성공했습니다.

Vote: 13
Authors: Feng-Lin Liu, Weicai Ye, Lin Gao, Xintao Wang, Di Zhang, Hongbo Fu, Pengfei Wan
- What's New: SketchVideo는 스케치를 기반으로 비디오를 생성 및 편집하는 새로운 프레임워크입니다. 사용자는 키프레임 스케치를 통해 비디오의 방향 및 움직임을 세밀하게 제어할 수 있습니다.
- Technical Details: 본 연구에서는 DiT 비디오 생성 모델을 기반으로 메모리 효율적인 스케치 제어 네트워크를 제안하였습니다. 스케치 제어 블록은 DiT 블록의 잔여 특징을 예측하고, 입력된 스케치가 시계열적으로 희박한 조건에서 모든 프레임에 전파되도록 '인터프레임 어텐션 메커니즘'(Inter-frame Attention Mechanism)을 도입했습니다. 영상 편집을 위해서는 원본 영상의 공간적 특징과 동적 움직임이 잘 일치하도록 하는 '비디오 삽입 모듈'(Video Insertion Module)을 설계하였습니다.
- Performance Highlights: 다양한 실험 결과, SketchVideo는 제어 가능한 비디오 생성 및 편집에서 우수한 성능을 보였습니다. SketchVideo의 비디오 생성 및 편집 작동 방식은 명시적으로 정의된 스케치와 텍스트 입력을 기반으로 해 현실감 넘치는 비디오 콘텐츠를 생성할 수 있습니다.

Vote: 13
Authors: Kurt Keutzer, Angjoo Kanazawa, Nan Huang, Chenfeng Xu, Wenzhao Zheng, Qianqian Wang, Shanghang Zhang
- What's New: Segment Any Motion in Videos는 동영상에서 움직이는 객체를 분할하기 위한 새로운 접근 방식으로, 장거리 트랙(Long-range Tracks)과 SAM2를 결합하여 효과적인 마스크 밀도화 및 프레임 간 추적을 가능하게 합니다. 기존의 광류(optical flow) 기반의 접근 방식과 달리, 장거리 궤적의 움직임 패턴과 DINO 특징을 결합하여 복잡한 변형 및 카메라 움직임을 처리하는데 탁월한 성능을 보입니다.
- Technical Details: 본 연구에서는 Spatio-Temporal Trajectory Attention과 Motion-Semantic Decoupled Embedding 모듈을 제안하여, 움직임에 기반한 정보와 의미론적 지지를 효과적으로 결합합니다. 구체적으로, 궤적 처리 모델을 통해 예측된 궤적 기반의 모션 레이블을 SAM2와 함께 단계적으로 픽셀 수준의 역동적 마스크로 변환하는 방식을 사용합니다. 이 과정은 DINO v2의 자가 감독 학습(Self-supervised Learning)에 근거한 특징을 포함하여 보다 일반화된 결과를 산출합니다.
- Performance Highlights: 다양한 벤치마크 데이터셋을 대상으로 실험을 수행한 결과, 제안된 방법은 기존의 기법들을 크게 능가하는 성능을 보였습니다. 특히 장거리 움직임 정보의 효과적인 활용을 통해 세밀한 객체 분할에서 탁월한 성능을 입증하였습니다. 실험 화면에서는 물체의 형태, 그림자 반사, 역동적 배경 움직임 및 급격한 카메라 이동을 효과적으로 처리한 결과가 제시되었습니다.

Vote: 12
Authors: Dian Yu, Dong Yu, Juntao Li, Haitao Mi, Min Zhang, Linfeng Song, Zhaopeng Tu, Yi Su
- What's New: 이 논문에서는 검증 가능한 보상(Verifiable Rewards; RLVR)을 활용한 강화학습(RL)을 수학적 추론 및 코딩을 넘어 다양한 영역에 적용하는 것을 다루고 있습니다. 이는 의료, 화학, 심리학, 경제학 등 광범위한 도메인에서의 LLM(대형 언어 모델)의 복잡한 추론 능력을 개선할 가능성을 탐색합니다.
- Technical Details: 논문에서는 도메인 전문가가 작성한 참조 답변이 존재할 때, 폐쇄형 및 오픈 소스 LLM들 간의 높은 일관성을 관측하였습니다. 이러한 환경에서는 대규모 주석이 없이도 교차 도메인 검증자로 사용할 수 있는 생성적 보상 모델을 제안합니다. 제안된 방법론은 7B 모델을 사용하여 일반적인 도메인에서의 효과적인 검증기를 트레이닝 할 수 있음을 보여줍니다.
- Performance Highlights: 본 연구에서 제안된 보상 모델을 사용한 정책들은 다양한 도메인 및 자유형태의 답변 작업에서 최신 오픈소스 정렬 LLM들, 예를 들어 Qwen2.5-72B-Instruct와 DeepSeek-R1-Distill-Qwen-32B를 크게 능가하는 성능을 보였습니다. 특히, 수학 및 다중 주제 데이터를 대상으로 한 평가에서 사용된 새로운 보상 모델은 기존의 규칙 기반 보상을 대체하여 스케일링 실험에서도 안정적인 성능 향상을 보였다고 평가하였습니다.
Zero4D: Training-Free 4D Video Generation From Single Video Using Off-the-Shelf Video Diffusion Model

Vote: 12
Authors: Jangho Park, Taesung Kwon, Jong Chul Ye
- What's New: Zero4D는 훈련이 필요 없는 새로운 4D 비디오 생성 방법을 제안합니다. 단일 비디오에서 다중 뷰 동기화 4D 비디오를 생성하기 위해 오프 더 셀프 비디오 확산 모델(Off-the-Shelf Video Diffusion Model)을 활용하여, 어떤 추가적인 대규모 데이터셋이나 훈련 없이 멀티뷰 비디오를 생성할 수 있습니다.
- Technical Details: Zero4D는 깊이 기반 워핑 기법을 통해 공간적-시간적 샘플링 그리드를 정렬하여 초기 키 프레임을 생성합니다. 이후, 두 축을 따라 양방향 비디오 보간(Bidirectional Video Interpolation)을 통해 4D 비디오 그리드를 완성합니다. 이 과정은 I2V 비디오 확산 모델을 활용하여 프레임의 일관성을 유지하며, 추가적인 워핑 과정으로 인한 픽셀 손실을 보완합니다.
- Performance Highlights: DAVIS와 Pexel 장면에서 실험한 결과, Zero4D는 기존 모델에 비해 FVD, FID, LPIPS와 같은 지표에서 우수한 성능을 보였으며, 주제 일관성과 모션 부드러움에서도 높은 평가를 받았습니다. 특히, Zero4D는 훈련 없이 RTX 4090 GPU로도 실행이 가능하여, 기존 방법들이 요구하는 대규모 데이터셋이나 높은 연산 자원을 필요로 하지 않습니다.

Vote: 12
Authors: Zeshi Yang, Liang Pan, Bo Dai, Wenjia Wang, Zhiyang Dou, Taku Komura, Jingbo Wang, Buzhen Huang
- What's New: TokenHSI는 다양한 인간-장면 상호작용(Human-Scene Interaction; HSI) 기술을 단일 트랜스포머 네트워크(Transformer Network) 내에서 통합하고 학습된 기술을 새로운 과제와 환경에 적응시킬 수 있는 통합된 물리 기반 캐릭터 제어 프레임워크입니다.
- Technical Details: TokenHSI는 인간의 고유감(Proprioception)을 별도의 공유된 토큰(Tokens)으로 모델링하여 마스크(Masking) 메커니즘을 통해 특정 과제 토큰과 결합함으로써 다중 기술의 통합과 유연한 적응을 가능하게 합니다. 또한, 우리 정책 아키텍처는 가변 길이 입력을 지원하여 새로운 시나리오에 대한 학습된 기술의 유연한 적응을 가능하게 합니다.
- Performance Highlights: TokenHSI는 복잡한 HSI 작업에 대한 높은 범용성, 적응성 및 확장성을 보여주며, 기존 방법 대비 높은 샘플 효율성과 성능을 달성하였습니다. 특히, 어려운 등산 및 운반 작업에서 99.2%의 높은 성공률을 유지하며, 향후의 HSI 연구 방향성을 제시하기도 합니다.
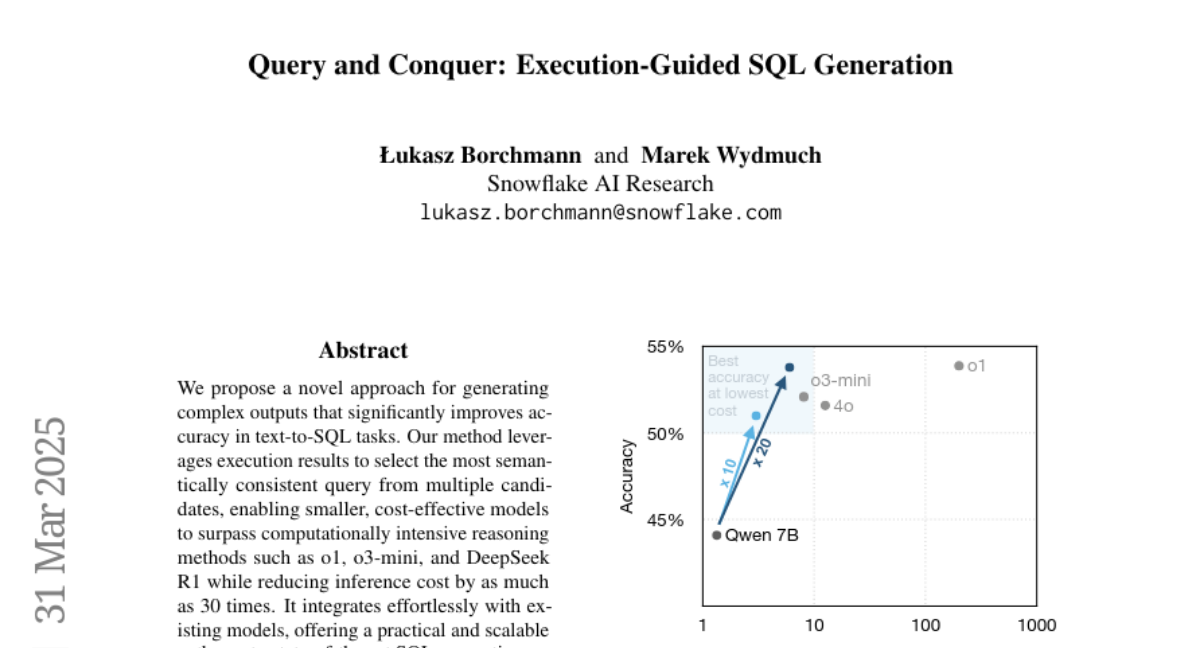
Vote: 12
Authors: Marek Wydmuch, Łukasz Borchmann
- What's New: 이 논문은 복잡한 텍스트에서 SQL로의 변환 작업(text-to-SQL tasks)의 정확성을 크게 향상시키는 새로운 접근 방식을 제안합니다. 이 방법은 실행 결과를 활용하여 여러 후보 쿼리 중에서 가장 의미론적으로 일관된 쿼리를 선택하는 방식을 도입하여, pass@1과 pass@k 사이의 정확도 격차를 줄였습니다.
- Technical Details: 제안된 self-consistency 접근 방식은 SQL 생성에 맞춰 조정되었으며, 정확 및 근사 실행 기반 유사성(metrics)을 사용하여 쿼리 출력에서 의미적 동등성을 직접 평가합니다. 특히 Minimum Bayes Risk (MBR) decoding 프레임워크를 활용하여 이 방법의 이론적 기반을 제공합니다. 또한 특정 SQL 방언의 prefix executability 속성을 활용하여 복합 쿼리의 중간 생성 단계에서 실행 기반 self-consistency를 점진적으로 적용할 수 있습니다.
- Performance Highlights: 제안된 방법은 비용 효율성을 높이는 동시에 성능을 크게 향상시키며, 작은 모델이 더 큰 모델 수준의 성능을 달성할 수 있도록 합니다. 특히 7B 파라미터의 Qwen 2.5 Coder 모델은 우리의 방법을 사용하여 정확도가 거의 10% 향상되었으며, O1과 같은 성능 수준을 달성하면서 추론 비용은 30배 낮았습니다. 결과적으로 execution-guided generation은 작은 모델에서도 품질과 비용 효율성을 제공하며, 복잡한 프로프라이어티 솔루션의 성능과 일치하거나 이를 능가할 수 있습니다.

Vote: 10
Authors: Xiaoguang Han, Yushuang Wu, Jiaqing Zhou, Hao Zhao, Jiahao Chang, Xiaoyang Guo, Ziteng Lu, Chongjie Ye
- What's New: Hi3DGen은 이미지에서 고품질 3D 모델을 생성하는 새로운 프레임워크로, 노말 브리징(Normal Bridging)을 사용하여 2D 이미지를 3D 기하구조로 변환합니다. 이 기술은 특히 고해상도의 상세한 기하구조를 효과적으로 생성할 수 있도록 함으로써 기존 방법들이 가진 한계를 극복합니다.
- Technical Details: Hi3DGen은 세 가지 주요 구성 요소로 구성됩니다: 1) 이미지-노말 추정기(Image-to-Normal Estimator)로 잡음 주입과 듀얼 스트림 학습을 통해 안정적이고 날카로운 노말 추정을 수행합니다. 2) 노말-기하학 학습(Normal-to-Geometry Learning) 접근을 사용하여 노말 맵을 통해 3D 기하학 생성의 충실도를 향상시킵니다. 3) 고품질 데이터세트를 구성하여 훈련을 지원하는 3D 데이터 합성 파이프라인입니다.
- Performance Highlights: Hi3DGen은 기존 최첨단 기법들을 뛰어넘는 높은 기하학적 세부사항을 가진 모델을 생성하는 성능을 보여주었습니다. 정량적 실험 결과, Hi3DGen은 강력한 일반화 능력 및 높은 기하학적 충실도를 달성하였으며, 사용자 연구에서도 높은 선호도를 받았습니다.

Vote: 9
Authors: Minhua Huang, Yachun Pang, Zhiming Ma, Wenjie Tang, Jingpeng Wang, Kai Wu, Yin Yang, Xiangzhao Lv, Yuchen Kang, Peidong Wang
- What's New: TeleAntiFraud-28k는 통신 사기 탐지를 위한 자동화된 시스템 개발을 위한 최초의 오디오-텍스트 슬로우-싱킹 데이터셋(Auto-Text Slow-Thinking Dataset)입니다. 이 데이터셋은 텔레커뮤니케이션 사기 분석을 위한 멀티모달 데이터 통합의 결함을 해결하기 위해 개발되었습니다.
- Technical Details: TeleAntiFraud-28k 데이터셋은 음성 인식(Automatic Speech Recognition; ASR)을 통해 익명화된 통화 기록을 텍스트로 변환하고, 이를 텍스트-음성(Text-to-Speech; TTS) 기술로 현실적인 시나리오에 맞게 재생성합니다. 대형 언어 모델(Large Language Models; LLM)을 통한 자율 샘플링 및 멀티 에이전트 적대적 합성을 통해 시나리오 다양성을 높이는 전략이 사용되었습니다. 데이터셋은 세 가지 핵심 태스크, 즉 시나리오 분류, 사기 판정, 사기 유형 식별을 포함합니다.
- Performance Highlights: 실험에서 Fine-Tuned AntiFraud-Qwen2Audio 모델이 평균 F1 스코어 83%를 기록, 다수의 최신 대형 오디오 언어 모델(Large Audio Language Models; LALMs)을 뛰어넘는 성능을 보였습니다. 이는 오디오 기반 사기 탐지 모델 개발에 데이터셋이 효과적임을 보여주었습니다.

Vote: 9
Authors: André G. Pereira, Jendrik Seipp, Augusto B. Corrêa
- What's New: 이 논문은 대형 언어 모델(LLMs; Large Language Models)을 활용하여 Python 코드로 도메인 의존적 휴리스틱을 자동 생성하여 고전적인 계획 문제(Classical Planning Problem)를 해결하는 혁신적인 방법을 제시합니다. 이를 통해 도메인 독립적 휴리스틱 뿐 아니라 최고 성능의 도메인 의존적 학습 알고리즘과도 경쟁할 수 있는 성능을 보여줍니다.
- Technical Details: 이 연구에서는 계획 도메인이 주어졌을 때, LLM을 활용해 여러 개의 도메인 의존적 휴리스틱 함수들을 Python 코드 형태로 생성합니다. 이후 이들을 탐욕적 우선 탐색(Greedy Best-First Search; GBFS)에 적용하여 가장 강력한 휴리스틱을 선택합니다. 이러한 파이프라인은 Pyperplan이라는 Python 기반의 교육적 계획 플래너에 구현되어 있으며, International Planning Competition (IPC) 2023의 학습 트랙 도메인에서 평가되었습니다.
- Performance Highlights: LLM으로 생성된 휴리스틱은 Pyperplan이 실행되었음에도 불구하고 Fast Downward 같은 C++로 구현된 최첨단 플래너를 넘어서거나 동등한 성능을 보였습니다. 특히, DeepSeek R1 모델을 사용한 휴리스틱이 총 373개의 과제를 해결하며 가장 높은 커버리지를 기록했습니다. 이는 Pyperplan의 비최적화된 Python 구현임에도 불구하고, 고성능 C++ 기반의 계획기를 능가하는 결과를 제공합니다.

Vote: 8
Authors: Jianguo Zhang, Akshara Prabhakar, Caiming Xiong, Shelby Heinecke, Zuxin Liu, Ming Zhu, Zhiwei Liu, Weiran Yao, Silvio Savarese, Huan Wang, Thai Hoang, Tulika Awalgaonkar, Juan Carlos Niebles, Haolin Chen, Juntao Tan, Shiyu Wang
- What's New: ActionStudio는 대형 행동 모델(Large Action Models) 학습을 위한 경량 확장 가능한 데이터 및 학습 프레임워크로, 이종의 에이전트 데이터 경로(Heterogeneous Agent Trajectories)를 표준 형식으로 통합하고, 다양한 학습 패러다임(LoRA, Full Fine-Tuning, Distributed Setup)을 지원하며, 강력한 전처리 및 검증 도구를 통합합니다.
- Technical Details: ActionStudio는 데이터 수집, 형식 통합, 품질 필터링 및 형식 변환을 포함한 데이터 전처리 파이프라인과 대규모 언어 모델(LLM)의 에이전트 작업에 대한 미세 조정(Fine-Tuning)을 위한 학습 파이프라인으로 구성됩니다. PyTorch와 Transformers, DeepSpeed를 사용하여 다양한 효율적인 학습 방법을 지원하고 있습니다. 통합 포맷 2.0(Unified Format 2.0)을 사용하여 다양한 에이전트 데이터 소스를 학습 준비 데이터 세트로 변환합니다.
- Performance Highlights: ActionStudio를 사용하여 학습된 모델은 NexusRaven 및 CRM Agent Bench와 같은 벤치마크에서 뛰어난 성능을 보였습니다. 예를 들어 xLAM-Mixtral-8x22b-inst-exp 모델은 NexusRaven에서 F1 점수 0.969를 기록하며 GPT-4 및 GPT-4o와 같은 상용 모델을 능가했습니다. CRM Agent Bench에서도 xLAM-Llama-3.3-70b-inst-exp 모델이 평균 정확도 0.87로 높은 성능을 기록했습니다.
Progressive Rendering Distillation: Adapting Stable Diffusion for Instant Text-to-Mesh Generation without 3D Data

Vote: 8
Authors: Xinyue Liang, Xiangyu Zhu, Zhiyuan Ma, Zhen Lei, Lei Zhang, Rongyuan Wu
- What's New: 이 논문에서는 3D 데이터가 없이도 텍스트를 순간적으로 3D 메시(meshed)로 변환하는 Stable Diffusion(SD) 모델의 적응에 관한 새로운 훈련 방법인 Progressive Rendering Distillation(PRD)를 제안합니다. PRD는 다중 시점(diffusion) 모델을 교사로 활용하여 SD를 원시 3D 생성기로 변환함으로써 3D 기준 데이터셋에 의존하지 않고도 고품질 3D 메시를 생성할 수 있는 솔루션을 제공합니다.
- Technical Details: PRD는 SD의 U-Net을 사용하여 무작위 노이즈에서 점진적으로 노이즈를 제거하는 여러 단계를 거칩니다. 매 단계마다 노이즈를 제거한 잠재 변수를 3D 출력으로 디코드합니다. MVDream, RichDreamer와 같은 다중 시점 모델을 사용하여 텍스처와 기하학 정보를 3D 출력에 일치하도록 Distillation합니다. 이 방법은 3D 데이터가 필요 없는 학습을 가능케 하며, 모델의 텍스트 입력 일반화 성능을 향상시킵니다. 더 나아가, Parameter-Efficient Triplane Adapter(PETA)를 소개하여 SD를 3D 생성에 적합하게 적은 수의 추가 파라미터로 조정합니다.
- Performance Highlights: 제안된 TriplaneTurbo는 단지 2.5%의 추가 학습 파라미터만으로 기존 텍스트-3D 모델보다 뛰어난 품질과 속도를 보여주며, 텍스트-메시 생성 속도를 1.2초로 줄입니다. 데이터를 확장함으로써, 복잡한 텍스트 입력에도 잘 일반화할 수 있는 성능을 보입니다.

Vote: 8
Authors: Nilabhra Roy Chowdhury, Fabian Güra, Louis Owen, Abhay Kumar
- What's New: 이 논문은 대규모 언어 모델(LLMs)의 활성화 스파이크(Massive Activations)를 체계적으로 분석하여, 이전의 몇몇 가정을 도전하며 모델이 어떻게 내부에서 동작하는지를 탐구합니다. 특히, 모든 큰 활성화가 해로운 것이 아니라는 점과 주의력 KV 편향(Attention KV Bias) 같은 제안된 완화 전략이 모든 경우에서 효과적이지 않음을 밝혀냈습니다.
- Technical Details: 이 연구는 대규모 언어 모델의 활성화 스파이크를 분석하기 위해 다양한 LLM 아키텍처(GLU 기반 및 비 GLU 기반)를 포함하여 대규모의 모델에 대한 실험을 수행했습니다. 연구자들은 주의력 KV 편향과 대상 분산 리스케일링(Target Variance Rescaling; TVR), 다이나믹 탄 (Dynamic Tanh; DyT) 같은 방법들을 사용하여 활성화 스파이크를 관리하는 전략을 조사했습니다. 논문은 김마(Gemma) 모델에서 BOS 토큰이 활성화 스파이크의 등장에 미치는 영향도 탐구했습니다.
- Performance Highlights: 결과에 따르면, 모든 모델에서 활성화 스파이크가 성능 저하를 초래하지 않으며, 일부 경우에는 성능에 거의 영향을 미치지 않았습니다. 대상 분산 리스케일링(TVR)과 같은 하이브리드 전략은 활성화의 극단적인 값을 억제하면서도 모델 성능을 유지하는 데 있어 효과적이었습니다. 이와 함께 DyT, KV Bias와의 조합은 대안적 완화 전략으로 높은 잠재력을 갖고 있었으며, 이를 통해 보다 견고한 LLM 설계를 위한 방향을 제시했습니다.

Vote: 8
Authors: Sara Rojas Martinez, Jun Chen, Letian Jiang, Bing Li, Cheng Zheng, Bernard Ghanem, Abdullah Hamdi, Chia-Wen Lin, Wenxuan Zhu, Jinjie Mai, Mohamed Elhoseiny
- What's New: 4D-Bench는 4D 객체 이해를 평가하기 위한 최초의 벤치마크로, Multi-modal Large Language Models(MLLMs)의 4D 객체 이해 능력을 평가합니다. 4D 객체 질문 응답(Question Answering) 및 4D 객체 캡셔닝(Captioning)을 통한 평가 과제를 제공하여, 기존의 2D 이미지/비디오 기반 벤치마크와는 차별화된 다중 시점 공간-시간적 이해를 요구합니다.
- Technical Details: 4D-Bench는 Objaverse-XL에서 수집된 수만 개의 동적 3D 객체를 활용하여 다중 시점 비디오로 표현된 4D 객체를 제공합니다. 이는 MLLMs가 물체의 시각적 속성을 다각도로 분석하고 이를 종합하며, 또한 시간적 진화를 이해하는 능력을 평가합니다. 데이터는 여러 시점에서 수집된 비디오로부터, MLLMs와 사람의 검증을 통해 생성한 QA 쌍을 포함합니다.
- Performance Highlights: MLLMs는 4D 객체 이해에서 인간에 비해 현저히 낮은 성능을 보이며, 특히 객체 수 카운팅과 시간적 이해 부분에서 어려움을 겪고 있습니다. 예를 들어, 최첨단 GPT-4o는 4D 객체 QA에서 62.98%의 정확도를 보여, 인간의 기준 성능인 91%에 크게 미치지 못했습니다. 이러한 실험 결과는 현재의 MLLMs가 4D 객체 학습에서 개선할 필요가 있음을 시사합니다.

Vote: 6
Authors: Yangguang Li, Chia-Hao Chen, Wanli Ouyang, Yuan-Chen Guo, Xianglong He, Chun Yuan, Ding Liang, Yan-Pei Cao, Zi-Xin Zou
- What's New: SparseFlex는 임의 토폴로지(Topology)를 가진 고해상도 3D 형태 모델링을 가능하게 하는 새로운 희소 구조 이소표면 표현(Novel Sparse-Structured Isosurface Representation)을 소개합니다. 이 방법은 렌더링 손실(Rendering Losses)을 통해 복잡한 기하 구조와 열린 표면의 정확한 재구성을 가능하게 합니다.
- Technical Details: SparseFlex는 Flexicubes와 희소 복셀 스트럭처(Sparse Voxel Structure)를 결합하여, 수면 근처의 계산에 집중합니다. 이 방법은 카메라 뷰 프러스텀 내의 복셀만을 활성화시키는 투영체 인식 섹션 복셀 훈련(Frustum-Aware Sectional Voxel Training) 전략을 도입하여 메모리 소비를 크게 줄입니다. SparseFlex VAE는 3D 모양생성을 위한 고품질 형상 모델링 파이프라인을 제안합니다.
- Performance Highlights: SparseFlex는 이전 방법보다 약 82% 감소한 Chamfer 거리(Chamfer Distance)를 보이며, F-score에서는 약 88% 증가한 성능을 보여줍니다. 이 방법은 고해상도와 세부 사항을 유지하면서 임의의 토폴로지를 가진 3D 형태의 재구성과 생성을 지원합니다.

Vote: 5
Authors: Qixing Huang, Yan Xia, Xiaowei Zhou, Georgios Pavlakos, Etienne Vouga
- What's New: 이 논문에서는 단일 이미지에서 생체역학적으로 정확한 골격 모델을 사용하여 3D 인간을 재구성하는 방법을 소개합니다. SKEL 모델을 기반으로 하고, 트랜스포머 모델을 훈련시켜 이 모델의 파라미터를 추정합니다. 이 접근 방법은 특히 극단적인 3D 포즈 및 관점에서도 기존 방법보다 뛰어난 성능을 보입니다.
- Technical Details: HSMR(Human Skeleton and Mesh Recovery) 방법은 SKEL 모델을 사용하여 단일 이미지 입력에서 골격 및 메쉬를 회복합니다. 훈련 데이터셋이 부족하므로 기존 데이터셋의 SMPL (pseudo) 기본 진실을 SKEL (pseudo) 기본 진실로 변환하여 초기 데이터를 생성하고, 훈련 중 반복적인 개선 절차로 이 데이터를 정제합니다. 이러한 방식은 SPIN과 유사하게 진행됩니다.
- Performance Highlights: HSMR은 기존 최첨단 방법과 비교하여 2D/3D 관절 정확성 평가에서 대등한 성능을 보이며, MOYO와 같은 극단적인 포즈와 시점에서 HMR2.0을 10mm 이상의 큰 차이로 능가합니다. 기존 SMPL 기반의 재구성 방법들은 종종 관절 각도 제한을 어기는 반면 HSMR은 더욱 현실적인 관절 회전 추정을 통해 이러한 문제를 해결합니다.

Vote: 5
Authors: Yueming Jin, Chang Han Low, Junde Wu, Ziyue Wang
- What's New: MedAgent-Pro는 멀티모달(multi-modal) 증거 기반 의료 진단을 위한 혁신적인 에이전트 워크플로우(workflow)를 제안합니다. 이는 특정 질병에 대한 믿을 수 있는 진단 계획을 생성하고, 다양한 지표를 분석하여 정량적 및 질적 증거를 기반으로 한 최종 진단을 제공합니다.
- Technical Details: MedAgent-Pro는 계층적(hierarchical) 구조를 가지고 있으며, Task 수준에서는 지식 기반 추론을 통해 임상 기준을 통합하여 진단 계획을 생성합니다. Case 수준에서는 멀티모달 환자 데이터를 분석하기 위해 전문 도구 에이전트가 사용됩니다. 최종 진단은 decider agent가 통합된 지표를 바탕으로 내립니다. 이 과정에서 도구 에이전트는 분류(Classification), 분할(Segmentation), VQA(Visual Question Answering) 모델 등을 활용합니다.
- Performance Highlights: MedAgent-Pro는 녹내장과 심장 질환 진단에서 최첨단 성능을 보이며, 일반 MLLM과 특정 과제 솔루션을 뛰어넘습니다. 멀티에이전트 워크플로우를 통해 복잡한 진단에서도 높은 정확도와 신뢰성을 입증하였습니다. 특히 MOE(Mixture-of-Experts) 디사이더는 F1 점수에서 단일 LLM 디사이더보다 높은 성능을 보입니다.

Vote: 4
Authors: Yiming Wang, Elisa Ricci, Paolo Rota, Massimiliano Mancini, Alessandro Conti, Enrico Fini
- What's New: 이 연구는 대형 멀티모달 모델(Large Multimodal Models; LMMs)의 진정한 개방형 세계(Open-World) 이미지 분류 능력을 평가하는 첫 번째 포괄적인 분석을 제공합니다. 전통적인 폐쇄형 세계(Close-World) 설정과는 달리, 이 연구에서는 LMMs가 자연어를 사용하여 이미지 분류를 수행하는 방식의 효율성을 조사합니다.
- Technical Details: 이 연구에서는 개방형 세계 이미지 분류 과제를 공식화하고 LLMs와의 정렬을 평가하기 위한 네 가지 상호 보완적인 메트릭을 도입합니다: 텍스트 포함(Text Inclusion), Llama 포함, 의미적 유사성(Semantic Similarity), 개념 유사성(Concept Similarity). 13개의 모델을 10개의 벤치마크에서 평가하여, 원형(Prototypical), 비원형(Non-Prototypical), 미세(Fine-Grained), 매우 미세(Very Fine-Grained) 클래스까지 포함하여 다양한 정밀도를 다룹니다.
- Performance Highlights: LLMs는 비록 폐쇄형 세계 모델의 성능에는 미치지 못하지만, 개방형 세계 설정에서 대비기반(Contrastive-Based) 접근법을 능가합니다. 실험 결과, 특히 Qwen2VL 모델이 높은 성능을 보여주고, InternVL2와 LLaVA-OV 같은 모델들은 원형 분류에서 차별적인 강점을 보여주었습니다. 그럼에도 불구하고, 이러한 모델들은 여전히 분류 간 개념 정밀도 및 정밀한 구별에서 도전을 직면하고 있습니다.

Vote: 3
Authors: Yuliang Xiu, Yue Chen, Andreas Geiger, Anpei Chen, Xingyu Chen
- What's New: Easi3R는 DUSt3R의 주의 메커니즘을 활용하여 훈련 없이 4D 재구성을 할 수 있는 혁신적인 방법을 제시합니다. 이 접근 방식은 기존 모델 훈련이나 파인 튜닝 없이도 동적 객체 분할 및 4D 포인트 맵 재구성을 가능하게 합니다.
- Technical Details: Easi3R는 DUSt3R의 주의 층(attention layers)을 분석하여, 이들 층이 카메라 및 객체의 움직임에 관한 풍부한 정보를 암묵적으로 내포하고 있음을 발견했습니다. 주의 값(attention values)의 재조정을 통해 동적 영역을 효과적으로 분할하고, 카메라 자세 추정 및 4D 재구성을 수행합니다. 이는 추가 비용 없이 DUSt3R의 기존 성능을 상회하는 결과를 보여줍니다.
- Performance Highlights: 다양한 실제 동영상 실험에서 Easi3R는 복잡한 동적 객체와 배경을 효과적으로 분리하고, 카메라 자세 추정 및 4D 포인트 맵 재구성에서 기존의 최첨단 방법들을 능가하는 성능을 보였습니다. 이는 추가적인 데이터셋 학습이나 파인 튜닝 없이도 가능합니다.

Vote: 3
Authors: Zhenyu Liang, Kebin Sun, Ran Cheng, Naiwei Yu, Hao Li
- What's New: 이 논문은 진화형 다목적 최적화(Evolutionary Multiobjective Optimization; EMO) 알고리즘과 GPU 가속화를 텐서화(Tensorization) 방법론을 통해 연결하는 아이디어를 제시합니다. 이를 통해 EMO 알고리즘을 NSGA-III, MOEA/D, HypE와 같은 대표적인 알고리즘에 적용하여 GPU 가속화를 달성합니다.
- Technical Details: 제안된 텐서화 방법론은 EMO 알고리즘의 데이터 구조와 연산을 텐서 표현으로 변환하여 GPU의 자동 활용을 가능하게 합니다. 이 알고리즘들은 브랙스(Brax)와 같은 GPU 가속 물리 엔진을 사용한 다목적 로봇 제어 벤치마크에서 성능을 평가받았으며, 텐서 기반 연산을 통해 효율적인 병렬 처리를 수행합니다.
- Performance Highlights: 텐서화된 EMO 알고리즘은 CPU 기반 알고리즘에 비해 1113배의 속도 향상을 이루었으며, 해의 품질을 유지하면서 수십만 규모의 인구를 효과적으로 처리합니다. 모로보트롤(MoRobtrol) 벤치마크 테스트에서는 고품질의 다양한 행동을 가진 해를 생성하는 능력도 입증되었습니다.

Vote: 3
Authors: Shuo Yang, Munan Ning, Jiayi Ye, Yibing Song, Li Yuan, Zheyuan Liu, Yanbo Wang, Xiao Chen, Qihui Zhang, Yue Huang
- What's New: UPME는 다중 모달 대형 언어 모델(Multimodal Large Language Model; MLLM)의 평가를 위한 새로운 비지도 학습 동료 검토 프레임워크입니다. 이 프레임워크는 사람이 설계한 QA 주석 없이 이미지 데이터만을 활용하여 질문을 자동 생성하고, 다른 모델의 답변을 검토하여 인간 작업 의존도를 줄입니다.
- Technical Details: UPME 프레임워크는 주어진 이미지에 대해 두 개의 후보 모델과 하나의 평가 모델을 랜덤으로 선택하여 진행됩니다. 평가 모델은 질문을 생성하고 각 후보 모델의 답변을 Vision-Language Scoring System을 사용하여 평가합니다. 여기에는 텍스트 응답 정확성, 시각적 이해 및 추론, 이미지-텍스트 상관성이 포함됩니다. 최적화 과정에서 동적 가중치 조정을 통해 모델 점수를 업데이트하고 모델의 평가 정확성을 높입니다.
- Performance Highlights: UPME는 MMstar 데이터셋에서 인간 평가와 Pearson 상관계수 0.944를 달성하며 높은 일치성을 보여주었습니다. ScienceQA 데이터셋에서는 0.814를 기록, 복잡한 데이터셋에서 우수한 성능을 입증했습니다. 이 실험 결과는 UPME가 기존의 동료 평가 방법들에 비해 높은 일관성과 정확성을 가지고 있음을 시사합니다. 또한, UPME는 MLLM-as-a-Judge 프레임워크에서 흔히 발생하는 장황함 및 자기 선호 편향을 효과적으로 줄였습니다.
KOFFVQA: An Objectively Evaluated Free-form VQA Benchmark for Large Vision-Language Models in the Korean Language

Vote: 3
Authors: Jaeyoon Jung, Yoonshik Kim
- What's New: KOFFVQA는 한국어의 대형 비전-언어 모델(Vision-Language Models; VLMs)을 객관적으로 평가할 수 있는 자유형식의 시각적 질문 응답(VQA) 벤치마크로, 기존 평가 방식의 주관성과 신뢰성 문제를 해결하고자 합니다. 이 벤치마크는 275개의 정교하게 제작된 질문과 각 이미지에 대한 평가 기준을 제공함으로써, 모델의 다양한 성능 측면을 측정할 새로운 방법론을 제시합니다.
- Technical Details: KOFFVQA 벤치마크는 세 가지 주요 카테고리와 10개의 하위 카테고리의 질문으로 구성되어 있으며, 각 질문은 이미지와 질문에 따른 사전 정의된 평가 기준을 포함하고 있습니다. 평가 과정에서 LLM(대형 언어 모델 링크: Large Language Models)은 주어진 기준에 기반해 모델의 응답을 점수화하는 방식으로 수행됩니다. 또, 응답의 언어는 langid 라이브러리를 이용해 한국어인지 판단되며, 한국어가 아닌 경우 점수는 0점 처리됩니다.
- Performance Highlights: KOFFVQA 벤치마크 실험에서 47개의 VLMs를 평가한 결과, 모델 크기가 성능 향상에 필수적이지 않음을 발견했습니다. 특히 문서 이해 분야에서는 Gemini 모델들이 높은 평가를 받았으며, 이는 모델의 전반적인 점수와 하위 카테고리의 점수가 항상 비례하지 않다는 것을 시사합니다. 또한, 평가 방식의 일관성을 비교한 결과, 사전 정의된 평가 기준을 사용한 방법이 보다 신뢰할 수 있는 평가를 제공함을 확인했습니다.

Vote: 2
Authors: Zhaoxin Fan, Kejian Wu, Chengwei Qin, Pengxiang Ding, Siteng Huang, Donglin Wang, Ziyue Qiao, Wenjie Zhang, Xiaomin Yu, Songyang Gao
- What's New: Unicorn은 텍스트 기반 데이터 합성을 통해 비전-언어 모델 훈련을 위한 새로운 패러다임을 제시합니다. 이 접근법은 실제 이미지에 대한 의존성을 제거하고, 대신 풍부한 텍스트 데이터를 활용하여 VLM 훈련에 필요한 고품질 멀티모달 데이터를 생성합니다. 주요 성과로는 Unicorn-1.2M과 Unicorn-471K-Instruction 데이터셋이 있으며, 이는 각각 프리트레이닝과 명령어 튜닝에 사용됩니다.
- Technical Details: Unicorn의 텍스트 전용 데이터 합성 프레임워크는 세 가지 단계로 나뉩니다. 첫 번째 단계는 '다양한 캡션 데이터 합성'으로, Qwen2.5-72B-Instruction 모델을 사용하여 1.2M 텍스트 캡션 데이터를 생성합니다. 두 번째 단계는 '명령어 튜닝 데이터 생성'으로, 471K 문장의 명령어 튜닝 데이터가 만들어집니다. 세 번째 단계는 '모달리티 표현 전이'로, LLM2CLIP을 통해 텍스트 표현을 시각적 표현 공간으로 전환하여 의미 있는 이미지 표현을 추출합니다.
- Performance Highlights: 텍스트 전용 합성 데이터셋으로 훈련된 Unicorn-8B 모델은, 여러 벤치마크에서 기존의 이미지-텍스트 쌍을 이용한 전통적인 방법과 동등하거나 또는 더 나은 성능을 보여주었습니다. 예를 들어, ScienceQA-IMG 벤치마크에서 Unicorn-8B는 다른 모델보다 더 높은 71.3의 정확도를 기록했습니다. 이러한 결과는 멀티모달 추론 능력을 포착하는 데 있어 텍스트 전용 훈련 패러다임의 잠재력을 극적으로 보여줍니다.

Vote: 2
Authors: Manish Shetty, Yijia Shao, Koushik Sen, Armando Solar-Lezama, Kevin Ellis, Naman Jain, Ziyang Li, Alex Gu, Wen-Ding Li, Diyi Yang
- What's New: 이 논문은 소프트웨어 엔지니어링에서 인공지능(AI)의 발전과 도전 과제들에 대해 다룹니다. 특히, 자동화된 소프트웨어 엔지니어링의 잠재력을 최대한 발휘하기 위해 해결해야 할 문제들이 많이 남아있음을 강조하며, 이러한 목표를 달성하기 위한 연구 방향을 제시합니다.
- Technical Details: 이 논문은 소프트웨어 엔지니어링 AI의 다양한 구체적인 과업을 체계적으로 분류하고, 현재 전략의 한계를 제한하는 주요 병목 현상을 제시합니다. 이어서 이러한 병목 현상을 극복하기 위한 가능성 있는 연구 방향을 제공하며, 각각의 도전 과제에 해당하는 연구 방향을 요약합니다.
- Performance Highlights: 현재의 인공지능 모델들은 더욱 복잡하고 대규모 프로젝트의 요구를 충족하지 못하고 있음이 나타났습니다. 특히 코드 생성 외에도 다양한 소프트웨어 엔지니어링 과업에 대한 연구가 필요하며, 이를 통해 전체 시스템의 성능을 의미 있게 향상시킬 수 있음을 시사합니다.

Vote: 2
Authors: EunJeong Hwang, Yuwei Yin, Giuseppe Carenini
- What's New: SWI(Speaking with Intent)는 LLMs(Large Language Models)가 명확하게 의도를 생성하여 문제 분석과 논리적 추론을 위한 고급 계획 지침을 제공하도록 하는 새로운 개념입니다. 인간의 의도적인 사고를 모방하여 LLMs의 추론 능력과 생성 품질을 향상시킬 수 있다고 제안됩니다.
- Technical Details: SWI는 LLMs가 자신의 의도를 명확히 말하여 고급 계획 메커니즘으로 활용하는 방법입니다. 이를 위해 자동회귀(autoregressive)와 주의(attention) 메커니즘이 사용되며, 시스템 및 사용자 프롬프트를 통해 의도를 생성하도록 모델에 지시합니다. 또한, 다양한 작업 범주 즉, 수학적 추론, 선택형 QA, 텍스트 요약에서 SWI의 효과를 평가하였습니다.
- Performance Highlights: SWI를 활용한 실험 결과, 베이스라인 대비 성능이 지속적으로 향상되었으며 Chain-of-Thought(Chain-of-Thought, CoT) 및 Plan-and-Solve(Plan-and-Solve, PS)와 같은 기존의 프롬프팅 방법을 초과합니다. 특히 경쟁 수준의 수학 문제 해결에서는 ARR(Analyzing, Retrieving, and Reasoning)을 능가하였습니다. 요약 작업에서는 SWI가 보다 정확하고 간결하며 사실적인 요약을 생성하는 것으로 나타났습니다.
Vote: 2
Authors: Junyi Chen, Wanli Ouyang, Di Huang, Xiaoshui Huang, Xianglong He, Chun Yuan, Yangguang Li, Zexiang Liu
- What's New: MeshCraft는 최근 AI 기술을 활용하여 고품질의 3D 메시를 효율적으로 생성하고 제어할 수 있는 새로운 프레임워크입니다. 이 시스템은 연속적인 공간 확산과 디퓨전 기반 트랜스포머(DiTs)를 활용하여 미리 정의된 메시 면(face)의 수를 조건으로 하는 3D 메시를 생성합니다.
- Technical Details: MeshCraft는 두 가지 주요 구성 요소로 이루어져 있습니다. 첫째, 트랜스포머 기반 VAE는 원시 메시를 지속적 페이스레벨(face-level) 토큰으로 인코딩하고 이를 원래 메시로 디코딩합니다. 둘째, 플로우 기반 디퓨전 트랜스포머는 페이스 수를 조건으로 하여 고품질 메시를 생성하도록 설계되었습니다. 이 시스템은 ShapeNet 및 Objaverse와 같은 데이터셋에서 뛰어난 성능을 발휘합니다.
- Performance Highlights: MeshCraft는 기존의 자동 회귀 방식보다 35배 빠른 속도로 800개의 면으로 구성된 메시를 3.2초 만에 생성할 수 있습니다. 또한, 정성적 및 정량적 평가에서 최신 기법을 능가하는 성능을 보였습니다.
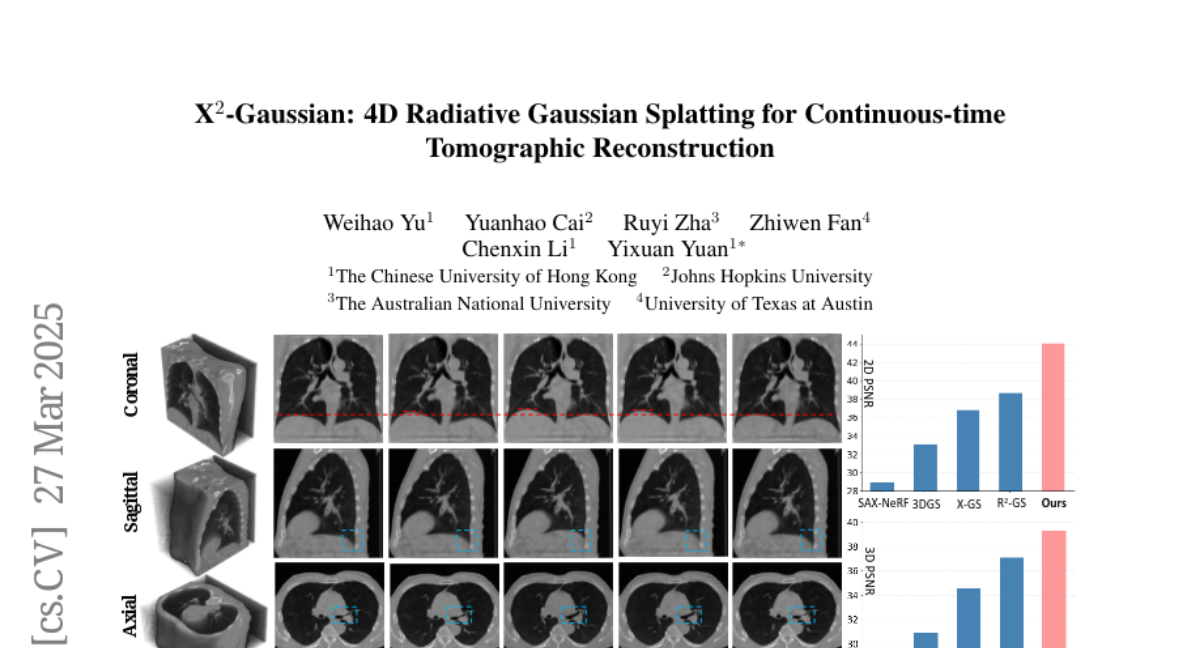
Vote: 2
Authors: Yuanhao Cai, Zhiwen Fan, Weihao Yu, Ruyi Zha, Chenxin Li, Yixuan Yuan
- What's New: X2-Gaussian는 4D CT 복원에서 연속적 운동 분석을 가능하게 하는 최초의 프레임워크입니다. 이 연구는 외부 게이팅 장치의 필요성을 없애고, 환자별 호흡 주기를 스스로 학습하는 방법을 도입하여 환자에게 물리적 제약을 주지 않습니다.
- Technical Details: X2-Gaussian는 3D Gaussian Splatting(3DGS)을 시간 영역으로 확장하여 동적 가우시안 운동 모델(Dynamic Gaussian Motion Model)을 개발했습니다. 이는 공간-시간 인코더 디코더 구조로 구현되며, 여기서 점차적인 변형 매개변수를 예측합니다. 또한, 자기 지도 학습(Self-supervised Learning)을 통해 외부 장치 없이 환자의 호흡 사이클을 추정할 수 있습니다. 중요한 요소로는 물리학 기반 주기적 일관성 손실(Physiology-driven Periodic Consistency Loss)이 도입되어 주기적 연속성을 학습합니다.
- Performance Highlights: 제안된 방법은 기존 방법들에 비해 PSNR에서 평균 9.93 dB의 향상을 보여주며, SSIM에서도 우수한 성능을 확인했습니다. 이는 의료 영상에서 뛰어난 복원 품질을 보여주고 있으며, 특히 호흡 움직임 모델링에서의 정확성을 입증합니다.

Vote: 1
Authors: Mingyu Derek Ma, Wei Wang, Yihe Deng, Xiaoxuan Wang
- What's New: 이 논문에서는 자기 학습(Self-Training)에 불확실한 데이터를 강조하기 위한 엔트로피 기반 적응 가중(Entropy-Based Adaptive Weighting)을 제안합니다. EAST는 모델의 샘플 분포에서 엔트로피를 측정하여 불확실한 데이터에 보다 높은 가중치를 할당함으로써 모델의 추론 능력을 향상시킵니다.
- Technical Details: EAST는 문제에 대한 LLM의 불확실성을 클러스터 기반 분포의 엔트로피로 측정한 후 매핑 함수(mapping function)를 적용하여 가중치를 할당합니다. 이 함수는 조정 가능한 매개변수를 포함하여 불확실한 데이터에 대한 유연한 강조를 가능하게 합니다. EAST는 SFT, DPO와 같은 다양한 손실 함수와 통합이 가능하며 반복적 자기 학습과도 잘 작동합니다.
- Performance Highlights: EAST는 GSM8K 벤치마크에서 5.6%, MATH 벤치마크에서 1%의 성능 향상을 보였습니다. 이는 기존의 버닐라(self-training) 방법보다 월등히 높은 결과로, 엔트로피 기반 가중이 불확실한 데이터를 보다 잘 활용하여 모델의 추론 능력을 향상시킴을 보여줍니다.

Vote: 1
Authors: Yanbo Fan, Yibing Song, Qifeng Chen, Ziyu Wan, Hongyu Liu, Yujun Shen, Jingye Chen, Xuan Wang, Yue Ma
- What's New: AvatarArtist는 다양한 도메인에서 고품질의 4D 아바타를 생성하는 데 중점을 둔 새로운 모델로, 얼굴 특징 및 움직임을 유지하면서 디지털 아바타를 생성하는 방법을 제공합니다. 이를 통해 AI 기반 콘텐츠 생성의 새로운 가능성을 열며, 코드 및 데이터가 공개되어 후속 연구를 활성화합니다.
- Technical Details: 이 연구는 매개 변수적 삼평면(parametric triplanes)을 중간 표현으로 사용하고, GAN과 확산 모델(diffusion models)을 결합한 학습 방법론을 제안합니다. Next3D와 같은 4D GAN을 사용하여 다양한 도메인의 다중 GAN을 효율적으로 학습시킵니다. 다중 도메인 이미지를 생성하기 위해 SDEdit와 ControlNet을 결합하여 다양한 스타일로 이미지를 변환하고, 이는 4D GAN 학습에 사용됩니다.
- Performance Highlights: AvatarArtist는 다양한 출처 이미지에 대해 강력한 견고성을 가지고 고품질의 4D 아바타를 생성합니다. 다른 방법론과의 비교에서, Pose 및 표현 일관성, 아이덴티티 보존에 있어 더 우수한 성능을 보였으며, 실험적으로 3D 구조 보존과 시각적 충실도 측면에서 뛰어난 성능을 입증했습니다.

Vote: 1
Authors: Yin Li, Yiwu Zhong, Yiquan Li, Khoi Duc Nguyen, Zhuoming Liu
- What's New: PAVE는 Pre-trained Video LLMs(Video Large Language Models)를 다양한 다운스트림 작업에 적응시키기 위한 새로운 프레임워크입니다. 이 프레임워크는 오디오, 3D 신호 또는 다중 시야 비디오와 같은 사이드 채널 신호를 통합하여 모델 성능을 향상시킵니다.
- Technical Details: PAVE는 '패치'라고 불리는 경량의 어댑터를 기본 모델에 추가하여 기존 아키텍처나 사전 학습된 가중치를 변경하지 않고 추가적인 매개변수와 연산을 최소화하여 적응성을 제공합니다. 이 어댑터는 열쇠와 값으로 사용되는 사이드 채널 신호와 쿼리로 사용되는 주키 프레임 사이에서 교차 주의를 활용하여 시간 축에 따라 신호를 융합하고 입력 비주얼 토큰을 업데이트합니다.
- Performance Highlights: PAVE는 상태-of-the-art 수준의 작업별 모델을 능가하면서 χ0.1%의 FLOPs와 매개변수를 추가하고, 다양한 비디오 LLM에 대한 멀티 태스크 학습을 지원하는 등 다양한 작업에서 기본 모델의 성능을 일관되게 향상시켰습니다. 예를 들어, Audio-Visual QA, 3D QA, 고 프레임 속도 비디오 이해, 다중 시야 비디오 인식에서 각각 2%, 6%, 1~5%, 1%의 성능 향상을 이루었습니다.

Vote: 1
Authors: Leander Girrbach, Zeynep Akata, Massimo Bini
- What's New: Decoupled Low-rank Adaptation (DeLoRA)는 새로운 파라미터 효율적 미세조정(Parameter Efficient FineTuning; PEFT) 방법으로, LoRA와 ETHER의 강점을 결합하여 각각의 한계를 극복합니다. DeLoRA는 학습 가능한 저랭크 행렬을 정규화 및 스케일링 함으로써 각도 학습과 적응 강도를 효과적으로 분리하여, 높은 성능과 강인성을 제공합니다.
- Technical Details: DeLoRA는 저랭크 행렬의 학습 가능한 경계를 도입하여 가중치 갱신 범위를 정함으로써 LoRA의 각도 학습과 적응 강도를 분리합니다. 이를 통해 다양한 학습 설정에서 성능을 유지하면서도 개인화 및 추론 시 결합 기능을 보존할 수 있습니다. 또한 DeLoRA는 학습률과 무관하게 경계를 설정하고, 이를 통해 피튜닝 시 다양한 설정에 적응성을 높였습니다. 이 방법은 가중치의 높은 표현력과 미세 조정 강인성을 가능하게 합니다.
- Performance Highlights: DeLoRA는 자연어 이해, 이미지 생성, 사용 지침 조정 등 다양한 기준에서 평가되었으며, 경쟁사 PEFT 방법과 비교했을 때 성능이 같거나 우수한 결과를 나타냈습니다. 특히 학습률 변화와 확장된 학습 기간 동안 크게 성능이 저하되지 않음을 보여주며, 우수한 강인성을 입증했습니다.

Vote: 0
Authors: Andrea Vedaldi, Christian Rupprecht, Ruining Li, Chuanxia Zheng
- What's New: DSO는 새로운 물리 시뮬레이션 최적화(Direct Simulation Optimization; DSO) 프레임워크를 통해 물리적 안정성을 보장하는 3D 객체를 생성합니다. DSO는 비분화 가능한 시뮬레이터를 활용해 3D 생성기가 물리적 안정성을 가진 객체를 직접 출력하도록 설계되었습니다.
- Technical Details: DSO는 물리 시뮬레이터로부터 안정성 점수를 받은 3D 객체 데이터셋을 구축하고, 이를 기반으로 직접 선호 최적화(Direct Preference Optimization; DPO) 또는 직접 보상 최적화(Direct Reward Optimization; DRO)라는 새로운 목적 함수를 통해 3D 생성기를 미세 조정합니다. DRO는 쌍별 선호 데이터 없이도 확산 모델을 외부 선호에 따라 조정할 수 있습니다.
- Performance Highlights: DSO를 적용한 모델은 테스트 시간 최적화가 없는 상태에서도 생성 시 물리적 안정성을 유지하며, Atlas3D 및 PhysComp와 같은 기존 방법보다 안정성과 기하학적 품질 면에서 우수한 성능을 보여줍니다. DSO는 특히 DRO 목적을 채택한 경우, 빠른 수렴과 우수한 정렬 성능을 나타냅니다. 이 프레임워크는 실제 3D 객체를 학습 데이터로 필요로 하지 않으며, 자신의 출력에 대한 시뮬레이션 피드백으로 자체 개선이 가능합니다.

Vote: 0
Authors: Taein Kwon, K R Prajwal, Andrew Zisserman, Sindhu B Hegde
- What's New: 이 연구는 'in-the-wild' 환경의 화행 제스처(co-speech gestures) 이해에 대한 새로운 프레임워크를 소개합니다. 특히 제스처 기반 검색(gesture-based retrieval), 제스처 단어 스포팅(gesture word spotting), 제스처를 통한 활성 화자 감지(active speaker detection)라는 세 가지 새로운 과제를 제시하고 이를 평가하기 위한 벤치마크를 새로 제안했습니다.
- Technical Details: 제안한 모델은 제스처, 오디오, 텍스트를 통합하는 'Joint Embedding space for Gestures, Audio, and Language' (JEGAL)라는 트라이모달 표현을 학습합니다. 두 가지 손실 함수인 글로벌 프레이즈 대조 손실(global phrase contrastive loss)과 로컬 제스처-단어 결합 손실(local gesture-word coupling loss)을 통해 약하게 감독된 방식으로 이러한 표현을 학습합니다. 이를 위해 간단한 멜스펙트로그램(melspectrogram), XLM-RoBERTa 등의 백본을 활용한 인코더를 사용합니다.
- Performance Highlights: JEGAL은 세 가지 과제에서 기존 방법과 비교해 뛰어난 성능을 보여주었습니다. 예를 들어, CROSS-MODAL RETRIEVAL(posts)에서 Recall@5는 17.4%에 달하며 다른 기술들과 비교하여 월등히 높은 성능을 기록했습니다. 이처럼 JEGAL은 제스처, 연설, 텍스트 간의 통합적인 이해에 기반한 향후 응용 가능성을 제시합니다.
This project is licensed under the CC BY-NC 4.0 license.
If this work is helpful, please kindly cite as:
@misc{daily_papers,
title = {Huggingface Daily Papers},
author = {AK391},
howpublished = {\url{https://huggingface.co/papers}},
year = {2023}
}
@misc{daily_papers_ko,
title = {Automatically translate and summarize huggingface's daily papers into korean},
author = {l-yohai},
howpublished = {\url{https://github.com/l-yohai/daily_papers_ko}},
year = {2023}
}