- 유사한 straming sw(storm, flink, samza 등)들과 실시간 분산처리 성능은 유사하고,
- 또한 데이터의 유실을 방지하는 exactly once도 유사하게 지원한다.
- Apache spark의 장점은 실시간 처리와 함께 다양한 plugin(Graphx, SQL, MLlib)을 제공하여 원하는 제품을 쉽게 확장할 수 있는데 그 장점이 있다. (Apache Flink도 일부 유사함)
- 또한 수많은 commiter & contrubuter들의 참여 및 기업에서의 적용/투자를 통하여 제품의 안정성 및 성능이 지속적으로 검증 및 개선된다는 장점도 있다
- 이는 Open source sw를 도입하고자 하는 기업의 관점에서는 가장 중요한 항목중에 하나이다.
- install
$ cd ~/study-spark-streaming-redis/sw/
$ wget http://d3kbcqa49mib13.cloudfront.net/spark-2.0.1-bin-hadoop2.7.tgz
$ tar -xvf spark-2.0.1-bin-hadoop2.7.tgz
$ cd spark-2.0.1-bin-hadoop2.7
- set spark configuration
- spark environment
# slave 설정 $ cp conf/slaves.template conf/slaves localhost //현재 별도의 slave node가 없으므로 localhost를 slave node로 사용 # spark master 설정 # 현재 demo에서는 별도로 변경할 설정이 없다. (실제 적용시 다양한 설정 값 적용) $ cp conf/spark-env.sh.template conf/spark-env.sh- add spark path to system path
vi ~/.bashrc export SPARK_HOME=~/study-spark-streaming-redis/sw/spark-2.0.1-bin-hadoop2.7 export PATH=$PATH:$SPARK_HOME/bin- Set ssh connection without password
$ ssh-keygen -t rsa # 설정사항 모두 공백인 상태로 Enter $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod og-wx ~/.ssh/authorized_keys $ ssh user_id@localhost # 정상적으로 접속되는지 확인
- run spark master
$ cd ~/study-spark-streaming-redis/sw/spark-2.0.1-bin-hadoop2.7
$ sbin/start-all.sh
- open spark master web-ui with web browser
http://localhsot:8080
- In memory cache, NoSQL key-value data store.
- install redis
$ cd ~/study-spark-streaming-redis/sw
$ wget http://download.redis.io/releases/redis-3.0.7.tar.gz
$ tar -xzf redis-3.0.7.tar.gz
$ cd redis-3.0.7
$ make
- python에서 redis에 접속하기 위해서 redis 라이브러리를 설치
$ sudo pip install redis
$ sudo pip install numpy
$ src/redis-server
- set & get example
$ cd ~/study-spark-streaming-redis/sw/redis-3.0.7
$ src/redis-cli
redis> set kim seongho
OK
redis> get kim
"seongho"
- hashmap example
redis> HSET testhash field1 "kim"
(integer) 1
redis> HSET testhash field2 "seongho"
(integer) 1
redis> HGETALL testhash
1) "field1"
2) "kim"
3) "field2"
4) "seongho"
redis> HGET myhash field1
"kim"
- 기존 사용하던 Docker-Elasticsearch-Kibana 사용
- 기존 사용하던 docker-kafka-zookeeper 사용
- install
$ mkdir ~/study-spark-streaming-redis/sw
$ cd ~/study-spark-streaming-redis/sw
$ wget https://artifacts.elastic.co/downloads/logstash/logstash-7.6.1.tar.gz
$ tar xvf logstash-7.6.1.tar.gz
- set logstash path to $path
$ vi ~/.bashrc
export PATH=$PATH:~/study-spark-streaming-redis/sw/logstash-7.6.1/bin
logstash -e 'input { stdin { } } output { stdout {} }'
# 아래와 같은 메세지가 stdin 입력을 받을 준비가 됨.
Settings: Default pipeline workers: 1
Pipeline main started
# 메세지 입력 후 엔터
hi logstash
# 아래와 같은 메세지가 출력되며 정상
2021-03-0201:22:14.405+0000 0.0.0.0 hi logstash
# Ctrl + D로 종료
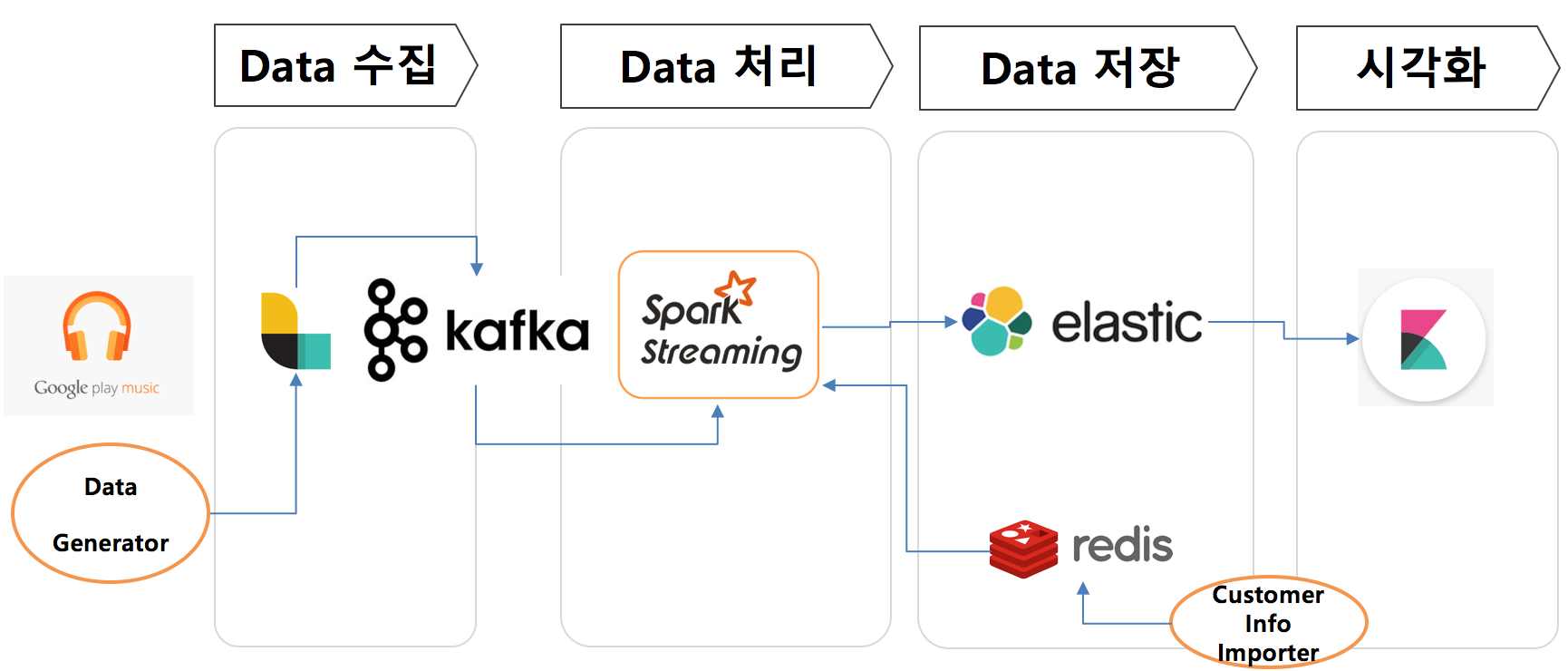
- 개요
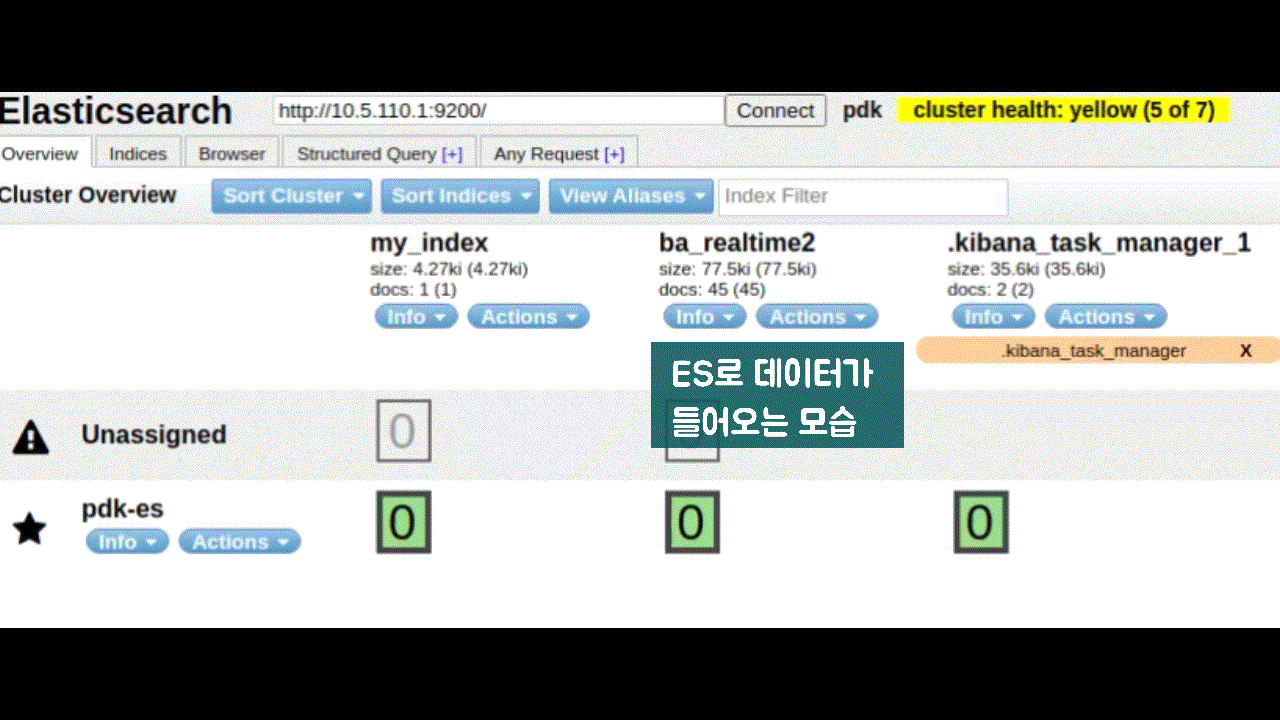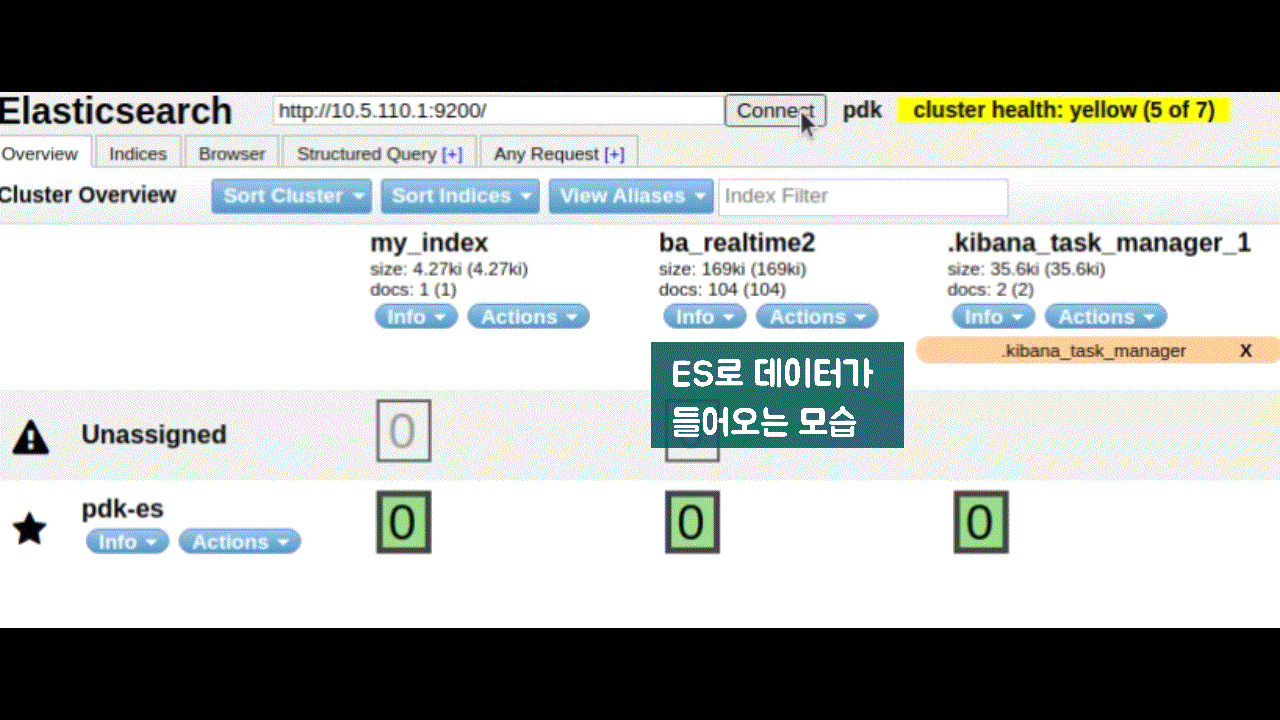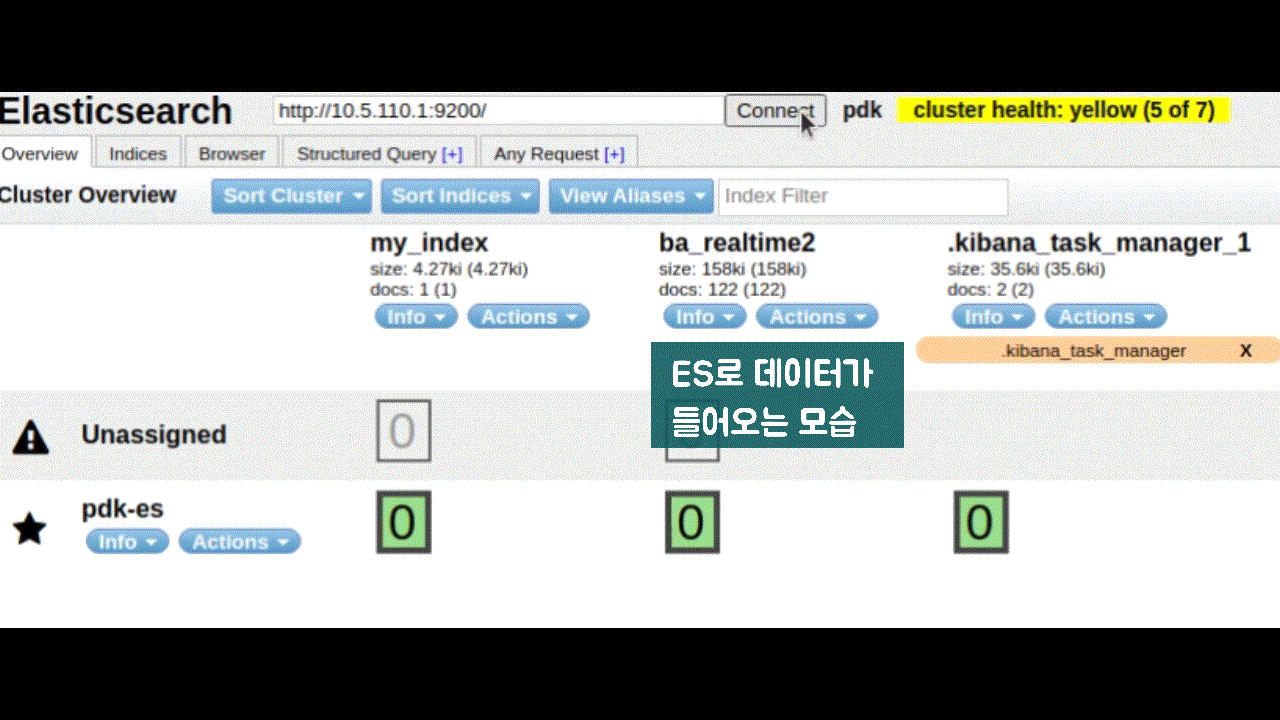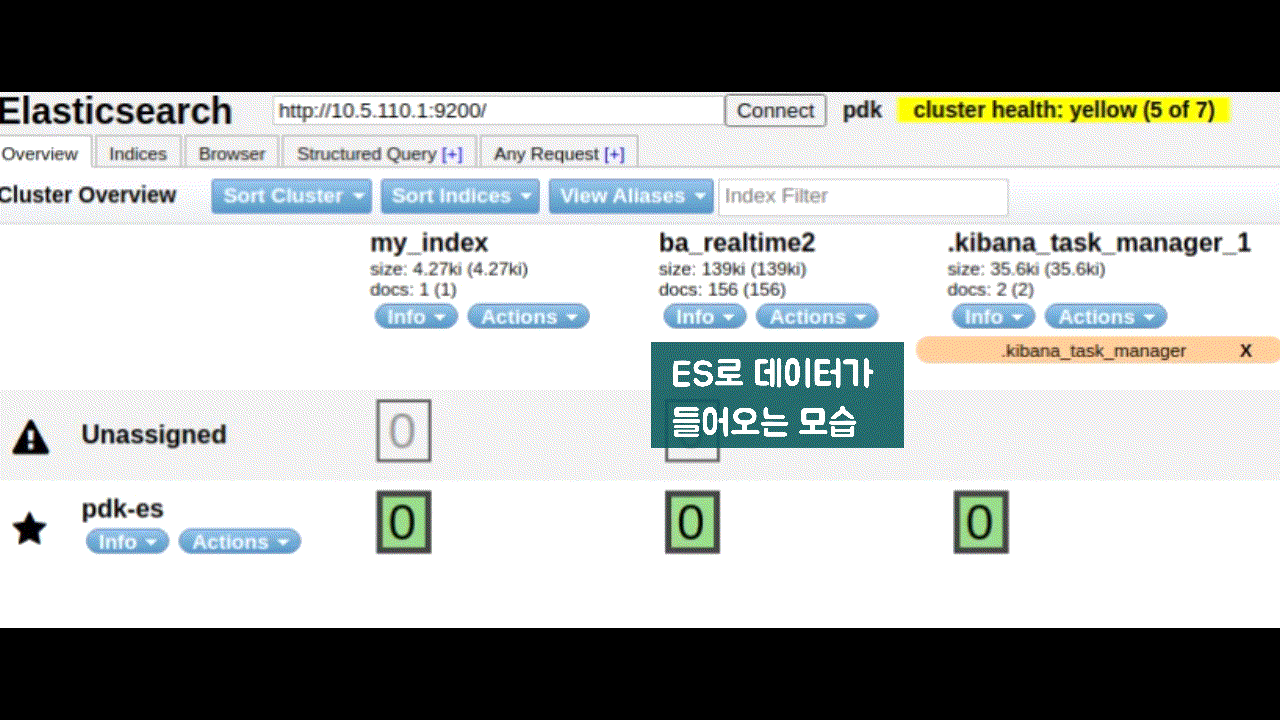
- logstash에서 kafka로 저장하고, 이를 spark에서 실시간 분산처리 후 ES에 저장
- logstash ➡ kafka ➡ spark streaming ➡ ES
redis⤴
- 특징
- logstash의 biz logic(filter)을 단순화하여 최대한 많은 양을 전송하는 용도로 활용한다.
- kafka를 이용하여 대량의 데이터를 빠르고, 안전하게 저장 및 전달하는 Message queue로 활용한다.
- Spark streaming은 kafka에서 받아온 데이터를 실시간 분산처리하여 대상 DB(ES)에 병렬로 저장한다.
- redis는 spark streaming에서 customer/music id를 빠르게 join하기 위한 memory cache역할을 한다.
- Software 구성도
- create kafka topic(realtime)
- logstash에서 수집한 log 메세지를 kafka로 보낼 때, realtime topic을 지정한다.
$ cd ~/study-spark-streaming-redis/sw/kafka_2.12-2.6.0 $ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic realtime # check created topic "realtime" # replication-factor : 메세지를 복제할 개수 (1은 원본만 유지) # partitions : 메세지를 몇개로 분산하여 저장할 것인지 결정 (갯수 만큼 병렬로 write/read 함) $ bin/kafka-topics.sh --list --zookeeper localhost:2181 realtime
- import customer info to redis
- run import_customer_info.py (read customer info and insert into redis)
$ cd ~/study-spark-streaming-redis/data $ python import_customer_info.py- redis에 정상적으로 저장되었는지 확인
$ ~/study-spark-streaming-redis/sw/redis-3.0.7/src/redis-cli 127.0.0.1:6379> keys * # 사용자 id별로 key 생성 1) "4042" 2) "4763" ... ... 4998) "1434" 4999) "782" 127.0.0.1:6379> hgetall 2 #사용자 id 2번에 대한 정보를 조회 1) "name" 2) "Paula Peltier" 3) "gender" 4) "0" 5) "age" 6) "28" 7) "zip" 8) "66216" 9) "Address" 10) "10084 Easy Gate Bend" 11) "SignDate" 12) "01/13/2013" 13) "Status" 14) "1" 15) "Level" 16) "0" 17) "Campaign" 18) "4" 19) "LinkedWithApps" 20) "1"
- Read logs and send to kafka
- logstash configuration
- input : tracks_live.csv ( data_generator로 생성하는 file )
- filter : 적용하지 않음 ( logstash는 빠르게 수집, 실제 데이터에 대한 처리(filter, aggregation...)는 spark streaming에서 처리 )
- output : logs에서 읽은 문자열을 그대로 kafka로 produce
$ cd ~/study-spark-streaming-redis/data $ vi logstash_streaming.conf input { file { path => "/home/user_name/study-spark-streaming-redis/data/tracks_live.csv" sincedb_path => "/dev/null" start_position => "beginning" } } output { stdout { codec => rubydebug{ } } kafka { codec => plain { format => "%{message}" } bootstrap_servers => "localhost:9092" topic_id => "realtime" } }- run logstash
$ cd ~/study-spark-streaming-redis/data $ ~/study-spark-streaming-redis/sw/logstash-7.6.1/bin/logstash -f logstash_streaming.conf - logstash configuration
- create spark application project using maven
- create scala/java project using maven
- spark application은 scala와 java를 모두 사용하므로 maven project 구성 시에 .java, .scala파일을 모두 인식할 수 있도록 설정해야 한다.
- freepsw/java_scala 프로젝트를 참고.
- pom.xml에 dependency 추가
- pom.xml(프로젝트에서 사용하는 library) 설정
- 여기에서 지정한 library는 mavend에서 자동으로 download하여 compile, run time에 참조한다.
-
- spark streaming driver 코드 작성
- SparkContex에 필요한 configuration을 설정
- StreamingContext를 생성
- Create Kafka Receiver and receive message from kafka broker
- kafka에서 데이터를 받기위한 Kafka receiver를 생성한다.
- 만약 kafka partition이 여러개 일 경우, numReceiver를 partition 갯수만큼 지정
- kafka receiver가 많아지면 데이터를 병렬로 읽어오게 된다.
- union을 활용하여 1개의 rdd로 join한다. (논리적으로 1개로 묶였을 뿐, 내부적으로는 여러개의 partition으로 구성됨)
- parser message and join customer info from redis
- kafkad에서 받아온 메세지 중에서 customer_id를 추출
- customer_id를 key로 redis에서 사용자 상세 정보를 조회 (import_customer_info.py에서 저장한 고객정보)
- kibana에서 사용할 timestamp field는 현재 시간으로 설정
- Write to ElasticSearch
- 본인의 경우 ElasticSearch를 다른 PC에서 실행시켰으므로 해당 PC의 IP를 입력하였음.
- kafka data + redis 고객정보를 합쳐서 elasticsearch에 저장
- create scala/java project using maven
- compile spark application and run spark streaming
- compile with maven command line
cd ~/study-spark-streaming-redis/demo-streaming $ sudo apt-get install -y maven $ mvn compile $ mvn package $ ls target # 필요한 library를 모두 합친 jar 파일이 생성되었다. demo-streaming-1.0-SNAPSHOT-jar-with-dependencies.jar # ..-jar-with-dependencies.jar은 application에 필요한 모든 library가 포함된 파일 # spark은 분산 환경에서 구동하기 때문에, 해당 library가 모든 서버에 존재해야만 정상적으로 실행, # 이러한 문제를 해결하기 위해서 jar파일 내부에 필요한 모든 library를 포함하도록 실행파일 생성.- spark-submit을 통해 spark application을 실행시킨다.
$ cd ~/study-spark-streaming-redis/data $ ./run_spark_streaming_s2.sh- 상세 설정
- class : jar파일 내부에서 실제 구동할 class명
- master : spark master의 ip:port(default 7077)
- deploy-mode : spark는 driver와 executor로 구분되어 동작하게 됨. 여기서 driver의 구동 위치를 결정
- client : 현재 spark-submit을 실행한 서버에 driver가 구동됨.
- cluster : spark master가 cluster node 중에서 1개의 node를 지정해서, 해당 node에서 driver 구동
- driver-memory : driver 프로세스에 할당되는 메모리
- executor-memory : executor 1개당 할당되는 메모리
- total-executor-cores : Total cores for all executors.
- executor-cores : Number of cores per executor
$ cd ~/study-spark-streaming-redis/data
$ python data_generator.py
- ES의 데이터를 이용해 kibana에 visualize
- elk stack 공부 당시 해봤으므로 생략.