- This project is basically for collecting enormous data and analysing it.
- It includes live streaming of data from FOREX trading API and Electric Vehicle stocks API.
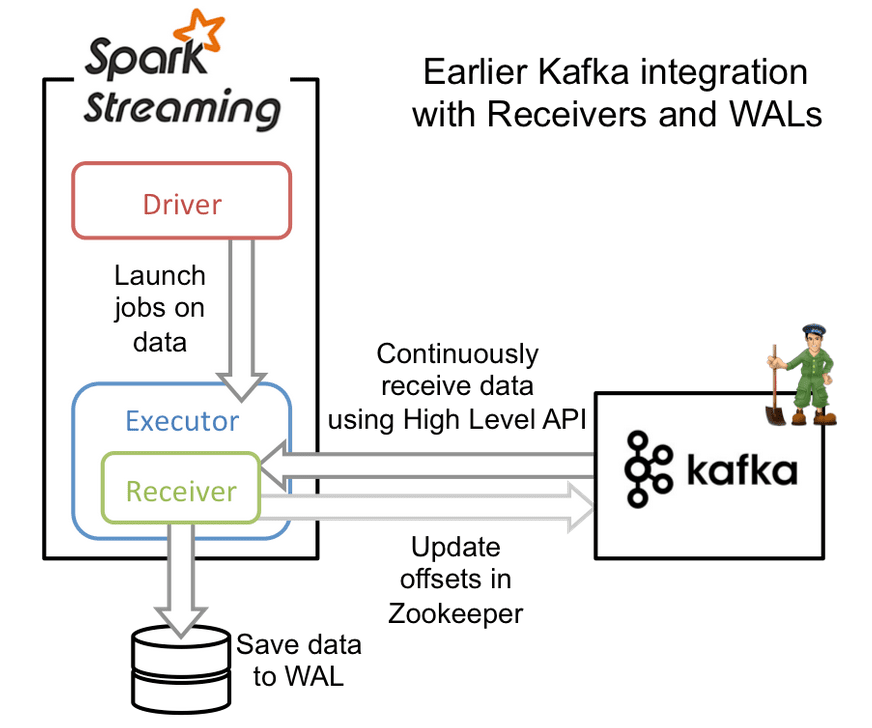
- The data is fetched and processed using Kafka Streaming and Spark streaming.
- Throughout this project stocks of Forex data and Electric Vehicle parts making companies data were analyzed and business use case is implemented.
- The analyzed data is then visualized by plotting different graphs using python libraries.
- Websocket,
- Requests library,
- Pandas datareader library,
- Netcat,
- API : Tiingo API,Alpha Vantage API.
- data visualization tool: matplotlib,Seaborn
- Spark
- Kafka
- Pyspark
GitHub clone URL: https://github.com/rajib1007/Project_3.git
INSTALL REQUIRED TOOLS TO PROCEED WORK & SET PATH
sudo apt-get install openjdk-8-jdk
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
tar xvzf spark-3.1.2-bin-hadoop3.2.tgz
wget https://archive.apache.org/dist/kafka/2.0.0/kafka_2.11-2.0.0.tgz
tar xvzf kafka_2.11-2.0.0.tgz
FOLLOW THIS LINK INSTALL JUPYTER NOTEBOOK ON UBUNTU
GOTO KAFKA DIRECTORY AND RUN ZOOKEEPER AND KAFKA SERVER
cd kafka_2.11-2.0.0/
bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-server-start.sh config/server.properties
CREATE A TOPIC project3 WITH REPLICATION FACTOR 1 AND PARTITION 1
bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic --replication-factor 1 --partitions 1
CREATE A producer.py FILE TO FETCH DATA FROM API AND PASS TO TOPIC
- CREATE ACCOUNT ON api.tiingo.com
- run producer.py file
START CONSUMER API IN NEW TERMINAL
bin/kafka-console-consumer.sh --topic <topic_name> --bootstrap-server localhost:9092
CREATE ANOTHER .py FILE TO STRUCTURE THE JSON DATA INTO SPARK DATAFRAME AND DO SOME OPERATION OR A USECASE
- CREATE TOPIC askPriceOutput
bin/kafka-console-consumer.sh –topic <output_topic_file> --bootstrap-server localhost:9092
- usecase2.py
- GOTO SPARK BIN FOLDER
cd /spark-3.1.2-bin-hadoop3.2/bin/
- RUN SPARK-SUBMIT JOB WITH usecase.py FILE AND STORE THE OUTPUT ON askPriceOutput TOPIC
spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.2 <file_path.py>
OUTPUT WILL BE SHOWING ON askPriceOutput TOPIC’S CONSUMER
OPEN JUPYTER NOTEBOOK AND INSTALL matplotlib library and kafka-python ON IT
- DATA STREAMING AND SPARK submit job- Rajib’s team
- Use cases- Eshwar’s team
- Visualization- Karan’s team
- EV stock use case-Kareem's team
- Deployment-Trupti’s Team