Podsumowanie i analiza tego opisu projektu Grid_bot_Merito:
Podsumowanie projektu:
Nazwa: Grid_bot_Merito Typ: Open-source chatbot Architektura: Retrieval-Augmented Generation (RAG) Zastosowanie: Analiza danych z inteligentnych sieci pomiarowych (smart grids) Cel: Ułatwienie dostępu do informacji, wsparcie analizy, usprawnienie decyzji w sektorze energetycznym. Technologie:
- Vite
- TypeScript
- React
- shadcn-ui
- Tailwind CS-Gemini
- Gemini API
Licencja: MIT License Szczegóły i analiza:
RAG (Retrieval-Augmented Generation): To ważny aspekt projektu. RAG łączy model generatywny (np. duży model językowy) z systemem wyszukiwania informacji. Oznacza to, że chatbot nie tylko odpowiada na pytania na podstawie swojej wiedzy, ale także przeszukuje bazę danych (np. dokumenty, pliki CSV z danymi pomiarowymi) i wykorzystuje te informacje do generowania odpowiedzi. To sprawia, że odpowiedzi są bardziej precyzyjne i oparte na aktualnych danych. Smart Grids: Projekt jest ściśle ukierunkowany na dane z inteligentnych sieci pomiarowych. To sugeruje, że chatbot będzie w stanie odpowiadać na pytania dotyczące zużycia energii, statusu urządzeń, potencjalnych awarii, trendów i innych aspektów związanych z tym sektorem. Open-source: Otwartość kodu źródłowego zachęca do współpracy, rozwoju i transparentności. Pozwala także na adaptację i wykorzystanie projektu w różnych środowiskach. Jupyter Notebook: Dominacja Jupyter Notebook w repozytorium sugeruje, że projekt jest w dużej mierze nastawiony na eksperymentowanie, eksplorację danych, tworzenie prototypów i udostępnianie interaktywnych analiz. Python: Potwierdza popularność języka Python w analizie danych i uczeniu maszynowym. To dobry wybór dla projektu opartego na RAG. Instalacja: Jasne instrukcje dotyczące instalacji (klonowanie, zmiana katalogu, instalacja zależności) są istotne dla potencjalnych użytkowników i kontrybutorów. Użycie: Wskazanie na dokumentację projektu jest pozytywnym aspektem. Dokumentacja jest kluczowa dla zrozumienia działania i wykorzystania chatbota. Wkład: Zaproszenie do współpracy i zgłaszania błędów zachęca społeczność do aktywnego udziału w rozwoju projektu. Licencja MIT: Zapewnia elastyczność w wykorzystaniu, modyfikacji i dystrybucji projektu. Potencjalne zastosowania chatbota:
Wsparcie techniczne: Pomoc inżynierom i pracownikom sieci w rozwiązywaniu problemów. Analiza danych: Ułatwienie analizy danych pomiarowych, identyfikacja trendów i anomalii. Planowanie i prognozowanie: Pomoc w prognozowaniu zapotrzebowania na energię i planowaniu przyszłych inwestycji. Obsługa klienta: Udzielanie odpowiedzi na typowe pytania od użytkowników końcowych. Szkolenia: Ułatwienie nauki na temat inteligentnych sieci. Podsumowanie:
Grid_bot_Merito to obiecujący projekt, który może mieć duże znaczenie dla sektora energetycznego. Wykorzystanie RAG, ukierunkowanie na dane z inteligentnych sieci, otwartość i jasne instrukcje instalacji to mocne strony tego projektu. Kluczowe jest rozwinięcie dokumentacji, dodanie interfejsu użytkownika i rozwijanie funkcjonalności chatbota.
Poczatek projektu:
https://smart-grid-gems-22.lovable.app/
codzienne aktualizacje:
(https://smart-grid-gems-95.lovable.app/)
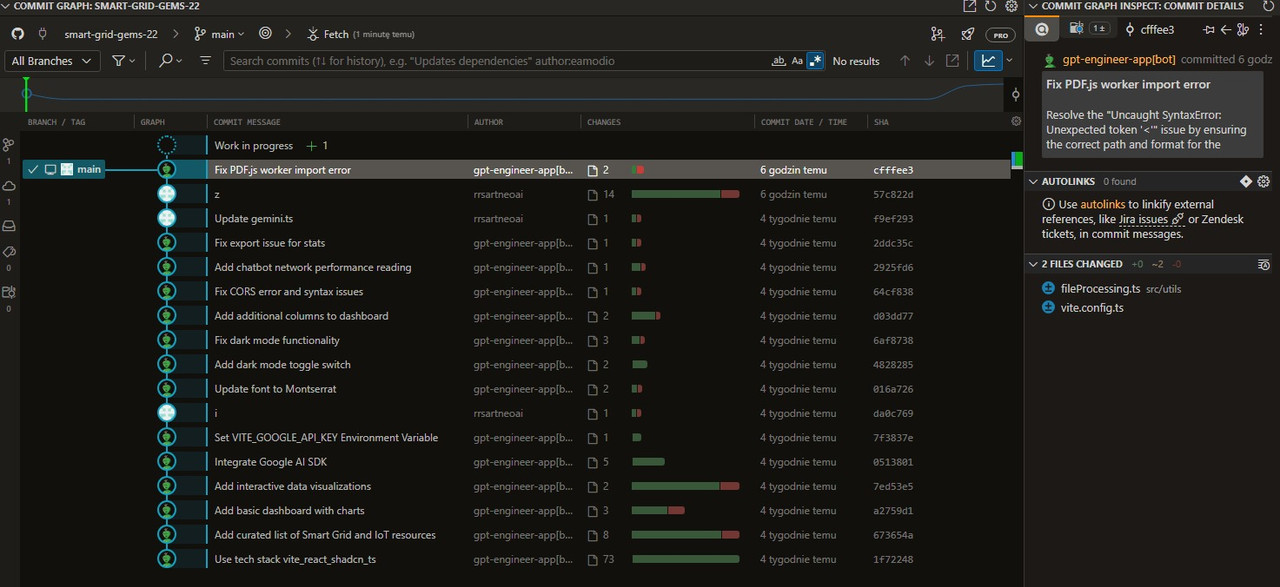
Ten obrazek przedstawia zrzut ekranu z narzędzia do przeglądania commitów Git, prawdopodobnie z Visual Studio Code, prezentujący historię commitów w gałęzi main projektu smart-grid-gems-22.
-
Nawigacja:
- Pasek na górze zawiera nazwę repozytorium (
smart-grid-gems-22) oraz aktualną gałąź (main). - Przyciski do nawigacji po repozytorium oraz możliwość wyszukiwania commitów.
- Przycisk odświeżania (
Fetch).
- Pasek na górze zawiera nazwę repozytorium (
-
Lista Commitów:
- Kolumna
BRANCH / TAGpokazuje nazwę gałęzi (main) i aktualny commit. - Kolumna
GRAPHprezentuje wizualizację gałęzi. - Kolumna
COMMIT MESSAGEzawiera opis każdego commita. - Kolumna
AUTHORpokazuje autora commitu. - Kolumna
CHANGESprezentuje liczbę dodanych i usuniętych linii kodu (zielony dla dodanych, czerwony dla usuniętych). - Kolumna
COMMIT DATE / TIMEpokazuje datę i godzinę commitu. - Kolumna
SHAprezentuje hash commitu. - Commit "Fix PDF.js worker import error" jest aktualnie zaznaczony.
- Kolumna
-
Prawy Panel - Szczegóły Commita:
- Górny pasek wskazuje szczegóły commitu wraz z autorem i nazwą.
- Wyświetla szczegółowy opis commita ("Resolve the 'Uncaught SyntaxError: Unexpected token '<'' issue by ensuring the correct path and format for the").
- Sekcja
AUTOLINKS(0 found). - Sekcja
2 FILES CHANGEDwyświetla pliki, które zostały zmodyfikowane w tym commicie (fileProcessing.ts src/utilsorazvite.config.ts).
Poniżej znajdują się przykładowe commity wraz z ich opisami:
- Fix PDF.js worker import error: Rozwiązanie problemu z importem workera PDF.js.
- z: (Niejasne, prawdopodobnie commit testowy lub roboczy).
- Update gemini.ts: Aktualizacja kodu związanego z Gemini.
- Fix export issue for stats: Rozwiązanie problemu z eksportowaniem statystyk.
- Add chatbot network performance reading: Dodanie odczytu wydajności sieci chatbota.
- Fix CORS error and syntax issues: Rozwiązanie problemu CORS i błędów składni.
- Add additional columns to dashboard: Dodanie dodatkowych kolumn do dashboardu.
- Fix dark mode functionality: Rozwiązanie problemu z trybem ciemnym.
- Add dark mode toggle switch: Dodanie przełącznika trybu ciemnego.
- Update font to Montserrat: Zmiana czcionki na Montserrat.
- Set VITE_GOOGLE_API_KEY Environment Variable: Ustawienie zmiennej środowiskowej API Google.
- Integrate Google AI SDK: Integracja SDK Google AI.
- Add interactive data visualizations: Dodanie interaktywnych wizualizacji danych.
- Add basic dashboard with charts: Dodanie podstawowego dashboardu z wykresami.
- Add curated list of Smart Grid and IoT resources: Dodanie listy zasobów Smart Grid i IoT.
- Use tech stack vite_react_shadcn_ts: Wykorzystanie stosu technologii vite, react, shadcn i typescript.
Ten zrzut ekranu jest przydatny do dokumentowania historii zmian w kodzie, prezentowania postępów w rozwoju projektu, a także do analizowania zmian wprowadzonych przez poszczególnych programistów.
- Kolory wskazują na ilość zmian w plikach (zielony - dodane, czerwony - usunięte).
- W prawym górnym rogu widoczne jest nazwa użytkownika oraz ilość zatwierdzonych commitów.
Jak korzystać z tego opisu?
- Zapisz plik jako
README.mdw katalogu z grafiką. - Zamień nazwę obrazka w linku na rzeczywistą nazwę Twojej grafiki.
- Dodaj link do grafiki, która będzie wyświetlona pod nagłówkiem.
- Opcjonalnie możesz rozbudować opis o szczegóły dotyczące twojego konkretnego projektu.
Taki opis w formacie Markdown będzie dobrze sformatowany i czytelny na GitHubie, ułatwiając innym zrozumienie historii commitów Twojego projektu.
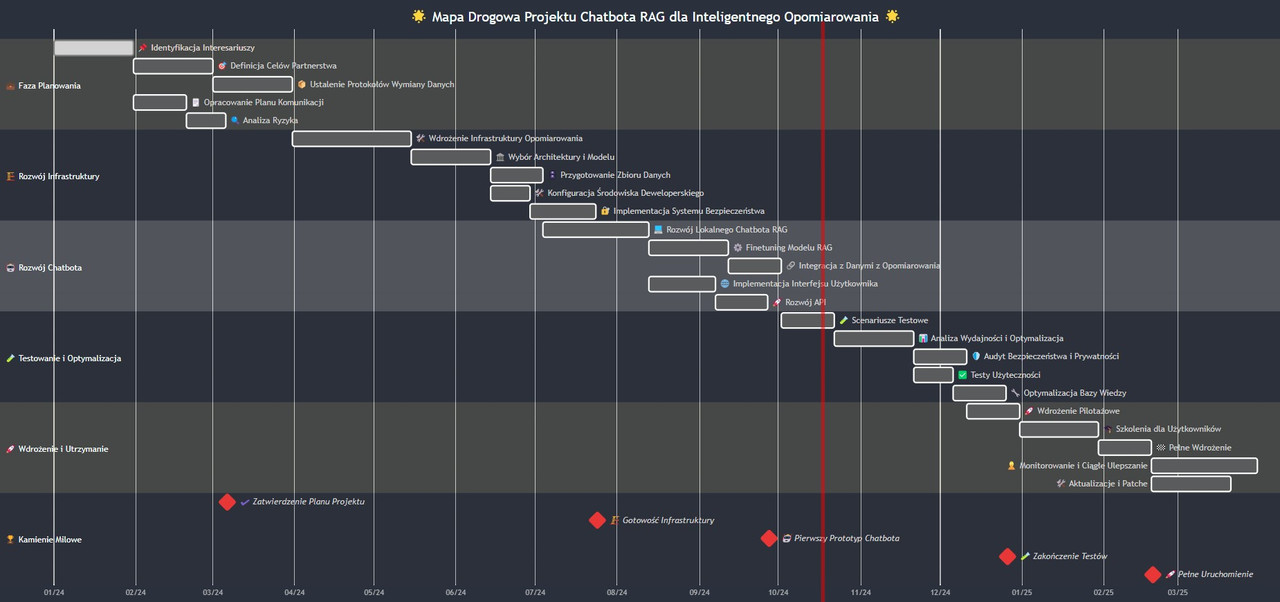
Ten diagram przedstawia harmonogram projektu (mapę drogową) rozwoju chatbota, który wykorzystuje mechanizm RAG (Retrieval-Augmented Generation) w kontekście inteligentnego opomiarowania (smart metering). Diagram przedstawia poszczególne etapy projektu oraz ich planowany czas trwania.
-
Faza Planowania (Planowanie):
- Identyfikacja Interesariuszy: Określenie wszystkich zaangażowanych stron projektu.
- Definicja Celów Partnerstwa: Ustalenie celów współpracy z partnerami.
- Ustalenie Protokołów Wymiany Danych: Określenie zasad wymiany danych.
- Opracowanie Planu Komunikacji: Stworzenie planu komunikacji w ramach projektu.
- Analiza Ryzyka: Analiza potencjalnych ryzyk związanych z projektem.
-
Rozwój Infrastruktury (Rozwój Infrastruktury):
- Wdrożenie Infrastruktury Opomiarowania: Wdrożenie niezbędnej infrastruktury pomiarowej.
- Wybór Architektury i Modelu: Wybór architektury systemu i modelu RAG.
- Przygotowanie Zbioru Danych: Zgromadzenie i przygotowanie zbioru danych do trenowania modelu.
- Konfiguracja Środowiska Deweloperskiego: Skonfigurowanie środowiska programistycznego.
- Implementacja Systemu Bezpieczeństwa: Wdrożenie zabezpieczeń systemu.
-
Rozwój Chatbota (Rozwój Chatbota):
- Rozwój Lokalnego Chatbota RAG: Rozwój lokalnej wersji chatbota.
- Finetuning Modelu RAG: Dopracowanie i optymalizacja modelu RAG.
- Integracja z Danymi z Opomiarowania: Integracja chatbota z danymi z systemu pomiarowego.
- Implementacja Interfejsu Użytkownika: Wdrożenie interfejsu użytkownika chatbota.
- Rozwój API: Rozwój interfejsu API chatbota.
-
Testowanie i Optymalizacja (Testowanie i Optymalizacja):
- Scenariusze Testowe: Opracowanie scenariuszy testowych.
- Analiza Wydajności i Optymalizacja: Analiza wydajności systemu i jego optymalizacja.
- Audyt Bezpieczeństwa i Prywatności: Przeprowadzenie audytu bezpieczeństwa i prywatności danych.
- Testy Użyteczności: Przeprowadzenie testów użyteczności systemu.
- Optymalizacja Bazy Wiedzy: Optymalizacja bazy wiedzy.
-
Wdrożenie i Utrzymanie (Wdrożenie i Utrzymanie):
- Wdrożenie Pilotażowe: Wdrożenie pilotażowe systemu.
- Szkolenia dla Użytkowników: Przeprowadzenie szkoleń dla użytkowników.
- Pełne Wdrożenie: Pełne wdrożenie systemu.
- Monitorowanie i Ciągłe Ulepszanie: Ciągłe monitorowanie i ulepszanie systemu.
- Aktualizacje i Patche: Regularne aktualizacje i wprowadzanie poprawek.
- Zatwierdzenie Planu Projektu: Oficjalne zatwierdzenie planu projektu.
- Gotowość Infrastruktury: Osiągnięcie gotowości infrastruktury systemu.
- Pierwszy Prototyp Chatbota: Ukończenie pierwszego prototypu chatbota.
- Zakończenie Testów: Zakończenie testowania systemu.
- Pełne Uruchomienie: Pełne uruchomienie systemu.
- Diagram przedstawia oś czasu z podziałem na miesiące (od 01/24 do 03/25).
- Każdy etap projektu oraz kamienie milowe są zaznaczone na osi czasu, co pozwala na wizualizację harmonogramu projektu.
Ten diagram przedstawia harmonogram rozwoju chatbota, który wykorzystuje mechanizm RAG w kontekście inteligentnego opomiarowania. Pomaga on w planowaniu i monitorowaniu postępów w projekcie.
- Diagram jest uproszczony i przedstawia kluczowe etapy projektu.
- Kolor ciemnoniebieski tła pomaga wyróżnić planowane wydarzenia na osi czasu.
- Kamienie milowe są zaznaczone czerwonymi rombami.
- Każda faza jest wyraźnie oznaczona kolorowym prostokątem.
Jak korzystać z tego opisu?
- Zapisz plik jako
README.mdw katalogu z grafiką. - Zamień nazwę obrazka w linku na rzeczywistą nazwę Twojej grafiki.
- Dodaj link do grafiki, która będzie wyświetlona pod nagłówkiem.
- Opcjonalnie możesz rozbudować opis o szczegóły dotyczące twojego konkretnego projektu.
Taki opis w formacie Markdown będzie dobrze sformatowany i czytelny na GitHubie, ułatwiając innym zrozumienie harmonogramu Twojego projektu.
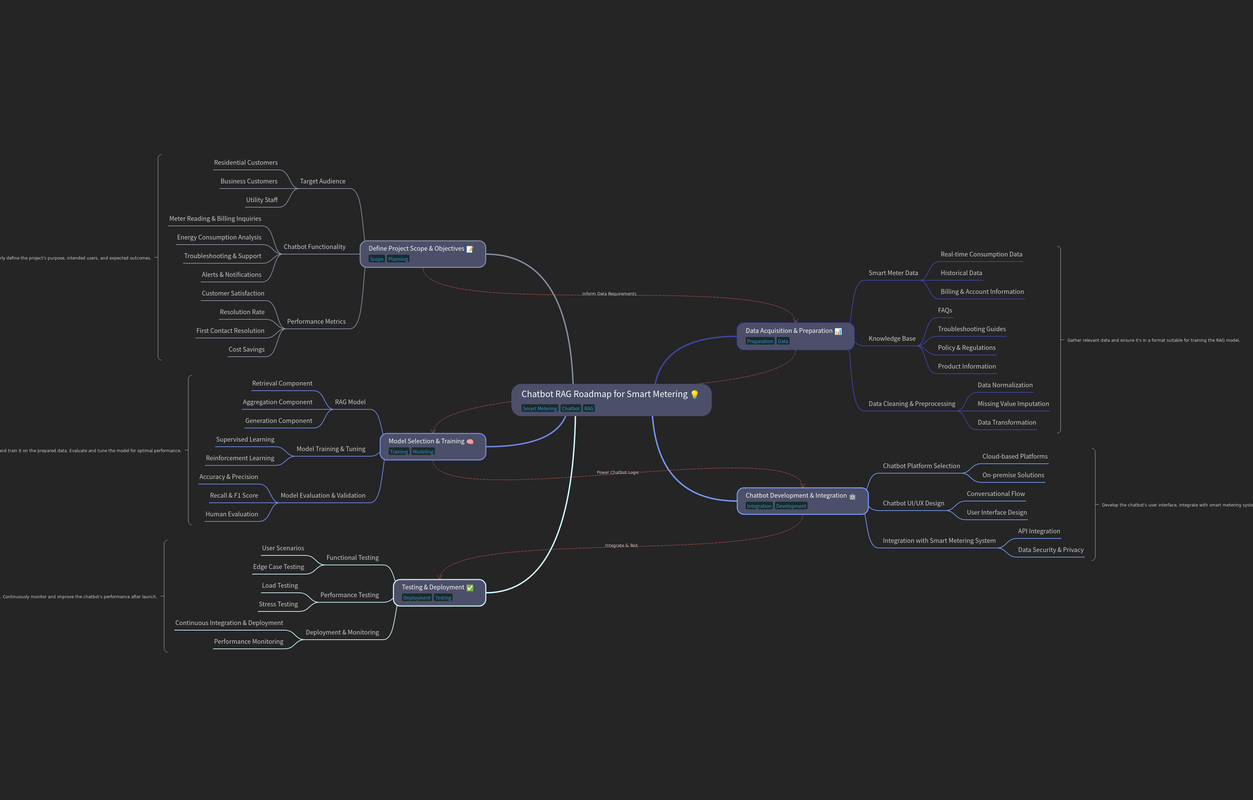
Ten diagram przedstawia mapę drogową (roadmap) rozwoju chatbota, który wykorzystuje mechanizm RAG (Retrieval-Augmented Generation) w kontekście inteligentnego opomiarowania (smart metering). Diagram obejmuje kluczowe etapy projektu, od definicji zakresu, przez szkolenie modelu, po testowanie i wdrożenie.
-
Chatbot RAG Roadmap for Smart Metering (Mapa Drogowa Chatbota RAG dla Inteligentnego Opomiarowania):
- Główny węzeł diagramu, określający tematykę projektu.
- Oznaczony tagami:
Smart Metering,Chatbot,RAG.
-
Define Project Scope & Objectives (Definiowanie Zakresu i Celów Projektu):
- Pierwszy etap projektu.
- Oznaczony tagami:
Scope,Planning. - Wskazuje na określenie zakresu projektu, w tym grup docelowych, jak np.:
- Residential Customers (Klienci indywidualni)
- Business Customers (Klienci biznesowi)
- Utility Staff (Personel zakładu energetycznego)
- Oraz funkcjonalności:
- Meter Reading & Billing Inquiries (Zapytania dotyczące odczytu i rozliczeń)
- Energy Consumption Analysis (Analiza zużycia energii)
- Troubleshooting & Support (Rozwiązywanie problemów i wsparcie)
- Alerts & Notifications (Alerty i powiadomienia)
- Customer Satisfaction (Zadowolenie klienta)
- Określenie metryk sukcesu:
- Resolution Rate (Współczynnik rozwiązania)
- First Contact Resolution (Rozwiązanie przy pierwszym kontakcie)
- Cost Savings (Oszczędności kosztów)
-
Data Acquisition & Preparation (Pozyskiwanie i Przygotowanie Danych):
- Etap przygotowania danych do treningu modelu.
- Oznaczony tagami:
Preparation,Data. - Obejmuje dane z inteligentnych liczników:
- Real-time consumption Data (Dane zużycia w czasie rzeczywistym)
- Historical Data (Dane historyczne)
- Billing & Account Information (Informacje o rozliczeniach i koncie)
- Oraz dane z bazy wiedzy:
- FAQs (Często zadawane pytania)
- Troubleshooting Guides (Przewodniki rozwiązywania problemów)
- Policy & Regulations (Polityki i regulacje)
- Product Information (Informacje o produktach)
- Oraz procesy:
- Data Normalization (Normalizacja danych)
- Missing Value Imputation (Uzupełnianie brakujących wartości)
- Data Transformation (Transformacja danych)
-
Model Selection & Training (Wybór i Szkolenie Modelu):
- Etap wyboru i szkolenia modelu RAG.
- Oznaczony tagami:
Training,Modeling. - Obejmuje elementy:
- Retrieval Component (Komponent wyszukiwania)
- Aggregation Component (Komponent agregacji)
- Generation Component (Komponent generowania)
- Metody:
- Supervised Learning (Uczenie nadzorowane)
- Reinforcement Learning (Uczenie ze wzmocnieniem)
- Metryki:
- Accuracy & Precision (Dokładność i precyzja)
- Recall & F1 Score (Współczynnik odzysku i F1)
- Human Evaluation (Ocena ludzka)
-
Chatbot Development & Integration (Rozwój i Integracja Chatbota):
- Etap rozwoju i integracji chatbota z systemem.
- Oznaczony tagami:
Integration,Development. - Obejmuje:
- Chatbot Platform Selection (Wybór platformy chatbota)
- Cloud-based Platforms (Platformy w chmurze)
- On-premise Solutions (Rozwiązania lokalne)
- Chatbot UI/UX Design (Projekt UI/UX chatbota)
- Conversational Flow (Przepływ konwersacji)
- User Interface Design (Projekt interfejsu użytkownika)
- Chatbot Platform Selection (Wybór platformy chatbota)
- Oraz integrację:
- API Integration (Integracja API)
- Integration with Smart Metering System (Integracja z systemem inteligentnego opomiarowania)
- Data Security & Privacy (Bezpieczeństwo i prywatność danych)
-
Testing & Deployment (Testowanie i Wdrożenie):
- Etap testowania i wdrożenia systemu.
- Oznaczony tagami:
Deployment,Testing. - Obejmuje:
- Functional Testing (Testy funkcjonalne)
- User Scenarios (Scenariusze użytkownika)
- Edge Case Testing (Testowanie przypadków brzegowych)
- Performance Testing (Testy wydajności)
- Load Testing (Testowanie obciążenia)
- Stress Testing (Testowanie obciążenia)
- Functional Testing (Testy funkcjonalne)
- Oraz:
- Continuous Integration & Deployment (Ciągła integracja i wdrożenie)
- Performance Monitoring (Monitorowanie wydajności)
- Strzałki wskazują na przepływ informacji i zależności między poszczególnymi etapami projektu.
Ten diagram przedstawia plan rozwoju chatbota w kontekście inteligentnego opomiarowania. Obejmuje on wszystkie kluczowe aspekty, od definicji celów, przez przygotowanie danych, szkolenie modelu, po testowanie i wdrożenie.
- Diagram jest uproszczony i przedstawia kluczowe etapy projektu.
- Poszczególne etapy można rozbudować o dodatkowe szczegóły w zależności od potrzeb.
- Linie przerywane oznaczają zależności, takie jak informowanie o wymaganiach dotyczących danych.
Jak korzystać z tego opisu?
- Zapisz plik jako
README.mdw katalogu z grafiką. - Zamień nazwę obrazka w linku na rzeczywistą nazwę Twojej grafiki.
- Dodaj link do grafiki, która będzie wyświetlona pod nagłówkiem.
- Opcjonalnie możesz rozbudować opis o szczegóły dotyczące twojego konkretnego projektu.
Taki opis w formacie Markdown będzie dobrze sformatowany i czytelny na GitHubie, ułatwiając innym zrozumienie mapy drogowej Twojego projektu.
Wzorcowy model architektury RAG
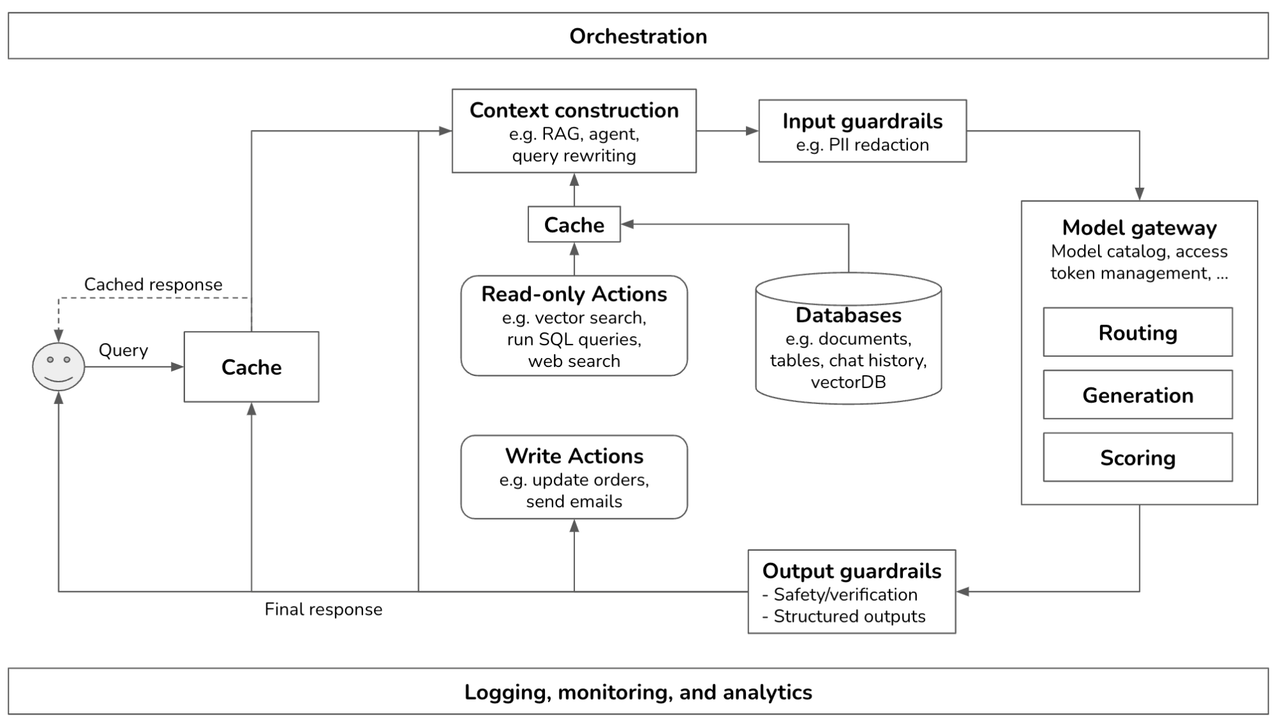
Ten diagram przedstawia architekturę systemu konwersacyjnego wykorzystującego duże modele językowe (LLM), z uwzględnieniem kluczowych komponentów i przepływu danych.
-
Orchestration (Orkiestracja):
- Górny poziom kontroli przepływu i koordynacji działań całego systemu.
-
Cache (Pamięć podręczna):
- Przechowuje wcześniej uzyskane odpowiedzi, aby przyspieszyć przetwarzanie powtarzających się zapytań.
- Zapytanie (
Query) najpierw trafia do pamięci podręcznej. Jeśli odpowiedź jest dostępna wCache, zwracana jest jakoCached response.
-
Context construction (Konstrukcja kontekstu):
- Odpowiada za budowanie kontekstu dla modelu LLM, na podstawie danych wejściowych.
- Wykorzystuje techniki takie jak RAG (Retrieval-Augmented Generation), agentów, czy przepisywanie zapytań.
-
Input guardrails (Strażnicy danych wejściowych):
- Zapewniają bezpieczeństwo i prywatność danych wejściowych, np. poprzez redakcję danych osobowych (PII).
-
Read-only Actions (Akcje tylko do odczytu):
- Wykonują operacje odczytu danych z różnych źródeł.
- Przykłady: wyszukiwanie wektorowe, uruchamianie zapytań SQL, przeszukiwanie internetu.
-
Databases (Bazy danych):
- Źródła danych dla systemu.
- Przykłady: dokumenty, tabele, historia czatów, bazy wektorowe.
-
Write Actions (Akcje zapisu):
- Wykonują operacje zapisu danych, np. aktualizację zamówień, wysyłanie e-maili.
-
Model gateway (Brama modeli):
- Zarządza dostępem do modeli językowych, katalogiem modeli i tokenami dostępu.
- Zawiera funkcje takie jak:
- Routing: Wybór odpowiedniego modelu do danego zadania.
- Generation: Generowanie odpowiedzi przez model.
- Scoring: Ocena jakości wygenerowanej odpowiedzi.
-
Output guardrails (Strażnicy danych wyjściowych):
- Zapewniają bezpieczeństwo, weryfikację i strukturalizację danych wyjściowych.
-
Logging, monitoring, and analytics (Logowanie, monitorowanie i analiza):
- Zapewnia rejestrowanie zdarzeń, monitorowanie systemu i analizę danych.
- Zapytanie (
Query) od użytkownika trafia doCache. - Jeśli w
Cacheznajduje się odpowiedź, jest ona zwracana jakoCached response. - W przeciwnym wypadku, zapytanie przechodzi do
Context construction, gdzie budowany jest kontekst. - Dane wejściowe są weryfikowane przez
Input guardrails. - W zależności od potrzeb, system wykonuje
Read-only ActionslubWrite Actions. - Kontekst trafia do
Model gateway, gdzie generowana jest odpowiedź. - Odpowiedź jest weryfikowana przez
Output guardrails. - Wynik końcowy (
Final response) wraca do użytkownika i jest zapisywany wCache. - Wszystkie operacje są logowane, monitorowane i analizowane.
Ten diagram przedstawia ogólną architekturę systemu, który może być wykorzystany do budowy chatbotów, asystentów wirtualnych i innych aplikacji opartych na LLM.
- Strzałki przedstawiają kierunek przepływu danych.
- Poszczególne komponenty mogą być rozwijane i modyfikowane w zależności od wymagań.
- Diagram jest uproszczony i pomija niektóre aspekty implementacyjne.
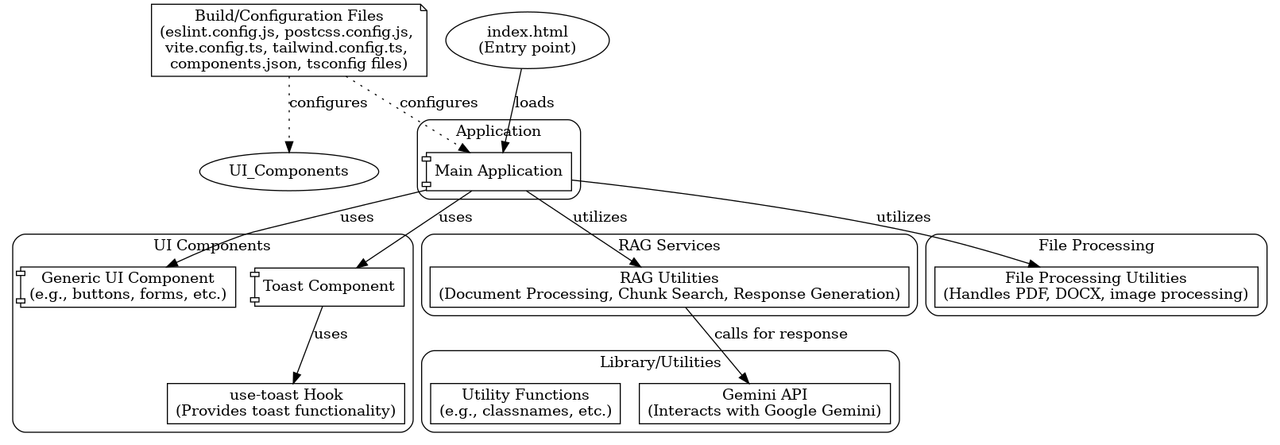
Ten diagram przedstawia architekturę aplikacji webowej, która integruje mechanizm RAG (Retrieval-Augmented Generation) i funkcje przetwarzania plików.
-
Build/Configuration Files (Pliki konfiguracyjne):
- Zawiera pliki konfiguracyjne dla projektu (np.
.eslint.config.js,postcss.config.js,vite.config.ts,tailwind.config.ts,components.json,tsconfig files). - Konfigurują działanie
UI_ComponentsiApplication.
- Zawiera pliki konfiguracyjne dla projektu (np.
-
index.html (Punkt wejścia):
- Plik HTML będący punktem wejścia do aplikacji.
- Ładuje
Application.
-
Application:
- Główna sekcja aplikacji, zawierająca element
Main Application.
- Główna sekcja aplikacji, zawierająca element
-
Main Application:
- Główny komponent aplikacji, który koordynuje i wykorzystuje inne komponenty.
-
UI Components (Komponenty interfejsu użytkownika):
- Zbiór komponentów interfejsu użytkownika, który jest skonfigurowany przez
Build/Configuration Filesoraz używany przezMain Application.- Generic UI Component (Ogólne komponenty UI):
- Podstawowe elementy interfejsu użytkownika (np. przyciski, formularze).
- Toast Component (Komponent powiadomień):
- Komponent do wyświetlania powiadomień, który
useshookuse-toast Hook.
- Komponent do wyświetlania powiadomień, który
- Generic UI Component (Ogólne komponenty UI):
- Zbiór komponentów interfejsu użytkownika, który jest skonfigurowany przez
-
RAG Services (Usługi RAG):
- Obsługuje funkcje związane z RAG.
- RAG Utilities (Narzędzia RAG):
- Zawiera funkcje przetwarzania dokumentów, wyszukiwania fragmentów, generowania odpowiedzi.
- Wykorzystuje elementy z
Library/Utilities.
- RAG Utilities (Narzędzia RAG):
- Obsługuje funkcje związane z RAG.
-
File Processing (Przetwarzanie plików):
- Odpowiada za przetwarzanie plików różnego typu.
- File Processing Utilities (Narzędzia przetwarzania plików):
- Obsługuje pliki PDF, DOCX i przetwarzanie obrazów.
- Jest wykorzystywane przez
Main Application.
- File Processing Utilities (Narzędzia przetwarzania plików):
- Odpowiada za przetwarzanie plików różnego typu.
-
Library/Utilities (Biblioteka/Narzędzia):
- Zbiór ogólnych funkcji użytkowych.
- Utility Functions (Funkcje narzędziowe):
- Zawiera funkcje pomocnicze (np. generowanie nazw klas).
- Gemini API:
- Interfejs do interakcji z modelem Google Gemini.
- Utility Functions (Funkcje narzędziowe):
- Zbiór ogólnych funkcji użytkowych.
-
use-toast Hook (Hook powiadomień): * Hook, który zapewnia funkcjonalność wyświetlania powiadomień.
- Pliki
Build/Configuration FileskonfigurująUI ComponentsiApplication. - Plik
index.htmlładujeApplication. Main ApplicationużywaUI Components,RAG Services, iFile Processing.Toast Componentużywause-toast Hookdo obsługi wyświetlania powiadomień.RAG UtilitieszRAG Serviceswywołuje funkcje zLibrary/Utilities, w tymGemini API.Main Applicationkorzysta zFile Processing Utilitiesdo przetwarzania plików.
Ten diagram przedstawia architekturę aplikacji, która wykorzystuje podejście RAG i umożliwia przetwarzanie różnego rodzaju plików. Jest to typowe dla aplikacji, które potrzebują zaawansowanych funkcji analizy tekstu i interakcji z modelami językowymi, oraz operacji na danych z plików.
- Strzałki z pełną linią oznaczają relacje użycia (uses) lub wykorzystania (utilizes).
- Strzałki przerywane oznaczają relacje konfiguracji (configures).
- Poszczególne komponenty można dostosowywać w zależności od konkretnych potrzeb projektu.
Jak korzystać z tego opisu?
- Zapisz plik jako
README.mdw katalogu z grafiką. - Zamień nazwę obrazka w linku na rzeczywistą nazwę Twojej grafiki.
- Dodaj link do grafiki, która będzie wyświetlona pod nagłówkiem.
- Opcjonalnie możesz rozbudować opis o szczegóły dotyczące twojego konkretnego projektu.
Taki opis w formacie Markdown będzie dobrze sformatowany i czytelny na GitHubie, ułatwiając innym zrozumienie architektury Twojej aplikacji.
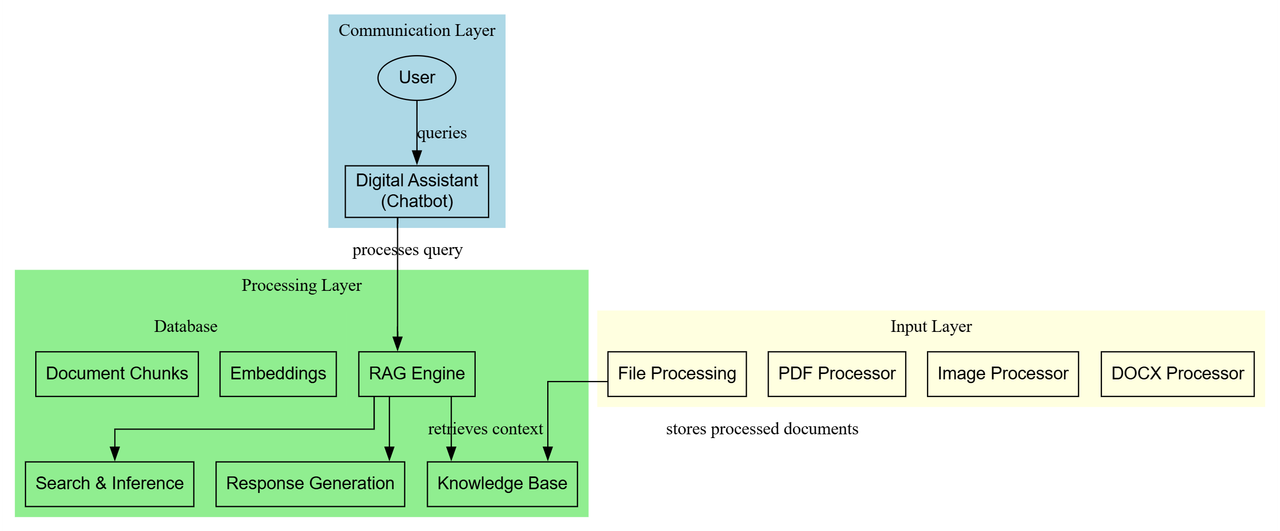
Ten diagram przedstawia architekturę systemu chatbota, który wykorzystuje technikę RAG (Retrieval-Augmented Generation) i potrafi przetwarzać różne typy plików. System jest podzielony na trzy główne warstwy: komunikacyjną, przetwarzania i wejścia.
-
Communication Layer (Warstwa komunikacji) (kolor niebieski):
- User (Użytkownik): Reprezentuje użytkownika wchodzącego w interakcję z systemem.
- Digital Assistant (Chatbot) (Asystent cyfrowy (chatbot)): Komponent, który przyjmuje zapytania użytkownika (
queries) i przetwarza je.
-
Processing Layer (Warstwa przetwarzania) (kolor zielony):
- Database (Baza danych):
- Document Chunks (Fragmenty dokumentów): Przechowuje podzielone dokumenty.
- Embeddings (Osadzenia): Przechowuje wektorowe reprezentacje fragmentów dokumentów.
- RAG Engine (Silnik RAG): Główny komponent przetwarzający zapytania.
- Search & Inference (Wyszukiwanie i wnioskowanie): Wykorzystuje
Document ChunksiEmbeddingsdo przeszukiwania kontekstu. - Response Generation (Generowanie odpowiedzi): Generuje odpowiedź na podstawie wyszukanego kontekstu.
- Knowledge Base (Baza wiedzy): Przechowuje wiedzę kontekstową potrzebną do generowania odpowiedzi, która jest pobierana przez
RAG Engine(retrieves context).
- Database (Baza danych):
-
Input Layer (Warstwa wejścia) (kolor żółty):
- File Processing (Przetwarzanie plików): Ogólny blok do przetwarzania plików.
- PDF Processor (Procesor PDF): Komponent do przetwarzania plików PDF.
- Image Processor (Procesor obrazów): Komponent do przetwarzania obrazów.
- DOCX Processor (Procesor DOCX): Komponent do przetwarzania plików DOCX.
- Blok ten
stores processed documents, co sugeruje, że przetworzone dane są magazynowane w celu późniejszego wykorzystania przez system.
- Blok ten
- Użytkownik (
User) wysyła zapytanie (queries) doDigital Assistant (Chatbot). Digital Assistantprzekazuje zapytanie doRAG Engine.RAG Enginekorzysta zSearch & Inference, aby wyszukać odpowiedni kontekst wDatabase(Document Chunks,Embeddings).RAG Enginepobiera odpowiedni kontekst zKnowledge Base.RAG Engineprzekazuje dane doResponse Generation.Response Generationtworzy odpowiedź, która jest zwracana do użytkownika.- W warstwie wejściowej,
File Processing,PDF Processor,Image ProcessoriDOCX Processorzajmują się przetwarzaniem plików i przechowywaniem ich do wykorzystania przez system.
Ten diagram przedstawia architekturę systemu chatbota opartego na RAG, który integruje funkcje przetwarzania różnych typów plików. Jest to typowe dla aplikacji, które potrzebują zaawansowanych funkcji analizy dokumentów i interakcji z użytkownikiem.
- Kolor niebieski reprezentuje warstwę komunikacji, zielony przetwarzania, a żółty warstwę wejściową.
- Strzałki pokazują przepływ danych między komponentami.
- Poszczególne komponenty mogą być modyfikowane i rozwijane w zależności od konkretnych potrzeb projektu.
Jak korzystać z tego opisu?
- Zapisz plik jako
README.mdw katalogu z grafiką. - Zamień nazwę obrazka w linku na rzeczywistą nazwę Twojej grafiki.
- Dodaj link do grafiki, która będzie wyświetlona pod nagłówkiem.
- Opcjonalnie możesz rozbudować opis o szczegóły dotyczące twojego konkretnego projektu.
Taki opis w formacie Markdown będzie dobrze sformatowany i czytelny na GitHubie, ułatwiając innym zrozumienie architektury Twojego systemu.
Ten dokument opisuje architekturę i przepływ danych w systemie służącym do wyświetlania danych o zużyciu energii oraz statystyk mocy. System składa się z kilku głównych komponentów i interakcji, które są szczegółowo opisane poniżej.
Poniższy diagram sekwencji ilustruje, jak generowany jest wykres zużycia energii:
![Diagram sekwencji dla wykresu zużycia energii]
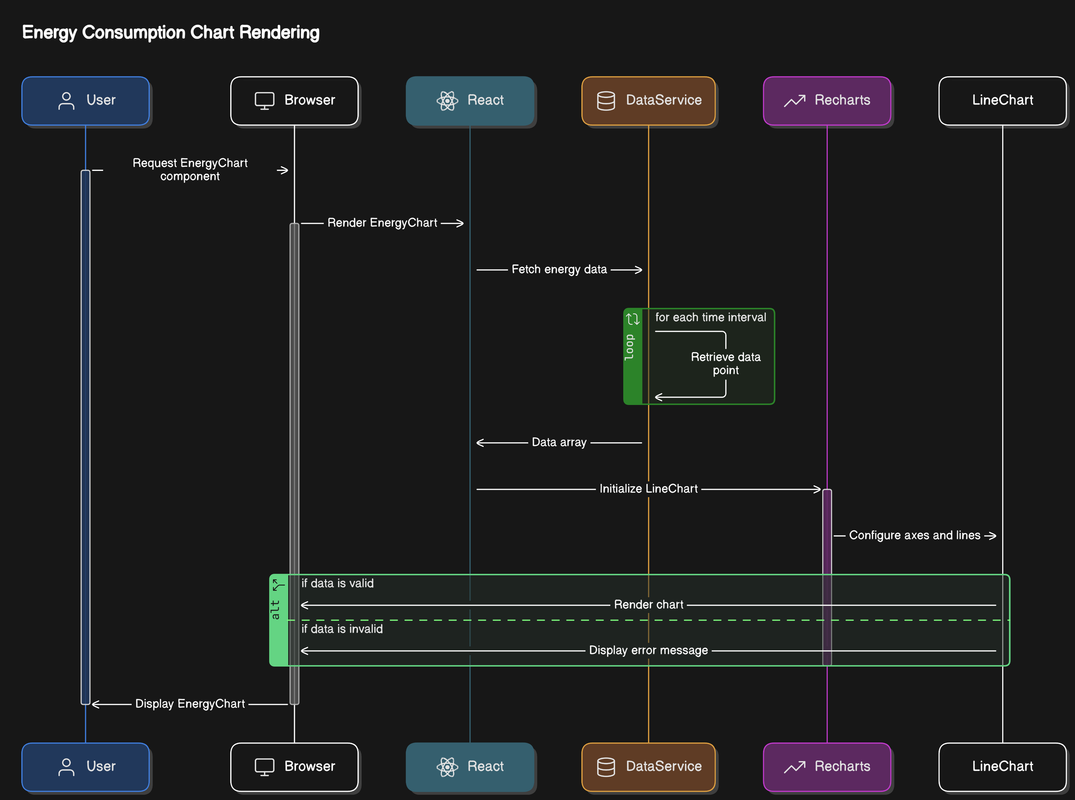
- Użytkownik inicjuje żądanie komponentu
EnergyChart. - Przeglądarka reaguje, wysyłając żądanie do komponentu React, aby renderować
EnergyChart. - React rozpoczyna proces renderowania, pobierając dane o zużyciu energii z DataService.
- DataService w pętli pobiera punkty danych dla każdego przedziału czasowego i konstruuje tablicę danych.
- React otrzymuje tablicę danych i inicjalizuje komponent
LineChartz biblioteki Recharts. - Recharts konfiguruje osie i linie wykresu.
- Następuje alternatywny przepływ:
- Jeśli dane są poprawne, wykres jest renderowany i wyświetlany Użytkownikowi.
- Jeśli dane są nieprawidłowe, wyświetlany jest komunikat o błędzie.
Poniższy schemat blokowy opisuje strukturę komponentu EnergyChart:
![Schemat blokowy komponentu EnergyChart]
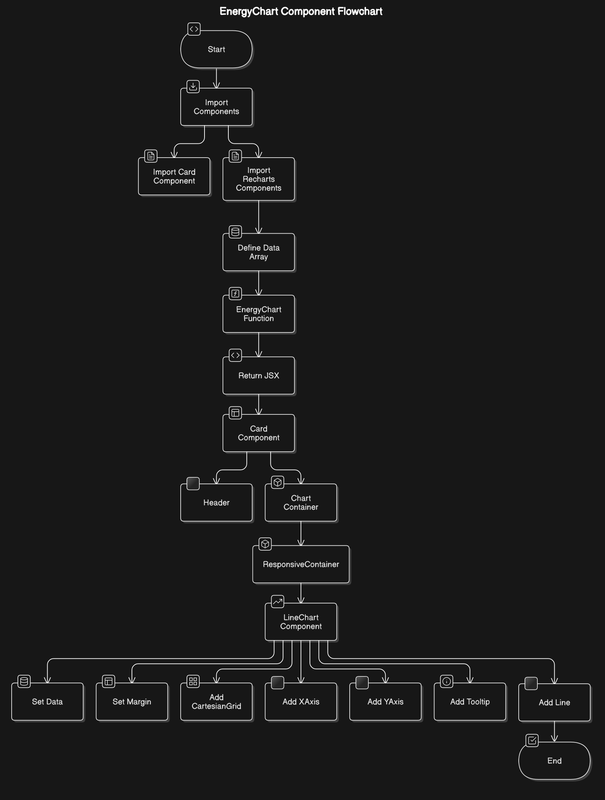
- Komponent rozpoczyna działanie.
- Importowane są niezbędne komponenty, w tym
CardiRecharts. - Definiowana jest tablica danych, która ma zostać wyświetlona na wykresie.
- Komponent
EnergyChartzwraca JSX, który tworzy strukturę interfejsu użytkownika:- Komponent
Cardjako kontener. Headerdla nagłówka wykresu.ChartContainerdla wykresu.ResponsiveContainerdla responsywnego wykresu.- Komponent
LineChartz biblioteki Recharts.
- Komponent
- Komponent
LineChartjest konfigurowany poprzez ustawienie danych, marginesów, siatki kartezjańskiej, osi X i Y, podpowiedzi (tooltip) i dodanie linii wykresu. - Komponent kończy działanie.
Poniższy diagram sekwencji ilustruje, jak pobierane i wyświetlane są statystyki mocy:
![Diagram sekwencji interakcji statystyk mocy]
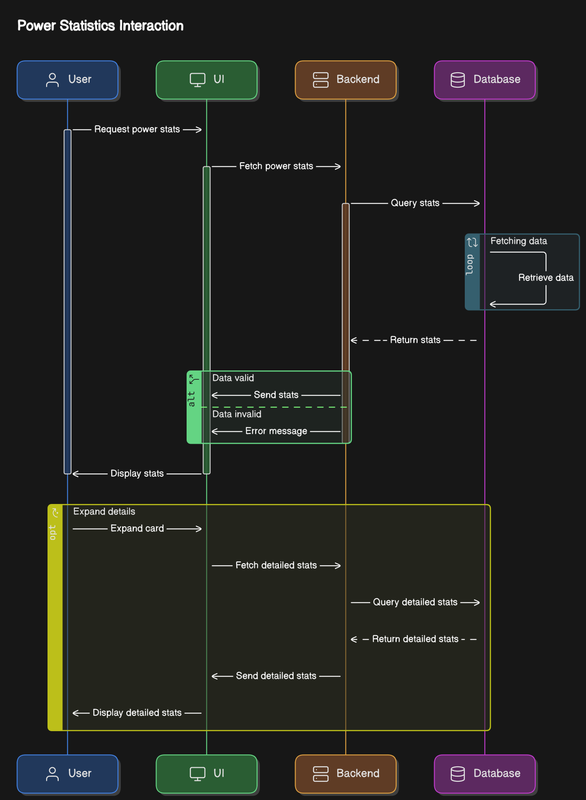
- Użytkownik inicjuje żądanie statystyk mocy.
- UI reaguje, wysyłając żądanie do Backendu.
- Backend wykonuje zapytanie do Bazy danych, w pętli pobierając kolejne dane.
- Baza danych zwraca statystyki Backendowi.
- Backend zwraca statystyki do UI
- Alternatywny przepływ:
- Jeśli dane są poprawne, statystyki są przesyłane do UI i wyświetlane Użytkownikowi
- Jeśli dane są nieprawidłowe, przesyłany jest komunikat o błędzie.
- Użytkownik decyduje o rozwinięciu karty w celu uzyskania szczegółowych statystyk.
- UI wysyła żądanie szczegółowych statystyk do Backendu.
- Backend wykonuje zapytanie do Bazy danych, aby pobrać dane szczegółowe.
- Baza danych zwraca szczegółowe statystyki Backendowi
- Backend zwraca szczegółowe statystyki do UI
- UI wyświetla szczegółowe statystyki Użytkownikowi.
- React: Biblioteka do budowy interfejsów użytkownika.
- Recharts: Biblioteka do tworzenia wykresów w React.
- Backend: Serwer API odpowiedzialny za pobieranie danych.
- Baza danych: Miejsce przechowywania danych.
- DataService: Warstwa pośrednicząca w pobieraniu danych.
- UI: Interfejs użytkownika, na którym renderowane są elementy i wykresy.
System zapewnia interaktywny widok danych dotyczących zużycia energii i statystyk mocy, korzystając z architektury opartej na komponentach, oddzielając warstwę prezentacji od warstwy danych. Diagramy sekwencji i schematy blokowe pomagają w zrozumieniu przepływu danych i struktury komponentów.
Monitoruj zużycie i generację energii w czasie rzeczywistym
(https://smart-grid-gems-22.lovable.app/)
There are several ways of editing your application.
Use browser
Simply visit the (https://smart-grid-gems-22.lovable.app/) and start prompting.
Changes made via Lovable will be committed automatically to this repo.
Use your preferred IDE
If you want to work locally using your own IDE, you can clone this repo and push changes. Pushed changes will also be reflected in Lovable.
The only requirement is having Node.js & npm installed - install with nvm
Follow these steps:
### Prerequisites
* **Bun:** You need Bun installed on your system. If you don't have it yet, follow the installation guide on the [official Bun website](https://bun.sh/docs/installation).
You can typically install it using:
```bash
curl -fsSL https://bun.sh/install | bash
```
### Installation
1. **Clone the repository:**
```bash
git clone [repository_url]
cd [project_directory]
```
2. **Install Bun:**
This project relies on `bun` as a package manager, so you might need to install `bun` globally to your local env or update to the latest version.
```bash
npm i -g bun
```
Alternatively, you can use the bun install command:
```bash
bun install
```
**Note:** You can install this globally to use bun commands as a cli tool.
3. **Install dependencies:**
```bash
npm i
```
or if you want to use bun's install:
```bash
bun install
```
This will install the project's dependencies listed in `package.json`.
### Running the Development Server
To start the development server, use the following command:
```bash
bun run devContributing:
After you've cloned the repository, please stick to the following flow:
Create a new branch for your changes:
git checkout -b feature-name
Make your changes, then stage and commit them:
git add .
git commit -m "Description of changes"
Push your branch to the remote repository:
git push origin feature-name
Create a Pull Request: Go to the GitHub repository, create a pull request from your branch, and after approval merge using squash and merge option.
**Edit a file directly in GitHub**
- Navigate to the desired file(s).
- Click the "Edit" button (pencil icon) at the top right of the file view.
- Make your changes and commit the changes.
**Use GitHub Codespaces**
- Navigate to the main page of your repository.
- Click on the "Code" button (green button) near the top right.
- Select the "Codespaces" tab.
- Click on "New codespace" to launch a new Codespace environment.
- Edit files directly within the Codespace and commit and push your changes once you're done.
## What technologies are used for this project?
This project is built with .
- Vite
- TypeScript
- React
- shadcn-ui
- Tailwind CS-Gemini
- Gemini API
## How can I deploy ?
(https://smart-grid-gems-22.lovable.app/) and click on Share -> Publish.
## I want to use a custom domain - is that possible?
We don't support custom domains (yet). If you want to deploy your project under your own domain then we recommend using Netlify. Visit our docs for more details: [Custom domains]