This code is a PyTorch implementation for paper: Listen, Attend and Spell, a nice work on End-to-End ASR, Speech Recognition model.
also provides a Chinese Mandarin ASR pretrained model.
- Dataset
- LibriSpeech for English Speech Recognition
- AISHELL-Speech for Chinese Mandarin Speech Recognition
- Usage
- generate vocab file
- training
- test
- infer
- Demo
Improving End-to-End Models For Speech Recognition
The LAS architecture consists of 3 components. The listener encoder component, which is similar to a standard AM, takes the a time-frequency representation of the input speech signal, x, and uses a set of neural network layers to map the input to a higher-level feature representation, henc. The output of the encoder is passed to an attender, which uses henc to learn an alignment between input features x and predicted subword units {yn, … y0}, where each subword is typically a grapheme or wordpiece. Finally, the output of the attention module is passed to the speller (i.e., decoder), similar to an LM, that produces a probability distribution over a set of hypothesized words.
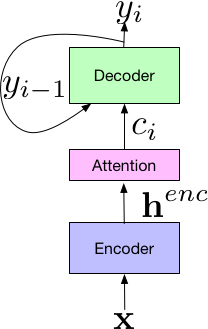
Components of the LAS End-to-End Model.
This repository contains:
- model code which implemented the paper.
- generate vocab file, you can use to generate your vocab file for your dataset.
- training scripts to train the model.
- testing scripts to test the model.
pip install -r requirements.txtFirst, we should generate our vocab file from dataset's transcripts file. Please reference code in generate_vocab_file.py. If you want train aishell data, you can use generate_vocab_file_aishell.py directly.
python generate_vocab_file_aishell.py --input_file $DATA_DIR/data_aishell/transcript_v0.8.txt --output_file ./aishell_vocab.txt --mode character --vocab_size 5000it will create a vocab file named aishell_vocab.txt in your folder.
Before training, you need to write your dataset code in package dataset.
If you want use my aishell dataset code, you also should take care about the transcripts file path in data/aishell.py line 26:
src_file = "/data/Speech/SLR33/data_aishell/" + "transcript/aishell_transcript_v0.8.txt"When ready.
Let's train:
python main.py --config ./config/aishell_asr_example_lstm4atthead1.yamlyou can write your config file, please reference config/aishell_asr_example_lstm4atthead1.yaml
specific variables: corpus's path & vocab_file
python main.py --config ./config/aishell_asr_example_lstm4atthead1.yaml --testa pretrained model training on AISHELL-Dataset
download from Google Drive
inference:
python infer.py- Listen, Attend and Spell, W Chan et al.
- Neural Machine Translation of Rare Words with Subword Units, R Sennrich et al.
- Attention-Based Models for Speech Recognition, J Chorowski et al.
- Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks, A Graves et al.
- Joint CTC-Attention based End-to-End Speech Recognition using Multi-task Learning, S Kim et al.
- Advances in Joint CTC-Attention based End-to-End Speech Recognition with a Deep CNN Encoder and RNN-LM, T Hori et al.
If this project help you reduce time to develop, you can give me a cup of coffee :)
AliPay(支付宝)

WechatPay(微信)

MIT © Kun