Pagination using Range header #234
Conversation
| end | ||
|
|
||
| context 'with an unbound end range' do | ||
| let(:range_header) { 'objects 0-' } |
There was a problem hiding this comment.
@geemus Do you think unbound ranges should be allowed?
There was a problem hiding this comment.
@gudmundur I think they are in the API already!
$ curl -H "Range: id ]006e2c53-e3a9-4152-851c-abf6e9991c63..; max=1" -H "Accept: application/vnd.heroku+json; version=3" -n https://api.heroku.com/apps
[
{
"archived_at":null,
...There was a problem hiding this comment.
Not absolutely required, but certainly nice to have.
|
@gudmundur Looks good so far! Let me know when you want a more detailed review. One tricky piece that we may still need are some kind of response helpers that are used to generate a next range. BTW, not sure if I missed something, but did we change the range from the two dots to a hyphen? Might make ranging via UUID a little tricky ;) |
|
@brandur Yeah, there is an internal RFC at Heroku that changes a few things. The major difference is that it's using slicing (limit & offset in SQL), rather than |
|
Ah, I see! Maybe a few considerations for you and @geemus to consider:
I don't have too much skin in the game anymore, but it might be wise to at least make the pagination mechanism modular so that users can vary their implementation if necessary. |
|
@brandur thanks for the feedback, some thoughts:
Also, happy to share the RFC itself if you are curious, will probably think about trying to move it into the HTTP API Guide in some capacity once we settle on some things. |
Yeah, that's a tough one. I suppose that if you do adopt offset-based pagination, it might make sense to go back to hyphen if most client libraries will have to change anyway.
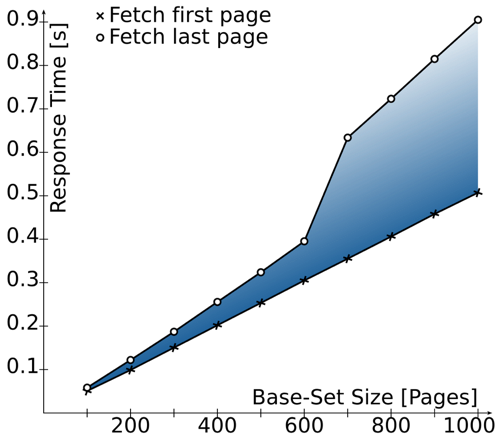
Check out this graph from the article above. It's far from a comprehensive analysis, but it shows the performance drop-off very well. The discrepancy starts to show up right away, but it took 600 pages to see a very serious cliff. The add-on API endpoint to retrieve lists of apps is probably large enough for at least some add-on providers for the difference to show (if you ever get that moved over to V3 ;). Obviously since it's offset-based today it's not going to take down the database or anything, but it's less efficient. And one more data point: Stripe started with offset-based pagination but moved off of it (somewhat anecdotal ;). This wasn't so much for performance reasons, but more because offset-based pagination's inferior characteristics around stability. |
{kind=link}
|
@brandur I guess maybe we end up stuck with both, at least potentially. Offset is simpler to implement and sometimes desired (when you want to range over non-unique and/or not ordered/incrementing values), but comes with tradeoffs. Otherwise using our original style (or something like it) over incrementing id would be more stable and more performant, but if I'm not mistaken it tends to need auto-incrementing id to work well in terms of stability (and I'm not sure we want to reveal those and/or depend upon their presence). Definitely something I'll have to ponder more before we settle on something here. |
|
Joining in here because part of the discussion for changing this was prompted by a few situations my team ran into. Content-based pagination is superior in all the ways you've mentioned @brandur but it still fundamentally relies on paginating over unique values. Some workarounds might be conceivable based on faux-composite indexes, but these have other trade-offs. Cleverer but inconceivable to implement well alternatives could also include returning smaller or larger ranges than requested when the page boundary lands in the middle of a set of same-value fields. But... :/ Have you thought much about a way to handle non-unique sort fields? In practice, these might be dates which rarely collide but in theory one might be sorting by something like a |
|
I don't think I like what I'm about to propose but I'll do so anyway in case it can be a strawman which prompts other thoughts... If, like Heroku, the sortable fields are pre-declared and the range headers are treated opaquely, we could create extra columns which hold unique values corresponding in order to the non-unique column, but which arbitrarily orders same-value records uniquely. E.g. the The trade-off here might be not working too well for mutable fields, but even this could be accommodated, to an extend, by spacing out the sort values. This might mean a header could be something like |
|
To take this further, Postgres is capable enough that these fields could actually be a custom type or domain which is a tuple of the original value and an auto-incrementing number. |
|
@bjeanes Wouldn't the tiebreaker have to be based on something unique in the content? |
|
@gudmundur yes, whether a sequence or some other field of the record, like |
Not really :/ I don't know of any non-unique examples in the Stripe API off-hand (which isn't to say there aren't; I still don't know it all that well), but I'll dig in if one comes up.
Good idea! That certainly seems worthy of investigation at the very least. There are of course that some possible downsides like the ranges looking a tad unwieldy and possibly a more difficult implementation, but I think you probably considered all of that already. A variation of the same idea might also be to allow expand the spec to allow ranging on composite fields and then just make sure that composite fields are always used in place of non-unique fields by themselves. So for example, instead of saying that it's possible to range on I was thinking originally that you might need some composite indexes on Anyway, I'm looking forward to see where you guys go with this! |
|
And sorry about the delay in reply here! I let my inbox runaway on me over the holidays :/ |
Potentially, but it should be pretty opaque. Since it's a |
+1. That would be a nice feature for convenience. |
|
For the case of ranging over unique values, I think our approach is fairly nailed down. I've mulled non-unique values for a while now, then finally spent time on Googling this and then stumbled on this http://www.slideshare.net/MarkusWinand/p2d2-pagination-done-the-postgresql-way. It seems that we can use row value expressions in Postgres to solve this. In conjunction with a non-unique field, we mix in a unique value, uuid for example. That would give us a header in the form of something like SELECT
*
FROM
model
WHERE
ROW(created_at, id) < ROW('2016-02-09T0730Z', 'facf751c-860e-4004-a206-6a0899b89597')
ORDER BY
created_at, id
LIMIT
200;Using this requires that we have a composite index on |
|
@gudmundur oh my god that is so elegant. I love it!
I'm thinking that in most cases your access isn't based on ownership so much as other access mechanisms (permissions, sharing, etc) which means we lose out on that extra tuple value. Nonetheless, that should do the trick in some cases. Really nice find @gudmundur! attn @geemus too |
|
(Obviously, I say that without having tested this yet, but in theory it seems solid) |
|
It looks like the Edit: which, incidentally, seems to be what slide 28 of the presentation you linked is doing |
|
Thanks for the write-up Gudmundur! This looks good to me as well! On Tuesday, February 9, 2016, Bo Jeanes [email protected] wrote:
|
|
Sounds great, thanks for researching. My only pause might be around the separator. I worry that forward slash might be part of a legit value (though it isn't in either of those) and/or if there is something clearer. Comma seems nice in some ways, for instance, though I'm not sure it helps at all wrt avoiding conflicts. |
|
@gudmundur @geemus what is the current status / blockers for this? I would like to be able to use this in my pliny app and if there is anything I can do to help, please let me know. |
|
@ransombriggs Implementing this. What specific part do you need? Pagination over uniques or over non-uniques? We'll be needing this on DevEx soon, so I'll allocate time to do this in the next couple of days. |
|
@gudmundur over uniques, I am just working on a pliny app and did not want to duplicate work if I could avoid it |
Note: 🐝 This is still work in progress. 🐝
This code is based on how the Heroku Platform API deals with pagination and ranges, both in terms of code and design. Credit for that goes to @brandur and @geemus.