Cloud Providers such as Together AI, Fireworks.ai, Lepton.ai, Cerebras, Sambanova, Groq, Anyscale, etc, enable developers to build applications with access to APIs for open source Large Language Models (LLMs). GenAI-Bench attempts to benchmark LLM Inference APIs, demostrate how they work, and compare models provided. The benchmark reports the end to end time for API response time for one token, which becomes the equivalent of Time To First Token (TTFT).
Almost all benchmarking results profile different cloud providers at different times of the day. As a result, the comparison is misleading as it discounts the effect of load on the cloud servers. If you need you app to use a cloud service provider at a certan time in the day, the result at a certain time at night or early morning is meaningless for you. The distinguishing feature about this benchmark is that it issues requests to all providers/models concurrently, so you get a fair apples-to-apples analysis of all the endpoints. The TTFT reported can be easiily compared bewteen the different providers/models.
First add all the required vendors, models, and API Keys in the configuration file (config.json). The configuration file should look like:
[
{
"vendor": "togetherai",
"model": "togethercomputer/llama-2-7b-chat",
"api_key": "Insert API Key here"
},
{
"vendor": "anyscale",
"model": "meta-llama/Llama-2-7b-chat-hf",
"api_key": "Insert API Key here"
}
]
You can replace the model with your favorite one. You can also compare multiple models from the same provider. As an example, the following config file compares Llama2-7B vs Llama2-70B from Together AI
[
{
"vendor": "togetherai",
"model": "togethercomputer/llama-2-7b-chat",
"api_key": "Insert API Key here"
},
{
"vendor": "togetherai",
"model": "togethercomputer/llama-2-70b-chat",
"api_key": "Insert API Key here"
}
]
Then Run:
python3 benchmark.py
Optional arguments allow you to change the number of iterations, time between iterations, and input file used to load tokens.
Here we take the example of Together AI. Other vendors have similar steps
- Sign up for Together API access at https://api.together.xyz
- Retrieve your API key from the settings portion of your profile.
- Supply the model and the API key in the example above.
The benchmark reports the results per iteration in CSV format. At the end of all the iterations, the benchmark plots a comparison in the provided results file.
Here are is an example result:
python3 benchmark.py
Iteration #, Date/Time, Model Name, Vendor, API response time(s)
0,togethercomputer/llama-2-7b-chat,togetherai,02/05/2024 00:01:42,0.6702483710005254
0,meta-llama/Llama-2-7b-chat-hf,anyscale,02/05/2024 00:01:42,0.7416756729999179
The above is the result of one iteration.
The following plot compares the Llama2-7B-chat model provided by Together AI and Anyscale. Data was collected on 2/5/2024 between 10AM PST and 12PM PST.

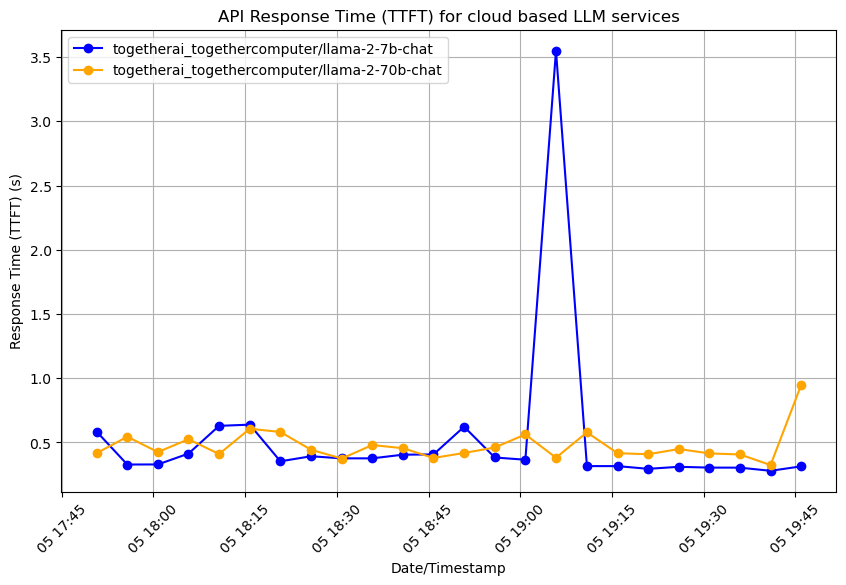
The following plot compares the Llama2-7B-chat model and Llama2-70B-chat model provided by Together AI. Data was collected on 2/5/2024 between 6PM PST and 8PM PST.
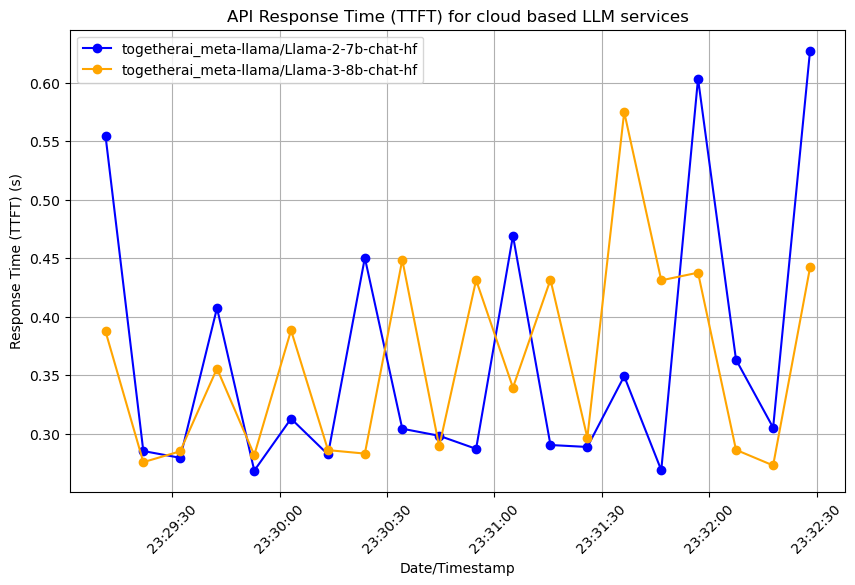
The following plot compares the Llama2-7B-chat model and the Llama3-8B-chat models provided by Together AI. The comparison was generated on the day Llama3 was made available by Together AI.
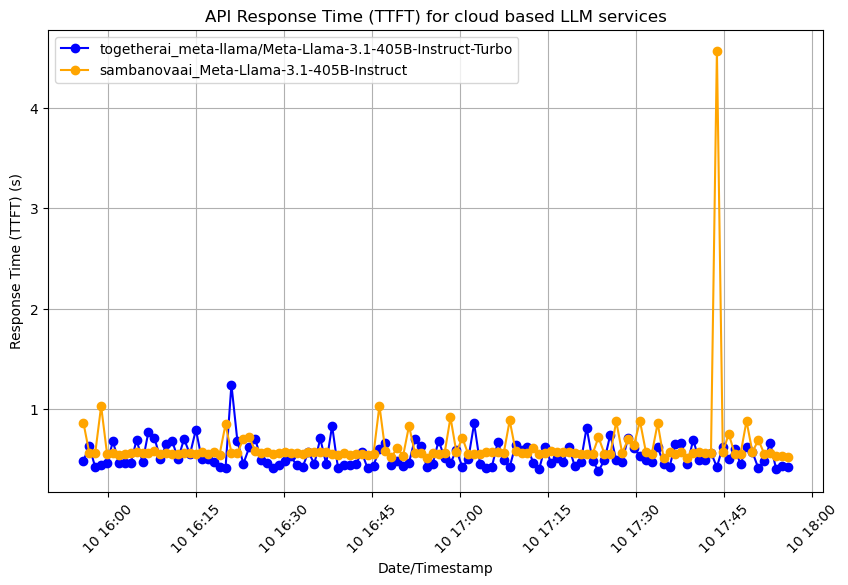
The following plot compared the Llama3-405B model offered by Together AI and Sambanova AI. This comparison was generated on the day Llama3-405B was made available for developer access.