期末评分标准
- 形式:不限(文本不超过 5000 字)
- 题材:不限
- 加分:数据获取难度(例,因公共议题向政府部门索要未公开数据)
- 评分:信息/数据搜集(30%)、内容逻辑(40%)、作品设计(30%)
- 成品链接(用于课堂展示)
- 过程描述文档(用于解释作品制作过程)
- 选题想法、资料搜集过程
- 确定内容框架的过程
- 视觉呈现的选择
- 参考资料(链接或文件)
- 用到的数据(链接或文件)
12月24日:对期末项目的反馈和建议会发给大家12月25日:项目链接会发给大家,请认真地看一遍所有同学的作品12月27日:- 每位同学上台介绍自己的项目(3分钟)
- 随机抽 2~3 位同学点评(毫无意见或没看过的话,最终成绩 -3 分,扣分无上限)
定性与定量
- 倾向于描述某个主题
- 重点在于深入探讨,而非进行数值衡量(看见细节、人性化)
- 方式包括但不限于:
- 访谈
- 专家意见
- 开放式调查问卷
- 观察性研究
- 结构化的统计数据
- 得到重要的变量或相关关系(掌握大局)
- 相关性 vs 因果关系
- 定性和定量可以互相成就
- Maximilian Schich et al., A network framework of cultural history:
在历史研究中,定性分析关注个体历史记录,定量分析测量并建立通用模式。
我们认为这两种方法是可以互补的:我们需要量化的方法来发现统计性规律,也需要定性的分析来解释已知通用模式中局部偏离所带来的影响。 - 例子合集:https://www.one-tab.com/page/NBCQydktQZSxvCibyISwbQ
What's next?
- 数据新闻精选 Feed 列表:http://initiumlab.com/blog/20170401-data-news/
- 学习 Coding:https://github.com/freeCodeCamp/freeCodeCamp
- 中国大学 MOOC:https://www.icourse163.org/
- 香港 Data & News Society:https://dnnsociety.org/
地球是什么形状
对于地球测量而言,地表是一个无法用数学公式进行表达的曲面,这样的曲面不能作为制图和测量的基准。
想象一下海洋仅受重力的影响静止不动,生成的表面是大地水准面的表现形式。大地水准面的提出,对大地测量带来重要的突破。但大地水准面依然无法建模。

由于椭球体是通过大地水准面得出的,当具体到各个国家时,并不能完美还原当地的实际情况。所以人们在实际使用中又提出了针对各地区的参考椭球体模型。

地图投影
一套将三维的地球特征转换为二维显示的数学法则。USGS的地图投影简短介绍: https://store.usgs.gov/assets/mod/storefiles/PDF/16573.pdf
三种投影面示意:分别为平面、圆锥面、圆柱面



常用地图投影:
- 墨卡托投影(Mercator)
最常见的投影方式,属于圆柱投影─等角正圆柱投影,墨卡托1569年专为航海目的而设计。此投影的等角属性最适合用于赤道附近地区,例如印尼和太平洋部分地区。 - 高斯-克鲁格投影(Gauss-Kruger),投影后无角度变形
- 通用墨卡托投影(UTM),横轴等角割圆柱投影
- 兰伯特正形圆锥投影(Lambert),等角圆锥投影,适用于中纬度
- 阿尔伯斯投影(Albers),方位等积投影
地图投影的选择:
- 世界地图投影:保证全球整体变形不大,采用多圆锥投影等
- 半球地图投影:东西半球(横轴等面积/等角方位投影),南北半球(正轴等面积/等角/等距离方位投影)
- 各大洲投影:亚洲和北美洲(彭纳投影)、欧洲和大洋洲(正轴等圆锥投影)、南美洲(桑逊投影)
- 我国地图投影:全国地图(Lambert居多)、分省区(高斯-克鲁格投影居多)、大比例尺地形图(高斯-克鲁格投影)
做选择的偷懒网站:http://projectionwizard.org/#
投影变形: 将不可展平的地球椭球面绘制到平面时产生的差异,包括长度变形、面积变形、角度变形
- 没有完美的投影方式!任何投影都会变形
- 墨卡托投影变形演示:https://thetruesize.com/
- 中国全图不适合墨卡托投影!
- 不如去下载标准地图:http://bzdt.ch.mnr.gov.cn/
地理数据
地理编码是指将坐标对、地址或地名等位置描述转换为地球表面上某位置的过程。
通过地理编码可以快速查找到各类位置。可搜索的位置类型包括:
- 感兴趣点或地名词典中的地名,例如山脉、桥梁和店铺
- 基于经纬度或其他参考系统的坐标
- 各种样式和格式表示的地址,包括街道交叉口、含有街道名称的门牌号及邮政编码
- 手动:例如使用 geojson.io
- 半手动:如使用谷歌地图链接里的经纬度,或百度的拾取坐标系统
- 自动:使用 API 等自动给地址编码
- 点,例如:餐馆的地点,经纬度
- 线,例如:一条路
- 多边形/面,例如:国家、商业区的形状
- 文件格式包括:
Excel, csv, shapefile, geojson
- 栅格可以是数字航空像片、卫星影像、数字图片或甚至扫描的地图。
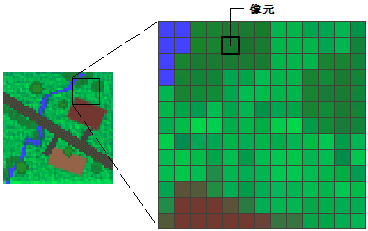
- 在栅格数据集中,每个像素都有一个值,来表示数据所描绘的现象:如类别、量级、高度或光谱值等
- 其中的类别可以是草地、森林或道路等土地利用类
- 量级可以表示重力、噪声污染或降雨百分比
- 高度(距离)则可表示平均海平面以上的表面高程,可以用来派生出坡度、坡向和流域属性
- 光谱值可在卫星影像和航空摄影中表示光反射系数和颜色
其他链接
- 复旦历史地理:http://yugong.fudan.edu.cn/index.php
- 葛剑雄老师:https://book.douban.com/subject/25720918/
- 哥大 SEDAC 数据(下载需注册):https://sedac.ciesin.columbia.edu/
- NASA 地球观测站,每日一图:https://earthobservatory.nasa.gov/images
- Earth 可视化:https://earth.nullschool.net/zh-cn/about.html
- 标准地图服务:http://bzdt.ch.mnr.gov.cn/index.html
- OpenStreetMap:https://www.openstreetmap.org/
- MIT Senseable City Lab:http://senseable.mit.edu/
- 北京城市实验室:https://www.beijingcitylab.com/
R 在新闻编辑室的应用

Federica Fragapane 作品及过程赏析
- 作品集
- 创作过程举例
Amanda Cox 的《纽约时报》“爆款”分析
总结作品件数:400件
作品编码方式:
- "surprise.reveal" 出乎意料、揭露
- "explicitly.emotional...atmospheric" 情感、共鸣
- "goofy.comparison" 比较
- "big.breaking.news.big.breaking.news.adjacent" 突发新闻、大新闻
- "comprehensive...way.more.detail.than.you.actually.need" 非常复杂
- "useful" 有用
- "mostly.things.you.already.know" 大部分信息已知
- "difficult.topic" 话题难(战争、暴力、气候变化)
- "data.really.hard" 数据艰辛
- "design.really.hard" 设计艰辛
- "development.really.hard" 开发艰辛
- "mostly.a.bar.chart" 就是张柱状图
- "takeaway" 快餐型
- "vectory" 矢量的(?)
- "requires.participation" 需要交互
- "slideshow.video.like" 形式像交互ppt或视频
- "moves..non.navigation" 不用交互
入选最“爆款”作品件数:6件
特质:
- "development.really.hard" 开发艰难
- "big.breaking.news.big.breaking.news.adjacent" 大新闻
- "useful" 有用
- "explicitly.emotional…atmospheric" 情感
- "surprise.reveal" 出乎意料、揭露
- "comprehensive" 复杂
总结:
- 话题难(战争、暴力、气候变化)的作品、快餐型作品的读者反馈都不咋的
- 共鸣强或有用的作品大多和突发新闻有关,读者反馈很好
- 一看就投入了更多时间做出的作品,反馈也较好
如何告诉读者这事儿很重要?
- 版面篇幅,《纽约时报》“美国每一栋建筑”

- 花费的功夫
R
学习R制图的代码案例库
本周作业
- 任选自己在“垃圾”或“未成年人犯罪”两次作业里做过的两张图(及数据)
- 使用ggplot2复刻/重新制作后导出(不用在其他软件里修饰)
- 提交的 markdown 里包括1️⃣之前的原图和ggplot图 2️⃣实现用的代码
- 考核点:在 R 里导入数据,用 ggplot2 进行基础绘图
- 如果你更习惯写 python ,提交 python 代码也行
图形语法简介
-
将绘图视为一种映射 (mapping),从数学空间映射到图形元素空间,例如将不同的数值映射成不同的色彩或透明度。
-
由下而上 bottom-up:
ggplot2 包的特点在于不去定义具体的图形(如直方图,散点图),而是定义底层组件(如线条、方块)来合成复杂的图形,这使它能以非常简洁的函数构建各类图形。

- 图层的集合 Layers
- 标度的集合 Scales
- 坐标系统 Coordiates
- 分面 Facets
基础概念
-
图层 (Layer): Adobe 软件的使用者对图层不会陌生。
一个图层好比是一张玻璃纸,包含有各种图形元素,你可以分别建立图层然后叠放在一起,组合成图形的最终效果。图层可以允许用户一步步的构建图形,方便单独对图层进行修改、增加统计量、甚至改动数据。 -
标度 (Scale):
把数据单位转换成电脑可以识别的物理单位,这个过程被称之为标度变换。一组分类数据可以映射成为不同的形状,也可以映射成为不同的大小或不同的颜色。 -
坐标系统 (Coordinate):
坐标系统控制了图形的坐标轴并影响所有图形元素,最常用的是直角坐标轴。 -
分面 (Facet):
很多时候需要将数据按某种方法分组,分别进行绘图。分面控制分组绘图的方法和排列形式。
- 图形属性与数据的映射(包括颜色、形状、大小等) aesthetic mappings
aes参数 - 几何对象(包括点 points、线 lines、条 bars等) geometric object
geom参数
几何对象决定图形渲染成什么类型,折线?直方图?散点图?等等 - 统计变换 statistical transformation
stat参数 - 位置调整 position adjustment
position参数
图形语法简介:以 mpg 数据集为例
# 安装、载入 ggplot2 包
install.packages("ggplot2")
library(ggplot2)
# 查看 mpg 数据
View(mpg)
# 或看看数据集前10行
head(mpg, 10)得到:
# A tibble: 10 x 11
manufacturer model displ year cyl trans drv cty hwy fl
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr>
1 audi a4 1.8 1999 4 auto… f 18 29 p
2 audi a4 1.8 1999 4 manu… f 21 29 p
3 audi a4 2 2008 4 manu… f 20 31 p
4 audi a4 2 2008 4 auto… f 21 30 p
5 audi a4 2.8 1999 6 auto… f 16 26 p
6 audi a4 2.8 1999 6 manu… f 18 26 p
7 audi a4 3.1 2008 6 auto… f 18 27 p
8 audi a4 q… 1.8 1999 4 manu… 4 18 26 p
9 audi a4 q… 1.8 1999 4 auto… 4 16 25 p
10 audi a4 q… 2 2008 4 manu… 4 20 28 p
# … with 1 more variable: class <chr>
通过代码 ?mgp,我们可以知道几个变量的意思
- manufacturer:制造商
- model:汽车型号
- trans:自动档、手动档
- drv:前驱 front-wheel drive、后驱 rear wheel、还是四驱 4wd
- cty:城市里,一升油能跑多少里程(英里/加仑),city miles per gallon
接下来要用到的变量为:
- displ:发动机排量(升),engine displacement
- hwy:高速公路上,一升油能跑多少里程(英里/加仑),highway miles per gallon
- cyl:气缸数量,cylinders
背景知识──我国轿车级别根据排量大小来决定:
追求高性能汽车的大都选择大排量发动机,经济型则选用小排量的发动机。
- 微型车排量 ≤ 1.0L
- 普通车排量 1-1.6L
- 中级车排量 1.6-2.5L
- 中高级车排量 2.5-4L
- 高级车排量 > 4L
认识完了 mpg 数据集,首先用 ggplot() 来定义数据源,其中 aes (图形属性)参数非常关键:
# 它把 发动机排量 (displ) 映射到X轴
# 它把 高速公路每加仑里程数 (hwy) 映射到Y轴
# 它把 气缸数量 (cyl) 变为分类数据后,映射为不同的颜色
p <- ggplot(data = mpg,aes(x = displ,y = hwy,colour = factor(cyl)))
p
运行 p 后我们得到了初始图层 (Layer) 的样子:

使用 + 号继续叠加图层:
geom_point()加上了几何对象(散点)图层geom_smooth()加上了平滑曲线
p + geom_point() + geom_smooth()
# 不明白的时候随时用 ?geom_smooth 等代码看 R 里的帮助我们得到了几个图层叠加后的图形:

油耗和排量、气缸的关系是?
p <- ggplot(mpg, aes(x = displ,y = hwy))
p + geom_point(aes(colour = factor(cyl))) + geom_smooth()实操1:在 R 里导入数据
# 首先设置工作环境
setwd("~/Desktop")
例1:导入csv或excel文件
# 读取 csv 格式数据
ramen <- read.csv("ramen.csv")
# 如果第一行没有每列的名称
ramen <- read.csv("ramen.csv", header = FALSE)
# 读取 excel 文件,需要安装 readxl 这个包
install.packages("readxl")
library(readxl)
ramen <- read_excel("ramen.xlsx")
# 假设文件中有多张表
ramen <- read_excel("ramen.xlsx", sheet = 2)
例2:利用api接口导入(以 Tushare 包为例)
# 安装、导入 Tushare 包
install.packages("Tushare")
library(Tushare)
# 使用你自己的token
api <- Tushare::pro_api(token = '你的token可以从 个人主页-接口TOKEN 里复制到这里')
# 只调用api接口,看看“股票列表”数据什么样子
api(api_name = 'stock_basic')
# 获取日线行情
zzd <- api(api_name = 'daily', ts_code='002069.SZ', start_date='20191030', end_date='20191115')
# 存取数据
write.csv(zzd, file="zzd-daily-20191030-20191115.csv")
相关书籍
- R Graphics Cookbook: https://r-graphics.org/
- 《ggplot2:数据分析与图形艺术》
- 《现代统计图形》:https://bookdown.org/xiangyun/msg/
本周作业
- 发邮件讨论对于期末项目的想法
- 关于期末项目
- 形式:不限(呈现的文本不超过5000字)
- 题材:不限
- 考核点:信息/数据搜集、呈现逻辑、内容梳理、作品美感
- 加分项:数据获取难度(例,因公共议题向政府部门索要未公开数据)
- 用 Web Scraper 抓取网站,如:http://ldzl.people.com.cn/dfzlk/front/firstPage.htm
- 熟悉 RStudio 界面及基础指令
形式与功能
下面这些功能,它有哪些?
- 展示
- 比较
- 组织
- 关联
-
重形式派代表:
Nigel Holmes- http://www.nigelholmes.com
- 幽默的力量 Using humor to inform
- “通常,让读者开心的成分有助于他们记住你的图表”
- 演讲:https://www.youtube.com/watch?v=WB7DCEayj3w
-
重功能派代表:
Edward Tufte- https://www.edwardtufte.com/
- 数据—油墨比 data-ink ratio(印刷时代)
- YouTube频道:https://www.youtube.com/user/EdwardTufte
-
形式常常受制于功能,但你依然拥有选择权
- 可视化轮盘
- 抽象/模拟,实用/修饰,致密/稀疏,多维/一维,创新/通用,简洁/冗余
- 灵活选择,不要刻板
R
- 设置工作环境
- 安装、运行R程序包
- 在R里寻求帮助
- 使用R程序包自带的例子、演示和数据
- 代码的大小写很重要,写命令时尤其要注意
- 符号
>代表一段 R 程序的开始+是续行符,当一段程序在某一行没有完整显示时,会折到下一行,此时 R 会以+来表示程序语句在继续#代表注释,即不会被执行的语句(但写给自己和合作者看很有用)
- 函数基本语法
函数名字(参数1, 参数2, … )- 这里的括号
()代表函数内容,而,分隔参数设定
- Tab 键和 Esc 键
Tab可以引导你写完函数Esc可以让你退出代码的黑洞
- 各种教程、教材:https://bookdown.org/
- 谢益辉《现代统计图形》:https://bookdown.org/xiangyun/msg/history.html
- Web Scraper: https://www.webscraper.io/
本周作业
- 形式: 图文(图最多两张;文字不超过1000字,写多了不扣分;请用中文书写)
- 新闻由头: https://thepaper.cn/newsDetail_forward_4791263
- 关键词: 未成年人保护法、未成年人犯罪
- 考核点:
- 信息/数据搜集能力,资料消化、内容梳理能力
- 制作过程说明详细
- 言之有物、逻辑自洽
- 提交的markdown文档应包括:
- 最终的图文呈现(1)
- 过程步骤(2):信息/数据搜集、选题角度确立的过程;数据分析和呈现的考虑与步骤
- 信息/数据来源链接(3)
什么是合适的图表
-
方式一:从图表类型起步 Top-down
- FT Visual Vocalbulary《金融时报》图表指南
- Chart Suggestions — A Thought-Starter
- 数据可视化工具目录
-
方式二:Bottom-up
- 从元素起步
- 尝试不同的表现形式


总原则:要呈现给读者的是故事,不是数据
- 数据点越多越复杂,读者“秒懂”的信息越少
- 你的信息图有重点吗?
怎么说重点?
颜色
- 用颜色来“合并”类似数组
- 用灰色来“隐去”背景数据
数值
- 每一个点需要标出吗?
- 每个值需要标出吗?
- 数值需要排序吗?
- 数组少就直接标吧
图例
- 没取整的数值型图例谁能“秒懂”?
- 多个区间的数值型图例可以横着放
- 考虑颜色/值标出多少合适
期末项目该准备起来了
- 工具
webscraper.io - 用途
抓取“规则”的网页,如:知乎某问题答案、网站文章列表等
找信息的渠道包括但不限于:
- 中外媒体报道(深度长篇报道)
- 相关多媒体制作,如纪录片等(帮助自己了解别人的叙事逻辑)
- 智库、数据库(等其他数据库)
- 相关书籍或文献(国图网站用起来)
- 社交媒体上的大众讨论(twitter、微博、reddit、知乎等)
- 关于该议题的线下讲座、论坛、活动(如“中法环境月”和“垃圾”选题)
别太懒太天真
- 太懒:不假思索,照搬报告里的观点
- 太傻:天知道它的内容多大水分、鬼知道它是不是公关软文,你怎么就都信了
- 请注明不是你自己的观点的出处,不背别人立场的锅
别对历史一无所知
友好型阅读材料:何伟《甲骨文》,请自行检索电子版
本周作业
- 以“垃圾”为题搜集数据和资料,不限角度和数据量、国内/国外的数据集都可以用
- 经过资料整合和数据分析后,以图文的形式呈现议题(图表 < 3张,文字 300-800 字)
- markdown文档应包括:
- 最终的图文呈现(1)
- 过程步骤(2):数据来源;过程中参考的资料、数据收集过程;数据分析和呈现的步骤
- 选择报道角度的思考过程(3)
- 制图不限所用工具
- 切入“垃圾”这个议题的角度(信息搜集、整合能力)
- 数据选择的合理性(对数据的理解)
- 制图的质量(呈现能力)
- 篇幅精简、直击重点,参考:Graphic Detail,不用面面俱到,而是言之有物

色彩
-
原色、间色、复色
- 原色 Primary Colors
指不能透过其他颜色混合调配而得出的“基本色”,三原色“红、黄、蓝” - 间色/二次色 Secondary Colors
由两种等量的原色混合而成,如橙=红+黄、紫=红+蓝、绿=蓝+黄 - 复色/第三色 Tertiary Colors
由色轮上的间色与其相邻的原色混合而成,如黄橙色、蓝紫色 - 互补色 Complementary Colors
色轮上二次色与其正对面的原色为互补色,如红色与绿色、蓝色与橙色
- 原色 Primary Colors
-
色彩三属性:色相、饱和度、明度
- 色相 Hue
简单来说,就是色轮上的12种颜色,如红色,黄色 - 饱和度/色度 Saturation
指某个颜色的强度,数值越高色彩越纯,低则逐渐变灰 - 明度/亮度 Value
指颜色的亮度:往一个颜色里加白色,明度就提高;反之加黑色,明度降低。两个极端就是黑、白两色
- 色相 Hue
-
RGB vs CMYK


色彩搭配
- 单色 Monochromatic

- 类似 Analogous
色轮上彼此相邻的颜色组成

- 互补 Complementary
色轮中完全对立的颜色为互补色

- 等边互补 Split Complementary
选择一种颜色,再在色轮上找出它正对面的互补色;
不直接使用这个互补色,而是使用该互补色两侧的颜色

基于数据的色彩选择
-
离散型色系 Diverging
两端颜色为互补色(如红色与绿色),中段颜色通常较浅;可以强调中间值域,并且使得两端的数据一目了然,适合偏重极值和中间值的数据

-
序列型色系 Sequential
一般是同一色调(Hue)的由浅及深或由深至浅;数值较小用浅色,较大用深色,适合单一主题、比重比较平均的数

-
分类型色系 Qualitative/Categorical
分类型的每种颜色都“各不相关”,采用不同色调;适合用来区分不同种类下的数据,如区分土地用途

-
ColorBrewer 演示



字体、排版
排版与字体基础
-
衬线、非衬线体
- Serif
- Sans Serif
-
空间:Kerning, Tracking...
- Kerning
- Tracking
-
排版原则
- 亲密性 Proximity
- 对齐性 Alignment
- 对比性 Constrast
- 重复性 Repitition
- 留白与“降噪”
阅读及资料
Markdown
资源列表
-
讲者
-
有关“量化”
-
不一样的信息来源
- 「后续」App
- 好奇怪 App, 好奇心日报
- 端传媒 Initium Media
- Matters 社区
-
可视化案例
-
The Economist, Graphic Detail
-
FlowingData http:www.flowingdata.com
-
Reddit 话题 dataisbeautiful
-
音乐
- Doodle Chaos Youtube 主页
- Nicholas Rougeux Youtube 主页, 作品之一卡农
- Giant Steps 爵士名曲“巨人脚步”可视化
-
情感
- Louise Ma, What Love Looks Like, See by Touch
- Lam Thuy Vo, Quantified Breakup
- Nicholas Felton, 个人数据可视化“鼻祖” annual personal reports 2005-2014
-
数据集
-
数据新闻公开课
Data Journalism and Visualization with Free Tools (10.14 - 11.24)
本周作业
- 用不同的可视化工具呈现同一个数据集
- 调研目前免费的可视化图表工具(国内外都得有,在线离线、交互静态都行)
- 在 Kaggle 选择一个公开数据集(可以只截取部分数据)
- 用你调研的图表工具(不少于3种)呈现上面选取的数据
- 在 markdown 里列出所选数据集、使用的工具及呈现,并附上使用体会
- 之前提交不规范,或还没掌握 markdown 基础的同学,修改已提交作业的 markdown 文档
- 按个人需求和计划,消化本周所列的链接内容,并注册公开课学习
数据的类型
- 定类/名义(nominal/categorical/set of characters):描述特征,不具有数值意义。如名字、性别、民族、车辆品牌、地点
- 定序(ordinal/sequence):分类和排序都有意义。如教育水平、问卷中的偏好程度等
- 定距(interval):没有绝对0点,数值间距相等,互相可以加减,但乘法无意义。如摄氏度、IQ
- 定比(ratio):有绝对0点(true/meaningful zero point),一个值是另一个值的倍数或比率,可计算差、中位数、均值等。如质量、高度、速度
- 离散(discrete):整数
- 连续(continuous):小数点位数没有限制
课堂练习
- “列”对应变量,“行”对应信息录入(columns for variables & rows for observations)
- 每一格应该只对应单一信息
- 命名时避免数值、空格和特殊字符,数值单位需指明
- “0”和“空白”的差异(0是数值,空白是null)

- 数据核验
- 输出时应导出为csv等通用格式
- 输出时应附上元数据(metadata: data about data)

- 提问:5W & H
- command+箭头
- 每一列记录的是什么信息?数据单位是什么?数据类型是什么?
- 每份数据应该有一个说明和元数据,找出数据背后的上下文
- 字符是英文还是中文,输入时有空格吗,有空白数据吗
- 练习2:2017年蔬菜产量最高的10个国家是?(数据:联合国粮农组织)
Excel 基础
- csv导入,文档编码与乱码 (tsv, fixed width)
- 冻结首排,开启过滤功能
- 排序(sorting)
- 过滤(filtering)
- 公式(functions)
- sum(), average(), median()
- upper(), lower(), proper()
- concatenate(), trim()
- left(), right()
- 数据透视表(pivot tables)
- Excel bugs:行数,日期
- 保存、保存、保存
- 记录每一步操作
- 数据备份,不更改原始数据(raw data)
- 如果已经有了机构的分析,依然要做完你自己的分析来核实
- 了解你的数据后再动手
- 和同仁交叉核对
- 如果条件允许,去实地调查数据是如何被收集及记录的
本周作业和阅读
- 搜索并阅读《上海市公共数据开放暂行办法》
- 搜索并回答:我国还有哪些关于公共数据开放的条例或法规?国内外有哪些政府开放数据平台?(markdown文档,列出信源和链接,包括👆🏻上海这个)
- 在国家统计局数据库找到全国GDP数据,回答:2012-2018年各季度GDP增速(列出选取的统计指标、数据页面、计算步骤及答案)
- 阅读👇🏻
阅读
- 高敏雪,《什么是政府统计》
- 任怡萌,《电子表格中的数据整理》
- Hadley Wickham, Tidy Data
- Ethan P. White, Nine simple ways to make it easier to (re)use your data
- Microsoft, Top ten ways to clean your data
数据的 5W & H
- 不管发布机构有多权威,数据都是可质疑的
- 人工会不同程度地参与数据整合过程,难免偏差与错误:To err is human.
- 永远检查数据集的元数据(Metadata)
个人数据的价值:Dear Data
Markdown 基础
- GitHub Pages 主题选择:https://pages.github.com/themes/
- Markdown Cheatsheet:https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet
- Markdown 教程:https://www.markdowntutorial.com/
本周作业
- 收集某个主题的个人数据,不限时间,规整为数据集
- 参考 Dear Data 的表现方式,拓展想象力
- 以手绘的形式呈现第一步收集的数据(无所谓美感,能展现想法为主),纸张大小 ≥ 明信片
- 以 markdown 文档形式记录自己的上述过程操作或感想
- 在同一个 markdown 文档里回答:你认为日常生活中哪些数据是被搜集的?被谁搜集了?
- 锻炼信息获取、辨别及核实的能力
- 锻炼数据处理及分析的能力
- 基本设计概念与图表制作
- 教学相长
- Excel, Ai, R, Sublime Text
- Data Journalism Handbook
- R Graphics Cookbook, 2nd edition
- Data + Design
- 平时作业 60%
- 期末项目 30%
- 课堂参与 10%
平时作业包含软件操作、信息搜集、数据申请或数据分析等。期末项目要求在与老师讨论后,独立完成一个以采访为基础、数据驱动、包含信息设计与呈现的作品。
- 数据获取难度高
- 数据处理和分析有明晰记录
- 视觉美感
- 援引内容不注明信源或链接
- 使用二手数据,未经核实的数据
- 信息获取方式不合伦理(如采访时没公开记者身份等)
- 编造信息或内容
- 大段改写或抄袭(包括设计抄袭)
- 缺勤6次以上
- 课堂上的拍照、录音和录像仅供个人学习使用,未经当事人书面允许请勿任意传播
- 互相尊重,不合适言行当面指出