

Rcrawler is an R package for web crawling websites and extracting structured data which can be used for a wide range of useful applications, like web mining, text mining, web content mining, and web structure mining. So what is the difference between Rcrawler and rvest : rvest extracts data from one specific page by navigating through selectors. However, Rcrawler automatically traverses and parse all web pages of a website, and extract all data you need from them at once with a single command.
For example collect all published posts on a blog, or extract all products data on a shopping website, or gathering all websites comments or reviews for your opinion mining studies.
More than that, Rcrawler can help you studies web site structure by building a network representation of a website internal and external hyperlinks (nodes & edges).
Help us improve Rcrawler by asking questions, revealing issues, suggesting new features. If you have a blog write about it, or just share it with your collegues.
👍 Thank you
☺️
To receive updates, tutorials ans annoucements, fill out this form

| Goal | Functions to use | Useful arguments |
|---|---|---|
| Retreive a web page | LinkExtractor | |
| Retreive a web page using a proxy | LinkExtractor | use_proxy |
| Retreive a web page and extract external links | LinkExtractor | ExternalLInks |
| Retreive a web page using a web driver, for javascript rendered web pages | run_browser, LinkExtractor | LinkExtractor(... Browser=) |
| Retreive a password protected web page (HTML-based authentication) | run_browser, LoginSession, LinkExtractor | LinkExtractor(... Browser=) |
| ------------ | ------------- | ------------- |
| Scrape one or many elements from a web page by XPath or CSS pattern (each element has one occurence in the page) | ContentScraper | XpathPatterns, CssPatterns, PatternsName |
| Scrape one or many elements from a web page by XPath or CSS pattern (each element can have many occurence in the page) | ContentScraper | XpathPatterns, CssPatterns, PatternsName, ManyPerPattern |
| Scrape data from multiple web pages/URLs having a commun extraction patterns (pages from the same website) | ContentScraper | Url= c("url1","url2") vector of URLs, XpathPatterns, CssPatterns, PatternsName. |
| Scrape data from pages using webdriver (for javascript rendered pages) | run_browser, ContentScraper | ContentScraper(... browser=) |
| Scrape data from password protected (HTML-based authentication) | run_browser, LoginSession, ContentScraper | ContentScraper(... browser=) |
| Scrape data from pages and transform it into a dataframe | ContentScraper | asDataFrame=TRUE |
| ------------ | ------------- | ------------- |
| Crawl and dowload all HTML pages of a specific website | Rcrawler | |
| Crawl and dowload and scrape data from HTML pages of a specific website | Rcrawler | ExtractXpathPat or ExtractCSSPat |
| Crawl, dowload/scrape all HTML pages of a specific website using a proxy | Rcrawler | use_proxy |
| Crawl and dowload/scrape all HTML pages of URLs gathered from the start page (crawl only the first level) | Rcrawler | MaxDepth=1 |
| Crawl the whole website but download/scrape only web pages whose URLs matches a specific regex pattern | Rcrawler | dataUrlfilter |
| Crawl and download/scrape only web pages whose URLs matches a specific regex pattern | Rcrawler | dataUrlfilter, crawlUrlfilter |
| Crawl and download/scrape webpages whose URLs retreived from a particular section of web pages (crawl links menu, pagination section, a specific URL list ..etc) | Rcrawler | crawlZoneCSSPat, crawlZoneXPath |
| Crawl/scrape a website search results | Rcrawler | dataUrlfilter, crawlUrlfilter, (crawlZoneCSSPat or crawlZoneXPath) |
| Crawl/scrape pages of a website with javascript rendred pages | Rcrawler | Vbrowser = TRUE |
| Crawl/scrape pages of password protected website | run_browser, LoginSession, Rcrawler | Rcrawler(... LoggedSession=) |
You have a huge website (over 50000 pages) and you are looking for some specific information to extract.
- First, try to limit your crawling by looking if your desired content is located under a specific section of the website.
- The second strategy is to use the website search field to look for what you need then, instead of providing the home page, use this search result page a start point for your crawling.
- If search option is not provided by the website, then you will make the half work manually. Start by looking for your target pages using google search :
Keywords+ site:https://targetwebsite.org
Then collect manually URLs from google result pages. Finally, use ContentScraper function to scrape all URLs at once (see 9-1).
With one single command Rcrawler function enables you to :
-
Download all website's HTML pages, (see 1)
-
Load collected HTML Files to R environement (memory) (see 2)
-
Extract structured DATA from all website pages: Titles, posts, Films, descriptions, products...etc (see 3)
-
Scraping targeted contents using search terms, by providing desired keywords Rcrawler can traverse all wbesite links and collect/extract only web pages related to your topic. (see 4)
Some websites are so big, you don't have sufficient time or ressources to crawl them, So you are only interested in a particular section of the website for these reason we provided some useful parameters to control the crawling process such as :
-
Filtering collected/scraped Urls by URLS having some keywords or matching a specific pattern (see 5)
-
Control how many levels Should be crawled from the start point .(see 6)
-
Choose to ignore some URL parameters during crawling process (see 7)
In Web structure mining field Rcrawler provide some starter kit to analyze the web site network.
- Represent a website Netwok by mapping all its internal and external hyperlink connections (Edges & nodes) (see 8)
In addtition, Rcrawler package provide a set of tools that makes your R web mining life easier:
-
Scrape data from a list of URLs you provide (see 9-1)
-
Exclude an inner element (node) from scraped data (see 9-2)
Other Examples :
- Crawl/Scrape IMDB website (see 10)
Install the release version from CRAN (Stable version):
install.packages("Rcrawler")
Or the development version from GitHub (may have errors):
# install.packages("devtools")
devtools::install_github("salimk/Rcrawler")
To show you what Rcrawler brings to the table, we’ll walk you through some use case examples: Start by loading the library
library(Rcrawler)
Rcrawler(Website = "http://www.glofile.com", no_cores = 4, no_conn = 4)
This command allows downloading all HTML files of a website from the server to your computer. It can be useful if you want to analyze or apply something on the whole web page (HTML file).
- no_cores specify how many processes will execute the task
- no_conn specify how many HTTP requests will be sent simultaneously (in parallel).
At the end of crawling process this function will return :
- A variable named "INDEX" in the global environment: It's a data frame representing the general URL index, which includes all crawled/scraped web pages with their details (content type, HTTP state, the number of out-links and in-links, encoding type, and level).

- A directory named as the website's domain plus current date and time, in this case, "glofile.com-101012" it's by default located in your working directory (R workspace). This directory contains all crawled and downloaded web pages (.html files). Files are named with the same numeric "id" they have in INDEX.

Note : Make sure that the website you want to crawl is not so big, as it may take more computer resources and time to finish. Stay polite, avoid overloading the server by using fewer connections, the chance of getting banned by the host server is higher when you are using many parallel connections.
After running Rcrawler command, Collected HTML web pages are supposed to be stored on your hard drive, In fact putting downloaded files directly into variables will consume the RAM, So, the crawler creates a folder for each crawling sessions with a name similar this pattern "website-DateTime" . To load collected files into a variable for processing or analysis, you will need to run these two functions: ListProjects and LoadHTMLFiles.
ListProjects()
Run this command to list all your crawling project folders. Then you just need to pick-up (copy) the project name you want. Then run the following command which will load all HTML into a vector.
MyDATA<-LoadHTMLFiles("forum.zebulon.fr-011925", type = "vector")
You can specify "list" as a type of returned variable. Also, this function has a parameter called (max) useful to limit the number of imported files.
In the example below, we will try to extract articles and titles from our demo blog. So each blog post normally has one title and one article. To do this we need to specify the XPath or the CSS selector pattern of the elements to extract.
Using XPath :
Rcrawler(Website = "http://www.glofile.com", no_cores = 4, no_conn = 4, ExtractXpathPat = c("//h1","//article"), PatternsNames = c("Title","Content"))
PatternsNames: No necessery but helps users identify extracted elements by checking the name of the object names(x).
Using CSS selectors :
Rcrawler(Website = "http://www.glofile.com", no_cores = 4, no_conn = 4, ExtractCSSPat = c(".entry-title",".entry-content"), PatternsNames = c("Title","Content"))
As result this function will return in addition to "INDEX" variable and file repository :
- A variable named "DATA" in global environment: It's a list of extracted contents. List of sublists, each sublist represent a web page and contain its extracted elements (title, content).

Note 1: By default Rcrawler will not collect nor scrape pages that do not contain any element matching the CSS or XPath pattern, As a result in the example below only article pages will be scrapped, categories or menu pages will be escaped.
Note 2: before using ExtractXpathPat or ExtractCSSPator on RCrawler function, try first to test your Xpath or CSS expression on a single webpage to ensure that they are correct, by using the ContentScraper function. Then check Data variable it should handle the extracted data, if it's empty or "NA", then no data founded matching the given patterns
Data<-ContentScraper(Url = "http://glofile.com/index.php/2017/06/08/athletisme-m-a-rome/", XpathPatterns =c("//h1","//article"))
OR using CSS selectors
Data<-ContentScraper(Url = "http://glofile.com/index.php/2017/06/08/athletisme-m-a-rome/", CssPatterns = c(".entry-title",".entry-content"))
Note 3:
- To learn how to make your Xpath expression follow this tutorial
- To easily identify your CSS expression followthis tutorial
Useful for extracting many elements having the same pattern from each page, like retrieving post comments, product reviews, movie cast, forums replies, the listing of something or even pages hyperlinks.. etc. To enable this option, we need to set ManyPerPattern parameter to TRUE.
Retreive hyperlinks :
Another way to scrape all href urls on each page of this website.
- Retrieve all links from a one or multiple specific pages
links<-ContentScraper(Url = "http://glofile.com/2017/06/08/placements-quelles-solutions-pour-doper/",
XpathPatterns = "//*/a/@href" ,
ManyPerPattern = TRUE)
- Retrieve all links from the whole website
Rcrawler( Website = "http://glofile.com/",
ExtractXpathPat = "//*/a/@href",
ManyPerPattern = TRUE)`
# Put all links together within one vector
Allinks<-unlist(lapply(DATA, `[[`, 2))
By default, extracted data are sotred in a List variable named DATA, It's a list of sublists where each sublist handles extracted elements from one page.
- To get all first elements of the lists in one vector (example all titles) :
VecTitle<-unlist(lapply(DATA, `[[`, 1))
- To get all second elements of the lists in one vector (example all content)
VecContent<-unlist(lapply(DATA, `[[`, 2))
- Tranform DATA list into Dataframe
df<-data.frame(do.call("rbind", DATA))
To crawl a website and collect/scrape only some web pages related to a specific topic, like gathering posts related to Donald trump from a news website. Rcrawler function has two useful parameters KeywordsFilter and KeywordsAccuracy.
KeywordsFilter : a character vector, here you should provide keywords/terms of the topic you are looking for. Rcrawler will calculate an accuracy score based on matched keywords and their occurrence on the page, then it collects or scrapes only web pages with at least a score of 1% wich mean at least one keyword is founded one time on the page. This parameter must be a vector with at least one keyword like c("mykeyword").
KeywordsAccuracy: Integer value range between 0 and 100, used only in combination the KeywordsFilter parameter to determine the minimum accuracy of web pages to be collected/scraped. You can use one or more search terms; the accuracy will be calculated based on how many provided keywords are found on on the page plus their occurrence rate. For example, if only one keyword is provided c("keyword"), 50% means one occurrence of "keyword" in the page 100% means five occurrences of "keyword" in the page
Given the text :
D<- " key2 text text text text text text text text text text key1 key1 key1 key1 key1"
- If KeywordsFilter="key1" result is 100%
- If KeywordsFilter="key2" result is 50%
- If KeywordsFilter=c( "key1","key2") result is 75% from 100/2+50/2
- If KeywordsFilter=c( "key1","key2", "key3") result is 50% from 100/3+50/3+0
Rcrawler(Website = "http://www.example.com/", KeywordsFilter = c("keyword1", "keyword2"))`
Crawl the website and collect only webpages containing keyword1 or keyword2 or both.
Rcrawler(Website = "http://www.example.com/", KeywordsFilter = c("keyword1", "keyword2"), KeywordsAccuracy = 50)
Crawl the website and collect only webpages that has an accuracy percentage higher than 50% of matching keyword1 and keyword2.
Rcrawler(Website = "http://www.master-maroc.com", KeywordsFilter = c("casablanca", "master"), KeywordsAccuracy = 50, ExtractXpathPat = c("//*[@class='article-content']","//*[@class='contentheading clearfix']"))
This command will crawl http://www.master-maroc.com website and looks for pages containing keywords "casablanca" or "master" , then extract data matching the given XPaths ( title , article) .
For some reason, you may want to collect just web pages having a specific urls pattern , like a website section, posts webpages. In this case, you need filter urls by Regular expressions .
In the example below we know that all blog post has dates like 2017/09/08 in their URLs so we can tell the crawler to collect only these pages by flitging only URLs matching this regular expression "/[0-9]{4}/[0-9]{2}/[0-9]{2}/". Ulrs having 4-digit/2-digit/2-digit/, which are blog post pages in our example .
Rcrawler(Website = "http://www.glofile.com", no_cores = 4, no_conn = 4, dataUrlfilter ="/[0-9]{4}/[0-9]{2}/[0-9]{2}/" )
Collected pages are like :
http://www.glofile.com/2017/06/08/sondage-quel-budget-prevoyez-vous
http://www.glofile.com/2017/06/08/jcdecaux-reconduction-dun-cont
http://www.glofile.com/2017/06/08/taux-nette-detente-en-italie-bc
In the following example we crawl and collect only pages in section "sport" in url.
Rcrawler(Website = "http://www.glofile.com/sport/", dataUrlfilter ="/sport/", crawlUrlfilter="/sport/" )
Downloded/Extracted Pages are like :
http://www.glofile.com/sport/marseille-vitoria-guimaraes.html
http://www.glofile.com/sport/balotelli-a-la-conclusion-d-une-belle.html
http://www.glofile.com/sport/la-reprise-acrobatique-gagnante.html
Note:
Provide dataUrlfilter only, means that the crawler will follow all website links but will collect/scrape only web pages whose Urls matching regex pattern.
Provide crawlUrlfilter means that the crawler will follow only links matching regex pattern
In this example, we will try to collect pages from a website search result.
Result pages are like:
http://glofile.com/?s=sur
http://glofile.com/page/2/?s=sur
http://glofile.com/page/2/?s=sur
*They all have "s=sur" in common
Post pages should be crawled an collected, post urls are like
http://glofile.com/2017/06/08/placements-quelles-solutions-pour-dper/
http://glofile.com/2017/06/08/taux-nette-detente/
*Post urls are distinguished by a date in URLS matching a regex "[0-9]{4}/[0-9]{2}/[0-9]{2}
Rcrawler(Website = "http://glofile.com/?s=sur", no_cores = 4, no_conn = 4,
crawlUrlfilter = c("[0-9]{4}/[0-9]{2}/[0-9]{2}","s=sur"),
dataUrlfilter = "[0-9]{4}/[0-9]{2}/[0-9]{2}")
Follow links like "[0-9]{4}/[0-9]{2}/[0-9]d{2}" or "s=sur" and collect/scrape links like "[0-9]{4}/[0-9]{2}/[0-9]{2}"
Note that Post links retreived from post page will be also collected, like "related posts", "see more","recent post" .. because they are matching same regex, so to limit crawling only on result pages section will use crawlZoneCSSPat arguments.
Rcrawler(Website = "http://glofile.com/?s=sur", no_cores = 4, no_conn = 4,
crawlUrlfilter = c("[0-9]{4}/[0-9]{2}/[0-9]{2}","s=sur"),
dataUrlfilter = "[0-9]{4}/[0-9]{2}/[0-9]{2}",
crawlZoneCSSPat = "body[class^='search'] main#main")
Some popular websites are so big, and you don't have time or dedicated ressources to crawl the whole website, or for some specific reason you may just need to crawl the top links of a given web page. For this purpose, you could use Maxdepth parameter to limit the crawler from going so deep. Example: A(B,C(E(H),F(G,k)),D) . Page A links to B, C, D ; Page C links to E and F, page F links to G and K and page E links to H, In this example A is level 0 ,C represend Level 1 and E,F are both level 2 .
Rcrawler(Website="http://101greatgoals.com/betting/" ,MaxDepth=1)
This command will parse only pages related to this link http://101greatgoals.com/betting/ (only links on that page)
Rcrawler(Website="http://101greatgoals.com/betting/" ,MaxDepth=4, crawlUrlfilter = "/betting/")
In this example the crawler start from this http://101greatgoals.com/betting/ and continue crawling until it reach the 4th level , however it will only collect pages of "betting" section ( having /betting/ in their url)
URL parameters are made of a key and a value separated by an equals sign (=) and joined by an ampersand (&). The first parameter always comes after a question mark in a URL. For example, http://example.com?product=1234&utm_source=google
There are many URL parameters that produce the same content, such as view=, display=, template= which change de display, the style of a web page but not the content. Another example is orderby= which change the order of a list but not the list itself, also replytocom for replaying to post comments . The crawler takes these pages as unique because they have different URLs which may lead to much duplicate content.
To ignore one or more URL parameters use ignoreUrlParams argument .
Rcrawler(Website = "http://forum.zebulon.fr/forums-de-zebulonfr-f30.html",no_cores = 2, no_conn = 2, ExtractCSSPat = c(".ipsType_pagetitle",".entry-content"), ManyPerPattern = TRUE, ignoreUrlParams =c("view","orderby"))
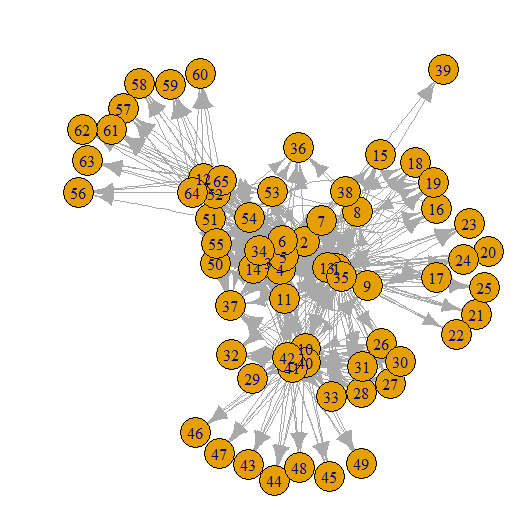
This option allows you to create a network representation graph of a website. This feature can be useful for Web structure mining.
Set NetworkData parameter to TRUE then Crawler will create two additional global variables handling Edges & Nodes of the website:
- NetwIndex : Vector maps alls hyperlinks (nodes) to unique integer ID (element position in the vector)
- NetwEdges : data.frame representing edges of the network, with these columns: From, To, Weight (the Depth level where the link connection has been discovered) and Type (number 1 for internal links, number 2 for external links).
Rcrawler(Website = "http://glofile.com/", no_cores = 4, no_conn = 4 , NetworkData = TRUE, NetwExtLinks =TRUE, statslinks = TRUE)
statslinks argument is optional, it counts for each page the number of inbound links. This command crawl our demo website, and create network edges data of internal links. Using Igraph library you can plot the network by the following commands (you can use any other library):
library(igraph)
network<-graph.data.frame(NetwEdges, directed=T)
plot(network)

To include external links in network representation , set NetwExtLinks parameter to TRUE
Rcrawler(Website = "http://glofile.com/", no_cores = 4, no_conn = 4 , NetworkData = TRUE, statslinks = TRUE)
After plotting we get this representation
If you have already a list of links of the same website and you want to scrape all of them at once. Use ContentScraper function which can process one or more urls. In the example bellow we collect reviews of 3 cosmetic product.
listURLs<-c("http://www.thedermreview.com/la-prairie-reviews/",
"http://www.thedermreview.com/arbonne-reviews/",
"http://www.thedermreview.com/murad-reviews/")
Reviews<-ContentScraper(Url = listURLs, CssPatterns =c(".entry-title","#comments p"), ManyPerPattern = TRUE)
ExcludeXpathPat or ExcludeCSSPat are two arguments that let you exclude some part from extracted contents. In fact in some cases Css or Xpath patterns extract some data that you don't want, which you can't exclude by pattern, such as excluding quotes from forum replies or excluding middle ads or links from Blog posts. These two parmaters are also implemented in Rcrawler function.
DATA<-ContentScraper(Url = "https://bitcointalk.org/index.php?topic=2334331.0", CssPatterns = c(".post"), ExcludeCSSPat = c(".quote",".quoteheader"), PatternsName = c("posts"), ManyPerPattern = TRUE)
From this Forum post Url we want to extract post title and all replies using CSS selectors c(".post"), However, we notice that each reply contain the previous reply as quote so we to exclude all quotes and quotes header (published by,date and time) from each extracted posts we use ExcludeCSSPat c(".quote",".quoteheader a")
- crawlUrlfilter ="/title/" : crawl only movie pages
- dataUrlfilter = "/title/" : collect only movie pages
- MaxDepth = 1, : only links extracted from the start pages
Rcrawler(Website = "https://www.imdb.com/list/ls027433291/" , no_cores = 4, no_conn = 4,
MaxDepth = 1, dataUrlfilter = "/title/", crawlUrlfilter ="/title/")

Tuto 10-2: crawl, collect and scrape all best imdb 2018 movies to extract their (title, Summarie and score).
- crawlUrlfilter ="/title/" : crawl only movie pages
- dataUrlfilter = "/title/" : collect only movie pages
- MaxDepth = 1, : only links in the start pages
- ExtractCSSPat : the desired DATA patterns
Rcrawler(Website = "https://www.imdb.com/list/ls027433291/" , no_cores = 4, no_conn = 4,
MaxDepth = 1, dataUrlfilter = "/title/", crawlUrlfilter ="/title/",
ExtractCSSPat =c("div.title_wrapper>h1", "div.summary_text","span[itemprop^='ratingValue']"),
PatternsNames =c("Title","Summary","Score"))
Transfom DATA list into Dataframe
df<-data.frame(do.call("rbind", DATA))

As you can see there are duplicated movies line, because they have different urls so to remove duplicates we need to ignore all URLs paremeters which makes Urls looks different despite they are similar .
Tuto 10-3: crawl, collect, and scrape all best imdb 2018 movie's pages and extract their (titles, Summaries and scores) without taking into account Url parameters
- ExtractCSSPat is the pattern of data to be scraped
- ignoreAllUrlParams = TRUE, remove duplicate elements by ignoring all URL parameters
Rcrawler(Website = "https://www.imdb.com/list/ls027433291/" , no_cores = 4, no_conn = 4,
MaxDepth = 1, dataUrlfilter = "/title/", crawlUrlfilter ="/title/",
ExtractCSSPat =c("div.title_wrapper>h1", "div.summary_text","span[itemprop^='ratingValue']"),
PatternsNames =c("Title","Summary","Score"), ignoreAllUrlParams = TRUE)
df<-data.frame(do.call("rbind", DATA))
Tuto 10-4: crawl, collect, and scrape all best imdb 2018 movie's pages and extract their (title, Summarie scores and Cast overview which is a list of actors)
- ManyPerPattern = TRUE enable extracting multiple elements for each pattern
Rcrawler(Website = "https://www.imdb.com/list/ls027433291/" , no_cores = 4, no_conn = 4,
MaxDepth = 1, dataUrlfilter = "/title/", crawlUrlfilter ="/title/",
ExtractCSSPat =c("div.title_wrapper>h1", "div.summary_text",
"span[itemprop^='ratingValue']","table[class='cast_list'] td:nth-child(2) a"),
PatternsNames =c("Title","Summary","Score","cast overview"), ManyPerPattern = TRUE,
ignoreAllUrlParams = TRUE)
df<-data.frame(do.call("rbind", DATA))

Tuto 10-5: crawl, collect, and scrape (titles, Summaries, scores and Cast overview ) from movies wich have and imdb rating superior to 7.0
Thus, we need to use a custom filter to scrape only pages having rating 7.0
The custom function must take one argument X (returned by Linkextractor function) and then return a boolean value TRUE/FALSE
ratingcondition<- function(x){
decision<-FALSE
rating<-tryCatch(ContentScraper(HTmlText = x$Info$Source_page,CssPatterns = "span[itemprop^='ratingValue']")[[1]][[1]],
error=function(e) NULL)
rat<<-rating
if(!is.null(rating) && !is.na(rating)) {
if((as.double(rating))>7) decision<-TRUE
}
decision
}
Rcrawler(Website = "https://www.imdb.com/list/ls027433291/" , no_cores = 4, no_conn = 4,
MaxDepth = 1, dataUrlfilter = "/title/", crawlUrlfilter ="/title/",
ExtractCSSPat =c("div.title_wrapper>h1", "div.summary_text",
"span[itemprop^='ratingValue']","table[class='cast_list'] td:nth-child(2) a"),
PatternsNames =c("Title","Summary","Score","cast overview"), ManyPerPattern = TRUE,
FUNPageFilter = ratingcondition, ignoreAllUrlParams = TRUE )
df<-data.frame(do.call("rbind", DATA))

Some tutorials on indeed jobs website
Collect job pages from indeed search results of keyword "data analyst"
Rcrawler(Website = "https://www.indeed.com/jobs?q=data+analyst&l=Tampa,+FL", no_cores = 4 , no_conn = 4,
crawlUrlfilter = c("/rc/","start="), dataUrlfilter = "/rc/",
crawlZoneCSSPat = "td#resultsCol"
)
If you want to learn more about web scraper/crawler architecture, functional properties and implementation using R language, you can download the published paper for free from this link : R web scraping
Our paper is submitted, you can cite our work
Khalil, S., & Fakir, M. (2017). RCrawler: An R package for parallel web crawling and scraping. SoftwareX, 6, 98-106.
@article{khalil2017rcrawler, title={RCrawler: An R package for parallel web crawling and scraping}, author={Khalil, Salim and Fakir, Mohamed}, journal={SoftwareX}, volume={6}, pages={98--106}, year={2017}, publisher={Elsevier} }
Upcoming updates :
- json + rss parser
- automatic extraction of article, table, lists
- crawl a list of websites
- content detection
UPDATE V 0.1.9 :
- Enhance LinkNormalization function
- Crawl and scrape javascript rendered web pages using phantoms js web driver
- Crawl and scrape password protected web pages
- Detect consecutive 304 errors and throw a warning message
- add saveonDisk paremeter to Rcrawler
- auto-loging if singout
- Improved documentation
- improve package code
- ignore all url parameters during crawling
Arguments added to Rcrawler
- use_proxy using proxy in crawling
- crawlUrlfilter filter urls to be crawled
- dataUrlfilter filter urls to be collected
- crawlZoneCSSPat and crawlZoneXPath Pattern of sections from where the crawler should gather links to be crawled
- Vbrowser use a webdriver to crawl website
- LoggedSession use a logged in session to crawl password protected pages
Fixed error :
- Fix character encoding in saved HTML files
UPDATE V 0.1.8 :
- Improve crawling algorithm to overcome the slowness over 30000 crawled URLs
- Fix some reported errors
UPDATE V 0.1.7 :
- Improve encoding detection
- Extract data using CSS selector
- Project folder name contain domain,day,time to avoid overriding previous crawling session.
- Include external links to network edges presentation
- The ability to filter out pages to collect using your custom function (prediction, calssification model)
- Scrape a list of URLs at once using contentscraper function
- Ability to Exlude some node from extracted content (like excluding quotes from forum post replies or excluding middle ads from Blog post)
- Add function to List projects folders and Other to Import collected Html from folder to environement
UPDATE V 0.1.5 - 0.1.6 :
- NetworkData parameter: Map all internal hyperlink connections within a given website and then construct Edges & Nodes Dataframe, Useful for Web structure mining.
- When scraping a website with a given xpath patterns, the crawler avoid scraping and extracting data from non-content pages ( webpages that does not matches any given pattern)
- ManyPerPattern: Extract All nodes matching a specific pattern from every scraped page useful for scraping reviews, comments, product listing etc..)
- MaxDeph params issue fixed
UPDATE V 0.1.3 :
- Support HTTPS protocol
- Scraping web pages by term search using keywords matching.
- Fixing the subscript out of band error
UPDATE V 0.1.2 :
- Fixing some issues opened on GitHub
- Drop simhash duplicate detection using java call due to many problems loading the package and rjava environment for many users.
UPDATE V 0.1.1 :
- Fix an issue in some examples (ignore special character which affected generated PDF )
- Add SystemRequirements field to Description with Java (>= 1.5)
- Compile java classes with a lower JDK (1.5), to overcome this error (Unsupported major.minor version 52.0) encountered during package check with r-patched-solaris-x86 and r-oldrel-osx-x86_64
To extract needed data , we start with selectorgadget to figure out which css selector matches the data we want (If you haven’t heard of selectorgadget, it’s the easiest way to determine which selector extracts the data that you’re interested in) . You can use it either by installing the Chrome Extension or drag the [bookmarklet] to your bookmark bar, then go to any page and launch it. Make sur you see this tutorial video on how to get css seletor using selectorgadget .
- First learn these expressions
| Expressions | Description |
|---|---|
| nodename | Selects all nodes with the name "nodename" might be div, table, span,tr,td, h1 ..etc |
| / | Selects from the root node |
| // | Selects nodes in the document from the current node that match the selection no matter where they are |
| . | Selects the current node |
| .. | Selects the parent of the current node |
| @ | Selects attributes |
-
Start your browser Chrome or Firefox, then open your target web page sample to extarct, assume we want to extract this movie cast http://www.imdb.com/title/tt1490017/
-
If you are using chrome, then right-click on one of the elements you want then select "Inspect" you shoud have a view similar to this one
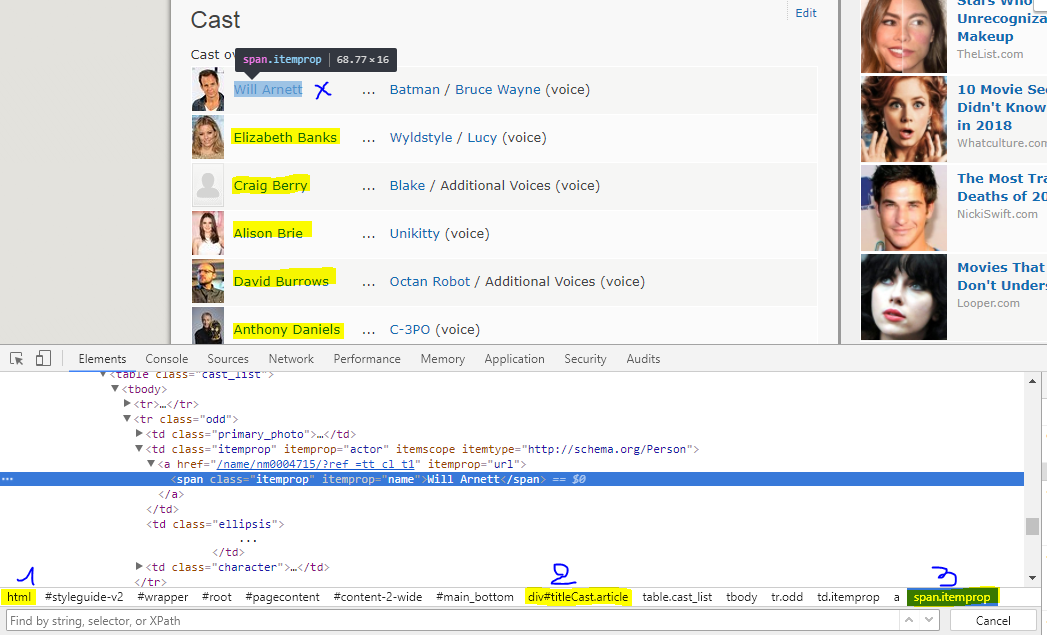
4- Hit Ctrl+F you shoud see a search field appear at the bottom of the page, its where you shoud first write and test your xpath expression, Above the field, there is an important list of elements all started with # all those node#class represents the way from the document root to the element you have selected. We picked up three of them to build our xpath (1 2 3 marked in yellow).
- Then we try to build and expression from those nodes :
//*/div[@id='titleCast']//span[@class='itemprop']
This expression means : We look for any span with class='itemprop' no mather what they are BUT located under a div[@id='titleCast']
- At the end after writing your expression on the xpath search field, you shoud see how many nodes are founded. If no one match your expression then try to fix it out until you get some result.

If you got the forllwing error, this means that your operating system or antivirus #' is bloking the webdriver (phantom.js) process, try to disable your antivirus temporarily or #' adjust your system configuration to allow phantomjs and processx executable (\link{browser_path} #' to know where phantomjs is located). #' Error in supervisor_start() : processx supervisor was not ready after 5 seconds.
web crawler r web scraper r web scraping r web crawling r r r studio language r tutorial through r pdf example r package in r r tutorial create in r in r tutorial code in r using r with r r course r cran r code com r crawler curso r r datacamp scraping web data r scrape web data r r dropdown en r examples r using r examples web scrape table in r json r r javascript web scrape r javascript using r javascript r language loop r library r multiple links r r library web scrape r link on r scrape web page r sous r sur r using r studio tutorial using rvest simple using r using r pdf tripadvisor using r web page scraping using r with r studio with r and phantomjs facebook fr r wikipedia with r examples with r selenium with r datacamp with r analytics vidhya twitter with r linkedin with r amazon with r javascript with r with r tutorial pdf r multiple web pages rss research papers ruby on rails avec r analytics vidhya r amazon advanced r a table r r and api r automated r r append a web page in r r bloggers r book by r r basics r click button r click r cookies rapidminer r example en español r fill form en français for r yahoo finance r code for r r download files r github r google r html r httr en html r https html in r r imdb studio password beginners guide on in r rvest book datacamp vs python multiple pages code package programming tables
web page scraping in r en java r java r multiple pages with selenium mit r r packages r phantomjs r pdf r programming r proxy dynamic pages with r r project en python en php web page scraping r parallel r using r programming password protected r simple in r r table scraping web data with r rvest easy with r r xml r xpath robot.txt research paper research paper pdf review