İlk öncə simple CPU design formasından başlayacayıq. CPU-a aid əsas componentləri hazırlayacayıq MMU, ALU, Interrupt controller, ISA (Instruction Set Architecture) etc.
Maintainer: [email protected] (Emin Ghuliev)
| Title | Session |
|---|---|
| CPU Design (Session 1) | Link |
- ALU (Arithmetic logic unit) ALU-nu burada RTL (Register-transfer level) level hazırlayacayıq mümkün qədər logic-gate (transistor-level) az toxunmağa çalışacam. Çünki burda əsas məqsəd ALU işləmə prinsipini anlamağdır.
- MMU (Memory management unit) Memory management unit üzərində əgər mümkün olsa real mode və protection mode hazırlayıb göstərəcəm (x86 model) Məsələn x86 virtual adres müraciətində adres translate necə edir daha sonra TLB inteqrasiyası. Əslində çalışacam daha çox x86 modelinə oxşadaq ancaq digər arxitekturalardaki işləmə prinsiplərinidə istifadə edə bilərik.
- İnterrupt Controller External və software interrupt-ları inteqrasiya edəcəyik. External interrupt-ları ola bilərki spesifik FPGA device üzərində inteqrasiya etdik çünki burada external interrupt eventi lazımdır bizə. Ancaq software interrupt-ları simulator üzərində yazacayıq.
- İSA (İnstruction set architecture)
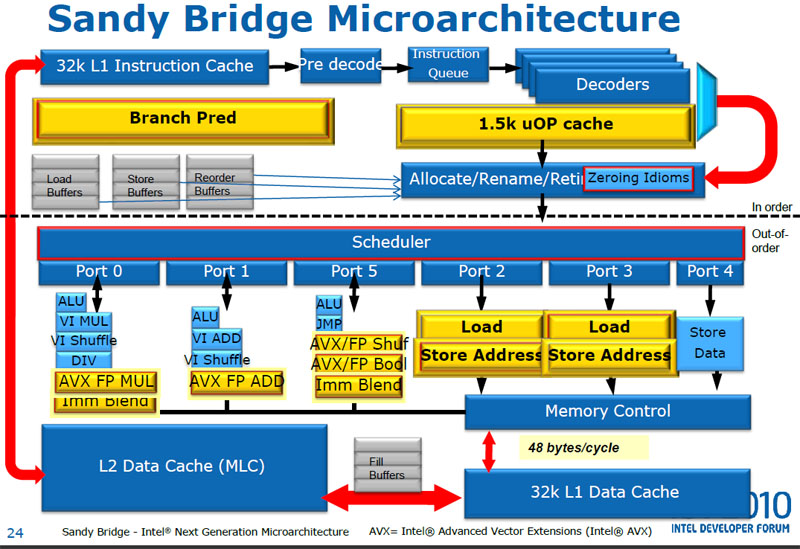
Əsas stage burada yerləşir instruction-larımız bu stage-də icra ediləcək. İlk öncə Single-cycle instruction cycle yazacayıq daha sonra multi-cycle yazacayıq. Ən sonda isə Pipeline execution sistemini hazırlayacayıq modern sistemlərin istifadə etdiyi kimi. Burada superscalar execution, register renaming (tomasulo algorithm), dynamic scheduling, branch prediction kimi mexanizmləri analiz və tətbiq edəcəyik. Həmçinin bəzi akademik paper-lərdəki texnikalarıda tətbiq edib performans analizləri aparacayıq #6 (An optimizing pipeline stall reduction algorithm for power and performance on multi-core CPUs). İntel prosessorunu tam inteqrasiya edə bilməsəkdə bəzi komponentləri yazmağa çalışacayıq. Mümkün olarsa İntel prosessorundaki bəzi modern komponentləri (e.g line-fill buffer, store and load buffer) patentlərdən baxıb reverse edərək inteqrasiya etməyə çalışacayıq #9. Əgər biz out-of-order execution hazırlayacağısa modern prosessordakı bəzi komponenlər bizə lazım olacaq load və store buffer kimi çünki instruction cycle-da branchın direction-ı bilinməmiş biz məlumatı yaddaşa yaza bilmərik bu halda bizə in-flight buffer lazımdır (Haswell microarchitecture diagramında qeyd olunub).
Cache locality, branch predictor etc. for programmer.
Bəzi data strukturlar üzərindən proqramçılara marağlı olacaq mövzulara toxunacayıq məsələn Binary search istifadə etdiyimiz zaman branch predictor-da yaranan miss-lər onun qarşısnı almaq üçün alternativ instructionların istifadə edilməsinə baxacayıq. Keçmiş təcrübəmdə əgər mümkündürsə bəzi basic blocklarda branch instruction-larını eliminate etmək üçün kiçik compiler yazmışdım:
val = middle < left ? left : right;Bu halda biz davam edən instruction cycle-da heçbir jumpingə ehtiyyac duymuruq. x86 modelində setb instruction ilə cmp instruction icrasından sonra jg,je etc. əvəzinə sadəcə flag-ları check edib qərar verə bilərik. Bunuda əgər mümkün olsa göstərməyə çalışacam. Bu proqramçılar üçün çox önəmlidir və bir çox xarici intervyularda bu suallar düşür. Başqa bir məsələ isə Cache locality-dir əgər biz caching tətbiq etsək burada 2 əsas reference locality üzərində dayanacayıq.
- Temporal
- Spatial Əsas binary search və B-tree üzərində Spatial cache localityə baxa bilərik ki, məsələn əgər biz yaddaşda random yerlərə müraciət ediriksə bu cache miss-ləri çoxalda bilər çünki cache design-ı zamanı baxacayıq ki bizim Cache line 64 baytdır. Yəni biz bir adrese müraciət zamanı CPU müraciət etdiyimiz adresdən sonraki 64 baytıda cache-ə əlavə edir ki daha sonra müraciət zamanı məlumat orada olsun. Əgər bu halda biz daha çox yaxın adreslərə müraciət etsək cache miss daha azalda bilərik. (Bu texnikalar daha çox machine learning alqoritmlərində istifadə edilir.).
Daha sonra isə modern İntel prosessorunu reverse edib bəzi komponentləri yazmağa çalışacayıq (Prefetcher, Caching etc.). İntelin i8080A prosessorunun silicon die modeli artıq reverse edilib #8. Həmçini gate level modelidə çıxarılıb:
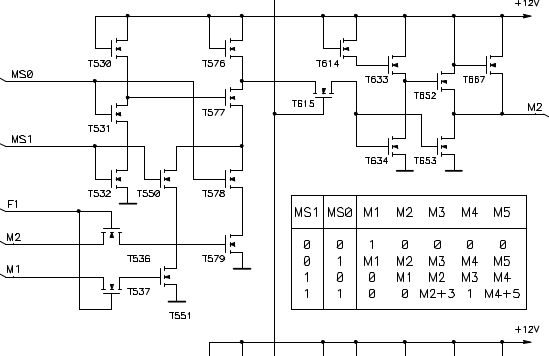
Əgər mümkün olsa transistor connectivity ilə bunları Verilog-a yaza bilərik.
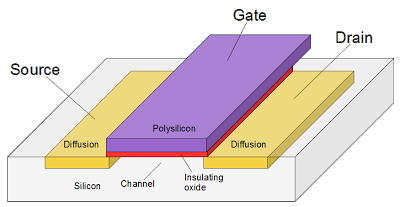
Daha sonra əgər mümkün olarsa silicon level reversing məsələsinidə baxa bilərik. Silicon Die üzərindən bəzi prosessorları (CMOS, TTL, RTL) necə reversə edə bilərik:
https://www.realworldtech.com/wp-content/uploads/2012/11/haswell-5.png
{kind=link}
Ardı var...

Bu seriyada həmçinin fərqli Hypervisor, Network development (BGP, OSPF, VRRP etc.), Microarchitectural algorithm analysis mövzularına toxunacam;
| Title | Session |
|---|---|
| Hypervisor/Containerization architecture/development (Docker, Kubernetes, Firecracker etc.) | Link |
- https://www.chipverify.com/verilog/verilog-introduction
- https://en.wikipedia.org/wiki/Field-programmable_gate_array
- https://en.wikipedia.org/wiki/Verilog
- https://en.wikipedia.org/wiki/Hardware_description_language
- https://en.wikipedia.org/wiki/Register-transfer_level
- https://link.springer.com/article/10.1186/s13673-014-0016-8
- Compiler Principles and Design in Verilog HDL (2015) - Book
- https://github.com/1801BM1/vm80a/
- https://patents.google.com/patent/US5367660A/en
- https://en.wikipedia.org/wiki/Logic_synthesis
- https://en.wikipedia.org/wiki/Lookup_table
- https://riscv.org/
- https://www.amazon.com/Computer-Organization-Design-RISC-V-Architecture/dp/0128122757