[email protected] - Zunda Krastmala 10 room 410
Course work
- laboratory works as hometasks - 40%
- video lectures
- online tests
- exam 60%
- Online tests sometimets to earn more points. (~5 tests)
grade = 0.4*course_work+06*exam+bouns only if 0.4*course_work+0.6*exam>=4
lectures:
- 12:30-14:05
- 14:30-16:05
mandatory tasks:
- 5 labs - min 2
- large set of practical problems
- tasks
- do the task with the packaged software, create a report
- laboratory works:
- intelligent agents
- 4 points
.net
- search
- 4 points
- java
- planning agents
- java
- inductive learning
- java
- complex decision making
- .net
- intelligent agents
points scored grade
at least 12 10
10 to 12 9
9 to 10 8
8 t 9 7
... ...
deadlines
- fst deadline: april 3
- all other semester work: may 22
- extended deadline, without feedback: may 30
text books:
- Russel S and Norvig: Artifcial Intelligence
objective strengthen theoretical knowledge about modern approaches of artificial intelligence acquired at the lectures of the course
- those unknown pocesses with which our brains solve problems ~ Minskiy
- the definition change through the years, which makes it difficult to explain
roots of AI:
- philosophy
- how the world works
- what we think about something
- mathematics
- formal logic
- algorithms -
- psychology
- behaviorism
- cognitive science
- neuroscience
- economics
- decision theory, utility theory
- game theory
- computer science (1940- about this part of computing)
- efficient computer
- linguistics
- natural language processing
The mind is something behind the machine
If you look at the mind as a machine then you can replicate it. If you look the emotional beeing behind the mind then you will see emotions, feelings, free will, etc, and we can't replicate them.

- Turing test
- rational agent aproach
- the agent is just something that acts
- a rational agent acts like the best outcome
- view of intelligence
- collective behaviors
- agennt -oriented and emergent view of intelligence
- autonoumus systems
- agents situted in enviroment
presentation: slidetodoc.com
Agent is just something that perceives and acts. Functions: mapping percepts to actions.
An agent is anything that can be viewed as perceiving its anviroment through sensors and acting upon that enviroment through effectors
based on this definitoin a termostat is an intelligent agent
properties of intelligent agents:
- the capability to follow the enviroment all the time, including during the reasoning and acting
- the agent must take an action when the action is meaningful
the agent coióntinues to learn uppon its experience
- one whose actions are not based completly on:
- built-in knowledge
- own experience
- truly autonoumus agent can adapt to wide variety of enviroments
- can interact with other agents
- agents can work together => multi agent system
- viewed as consisting of mental components such as: beliefs, capabilities, choices, commitments
- an entity is a software agent if and only if it communicates correctly in an agent communication language

- does the right thing
- the best available action
- rational: performande, percept sequence, knowledge about the enviroment, actions
- ideal rational
- omniscient <- knows everything
- to determine if the agent does right things
- outside the agent <- to be more objective valuation
- is defined by some authority
- how and wen to evaluate agents success
An agent is a proram and an architecture
- percepts
- actions
- goals
- enviroment
PEAS/PAGE description - Performance enviroment actuators and sensors / percepts actions goals environment
| Agent | Performance | Enviroment | Actions | Sensors |
|---|---|---|---|---|
| Interactive English tutor | Maximie scored in the test | Student group | Witten tasks | written words |
| automated taxi driver | safe, fast, legal trip, maximal profit | Roads, other traffic, pedestrians, customers | Steering, accelerator, brakes, signal | cameras sonar, speedometer |
| Medical diagnosis system | Healthy patioents minimal costs | patients, hospital staff | questions, tests, treatments | symptoms, patent answers |
enviroments
- the range can be vast
- there are some dimensions that categorize enviroments
- characteristics:
- observability
- fully observale: agents sensors give access to compplete state of the enviroment
- effectively fully observe: detect everthing which is relevant to me now
- partially observable: noisy or inaccurate sensors or parts of the state are missing ins sensors sdata *ex: vacuum cleaner can not perceivve dirt in another room
- unobservable: agent has no sensors at all
- deterministics vs stochastic:
- deterministic: next state the enviroment is completly determinated by current state and action executed by the agent
- stochastic: uncertainity about outcomes is quantified in terms of probabilities
- episodic vs sequnetial
- episodic: the experience is divided in atomic episodes
- episode: an agent recieves a percept and performs a single action
- epsodes do not depend on actions taken in prev episodes
- calssification tasks
- sequnetial: current decision can be larger
- episodic: the experience is divided in atomic episodes
- single vs multi-agent
- single: only on agent ex: agent solving crosswqord puzzle
- multi-agent: there are other agents maximizin a performance measure that depends on the behavior of other one ex: chess
- static vs dynamic
- known vs unknown:
- in known enviroment the designe knows the laws of physics ex: the outcome probability of actios is known
- unknown: the agent has to learn how the enviroment works: ex an unkown video game, wher don't know how to solve/use it
- observability
the skeleton of agent:
- choose best action
- action: update memory
- return: action
table driven agent:
- percept sequneces: look-up percepts, table
- return action
rule based agent:
- percept: interpretation
- rule match: interpreted percept, if pattern
- rule firing: then pattern
- action: return actrion
applications in lgoical reasoning systems

model based agent
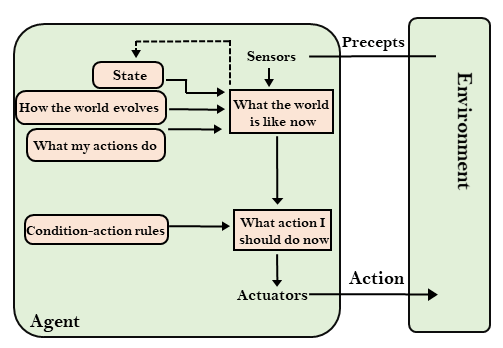
goal based agent
- goal
- interface
- search and planning
utility agent
- utility function assigs a real number starting how good the state is for the agent
- the higher the utility is the better the state is for the agent
compare performance of differen computer agent types with human agents that have the same information as the computer agents
The objective of the laboratory work is to study behaviour of different types of intelligent agents on the example of vacuum cleaning agent. The following types of agents are used in experiments: global optimization agent, local optimisation agent and random choice agent. Results achieved by human agent and computer agent must be compared based on experiments with the software “AgSim – 05”. The answers to the control tasks and conclusions must be given in the report.
problem solving agent
- goal formulation
- problem formulation - process of decideing what actions and states to consider
- search: systematic exploratio of the sequnece of alternative states that appear in a problem solving
- current state
- action
- return
- single state problem
- percepts: give enough info to tell exactly which state is it
- agent knows exactly what each of its actions
- multiple state poblem
- percepts give not enough info to tell which state is it
- agent knows all the effects of its actions
- agent must reason about f states that it might get to
problem: isa collection of information that the agent can use to decide what to do. specialization for single state probelm
state space s the set of all states reeacheble from the initial state by any sequence of actions
- initial state: is the state that the agent knows itself to be in
- goal statet corresponds to the solution of the problem
- operator describes an action in terms od which state will be reached by carrying out the action
representation: four tuple:
[N, A, IS, GS]
N- nodes - statesA- edgesIS- Initial stateGS- goal states: agent can apply if explicit state or measurable property of the states encountered in the search, property of the path developed in the search.
representation with raphs:
- nodes: particluar problem splution states
- arcs: problem solving process
- initial states: from root of the graph and correspond to the given information ina problem instance
Branching factor: number of edges of a node.
how to mesure effectiveness:
- does a search find a solution at all?
- is a solution good?
- what is the search cost associated with the time and memory required to fin a solution
total cost = pth cost + search cost
search process:
- builds up a search tree
- start drom search node - initial state
- dettermining the childre of state is called expanding the state
at each step the search algorythm chhooses one leaf node to excpand:
- they have not been expanded
- expanded but not the correct way
systematic move foreward and not coming back
- starts at initial and end at particular solution
- there is no solution at any time
but how will machine implement it?


there are cases where data driven is better then goal driver, and vice versa
like above
- search strarts from the goal, applies operators that could produce the goal, and chains backward to given facts of the problem
- searching backward means generating
- is better when there is more branching factor
problem specific knowledge is used, so we have to know the problem
no information is available about:
- the number of steps
- the cost
- how good is the current state
in order which nodes are expended is:
- breath first search
- uniform cost search
- depth-first search
- depth limited search
- iterative deepening search
- bidirectional search
- this search expands the shallowest node in the search tree first
YouTube - Breadth First Search Algorithm | Shortest Path | Graph Theory


- this search expands the lowesst cost node on the frontier first
- the path cost must never decrease
g(successor(n)) >= g(n)
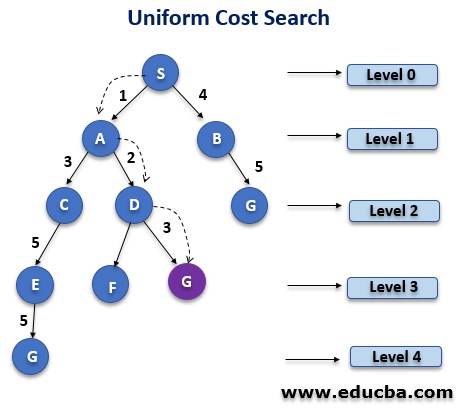
works the same way as the backtracking
same as depth-first search, but have a maximum trashold what can achive in a direction

- has a limit
- if fails then increase the limit
- each time restart the search algo from the root
iterative deepening search and depth-first from the other direction at the same time

two lists are used to implement algo:
- open: the nodes which we didn't found yet
- closed: which we already found it
to implement breadth-first and depth-first
- initially open contains the initial node
- states are excluded from the left side of the open list
- new states are included in the right side of open in case of breadth first search and in the left side in case of depth first search
- algo terminates when the goal state is either in the first position of the list open or is inserted into the list closed
- states that already are open or closed are not added to the list open
- completeness - is a solution guaranteed?
- time complexity - time needed for solution
- space complexity - memory needed for solution
- optimality - is highest quality solution quaranteed when there are several different solutions?
| criterion | breadth first | uniform | depth first | dept limited | iterative deepening | bidirectional |
|---|---|---|---|---|---|---|
| complete | + | + | - | + if l>= d | + | + |
| time | b^d | b^d | b^m | b^l | b^d | b^(d/2) |
| space | b^d | d^b | bm | bl | b^(d/2) | |
| optimal | + | + | - | - | + | + |
- b branching factor (every state can be expanded to yield b new states)
- d is the depth of solution
- m is the maximum depth of the search tree
- l is the depth limit
NEXT TIME TEST
- open zoom
- open camera
- turn off microphone
- open test
- take it
- send it in MSWord or Pdf
- experience bassed
- empirically found
- allows process the most promising branches first
to define heuristics:
- costs: lower value is better
- *quality of the node path: higher values is better
depend on the domain/state space and not the algorithms/search strategy
- greedy search - minimizing the estimate cost to real search
- A*
- IDA* - iterative deepening A*
- SMA* search - simpilfied memory bounded A*
- iterative improvement algorithms
- hill climbing
- beam search
- random restart hill climbing
- stochastic hill climbing
- simulated annealing
- this search expands thew node appears to be the best according to the evaluation fuinction
https://www.geeksforgeeks.org/greedy-algorithms/
- reduces the time and pace complexity with a good heuristic function
more in: https://github.com/gabboraron/MI-EA
f(n) = g(x) + h(x)
condservs memory
-each iteration is depth first search - modified to use an f-cost
expands all nodes inside the contour for the current f-cost peeping over the contour to find out where the next contour is, where all nodes have f(n) less than or equal to f-cost
- only goes through two or three restarts since typically f only increases several times along the heuristic route
- cheap - fast
- this search explores the state space trying to find the best value of estimated cost
- take to reach the goal very fast and with very low resources
more complicated tasks can be handled with this
- uses only the best W nodes at each level the other nodes are ignored
- uses lot of memory
- breaadth first level by level
- all nodes from the list OPEN are expeaded
- expect only the the best weight
beam means how many nodes can we store
- uses local maxima
- picks a randomly seleted successor of the current node
- if the move improves the situation always executed
- probability decrases eponentially with the badness of the move calculated as difference of values between next and current state
- when we are creating path it should be good all the time
- if local choices are perfectly then the algo is it too
- randomy choses on of sucessors that imprves the quality of the state
- depends on the improvement
- lowest heuristic: allwys going to lower value in the graph!
- highest heuristic: allwys going to hisgher value in the graph!
because heuristics use limited information they can lead a search algorithm to a suboptimal solution or fail to find any solution at all
- best first: is not an answer to all searching needs because at the worst case exponentional growt will occur.
- greedy star: is optimal, finding the shortest path, but in worth case is neither complete
A*:IDA*: it can expandN^2nodes inNiterationSMA*not complete and not optimal, huge memory usage- Hill climbing: will halt even thought the solution may be far from satisfactory
different use cases needs different algorithms
- two player (human or computer)
- conflict games
- players use heuristics
like in chess:
- both players know where the pieces are
- both know the possible moves
like in card games:
- players do not know the other's pieces
in each situation each player has full information:
- chess
- tick-tack-toe
- checkers
- chess
are not:
- poker
- bridge
- dice games
- game trees consists of nodes and arcs
- nodes represent a possible state of game
- edges represent a the way how we occure there
- root node is the starting position
- internal node
- leaf nodes are the possible termination places of the game
- each level in gme tree is a turn of a player
- dividing into minimizer and maximizer levels of the game tree
- the idea is to maxximise your result in the game by minimizing opponents result
- the algorithm comes down to the leaf nodes and assigns the heuristic values that denote how good the state is for the maximizer
- the evaluations are transferred upwards
- heuristic evaluations:
- the heuristic evaluations are given as numbers
- they characterise how good the state is for the given player
- 1 if the maximizer wins
- -1 if minimizer wins
- 0 if draw
steps of mimiax algorithm
- build full gam tree
- divide the gam tree into the levels (MIN-MAX)
- assign heuristi evaluations to the leaf nodes
- transfer the evaluations upwards till the root node
- in building the game tree choosing the parameters is the key
- it is hard to create the game tree
- looking forward by n moves
F(s) = a*B + b*R+c*M+d*C+e*P+f*Awhere
Btotal value of piecesRprotection of the kingMmobility of the piecesCcontorl over the centerPpawn structureApossibel attacka;b;c;d;e;f- weights
what is knowladge?
- an individual understanding of given subject
- for us only the domain specific knowledge is intersting!
- domain is a well-focused area!
- in general a representation is a set of conventions about how to describe a class of things
- a description makes use of the conventions of a represenation to describe some particular thing the function of any representation scheme is to capture essential features of a problem domain => make this available for the machine
- the represenation language must allow the programmer to use the knowladgebase
https://www.javatpoint.com/the-wumpus-world-in-artificial-intelligence
- cave explored by agent consist from rooms connected with passageways
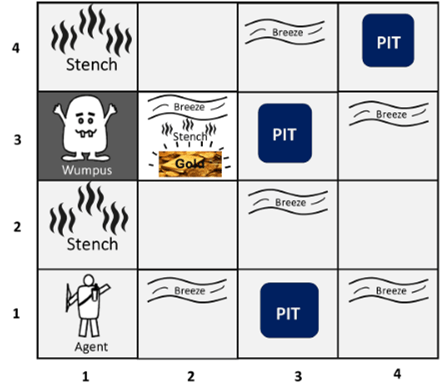
declarative knowledge
- concepts
- facts
- objects
procedureal knowledge: describes how a problem is solved
- rules
- strategies
- agendas
- procedures
heuristic knowledge (shallow knowledge): describe a rule of thumb that guides the reasoning process; it is empirical and represents the knowledge compiled by an expert throught the experience of solving past problems
- rules of thumb
meta knowledge: describes knowledge about knowledge. This type of knowlede is used to pick other knowledge that is best suited for solving a problem. experts use this type of knowledge to enhance the efficiency of problem solving by directing their reasoning in the most promising area.
- knowledge about the other types of knowledge and how to use them
structural knowledge: describes knowledge structures. this type of knowledge describes an expert's overall mental model of the problem. The expert's mental model of concepts sub-concepts and objects is typical of rhis type of knowledge
- rule sets
- concepts relationships
- concept to object relationships
knowledge representation language:
- syntax of the language describes the possible config
- semantics determines the facts in the world which the sentences refer
if yntacs and semantics are defines precisely the language is called logic
Sentences => semantics => facts
- representation must be encoded some way that can be physically stored within an intelligent system
- it is imposible to put the worlld inside a computer so all reasoning mechanisms must operate on representations of facts, rather than on facts themselves
representation:
- kexical
- structural
- procedural
- semantic
logical formalism suggests a powerful way of deriving new knowledge from olf mathematifal deduction; this conclusion can be made that a new statement is true by proving that it follows from the statements that are already known.
- sound
- complete
AI programming requires means of capturing and reasoning about qualitative aspects of a problem
logic provides ai progrmmers with a well-definied language => create automation for us
logical axioms, and "problmes as theorems" representations help us attack a problem
=> AI programming languages: PROLOG
- not all problems can be solved with logic
- some knowledge resits embodiment in axioms
- logic is weak as a representation for certain kinds of knowledge
- the notation of pure logic does not allow to express such notations as heuristic distances
- difficult to develop a system like that
Kinnds of logic:
- general lang:
- propositional calculus
- predicate calculus
- based on general lang:
- temporal
- probability
- fuzzy
- symbols: P, Q, R, S, T
- truth symbols: True, False
- connectivities: ^; ˇ; =>, ≅, !
where
- every propositinoal symbo and truth symbol is a sentence
- negation of a sentance is a sentance
- conjunction or AND of two sentences is a sentence
how to test truth validity:
- truth table method:
+any propositional calculus expression can be tested-time consuming in case of large number of propositions
- complete proof procedures
+can procedure any expression that logically folllows from a set of experiences- inference mechanism <-methods by the conclusion is reached
a |= b meaning:b can be derived from a by inference: a/b
- an interfence rule is sound if the conclusion is true, in all cases where the premises are true
- to prove the soundness the truth table must be constructed with one line for each possible model of the proposition symbols in the premises, in all model where the premise is true, the conclusion must be also true

B=It rained on Firday
will it rain on Monday?
- irreducible syntactic elements
- symbols may represent constants tom represents Tom. the true and false are reserved as truth symbols
- a fact or proposition is divided into two parts: predicate and argument. The arguments athe object or objecxt of the proposition
Tom owns the car => owns(tom,car)
- owns - predicate
- tom, car - arguments and symbols
- variables: represent general classes of objects or poperties
- functions: mapping one or more leemnt of a set (domain) to a unique elemnt of another set (range)
- elements of the domain and range are objects in the world of discourse
- every function symbol has an associated arity (number od elements in domain which are used in the function)
- functions can be used within predicates
- atomic sentences
if x and y is a syntax then x and y and x=>y and x or y and ∀x and ∃x is also a syntax.
∀X (cat(X) => animal(X))means: All cats are animals∀X (likes(X, mary) and nice(mary) => nice(X))mens: all instances of X who like Mary, and if Mary is nice, then it is implied that those who like Mary are also nice.∀X, Y (parent(X, Y) => child(Y, X))is “For all persons, if X is a parent of Y, then Y is a child of X”∀X ∃Y loves(X, Y)means Everybody loves somebody
Predicate calculus semantics provide a formal basis, for determining the truth value of well-formed expressions
The truth of expressions depends on the mapping of constants, variables, predicates, and functions into objects and relations in the domain of discourse
ex: owns(john, ford); friends(john, bill)
Let the domain D be a nonempty set.
An interpretation over D is an assignment of the entities of D to each of the constant, variable, predicate and function symbols of a predicate calculus expression
- Each constant is assigned an element of D
- Each variable is assigned to a nonempty subset of D.
Each function f of arity m is defined on m arguments of D and defines a mapping from D^m into D
Each predicate p of arity n is defined on n arguments from D and defines a mapping from D^n into {T, F}
Given an interpretation, the meaning of an expression is a truth value assignment over the interpretation.
Let E be an expression and I an interpretation for E over a nonempty domain D. The truth value for E is determined by:
- The value of constant is the element of D it is assigned to by I
- The value of a variable is the set of elements of D it is assigned to by I
- The value of a function expression is that element of D obtained by evaluating the function for the parameter values assigned by the interpretation
- The value of truth symbol “true” is T and “false” is F
- The value of an atomic sentence is either T or F, as determined by the interpretation I
- The value of the negation of a sentence is T if the value of the sentence is F and is F if the value of the sentence is T
***If the domain of interpretation is infinite, exhaustive testing of all substitutions to a universally quantified variable is computationally impossible: the algorithm may never halt
That is why the predicate calculus is said to be undecidable***
- Evaluating the truth value of a sentence containing an existentially quantified variable may not be easier
- If the domain of the variable is infinite and the sentence is false under all substitutions, the algorithm will never halt
In the language defined, universally and existentially quantified variables may refer only to objects (constants) in the domain of discourse
This language is called the first-order logic (first-order predicate calculus)
- any natural language may be expressed in first-order logic using the symbols, connectives, and variable symbols
Example:
- “All basketball players are tall”. Mappings:
- ∀X(basketball_player(X) and tall(X))
- ∀XX(basketball_player(X) => tall(X))
- In propositional calculus two expressions match if and only if they are syntactically identical
- In predicate calculus a decision process based on universal instantiation is needed for determining the variable substitutions under which two or more expressions can be made identical
- Unification is an algorithm for determining the substitutions needed to make two predicate calculus expressions match
- All variables must be universally quantified
- Existentially quantified variables may be eliminated by replacing them with the constants
- all quantifiers can be dropped
- Skolemization replaces each existentially quantified variable with a function that returns the appropriate constant *ex:
∀X ∃Y father(X,Y)become∀X father(X, f(X))- Unification is complicated because a variable may be replaced by any term, including other variables and function expressions of arbitrary complexity
- the action description
- the precondition: it is a conjuction of predicates that must be true before the operator can be applied
- the effect of an operator: it isa conjuction of predicates that describes how the situation changes when the operator is applied
operator(ACTION: action's name,
PRECONDITION: p(x) and q(y) and ...
EFFECT: r(y) and w(x) and ...)
- progression planner: searches forward
- regression planner: searches backward
plans:
- pratially ordered plans
- totally ordered plans
POP algorithm:
- starts with minimal partial plan
- extends the plan by achieving a precondition of needed step
- records a causal link for the newly achieved precondition
- if the new step threatens an existing causal link or an existing step threatens the new causal link the threat resolving is applied
- if at any point the algorithm fails to find a relevant operator or resolve a threat it backtracks to previos choice point
execution monitoring: the agent monitors what is happening during the execution of the plan. The agent can do replanning. the execution monitoring agent is deferring the job of dealing with those conditions until they actually arise
Learning element is responsible for making imporvements and for efficiency of the performance element. Performance element is responsible for sleecting exrternal actions. Critic is designed to tell the learning elemeent how well the agent is doing. Problem generator is responsible for suggesting actions
decision trees are a method for learning boolean functions.
internal nodes response to a test of the value of the attributes
The tree can be expaussed as a confunction of inividual implications to the paths through the tree ending in YES nodes
The decision tree must answer in expressions.
- the DT can't represent any set - implicity limiter
- any boolean function can be written in a DT
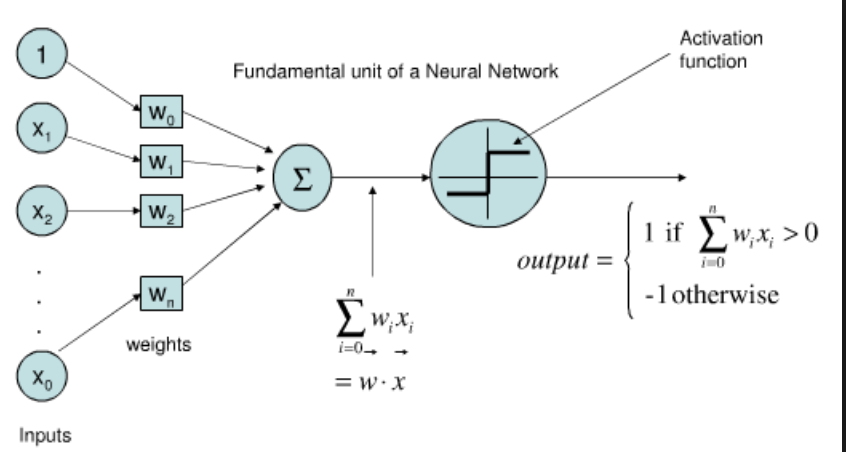
- artificial neural network is composed of a number of a sinple arithmetic computing elements or nodes connected by links - synoyms: connectionism, parallel distributed processing, and neural copmutation.
- mathematical model of operation of brain
- brains information capacity is thought to emerge primarily from networks of such neurons
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- 1943 McCulloch and Pitts - simple math model of neuron is devised
- neural network is composed of a number of units connected by links
- each link has a numeric weight associated with
first linear component called input ifunction: wehere
w0i connected to fixed input a0 =-1
second is a nonliner component called the activation function, g the ttransforms the weighted sum into the final value
- the activation function g is designed to meet two wishes
- feed forward networks
- recurrent network - the network structure is cyclic
- feeds its outputs back into its own inputs
- the activation levels of recurrent networks form a dynamic system that may reach a stable state or exhibit oscillations
- hopfield network are the best-understood class of recurrent networks
- bidirectional connections with symmetric weights
- single layered feed-forward neural network
- with a treshold activation function the percetron represents a boolean function
- a treshold perceptron returns 1 if and only if the weighted sum of its input is positive
- this eq defines a hyperplane in the input space, perceptron returns 1 if and only if the input is on one side of that hyperplane
- for this reason the threshold perceptron is called a liner separator
- the
error = T-OwhereOis the output of the perceptron on the example andTis the true output value.- if the error is positive then
Omust be increased - if error is negative
- the perceptron learning rate is
alphaand
- if the error is positive then
- edible 1
- not edible 0
- good fruit 1
- not good fruit 0
back-prpagation learning: at the output layer in weight update rule the activation of the hidden unit aj is used instead of the input value: and the rule contains a term for the gradient of the activation function
where Erriis the erro (Ti-Oi) at the output node: g'(ini) is the derivative of the activation function g -> only sigmouid function can e used in multilayer network
new error term is which for output nodes is
update rule now is the following
repeat this calculation the following for each layer in the network, until the earliest hidden layer is reached: propagate the delta value
- divide example set
- how many units
- kind of units
- units are connected
- initialize the weights
- encode the examples in terms of inputs
- train model - train the weights
- test model
- agents almost never have access to the whole truth about network
- utility theory is used to represent and reason with prefereneces
- termutility is used in sense of the quality of being useful
- every state has a degree of usefulness or utility to an agent and that the agent will preffer states with higher utility
- the utility of state is realtive o the aent whose preferneces the utility function is supposed to represent
- an atomic snetence is a full specification of the state of the world
- values for all variables world cosist of
The probability of both events:
the false version:
the multiplication rule:
Belief Bayesian network: a data structure to represent the dependence between variables and to give a concise specification of the joint probability distribution
- a set of random variables makes up nodes of the network
- set of directed links
the probability of all events:
used to refer ro the set