A lines-of-code counter.
Focused on C++ projects, which sometimes include code generated by bison, flex, moc, rcc and uic.
Has support for many other languages, but since I'm not a user of many of them, may be inaccurate on other languages. If you use this code, feel free to open an issue if you find problems.
When I first wrote mcloc more than 20 years ago, I needed a tool that could ignore source code that was generated by flex or bison. By default, mcloc will ignore code generated by flex, bison, moc, rcc and uic and instead just count the generator input. That's my personal preference; generated code is not code I maintain, and is usually much larger than the generator input I maintain (and hence misleading). Counters for generated code can be enabled on the command line if desired.
Speed has never been an issue in my usage. As an example, on a large code base which is orders of magnitude larger than my typical use:
% time mcloc -l -Lc++ ~/gits/qt5
CODE COMMENTS LANGUAGE
L 12,892,785 2,270,945 C++
12,892,785 2,270,945 TOTAL (208.4ms, 72.77M lines/s, 308% sys 1,361% usr)
3.231u 1.117s 0:01.07 405.6% 0+0k 0+0io 0pf+0w
I don't need it to be any faster. Note that above we see it only took 208.4 milliseconds to count lines in the source. The remaining 800 milliseconds or so was spent doing things like reading the configuration, finding files of interest in the filesystem, etc. For my typical usage, on MUCH smaller code bases, it's essentially instantaneous. And I'm not willing to gravely risk accuracy in the name of a bit more speed. A few lines here and there, no big deal. But any time I find it getting lost and grossly miscounting, I fix it. This tends to be a problem with most LOC counters and it's understandable. There are limitations with what can be done accurately for some languages without writing a full language front end. And some sources (the patterns in the rules of flex source, for example) tend to throw a wrench in the mechanisms used by some LOC counting tools.
./configure
make
I don't include an install target in the Makefile. I normally build a package and install the package.
To build a package on FreeBSD, you need mkfbsdmnfst. To build a package on a Debian-based Linux, you need mkdebcontrol. No additional tools are needed on macOS, assuming you have Xcode and the Xcode command line tools installed.
On FreeBSD:
gmake package
pkg install mcloc-1.0.8.txz
On Linux:
make package
dpkg -i mcloc_1.0.8_amd64.deb
On macOS:
gmake package
open mcloc-1.0.8.pkg
Like all LOC counters that don't implement a full language front end, it is not always 100% accurate. But in the areas that are important to me in my own code (C, C++, flex, bison), it's more accurate than other tools I've tried. Your mileage may vary. If you find a test case where it gets lost, open an issue and I'll try to fix it (and create a unit test so it doesn't happen again).
For some languages, counting lines of code and lines of comments is essentially trivial and can be done with simple egrep invocations. Those with block commenting with comment start/end sequences are more difficult. And some with nested comment facilities are even more difficult. There's only so much a textual tool can do, and I encourage users of these tools to be wary. I've been seeing misleading claims of accuracy for literally decades for these tools. I make no claim of 100% accuracy. It's important to understand how these tools work, and if you want 100% accuracy, write your comments in a manner that doesn't send the tool into the weeds. And of course... you can always write your own tool or contribute issue and/or fixes to any of the tools that are open source!
As an example, this simple C++ source is grossly miscounted by tokei and scc, which both claim to be accurate:
#include <iostream>
int main(int argc, char *argv[])
{
std::cout << '"';
/* block comment
inside code */
}
//----------------------------------------------------------------------------
//!
//----------------------------------------------------------------------------
/*
*
*
*
*/
I'm not maligning these other tools. I'm simply pointing out that some languages have valid language syntax that can send our tools into the weeds. Be aware. I'm quite certain there are many cases where mcloc makes egregious mistakes, and I just haven't seen them yet since my usage is limited to my own code. But I will say that philosophically, I'm not very interested in "fast!" if I can't trust the tool on my code. If you report problems, I'll do my best to address them even if it means being a bit slower.
Since I don't work in very many of the languages I claim to support, I don't have tests for them at the moment and I'm sure that there are problems I don't know about.
Mapping a file to a scanner is done via filename extensions (or regular expressions for a few cases). This is by design and it's highly unlikely I'll change it; all of my projects follow consistent naming conventions and my work is focused on languages where source files all have common extensions. The mappings can be configured in the configuration file. This is a design tradeoff that allows me to ignore files that don't match a naming convention instead of opening them and trying to figure out what they are.
Of course this makes it unsuitable for some code bases, especially those that might have conflicting extensions (say perl and Prolog) and definitely those that have no filename extensions.
I just haven't had time to do this. It shouldn't be difficult; in all likelihood it's not much more than bringing in an open source version of getopt.
I sort of threw this together as a hack. If others find it useful, I'll put some more work into it. Just let me know! It's Qt5-based so you'll need Qt5 installed in order to compile and use it.
I consider lines-of-code counters mostly personal developer tools. Writing one is a useful exercise that I encourage other developers to try as an exercise, in whatever language you prefer.
In and of itself, lines of code isn't a terribly useful metric. It's certainly not very useful to someone who isn't actively working on the code being counted. The correlation to work done is often weak, and the anticorrelation is often strong (it takes more work/knowledge to deliver the same functionality with fewer lines of code).
My primary use of mcloc is during exploratory design where LOC is one metric I'll use to guide my design choices, and in refactoring efforts where the simplification and reduction of code is an objective. Say modernizing C++98 or C++03 code to C++11 or later, which often presents opportunities to utilize new language and standard library facilities that reduce the amount of code we have to maintain.
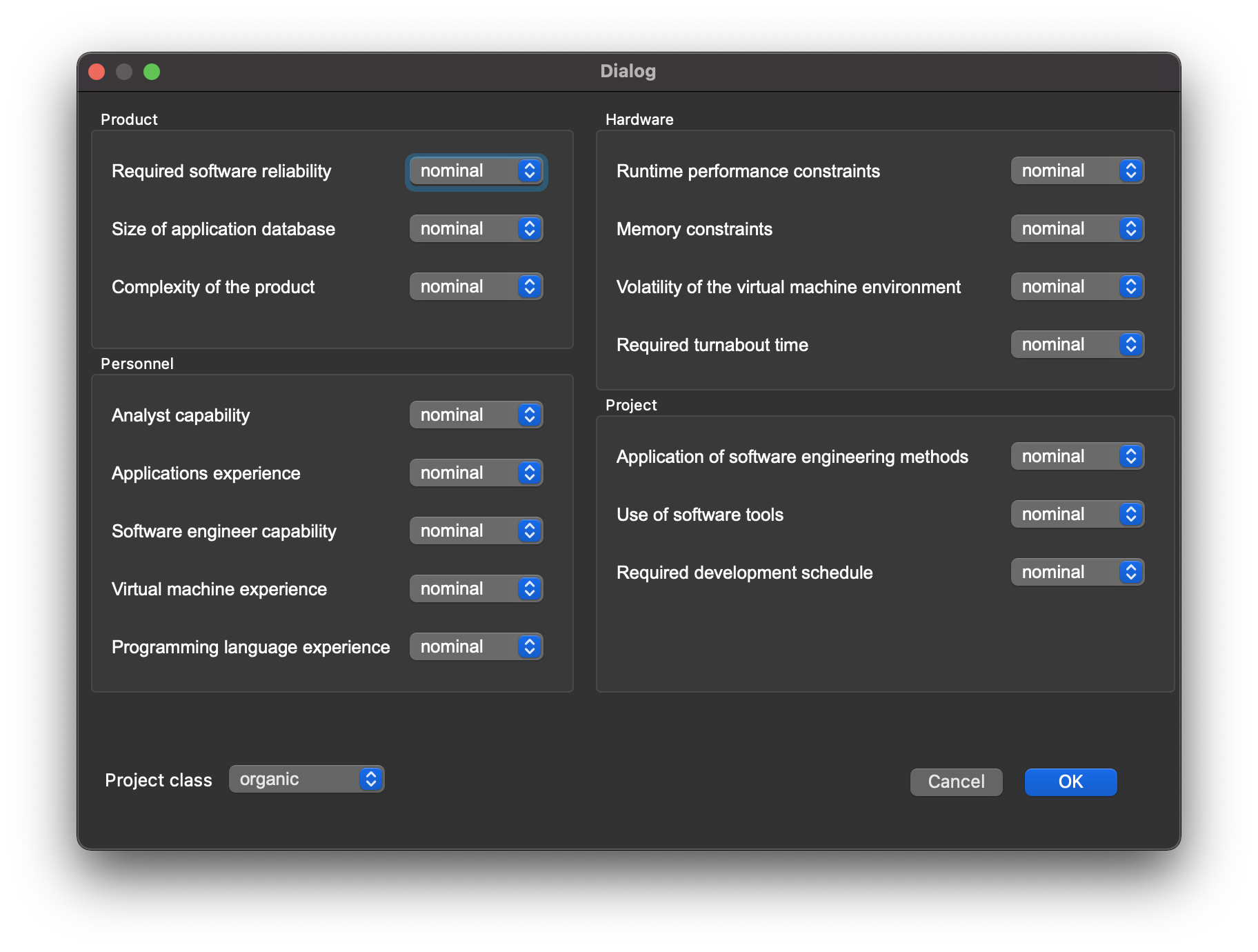
Here's a screenshot of the main page of qmcloc, with numbers from a working copy of mcloc.
And a screenshot of the COCOMO configuration dialog.