GluonCV 0.5.0 Release
Pre-releaseGluonCV 0.5.0 Release
Highlights
GluonCV v0.5.0 added Video Action Recognition models, added AlphaPose, added MobileNetV3, added VPLR semantic segmentation models for driving scenes, added more Int8 quantized models for deployment, and we also included multiple usability improvements.
New Models released in 0.5
| Model | Metric | 0.5 |
|---|---|---|
| vgg16_ucf101 | UCF101 Top-1 | 83.4 |
| inceptionv3_ucf101 | UCF101 Top-1 | 88.1 |
| inceptionv3_kinetics400 | Kinetics400 Top-1 | 72.5 |
| alpha_pose_resnet101_v1b_coco | OKS AP (with flip) | 76.7/92.6/82.9 |
| MobileNetV3_Large | ImageNet Top-1 | 75.32 |
| MobileNetV3_Small | ImageNet Top-1 | 67.72 |
| deeplab_v3b_plus_wideresnet_citys | Cityscapes mIoU | 83.5 |
New application: Video Action Recognition
https://gluon-cv.mxnet.io/model_zoo/action_recognition.html

Video Action Recognition in GluonCV is a complete application set, including model definition, training scripts, useful loss and metric functions. We also included some pre-trained models and usage tutorials.
| Model | Pre-Trained Dataset | Clip Length | Num of Segments | Metric | Dataset | Accuracy |
|---|---|---|---|---|---|---|
| vgg16_ucf101 | ImageNet | 1 | 1 | Top-1 | UCF101 | 81.5 |
| vgg16_ucf101 | ImageNet | 1 | 3 | Top-1 | UCF101 | 83.4 |
| inceptionv3_ucf101 | ImageNet | 1 | 1 | Top-1 | UCF101 | 85.6 |
| inceptionv3_ucf101 | ImageNet | 1 | 3 | Top-1 | UCF101 | 88.1 |
| inceptionv3_kinetics400 | ImageNet | 1 | 3 | Top-1 | Kinetics400 | 72.5 |
The tutorial for how to prepare UCF101 and Kinetics400 dataset: https://gluon-cv.mxnet.io/build/examples_datasets/ucf101.html and https://gluon-cv.mxnet.io/build/examples_datasets/kinetics400.html .
The demo for using the pre-trained model to predict human actions: https://gluon-cv.mxnet.io/build/examples_action_recognition/demo_ucf101.html.
The tutorial for how to train your own action recognition model: https://gluon-cv.mxnet.io/build/examples_action_recognition/dive_deep_ucf101.html.
More state-of-the-art models (I3D, SlowFast, etc.) are coming in the next release. Stay tuned.
New model: AlphaPose
https://gluon-cv.mxnet.io/model_zoo/pose.html#alphapose

| Model | Dataset | OKS AP | OKS AP (with flip) |
|---|---|---|---|
| alpha_pose_resnet101_v1b_coco | COCO Keypoint | 74.2/91.6/80.7 | 76.7/92.6/82.9 |
The demo for using the pre-trained AlphaPose model: https://gluon-cv.mxnet.io/build/examples_pose/demo_alpha_pose.html.
New model: MobileNetV3
https://gluon-cv.mxnet.io/model_zoo/classification.html#mobilenet
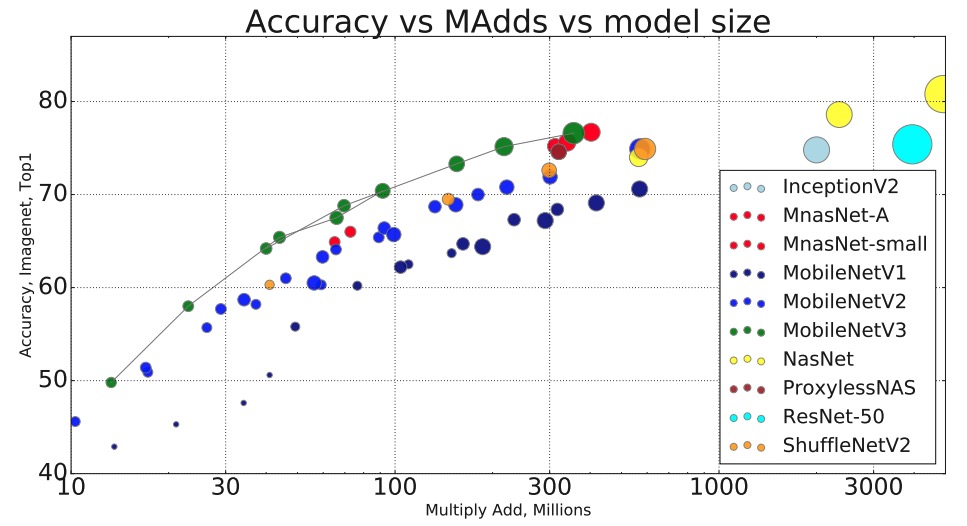
| Model | Dataset | Top-1 | Top-5 | Top-1 (original paper) |
|---|---|---|---|---|
| MobileNetV3_Large | ImageNet | 75.3 | 92.3 | 75.2 |
| MobileNetV3_Small | ImageNet | 67.7 | 87.5 | 67.4 |
New model: Semantic Segmentation VPLR
https://gluon-cv.mxnet.io/model_zoo/segmentation.html#cityscapes-dataset

| Model | Pre-Trained Dataset | Dataset | mIoU | iIoU |
|---|---|---|---|---|
| deeplab_v3b_plus_wideresnet_citys | ImageNet, Mapillary Vista | Cityscapes | 83.5 | 64.4 |
Improving Semantic Segmentation via Video Propagation and Label Relaxation ported in GluonCV. State-of-the-art method on several driving semantic segmentation benchmarks (Cityscapes, CamVid and KITTI), and generalizes well to other scenes.
New model: More Int8 quantized models
https://gluon-cv.mxnet.io/build/examples_deployment/int8_inference.html
Below CPU performance is benchmarked on AWS EC2 C5.12xlarge instance with 24 physical cores.
Note that you will need nightly build of MXNet to properly use these new features.

| Model | Dataset | Batch Size | C5.12xlarge FP32 | C5.12xlarge INT8 | Speedup | FP32 Acc | INT8 Acc |
|---|---|---|---|---|---|---|---|
| FCN_resnet101 | VOC | 1 | 5.46 | 26.33 | 4.82 | 97.97% | 98.00% |
| PSP_resnet101 | VOC | 1 | 3.96 | 10.63 | 2.68 | 98.46% | 98.45% |
| Deeplab_resnet101 | VOC | 1 | 4.17 | 13.35 | 3.20 | 98.36% | 98.34% |
| FCN_resnet101 | COCO | 1 | 5.19 | 26.22 | 5.05 | 91.28% | 90.96% |
| PSP_resnet101 | COCO | 1 | 3.94 | 10.60 | 2.69 | 91.82% | 91.88% |
| Deeplab_resnet101 | COCO | 1 | 4.15 | 13.56 | 3.27 | 91.86% | 91.98% |
For segmentation models, the accuracy metric is pixAcc. Usage of int8 quantized model is identical to standard GluonCV models, simple use suffix _int8.
Bug fixes and Improvements
- RCNN added automatic mix precision and horovod integration. Close to 4x improvements in training throughput on 8 V100 GPU.
- RCNN added multi-image per device support.