{kind=link}
Rewarding Doubt: A Reinforcement Learning Approach to Calibrated Confidence Expression of Large Language Models
This repository contains the official implementation of the paper
Rewarding Doubt: A Reinforcement Learning Approach to Calibrated Confidence Expression of Large Language Models
David Bani-Harouni1, Chantal Pellegrini1, Paul Stangel, Ege Özsoy, Kamilia Zaripova, Matthias Keicher, Nassir Navab
Technical University of Munich, Munich Center for Machine Learning
1 Shared first authorshipto be published at ICLR 2026
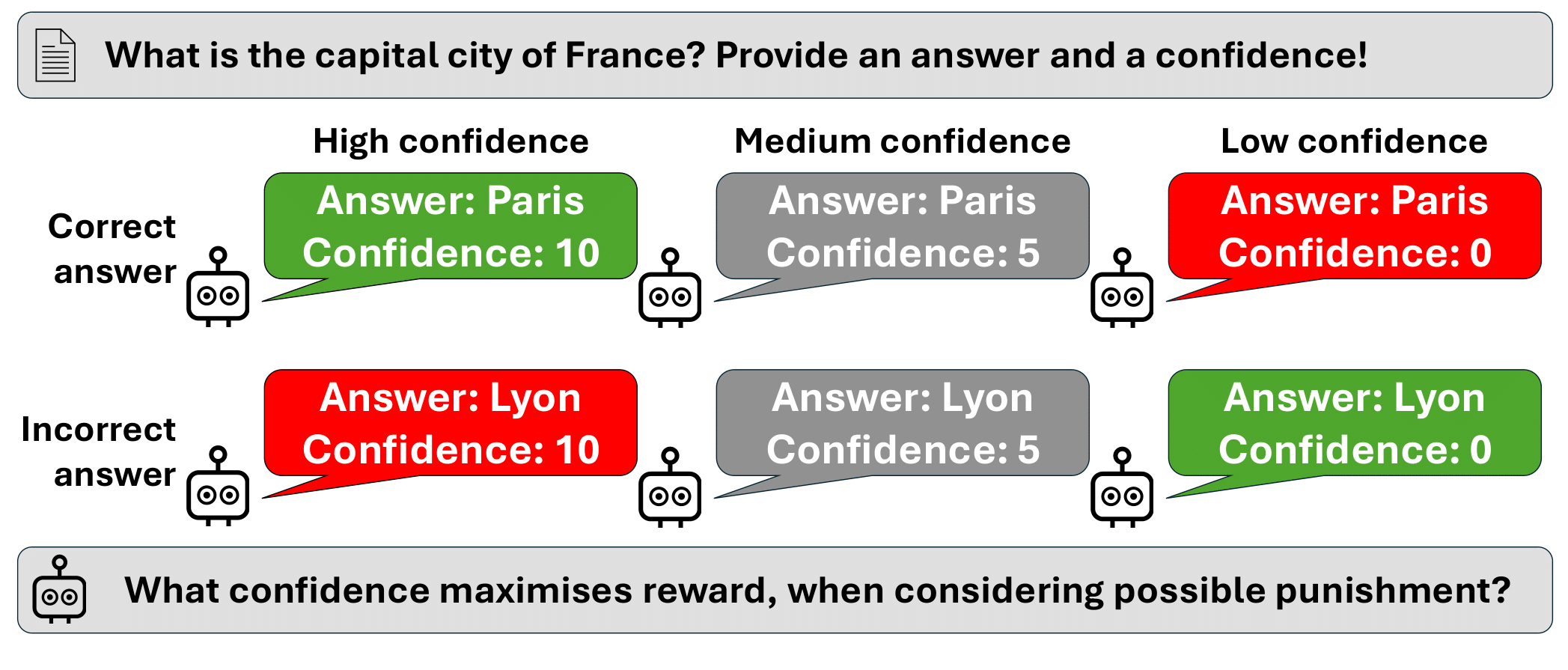
A safe and trustworthy use of Large Language Models (LLMs) requires an accurate expression of confidence in their answers. We propose a novel Reinforcement Learning approach that allows to directly fine-tune LLMs to express calibrated confidence estimates alongside their answers to factual questions. Our method optimizes a reward based on the logarithmic scoring rule, explicitly penalizing both over- and under-confidence. This encourages the model to align its confidence estimates with the actual predictive accuracy. The optimal policy under our reward design would result in perfectly calibrated confidence expressions. Unlike prior approaches that decouple confidence estimation from response generation, our method integrates confidence calibration seamlessly into the generative process of the LLM. Empirically, we demonstrate that models trained with our approach exhibit substantially improved calibration and generalize to unseen tasks without further fine-tuning, suggesting the emergence of general confidence awareness.
If you find this work useful, please cite:
@article{bani2025rewarding,
title={Rewarding Doubt: A Reinforcement Learning Approach to Calibrated Confidence Expression of Large Language Models},
author={Bani-Harouni, David and Pellegrini, Chantal and Stangel, Paul and {\"O}zsoy, Ege and Zaripova, Kamilia and Keicher, Matthias and Navab, Nassir},
journal={arXiv preprint arXiv:2503.02623},
year={2025}
}