Build local, on-device RAG in Flutter with a Dart package.
Mobile RAG Engine is a Flutter package for local Retrieval-Augmented Generation (RAG): ingest local documents, chunk and embed them on-device, then run hybrid semantic + keyword search through a Dart API. No server, no API cost, no network round-trip for retrieval.

Use it when you need a Flutter local RAG engine for private notes, document Q&A, chat with PDF, offline assistants, or enterprise apps where user data must stay on the device.
You do NOT need to install Rust, Cargo, or Android NDK.
This package includes pre-compiled binaries for iOS, Android, and macOS. Just pub add and run.
| Feature | Pure Dart | Mobile RAG Engine (Rust) |
|---|---|---|
| Tokenization | Slow | HuggingFace tokenizers (Rust) |
| Vector Search | O(n) | HNSW Index — sub-linear retrieval |
| Memory Usage | High | Copy-minimized Rust core, Float32List zero-copy transport |
Numbers vary by device and corpus. See
benchmark_serviceand the0.18.0retrieval-hot-path notes in CHANGELOG.md for measured deltas on your own hardware.
| Area | Current status | Evidence / boundary |
|---|---|---|
| Local Flutter RAG retrieval | Supported | Dart facade over a Rust core for ingest, chunking, embedding, SQLite storage, HNSW vector search, BM25 keyword search, RRF fusion, and context assembly |
| Offline / on-device operation | Supported | Models and user documents stay local after you bundle the ONNX model and tokenizer assets |
| Hybrid source retrieval | Verified on benchmark fixtures | 80-source balanced profile run: source_recall@10 = 1.000 for shipped default_hybrid |
| Passage/context retrieval | Verified on benchmark fixtures | 80-query passage run: passage_recall@10 = 0.925, answerable_context@10 = 0.938; semantic passage misses remain the main improvement area |
| Text-layer PDF-to-RAG | Verified on sample scope | sample_eng.pdf and sample_kor.pdf profile run: 8/8 PDF-derived queries reached source, passage, and answerable context at top-10 |
| Scanned/image-only PDFs | Detected, not OCR-processed | OCR-required PDFs are surfaced as extraction errors so your app can route to an OCR layer; OCR is not bundled in this package |
| Large, table-heavy, OCR-heavy PDFs | Still being validated | Do not treat the PDF smoke result as broad PDF robustness or mobile latency/memory proof |
For the implementation-oriented guide, see Flutter Local RAG Engine Guide.
Data never leaves the user's device. Perfect for privacy-focused apps (journals, secure chats, enterprise tools).
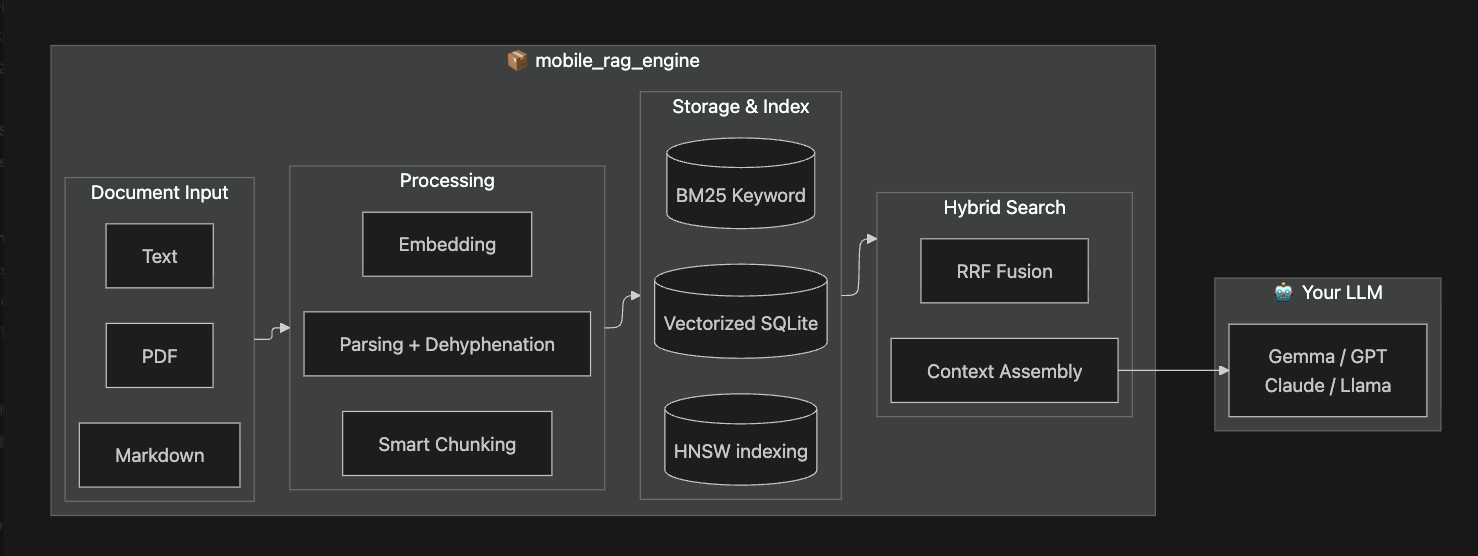
One package, complete pipeline. From any document format to LLM-ready context.
| Category | Features |
|---|---|
| Document Input | Text-layer PDF, Markdown, Plain Text, and beta DOCX support; file-path and UTF-8 ingest fast paths |
| Chunking | Plain-text paragraph/line chunking with heading-aware split and tokenizer hard guard; Markdown structure-aware chunking with header-path metadata |
| Search | HNSW vector + BM25 keyword hybrid search with RRF fusion; metadata-first search with explicit context/chunk hydration |
| Storage | SQLite persistence, HNSW Index persistence (fast startup), connection pooling, resumable indexing |
| Collections | Collection-scoped ingest/search/rebuild via inCollection('id') |
| Performance | Rust core, 10x faster tokenization, thread control, memory optimized |
| Context | Engine-tokenizer exact context budget, adjacent chunk expansion, single source mode |
Support boundaries: text-layer PDFs are production-ready. Scanned or image-only PDFs should be routed through an OCR layer before indexing. DOCX extraction is available for early adopters, but complex DOCX layouts such as tables, headers, and footnotes should be treated as beta.
| Platform | Minimum Version |
|---|---|
| iOS | 16.0+ |
| Android | API 21+ (Android 5.0 Lollipop) |
| macOS | 14.0+ |
ONNX Runtime is provided through
flutter_onnxruntime. CocoaPods iOS builds require static framework linkage (use_frameworks! :linkage => :static), and Android release builds should keep ONNX Runtime classes in ProGuard/R8 rules.
dependencies:
mobile_rag_engine: ^0.19.0# Create assets folder
mkdir -p assets && cd assets
# Download all-MiniLM-L6-v2 model (INT8 quantized for ARM64, ~23MB)
curl -L -o model.onnx "https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2/resolve/main/onnx/model_qint8_arm64.onnx"
curl -L -o tokenizer.json "https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2/resolve/main/tokenizer.json"Need multilingual (Korean, CJK, etc.)? See Model Setup Guide for BGE-m3 and other model options.
- Adjacent Chunk Retrieval - Fetch surrounding context.
- Index Management - Stats, persistence, and recovery.
- Markdown Chunker - Structure-aware text splitting.
- Multi-Collection - Isolate ingest/search/rebuild by category.
- Prompt Compression - Reduce token usage.
- Search by Source - Filter results by document.
- Search Strategies - Tune ranking and retrieval.
- Flutter Local RAG Engine Guide - Build local/on-device RAG in Flutter with Dart APIs.
- Quick Start - Setup in 5 minutes.
- Model Setup - Choosing and downloading models.
- Release Build - Bundle size optimization for production.
- Troubleshooting - Common fixes.
- FAQ - Frequently asked questions.
- Unit Testing - Mocking for isolated tests.
Initialize the engine once in your main() function. See the Quick Start Guide for the full parameter table.
await MobileRag.initialize(
tokenizerAsset: 'assets/tokenizer.json',
modelAsset: 'assets/model.onnx',
deferIndexWarmup: true,
);
// Before first search, wait for BM25/HNSW warmup if you deferred it:
if (!MobileRag.instance.isIndexReady) {
await MobileRag.instance.warmupFuture;
}class MySearchScreen extends StatelessWidget {
Future<void> _search() async {
// 1. Add Documents (auto-chunked & embedded). Indexing is auto-managed
// (debounced ~500ms) — only call rebuildIndex() if you need it now.
await MobileRag.instance.addDocument(
'Flutter is a UI toolkit for building apps.',
);
// File / UTF-8 fast paths are useful for large local documents.
await MobileRag.instance.addDocumentFromFile('/path/to/manual.pdf');
final noteBytes = await File('/path/to/notes.md').readAsBytes();
await MobileRag.instance.addDocumentUtf8(noteBytes, name: 'notes.md');
// 2. Search with LLM-ready context
final result = await MobileRag.instance.search(
'What is Flutter?',
tokenBudget: 2000,
);
print(result.context.text); // Ready to send to LLM
}
}addDocumentFromFile is the fastest path because the Rust core reads and chunks the file directly. Some platform pickers (cloud-backed pickers, content URIs without a stable local path, etc.) return data that is not exposed as a real filesystem path. In those cases, fall back to UTF-8 or parsed-text ingestion:
try {
await MobileRag.instance.addDocumentFromFile(path, name: fileName);
} on RagError {
final bytes = await File(path).readAsBytes();
final lower = fileName.toLowerCase();
if (lower.endsWith('.txt') ||
lower.endsWith('.md') ||
lower.endsWith('.markdown')) {
await MobileRag.instance.addDocumentUtf8(bytes, name: fileName);
} else {
try {
final text = await DocumentParser.parse(bytes);
await MobileRag.instance.addDocument(text, name: fileName);
} catch (error) {
if (DocumentParser.isOcrRequiredPdfExtractionError(error)) {
throw UnsupportedError(
DocumentParser.userMessageForExtractionError(error),
);
}
rethrow;
}
}
}Use searchMeta when you want lightweight search metadata first, then explicitly assemble context or hydrate only the chunks you need.
final meta = await MobileRag.instance.searchMeta(
'What is Flutter?',
topK: 10,
);
try {
final context = await MobileRag.instance.assembleContext(
searchHandle: meta.handle,
tokenBudget: 2000,
);
final chunkIds = meta.hits.map((hit) => hit.chunkId.toInt()).toList();
final chunks = await MobileRag.instance.hydrateChunks(
searchHandle: meta.handle,
chunkIds: chunkIds,
);
final excerpts = await MobileRag.instance.getChunkExcerpts(
searchHandle: meta.handle,
chunkIds: chunkIds,
maxBytes: 256,
);
print(context.text);
print('hydrated=${chunks.length}, excerpts=${excerpts.length}');
} finally {
await meta.handle.dispose();
}Use collection scopes when you want independent rebuild boundaries per category.
final business = MobileRag.instance.inCollection('business');
final travel = MobileRag.instance.inCollection('travel');
await business.addDocument('Quarterly planning memo...');
await travel.addDocument('Kyoto itinerary...');
if (!travel.isIndexReady) {
await travel.warmupFuture;
}
final travelHits = await travel.searchHybrid('itinerary');
print(travelHits.length);If you do not specify a collection, the engine uses the default __default__
collection for backward compatibility.
Advanced Usage: For fine-grained control, use the high-level metadata lane (
searchMeta,assembleContext,hydrateChunks,getChunkExcerpts) and the public API reference. Most apps should stay on theMobileRagfacade.
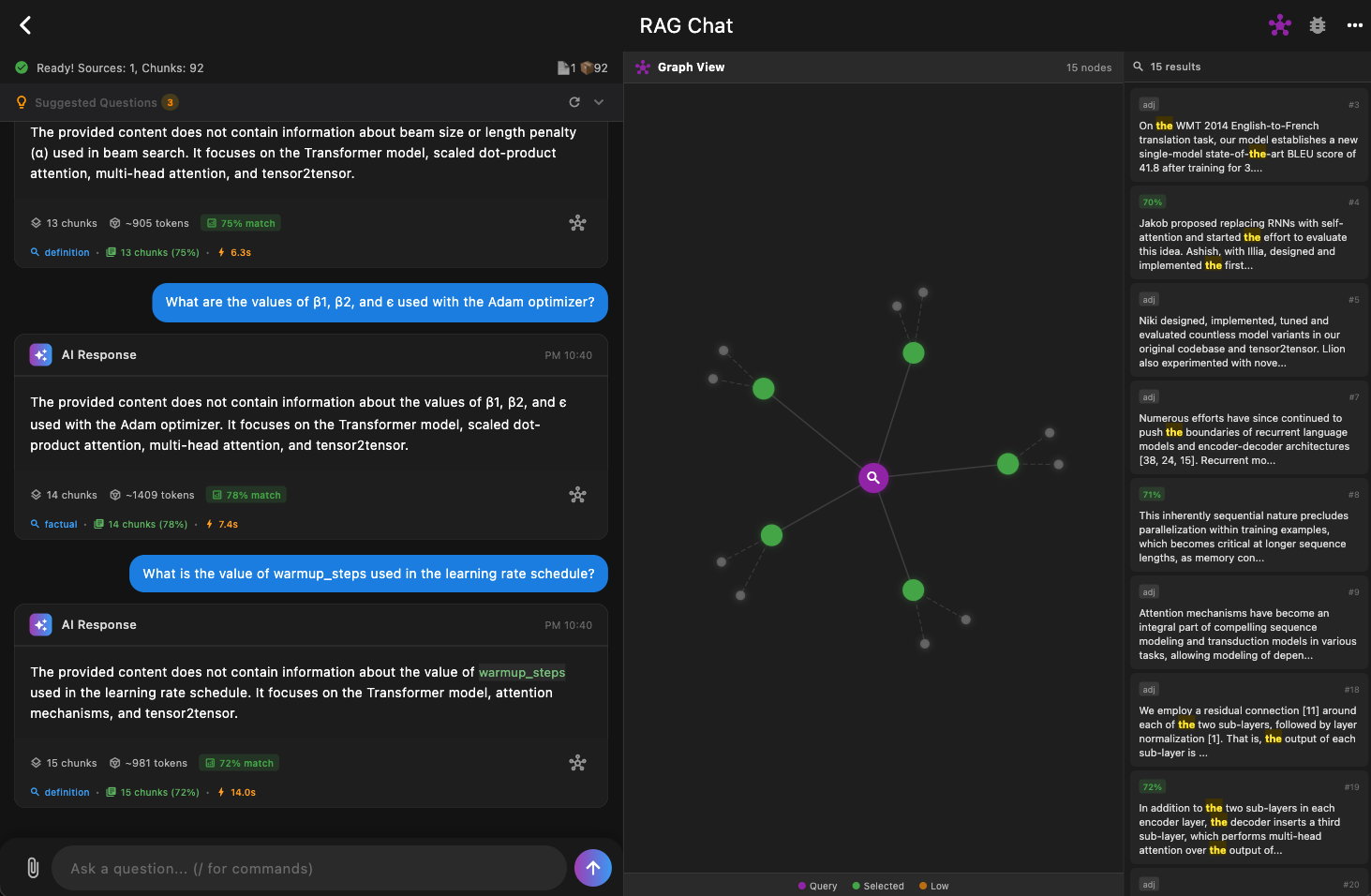
Check out the example application using this package. This desktop app demonstrates full RAG pipeline integration with an LLM (Gemma 2B) running locally on-device.
Bug reports, feature requests, and PRs are all welcome!
This project is licensed under the MIT License.