ec2cluster is a Rails web console, including a REST API, that launches temporary Beowulf clusters on Amazon EC2 for parallel processing. You upload input data and code to Amazon S3, then submit a job request including how many nodes you want in your cluster. ec2cluster will spin up & configure a private beowulf cluster, process the data in parallel across the nodes, upload the output results to an Amazon S3 bucket, and terminate the cluster when the job completes (termination is optional). ec2cluster is like Amazon Elastic MapReduce, except it is uses MPI and REST instead of Hadoop and SOAP. The source code is also free for use in both personal and commercial projects, released under the BSD license.
- feature 1
- feature 2
overview goes here, workflow, s3 inputs, commands.
instructions go here for kmeans example
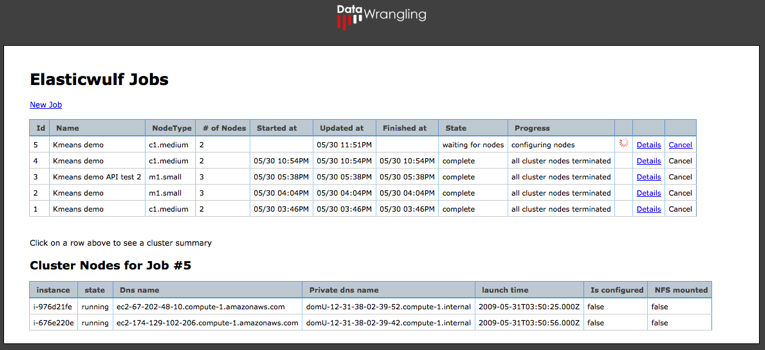
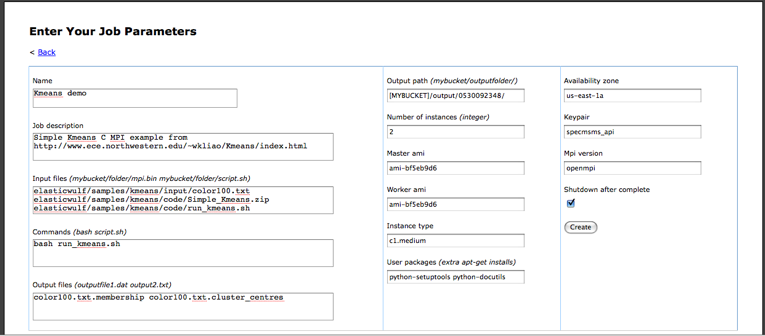
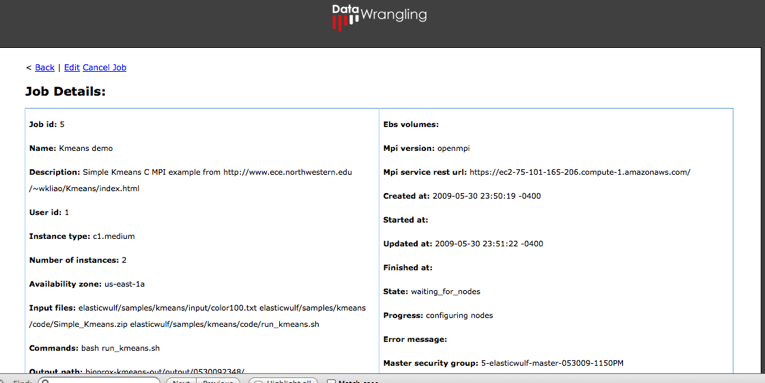
todo
TODO: API docs and instructions go here
TODO: flesh this out more…
The full code is at http://github.com/datawrangling/ec2cluster-client-demos
Fill in your AWS info and server details in config.yml:
aws_access_key_id: AAAAA8BHBBBBBBBBBMM9
aws_secret_access_key: ABCiDu/BIBSCubisbdiBISBDUSBDUSBFSUIbubbu
rest_url: https://ec2-XXX-XXX-XX-XXX.compute-1.amazonaws.com/
admin_user: REPLACE_ME
admin_password: REPLACE_ME
inputbucket: REPLACE-WITH-YOUR-INBUCKET
outputbucket: REPLACE-WITH-YOUR-OUTBUCKET
keypair: your-keypair
Use ActiveResource to communicate with the ec2cluster REST API with Ruby
class Job < ActiveResource::Base
self.site = CONFIG['rest_url']
self.user = CONFIG['admin_user']
self.password = CONFIG['admin_password']
self.timeout = 5
end
Submit a new job request to the API using just the required parameters:
job = Job.new(:name => "Kmeans demo API test 2",
:description => "Simple Kmeans C MPI example, run by pete using Ruby client",
:input_files => s3infiles.join(" "),
:commands => "bash run_kmeans.sh",
:output_files => expected_outputs.join(" "),
:output_path => CONFIG["outputbucket"] + "/" + out_path,
:number_of_instances => "3",
:instance_type => "m1.small")
job.save
job_id = job.id
Periodically ping server for job status until Job is complete, then fetch output files from S3
until job.state == 'complete' do
begin
job = Job.find(job_id)
puts "[State]: " + job.state + " [Progress]: " + job.progress unless job.progress.nil?
rescue ActiveResource::TimeoutError
puts "TimeoutError calling REST server..."
end
sleep 5
end
Some examples of other optional parameters for Job.new()
master_ami => "ami-bf5eb9d6"
worker_ami => "ami-bf5eb9d6"
user_packages => "python-setuptools python-docutils"
availability_zone => "us-east-1a"
keypair => CONFIG["keypair"]
mpi_version => "openmpi"
shutdown_after_complete => false
Submit a new job request
To submit a new job via a json request, you can post a JSON request to the REST api:
REQUEST
$ curl -H “Content-Type:application/json” -H “Accept:application/json” -d \
“{\”job\“: {\”name\“: \”My Json MPI job\“, \”description\“: \”test run of X\!Tandem\“, \
\”user_id\“: 2, \”number_of_instances\“: 12, \”instance_type\“: \”c1.medium\“, \
\”input_files\“: \”s3://mybucket/input/genome.txt s3://myfastabucket/somedata.fasta\“, \
\”commands\“: \”bash runtandem.sh\“, \”output_files\“: \”myoutput.txt\“, \”output_path\“: \
\”S3://myoutputbucket/myrunsfolder\“}}” http://localhost:3000/jobs
Checking on job status via GET
REQUEST
$ curl http://localhost:3000/jobs/3.json
Cancel a job request and shutdown the EC2 cluster
REQUEST
$ curl -H “Content-Type:application/json” -H “Accept: application/json” \
-X PUT http://localhost:3000/jobs/3/cancel
todo
todo
todo
todo
todo
If you can solve your problem with Hadoop, go for it. If you are short on time and MPI code exists that solves your problem, then you might want to try ec2cluster. MPI has been around for a while and there are lots of existing libraries for a number of domains. That said, debugging MPI jobs and dealing with node failure can be a hassle. Reuse or reimplement, your choice.
dependencies will go here (rails, ec2onrails, capistrano, Amazon EC2/S3 setup)
fetching the source code instructions will go here
Install the ec2onrails gem as described at http://ec2onrails.rubyforge.org/:
$ sudo gem install ec2onrails
Find AMI id of the latest 32 bit ec2onrails image (in our case this was ami-5394733a):
$ cap ec2onrails:ami_ids
Launch an instance of the latest ec2onrails ami and note the returned instance address from ec2-describe-instances, it will be something like ec2-12-xx-xx-xx.z-1.compute-1.amazonaws.com
$ ec2-run-instances ami-5394733a -k gsg-keypair
$ ec2-describe-instances
Create the needed configuration files from the provided examples and edit them, filling in your instance address information, keypairs, and other configuration information as indicated in the comments of each file. See the ec2onrails documentation or source code for more details on each setting. If you want to make changes to the ec2cluster code, be sure to replace the base github repository in deploy.rb and config.yml with your own github location.
$ cp config/deploy.rb.example config/deploy.rb
$ cp config/s3.yml.example config/s3.yml
$ cp config/config.yml.example config/config.yml
$ cp config/database.yml.example config/database.yml
Be sure to substitute in your own AWS key and secret key in both config.yml and s3.yml
aws_secret_access_key: YYVUYVIUBIBI
aws_access_key_id: BBKBBOUjbkj/BBOUBOBJKBjbjbboubuBUB
Also replace the admin user name and password in config.yml:
admin_user: REPLACE_ME
admin_password: REPLACE_ME
This application should be run under SSL and the access should be restricted to only trusted application ip addresses using EC2 security group filters. Ideally, your client application is also running on EC2 in the same security group.
Deploy the app to your launched EC2 instance with Capistrano (this wil take several minutes)
$ cap ec2onrails:setup
$ cap deploy:cold
Use the admin login information you set in config.yml to access the dashboard from a web browser or as web service at the url of the instance you provided in deploy.rb: https://ec2-12-xx-xx-xx.z-1.compute-1.amazonaws.com . You can also ssh into your running EC2 instance as usual with your keypairs to debug any issues. See the ec2onrails forums for more help debugging deployment issues.
To redeploy the app after making changes to the base ec2cluster code (this will also restart the delayed_job services which launch and terminate EC2 clusters):
$ cap deploy
To manually restart the apache service or mongrels:
$ cap ec2onrails:server:restart_services
$ cap deploy:restart
If the job processor is stuck waiting for instances, you might need to ensure the delayed_job worker is running. You can manually stop and start the delayed_job workers as follows:
$ cap delayed_job:stop
$ cap delayed_job:start
To clear the job queue, ssh into the EC2 instance and run the following command from within
/mnt/app/current(no rake task yet):
$ RAILS_ENV=production rake jobs:clear
Unless your local machine’s ip address and rails port is publicly reachable, local runs will not function properly (the cluster nodes need to communicate with the rails app).
Do the normal rails gem install dance for any missing dependencies
$ rake gems:install
Create the database
$ rake db:create
$ rake db:migrate
Launch the rails app itself
$ script/server
=> Booting Mongrel
=> Rails 2.3.2 application starting on http://0.0.0.0:3000
=> Call with -d to detach
=> Ctrl-C to shutdown server
Launch a background delayed_job worker in a separate terminal window
$ rake jobs:work
(in /Users/pskomoroch/rails_projects/ec2cluster)
* Starting job worker host:72-63-103-214.pools.spcsdns.net pid:12221
background cluster launch initiated…
1 jobs processed at 0.0498 j/s, 0 failed …
background cluster shutdown initiated…
1 jobs processed at 0.0499 j/s, 0 failed …
background cluster launch initiated…
Navigate to http://localhost:3000/ to use the web UI or submit REST requests