![]()
This repository is no longer maintained.
Please use the updated demo available here:
👉 Lakehouse AI: Deploy Your LLM Chatbot
This solution accelerator demonstrated how to build a domain-specific Q&A bot using large language models (LLMs) and your own data. The application combined user questions with relevant documents to generate grounded responses.
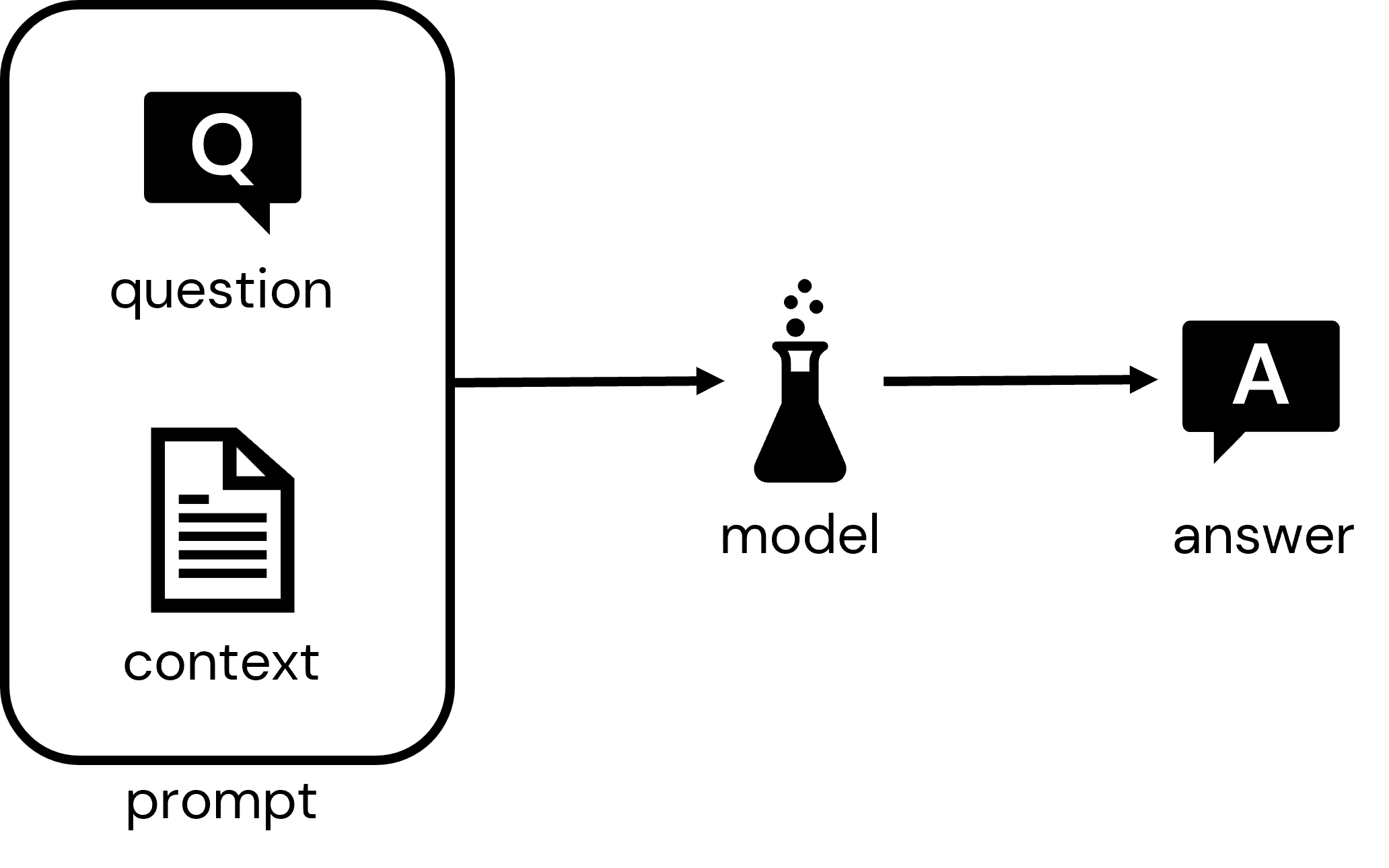
The original project consisted of:
- 01: Build Document Index
- 02: Assemble Application
- 03: Deploy Application
This project is provided as-is and is no longer actively supported by Databricks.
Please do not submit support tickets for this repository.
For the latest supported implementation, visit the new demo linked above.
© 2023 Databricks, Inc. All rights reserved. Source code is provided under the Databricks License.
| Library | Description | License | Source |
|---|---|---|---|
| langchain | LLM composability framework | MIT | https://pypi.org/project/langchain/ |
| tiktoken | Fast BPE tokenizer for OpenAI models | MIT | https://pypi.org/project/tiktoken/ |
| faiss-cpu | Similarity search and clustering for dense vectors | MIT | https://pypi.org/project/faiss-cpu/ |
| openai | OpenAI API client | MIT | https://pypi.org/project/openai/ |